近年来,大语言模型(Large Language Models, LLMs)已经成为人工智能领域最重要的技术方向之一。从对话系统到代码生成,再到各类智能助手,模型规模和应用场景都在不断扩展。然而,与模型能力同步增长的,是推理阶段对算力、能耗和系统效率的持续压力。
目前,大多数大模型推理仍然依赖 GPU。但在实际应用中,GPU 并非在所有推理场景下都是最优解,我们也希望探索 FPGA 等新型设备的推理性能。
本系列博客将围绕一个具体而完整的实验项目,介绍如何使用 FPGA 对大模型推理进行加速,并跑通一个可以在终端中交互的推理 demo。具体的博客内容如下:
- 如何使用 FPGA 推理大模型 (1) - 简介
- 如何使用 FPGA 推理大模型 (2) - 加速核心编写
- 如何使用 FPGA 推理大模型 (3) - 硬件平台搭建
- 如何使用 FPGA 推理大模型 (4) - 运行推理
1. 为什么使用 FPGA?
GPU 更擅长大规模、批量化的并行计算,而大模型的推理阶段,GPU 的算力往往难以被充分利用。FPGA 是可定制化的硬件,能够根据模型大小与精度对硬件架构进行细粒度的调整,在能效比上仍具有优势。
我们希望借助本博客,帮助大模型社区爱好者、FPGA 初学者了解 FPGA 计算加速的部署流程。
2. 加速成果展示
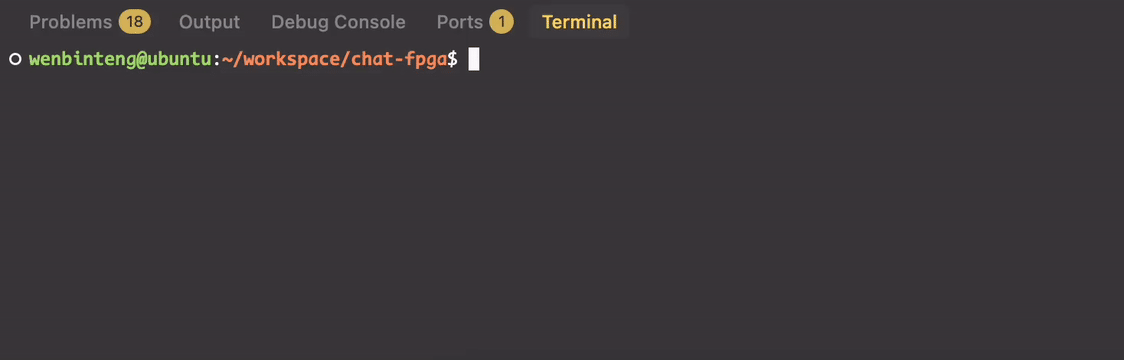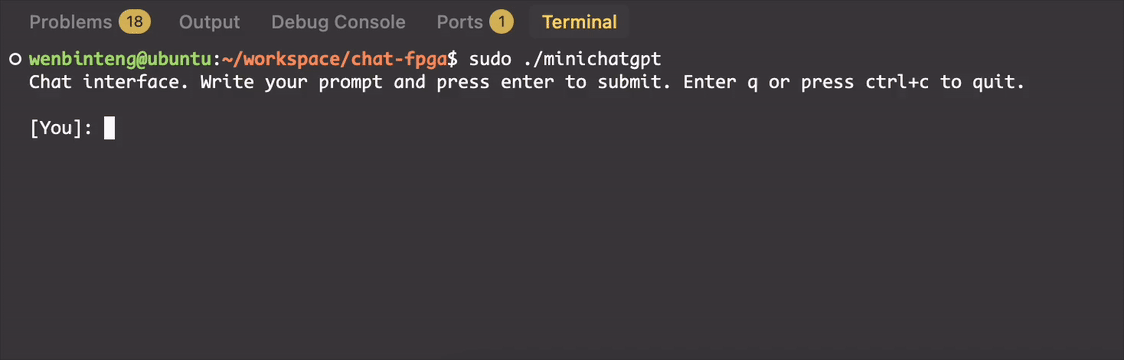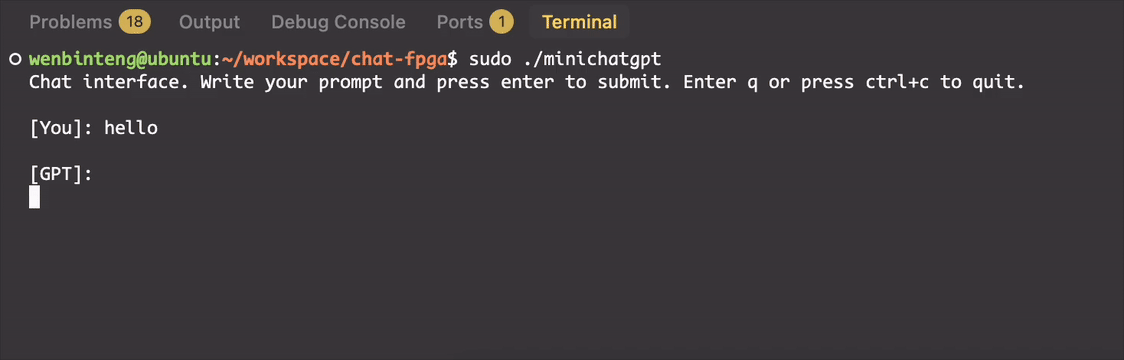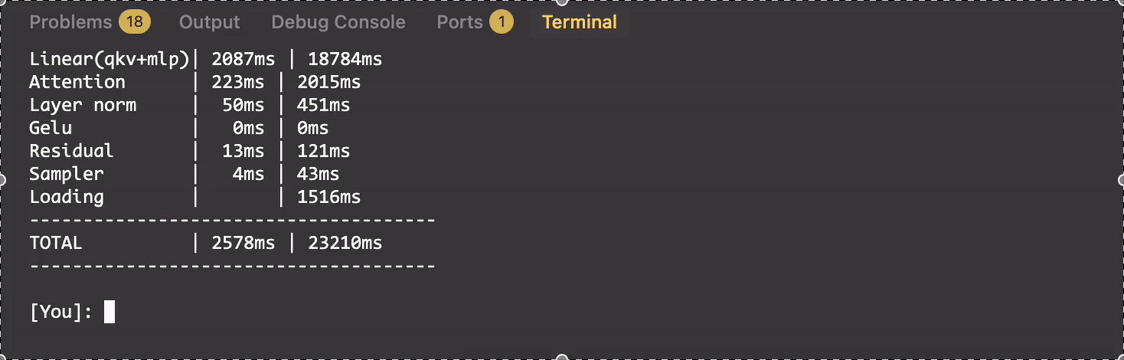
下面分别是在 FPGA (AMD Xilinx Alveo U280) 上推理 GPT-2 的效果(x10 speed)。
3. 项目代码仓库与快速上手
本系列博客对应的代码仓库为:chat-fpga,仓库中包含 FPGA 硬件平台工程、FPGA 加速核心代码、模型推理框架,可以支持快速上手与再次开发。
快速上手
- 克隆我们的代码仓库。
git clone https://github.com/WenbinTeng/chat-fpga.git
cd chat-fpga
- 编译推理框架。
make
- 使用我们提供的比特流,烧写 FPGA(Xilinx Alveo U280)。
cd bitstreams
vivado -mode batch -source program.tcl
- 下载 XDMA 驱动,编译,加载。
git clone https://github.com/Xilinx/dma_ip_drivers.git
cd dma_ip_drivers/XDMA/linux-kernelcd xdma
sudo make installcd ../tools
sudo makecd ../tests
sudo ./load_driver.sh
- 执行推理,在命令行中进行对话。
sudo ./minichatgpt
如果您对更详细的设计部署流程感兴趣,可以继续浏览我们的博客!