此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第四课的第二周内容,2.5到2.7的内容。
本周为第四课的第二周内容,这一课所有内容的中心只有一个:计算机视觉。应用在深度学习里,就是专门用来进行图学习的模型和技术,是在之前全连接基础上的“特化”,也是相关专业里的一个重要研究大类。
这一整节课都存在大量需要反复理解的内容和机器学习、数学基础。 因此我会尽可能的补足基础,用比喻和实例来演示每个部分,从而帮助理解。
第二周的内容是对一些经典网络模型结构和原理的介绍,自然会涉及到相应的文献论文。因此,我也会在相应的模型下附上提出该模型的论文链接。
本篇的内容关于 1×1卷积与Inception网络。
1. 1×1卷积
1×1卷积的全称是在卷积层中使用1×1大小的卷积核。
很显然,乍一看这是一个让人疑惑的设置——我们知道,卷积操作的作用就是提取局部特征,而现在如果把卷积核设置为1×1大小,那不就是给输入整个乘了一个系数吗?有什么用?
在2013年前,大部分人也都是这种想法,直到这一年,一篇名为Network in Network的论文被发表,论文提出了 1×1 卷积可以在不改变特征图空间尺寸的前提下,对通道维度进行线性组合,从而灵活地调整通道数,并通过叠加非线性显著提升网络表达能力;相比用大卷积核堆叠实现相同效果,其参数量和计算量都更低。
因此,1×1 卷积虽然不能像其他卷积核一样用来提取局部特征,但它也有自己独特的作用。
用更好理解的话来说,1×1 卷积像是 “通道数上的池化(但带参数、还能升维)”和“卷积实现的全连接” 。
不太明白很正常,下面我们就来展开叙述。
1.1 1×1 卷积的实质:通道维度上的线性组合
我们已经知道,1×1 卷积不能用来提取空间上的局部特征。
在实际运算中,它做的事情非常单一:在每一个空间位置上,对所有通道对应的数值做一次线性组合。
说到这里,你可能会感到有些熟悉——这种运算形式,好像在某个地方已经见过了。
我们先来看课程中的这个例子:
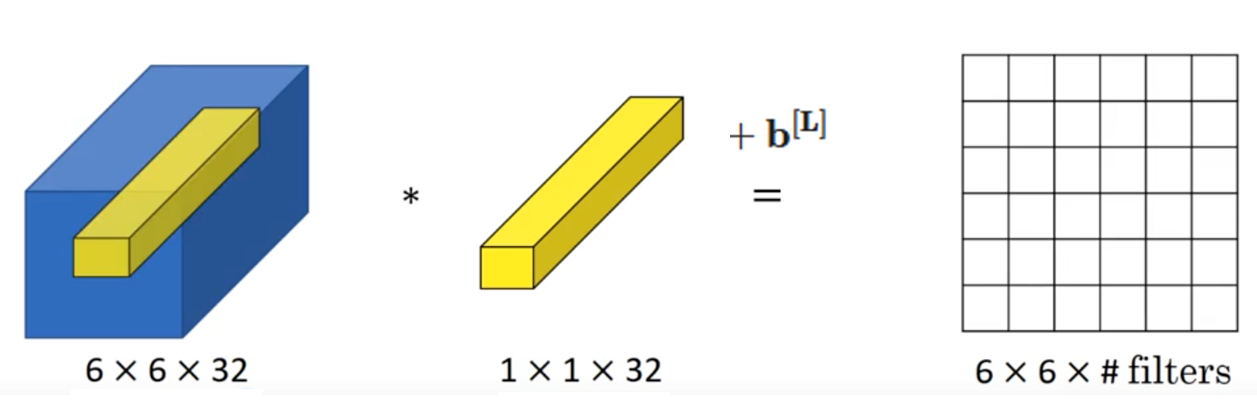
如果用数学形式来表示这一次的计算,就是这样:
没错,这就是单个样本在全连接层的线性组合公式。
在这个例子里,可以这样理解:
- 对于特征图中的每一个空间位置。
- 该位置在 32 个通道上的数值,组成了一个 32 维向量。
- 1×1 卷积所做的,就是对这个 32 维向量进行一次线性组合,得到新的输出特征。
从这个角度来看,每一个空间位置都可以被视作一个“独立的小样本”,而 1×1 卷积在该位置上的作用,就等价于对这个样本做了一次全连接层的计算。
所以说:1×1 卷积本质上是在同一空间位置上对通道做线性组合。
我们继续,还记得我们在卷积层特点里提到过的参数共享吗?
正是由于同一组 1×1 卷积核会共享到所有空间位置,网络会在反向传播过程中不断调整这些权重,从而学会:
- 哪些通道对应的特征更重要。
- 哪些特征应该被弱化。
- 哪些特征可以通过线性组合整合成更有效的表示。
我们再举一个简单的示例看看:
假设在某一层网络中,某一个空间位置 \((i,j)\) 在 3 个通道上的取值分别是:
这表示:在同一空间位置上,三个通道对应的特征值分别为 \(2\)、\(1\) 和 \(-1\)。
现在,我们对这一层使用 1×1 卷积,设该卷积核在通道维度上的权重为:
那么,该位置的线性组合结果为:
如果我们使用多个 1×1 卷积核,那么同一个位置就可以输出多个这样的数值,从而得到新的多通道特征图。
在了解了原理后,我们来看看1×1卷积在实际中更常见的一种应用。
1.2 使用1×1卷积调整通道数
使用1×1卷积,在保持空间尺寸不变的前提下,对通道数进行调整,减少计算量。这才是它在实际设计中更常见的应用。
其中一个原因是因为在实际调试中,我们很难直接感受网络的非线性和表达能力的强弱,但是却能直接地测算出网络参数量和计算量的减少。
另外就是一些特殊的网络需要通道数的对齐,比如残差网络,我们很快就会提到它。
来看课程中这样一个例子:
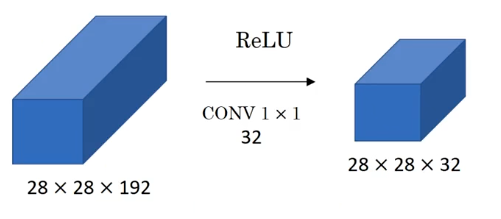
可以看到,这一层卷积仅仅改变了通道数的大小,为什么要这么做?
我们知道,如果想在不增加太多参数的情况下压缩特征图的空间尺寸,池化通常是一个常用的选择。
我们打几个比方来帮助理解:
可以把池化理解为“把一张高清照片缩小分辨率”:画面变小了,细节少了一点,但整体轮廓还在。
但池化有一个明显的局限:它只能压缩长和宽,却无法改变通道数。
也就是说,池化只能让“每一张图变小”,却没法决定“这组图里到底保留几张”。
因此,当我们希望在保持空间尺寸不变的前提下,对通道数进行调整时,就不得不引入卷积操作。如果直接使用 3×3、5×5 这样的卷积核,就相当于一边在做空间特征提取,一边还要完成通道重组,参数量和计算量都会迅速增加,而现在我们只想调整通道数。
在这种情况下,1×1 卷积就像一个“通道维度上的判断者”。
它不会去看周围像素的信息(实际上也看不了),而是站在每一个空间位置上,只对该位置的所有通道做重新组合:哪些特征该保留,哪些该弱化,哪些可以合并在一起,都由 1×1 卷积来决定。
因为就像上面所提的: 1×1 卷积本质上是在同一空间位置上对通道做线性组合。
总结一下,1×1 卷积不负责“看得更广”,而是负责“把已有的信息整理得更清楚”,即在不改变空间结构的前提下,对特征进行重组与筛选。
正因为它不引入新的空间邻域关系,却又能灵活调整通道数,所以相比使用大尺寸卷积核,它在完成相同通道变换任务时,参数量和计算开销都要小得多。
1.3 拓展:ResNet 中的 1×1 卷积应用
在上一篇残差网络中我们就提到过,ResNet 中有很多细节值得说明,对 1×1 卷积的使用就是其中之一。
这里我们正式引入1×1 卷积后,就再来看看它在 ResNet 中发挥的作用。
再复制一下残差网络中的一个关键点:在残差块中,参与融合(相加)的两条分支,其输出张量的维度必须一致,否则残差相加无法进行。
ResNet 里有那么多残差块,总不能让数据在传播中全设置为固定维度吧?
1×1 卷积正是 ResNet 中解决这一问题的关键工具,它在 ResNet 既起到了维度对齐的作用,又在深层网络中减少了计算量。
下面就简单展开一下:
(1)用于残差分支中的“维度对齐”
我们已经知道,残差连接的核心操作是:
但是再重复一遍,这里有一个隐含前提:\(F(x)\) 和 \(x\) 的 形状必须完全一致(空间尺寸 + 通道数)。
在理想情况下,残差块输入输出通道数相同,旁路连接可以直接相加;但在实际网络设计中,经常会遇到这种情况:
- 主分支通过卷积 改变了通道数(例如 64 → 128)。
- 或者通过 stride=2 的卷积 改变了空间尺寸。
这时,原始输入 \(x\) 已经无法直接与 \(F(x)\) 相加。
而解决方法就是:
在旁路上引入一个 1×1 卷积,对 \(x\) 做一次线性映射:
再进行残差相加:
这里有一点很容易迷惑:我记得1×1 卷积不是只能改变通道数吗?它怎么适应空间尺寸的变化?
别忘了,卷积有好几个参数呢:
我们可以通过调整 1×1 卷积步长和 padding 让他适应 \(F(x)\) 的维度。
打个比方来总结一下: 这里的 1×1 卷积就像一个转接头,让旁路连接能顺利进行。
(2)用于 Bottleneck 结构中的“降维—升维”
论文在更深的 ResNet(如 ResNet-50 / 101)中,引入了著名的 Bottleneck 结构:
这里的两个 1×1 卷积并不是为了提取空间特征,而是承担通道调度的作用:
- 第一个 1×1 卷积:降维,减少通道数,降低后续 3×3 卷积的计算量。
- 第二个 1×1 卷积:升维,恢复通道数,保证与残差分支可相加。
为什么要这么做?
还是打个比方:
如果把 3×3 卷积看成是“需要对每一个像素周围反复计算的大型加工机器”,那么 1×1 卷积更像是一个“预处理与整理工序”:
- 干活前,先用 1×1 卷积把原本“杂乱、冗余、维度很高”的原材料压缩成更精简的形态(降维),让后续的 3×3 卷积在更少的通道上重复计算;
- 干活后,再用 1×1 卷积把加工后的结果重新展开、整合成需要的规模(升维)。
这样做的关键在于:把最耗计算量的 3×3 卷积,限制在更小的通道空间里执行。
而这样做的结果是:
相比三个3×3 卷积,在几乎不损失表达能力的前提下,大幅降低参数量和计算量。这是 ResNet 能够做到“又深又能训”的重要原因之一。
而这里的 1×1 卷积不直接创造新信息,但决定信息如何高效、顺畅地流动。
这便是 ResNet 对1×1 卷积的应用。
2. Inception网络
在开始之前,需要先说明的是:Inception 网络不同于 ResNet,其完整结构在当前主流视觉模型中已较少直接使用,尤其是在 Transformer 架构兴起之后,其整体设计思路逐渐淡出主流。
因此,这里不再对 Inception 网络本身展开过多细节,而是主要说说它的一项至今仍被广泛借鉴的一项核心思想——多尺度卷积。
2.1 多尺度卷积
我们已经了解了很多卷积网络了,如果再让我们自己设计卷积网络,你更倾向先设置卷积核为多少?
我个人更倾向于使用一些著名论文里的参数设置,再进行调试看看效果,但这样又花费了大量的时间。
因此,在 2014 年,一篇名为 Going deeper with convolutions的论文提出了这样一个想法:不知道哪个好那我就都用上,即不再人为固定卷积核尺度,而是在同一层中并行使用多种不同大小的卷积核,让网络在训练过程中自动学习如何组合和利用不同尺度的特征。
具体是怎么进行的?来看看课程里的示例:
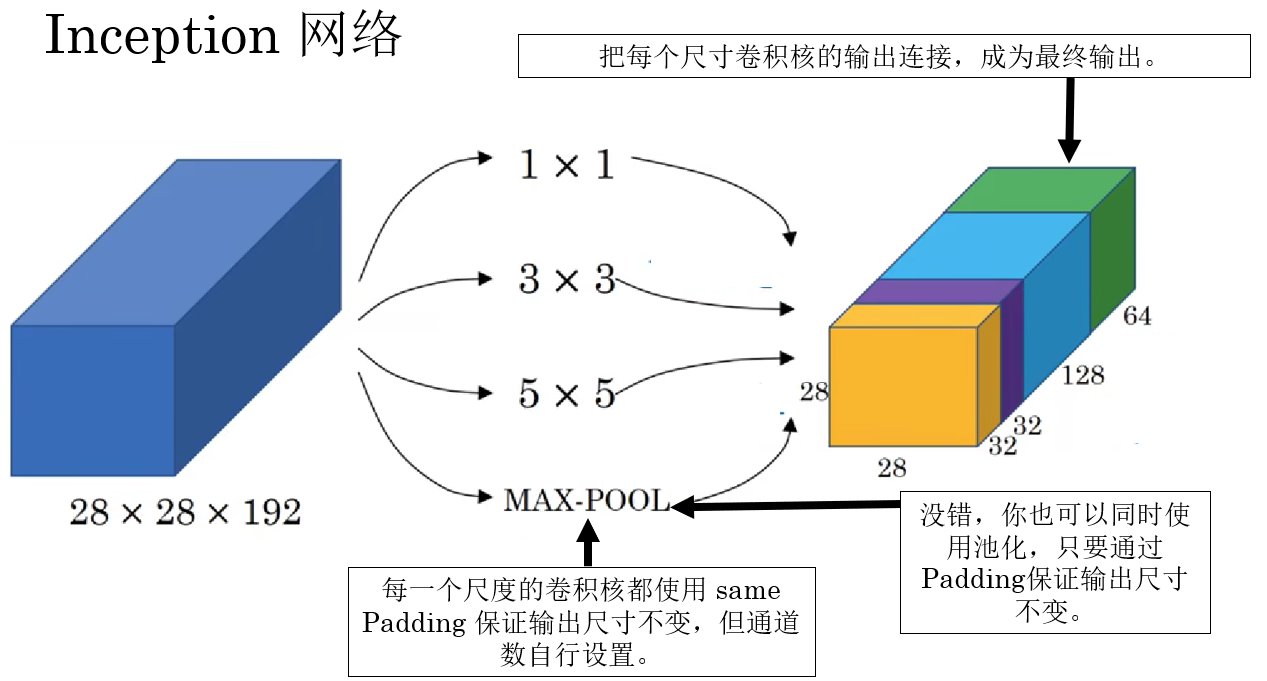
这一设计在当时确实达成了性能的提升,但同时也带来新的问题:极大的参数和计算量。
我们继续:
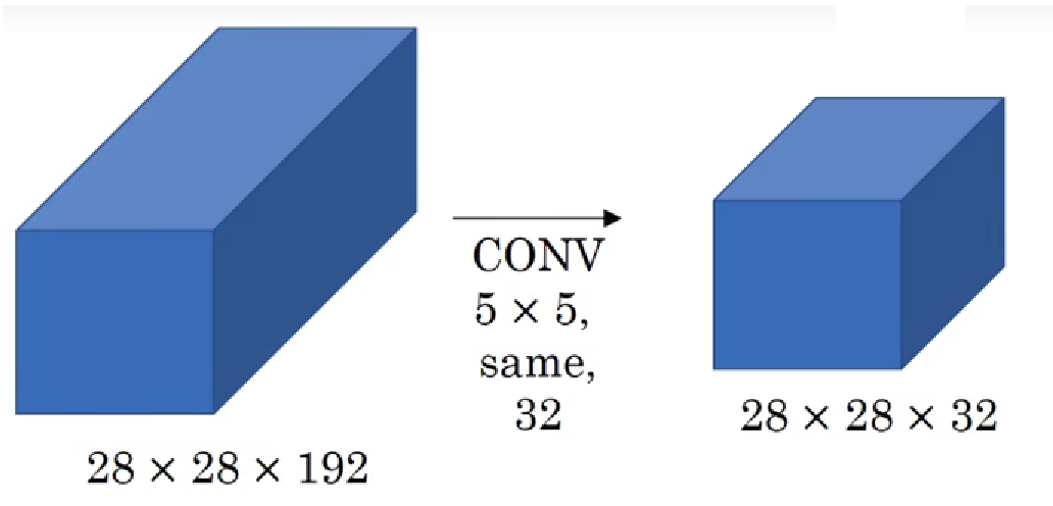
直接说结论:这层的正向传播会经过 1.2 亿次乘法运算, 这还只是网络中的一层。
那如何减少计算量?没错,Inception也应用了1×1 卷积。
2.2 Inception的1×1 卷积应用
实际上也很简单,把刚刚的层级结构改成下面这样:
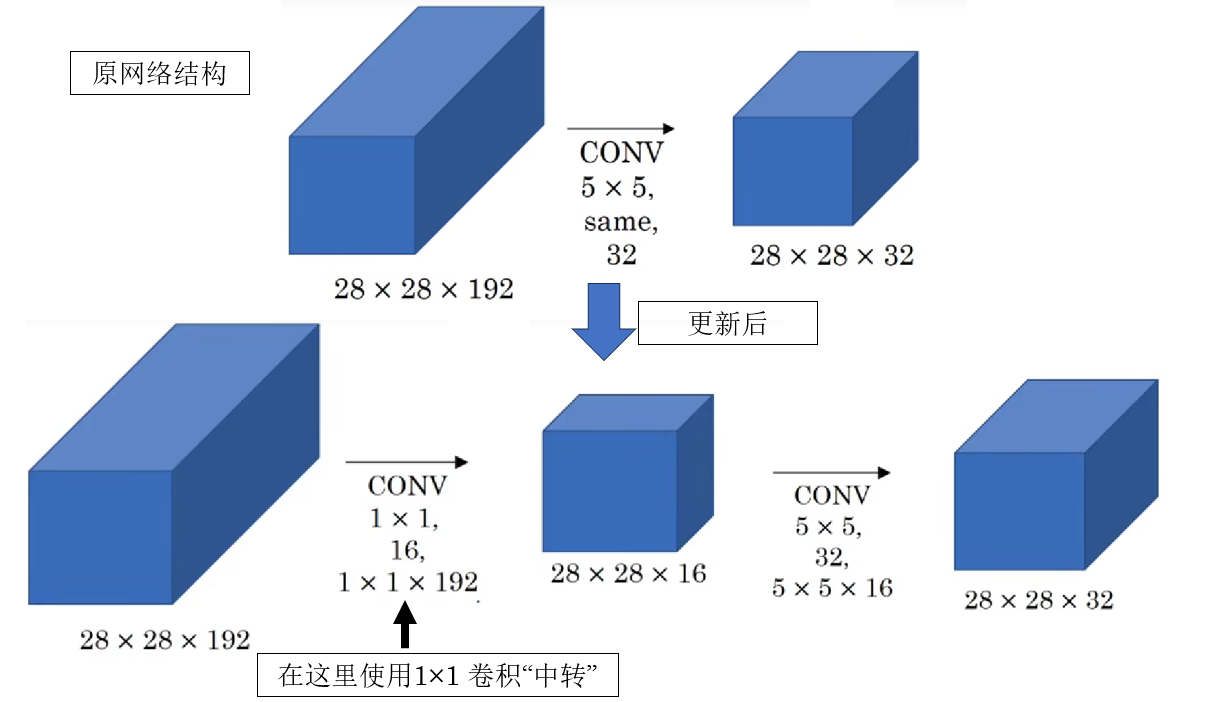
现在,这两次卷积运算也只会使用 1240 万次乘法,是原本的十分之一。
原理很简单:之前使用 32 个 5×5 卷积核直接对输入进行卷积,而现在在对输入进行卷积前,我们先用 1×1 卷积把输入通道数先压缩到原来的十分之一量级,总体上减少了计算量。
就不再详细展开计算过程了。
因此,下面就看看引入1×1 卷积后,Inception对一次多尺度卷积的设计是什么样的。
2.3 Inception的网络结构
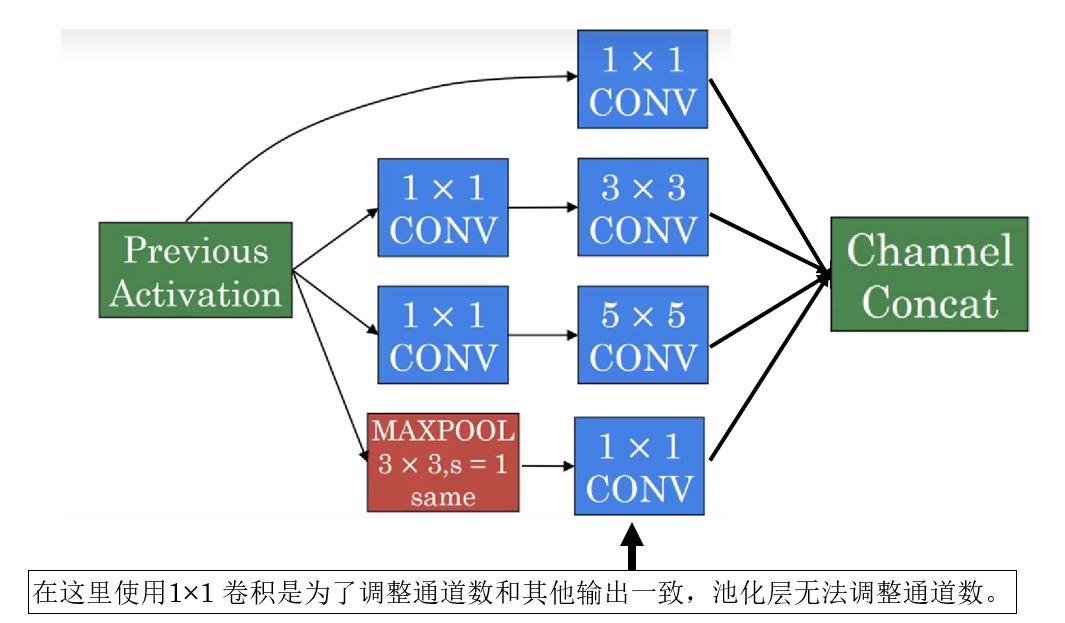
对于每层来说,实际上是就是给大尺度卷积核前都使用了一次1×1 卷积,像这样:
而整个网络就是这样层级的堆叠:
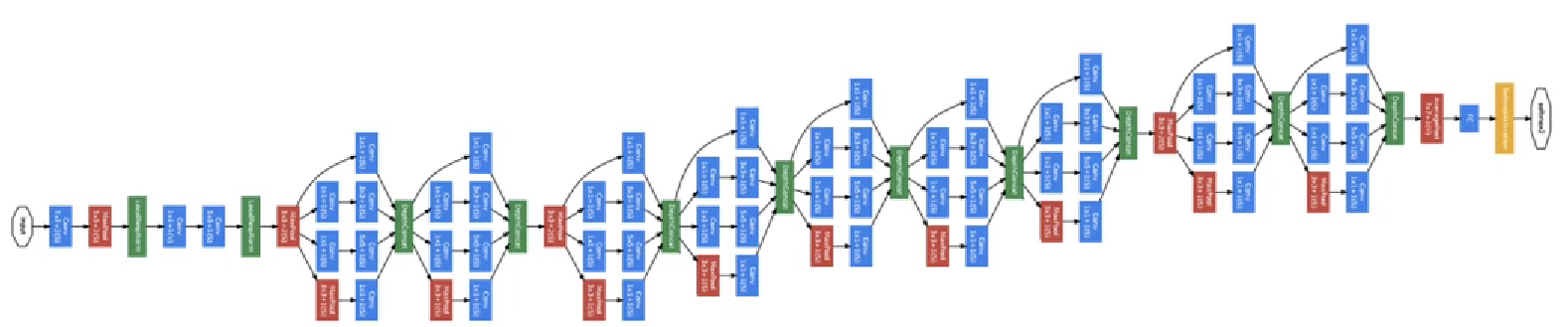
就不再过多展开关于 Inception 的内容了。
虽然 Inception 本身已经近乎退场,但他的贡献并不在于某一个具体模块,而在于它第一次系统性地提出:单一尺度不足以描述复杂视觉结构。
后续模型几乎无一例外地继承了这一思想,只是将“多尺度”的实现方式,从同层并行卷积,演化为跨层结构、感受野调控或注意力机制。
3.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 1×1 卷积 | 在不改变空间尺寸的前提下,对同一空间位置的通道向量做线性组合,可实现通道压缩、扩展与重组 | 像是在每个像素点上做一次“带参数的筛选与加权汇总”,不看周围,只整理自己手里的信息 |
| 通道调整(降维 / 升维) | 通过控制输出通道数,减少或扩展特征表示,尤其用于控制计算量 | 像是在决定:这批信息里哪些值得继续加工,哪些先压缩收纳 |
| 1×1 卷积 vs 池化 | 池化压缩空间尺寸但不改通道;1×1 卷积改通道但不动空间 | 池化像缩小照片分辨率;1×1 卷积像整理照片册里保留几张照片 |
| ResNet 中的维度对齐 | 当主分支改变通道数或空间尺寸时,用带 stride 的 1×1 卷积调整旁路形状以便相加 | 像一个转接头,把不匹配的接口接成能插上的形状 |
| Bottleneck 结构 | 用 1×1 降维 → 3×3 计算 → 1×1 升维,把高成本计算限制在低维空间 | 像是先把原料切细再加工,最后再拼装回成品 |
| Inception 的多尺度思想 | 同一层并行使用多种卷积核尺度,让网络自动选择有效尺度 | 像是同时用放大镜、普通镜和望远镜观察同一物体 |
| Inception 的计算问题 | 多尺度并行带来参数和计算量爆炸 | 像是所有机器同时全速运转,成本急剧上升 |
| Inception 中的 1×1 卷积 | 在大卷积前先压缩通道,显著降低后续多尺度卷积的计算量 | 像是先精简原料,再送进重型加工设备 |