从零搭建向量数据库:实现文本语义检索实战
写在最前面:我一开始真没打算“自己搭一个”
说句实话,我第一次接触向量数据库的时候,根本没想过要自己搭一套。
原因也很现实:
- 市面上已经有不少成熟产品
- 文档、SDK、Demo 一应俱全
- 看起来直接用现成的就好
所以一开始我的想法非常简单:
我只需要一个“能做语义检索的东西”,
至于它内部怎么跑的,说实话并不关心。
直到后来在项目里遇到几个非常具体的问题:
- 检索结果为什么会抖
- 为什么同样的数据,换个参数效果差这么多
- 数据量一上来,延迟突然失控
那时候我才意识到一个问题:
如果你完全不了解向量数据库是怎么“拼”起来的,
那你其实很难用好它。
这篇文章,就是在这种背景下写的。
不是为了造一个“能对外卖钱的数据库”,而是为了搞清楚:
一套最小可用的向量数据库,从工程角度到底需要哪些东西?
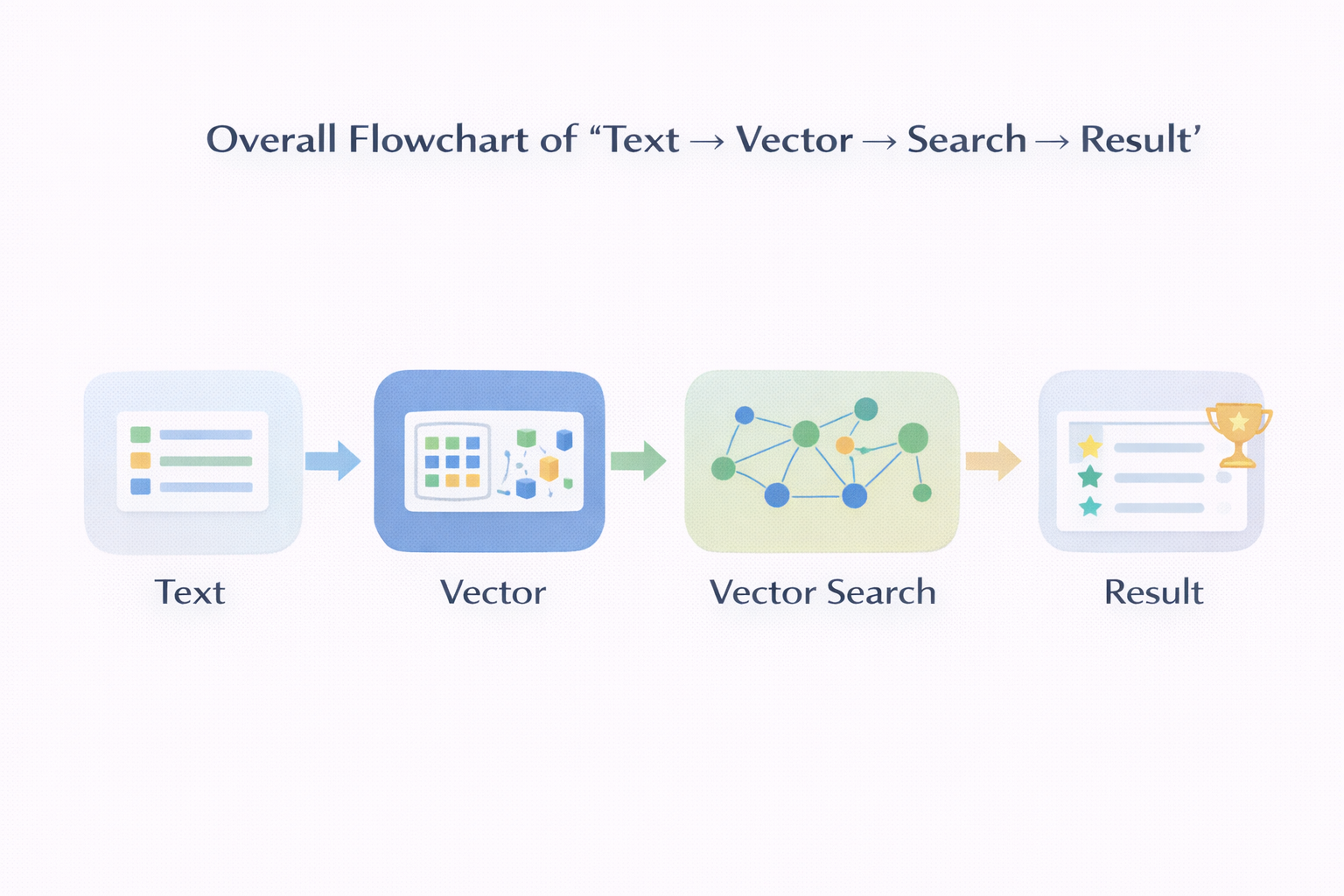
从目标说起:我们到底要做一个什么东西
在开始写代码之前,我建议先把目标说清楚。
这篇文章里,我们要做的事情其实很克制:
- 输入是一段文本
- 系统能返回语义上相近的文本
- 支持一定规模的数据
- 结构清楚、可扩展
换句话说,我们要实现的是:
一个最小但完整的文本语义检索系统
它不追求极限性能,但每一层都是真实向量数据库会有的结构。
第一步:把“文本”变成“向量”(很多问题从这里开始)
所有向量数据库的起点,其实都非常一致:
你得先有向量。
这一步通常叫 embedding。
选模型之前,我先踩过一个坑
一开始我也犯过一个很常见的错误:
embedding 模型,越大越好吧?
后来发现,完全不是这么回事。
在真实工程里,你要考虑的其实是:
- 向量维度
- 生成速度
- 稳定性
- 是否和你的任务匹配
对“文本语义检索”这个任务来说,一个稳定、维度适中、输出一致的模型,往往比一个“看起来更强”的模型更重要。
一个很现实的工程判断
如果你是第一次搭:
- 不要追求最强 embedding
- 不要一上来就换模型
- 先选一个“大家都用过、坑被踩过的”
因为后面你会发现,问题往往不出在 embedding 上。
第二步:向量要不要“原样存”?
当你已经能把文本变成向量,接下来一个非常自然的问题就来了:
向量该怎么存?
很多人第一反应是:
直接存成 list / numpy array 不就行了?
在数据量很小的时候,这个想法完全没问题。
但一旦你认真算一下空间和性能,就会开始犹豫。
一个简单但很打击人的计算
假设:
- 100 万条文本
- 每条 768 维
- float32
那你光原始向量就已经是几十 GB。
这时候你就会意识到:
“原样存”这条路,迟早会走不下去。
压缩不是锦上添花,而是你迟早要面对的事
我当时的第一反应其实是抗拒的:
我只是想做个语义检索,
怎么突然就要研究压缩了?
但后来你会发现,压缩在向量数据库里承担的角色非常特殊:
- 它不只是为了省空间
- 更是为了让后面的检索“跑得动”
哪怕你第一版系统里不真的做复杂压缩,
你也要在结构上给它留位置。
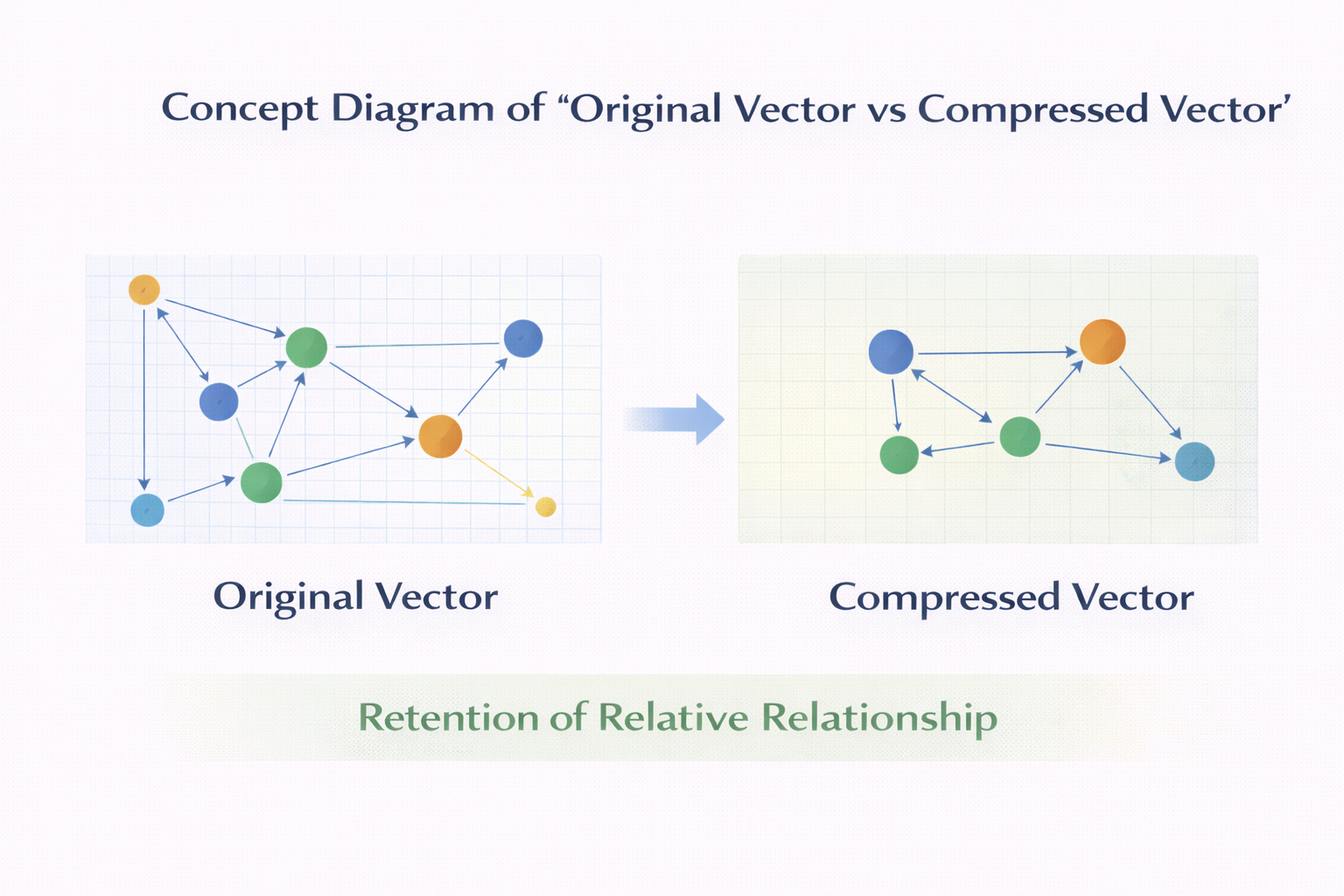
原始向量 vs 压缩向量 概念图
第三步:最朴素的检索方式(以及它为什么注定不行)
在正式引入索引之前,我强烈建议你先实现一版最朴素的检索。
也就是:
- 对 query 向量
- 和所有向量
- 逐一算相似度
- 排序取 topK
为什么?
因为这是你理解后面一切优化的“对照组”。
当你真正跑起来的时候,会发生什么
在数据量小时,你会觉得:
好像也没那么慢?
但只要你把数据量放大一个数量级,
延迟和资源占用就会立刻告诉你现实有多残酷。
这一步非常重要,因为它会让你发自内心地接受:
必须引入近似搜索。
第四步:接受现实,引入 ANN
我第一次认真看 ANN 相关资料的时候,内心其实是有点抗拒的。
因为这意味着一个非常不工程师直觉的事实:
我主动放弃“最优解”。
但后来你会发现,这不是退步,而是妥协。
一个重要但常被忽略的认知
在语义检索里:
- 你几乎不可能定义“绝对最相似”
- 人类对结果的容忍度其实很高
- 稳定、可控,远比“极致准确”重要
所以 ANN 的存在,本质上是:
把“精确性”换成“可用性”。
第五步:我们到底要不要“自己写索引”
这是很多人会卡住的地方。
我的建议非常直接:
第一版,千万别自己实现复杂索引算法。
不是因为你写不出来,而是因为:
- 实现成本极高
- debug 成本更高
- 非常容易在细节上出错
更好的方式是:
- 先理解索引在干什么
- 再决定是否替换、优化
你要清楚的是:
向量数据库真正的难点,不是“有没有索引”,
而是索引和系统其他部分怎么配合。
第六步:一次完整查询到底发生了什么
当你把系统各个模块拼起来,一次语义检索请求,通常会经历:
- 文本 → embedding
- embedding → 索引搜索
- 得到候选向量
- 精排
- 返回结果
一个很重要的工程细节是:
真正参与精确相似度计算的向量,数量应该很少。
如果不是这样,那你的系统迟早会顶不住。

向量检索完整请求路径图
第七步:别忽略元数据和过滤条件
很多“从零搭建”的教程,都会下意识忽略 metadata。
但在真实系统里,没有 metadata 的向量数据库几乎没法用。
比如:
- 时间过滤
- 类型过滤
- 权限控制
工程上的现实是:
向量检索只是第一步,
真正能不能用,取决于你怎么把它和结构化条件结合。
第八步:性能问题通常不是你一开始想的那样
很多人会下意识把性能问题归结为:
- 向量算得慢
- 索引不够高级
但我在实践中遇到的瓶颈,更多来自:
- 内存布局不友好
- cache miss
- 数据结构不连续
这也是为什么你会发现:
同样的算法,不同实现,性能差距巨大。
写到这里,说点非常现实的感受
如果你真的按这条路从零搭一遍,你会明显感觉到:
- 向量数据库并不“神秘”
- 它是很多工程选择堆出来的结果
- 每一步看起来都不复杂,但组合起来很重
这也是为什么,大多数团队最终都会选择:
- 用成熟方案
- 但前提是你理解它在干什么
写在最后:什么时候你应该自己搭,什么时候不该
我现在对“自己搭向量数据库”的看法是这样的:
- 为了学习,非常值得
- 为了上线产品,大多数时候不值得
- 为了理解系统边界,极其有价值
你不一定要永远自己维护一套,
但你最好至少亲手搭过一次。
尾声:一点关于工程效率的补充
在真实项目中,你往往不仅要处理向量检索,还要同时面对:
- 数据构建
- 模型训练
- 实验对比
- 版本管理
如果你把所有东西都从零写一遍,成本会非常高。
这也是为什么我后来会在一些项目里,先借助像 LLaMA-Factory online 这样的工具,把模型微调、数据处理、实验流程这些容易反复踩坑的部分先跑顺,再把精力放在真正需要定制的系统设计上。
它解决的不是“算法多高级”,而是一个很现实的问题:
让工程师少在重复的工程细节里消耗精力。