链接:【NLP公开课02:深度时序数据与文本数据结构】
在深度学习的世界中,某一领域的架构/算法往往是根据该领域中特定的数据状态设计出来的。例如,为了处理带有空间信息的图像数据,算法工程师们使用了能够处理空间信息的卷积操作来创造卷积神经网络;又比如,为了将充满噪音的数据转变成干净的数据,算法工程师们创造了能够吞吃噪音、输出纯净数据的自动编码器结构。因此,在了解每个领域的算法架构之前,我们最好先学习当前领域的数据特点和数据结构,在自然语言处理领域也是如此。
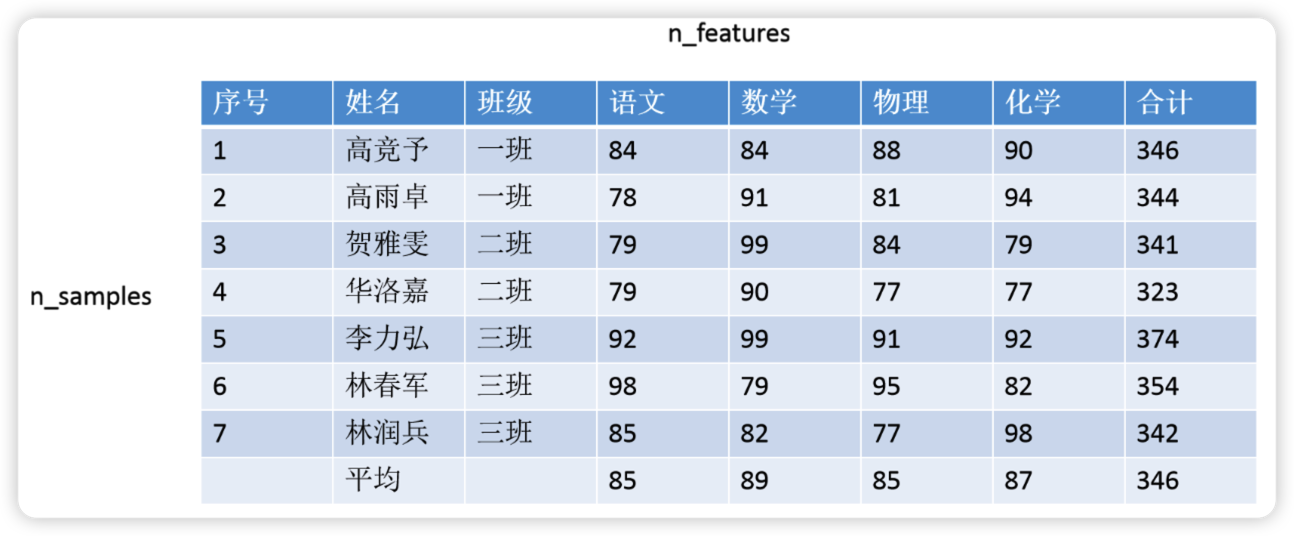
自然语言领域的核心数据是序列数据,这是一种在样本与样本之间存在特定顺序、且这种特定顺序不能被轻易修改的数据。这是什么意思呢?在机器学习和普通深度神经网络的领域中我们所使用的数据是二维表。如下所示,在普通的二维表中,样本与样本之间是相互独立的,一个样本及其特征对应了唯一的标签,因此无论我们先训练1号样本、还是先训练7号样本、还是只训练数据集中的一部分样本,都不会从本质上改变数据的含义、许多时候也不会改变算法对数据的理解和学习结果。
1. 序列数据分类
但序列数据则不然,对序列数据来说,一旦调换样本顺序或样本发生缺失,数据的含义就会发生巨大变化。最典型的序列数据有以下几种类型:
1.1 文本数据(Text Data):文本数据中的样本的“特定顺序”是语义的顺序,也就是词与词、句子与句子、段落与段落之间的顺序。在语义环境中,词语顺序的变化或词语的缺失可能会彻底改变语义,例如——
改变顺序:事半功倍和事倍功半;曾国藩战太平天国时非常著名的典故:他将“屡战屡败”修改为“屡败屡战”,前者给人绝望,后者给人希望。
样本缺失(对文本来说特指上下文缺失):小猫睡在毛毯上,因为它很____。当我们在横线上填上不同的词时,句子的含义会发生变化。
1.2 时间序列数据(Time Series Data):时间序列数据中的“特定顺序”就是时间顺序,时序数据中的每个样本就是每个时间点,在不同时间点上存在着不同的标签取值,且这些标签取值常常用于描述某个变量随时间变化的趋势,因此样本之间的顺序不能随意改变。例如,股票价格、气温记录和心电图等数据,一旦改变样本顺序,就会破坏当前趋势,影响对未来时间下的标签的预测。
1.3 音频数据(Audio Data):音频数据大部分时候是文本数据的声音信号,此时音频数据中的“特定顺序”也是语义的顺序;当然,音频数据中的顺序也可能是音符的顺序,试想你将一首歌的旋律全部打乱再重新播放,那整首歌的旋律和听感就会完全丧失。
1.4 视频数据(Video Data):你知道动画是由一张张原画构成的吗?视频数据本质就是由一帧帧图像构成的,因此视频数据是图像按照特定顺序排列后构成的数据。和音频数据类似,如果将动画或电影中的画面顺序打乱再重新播放,那没有任何人能够理解视频的内容。
类似的数据还有很多,例如DNA序列数据,从医学角度来说DNA测序的顺序不能被打乱,否则就会违背医学常识。除此之外,符号序列数据也是常见的序列数据,密码学、自动编码学、甚至自动编程的算法都对数据本身的逻辑有严格的要求。很明显,在处理序列数据时,我们不仅要让算法理解每一个样本,还需要让算法学习到样本与样本之间的联系。今天,这些能够学习到样本之间联系的算法们构成了自然语言处理架构群。
2 序列数据的输入数据结构
序列数据的概念很容易理解,但奇妙的是,现实中的序列数据可以是二、三、四、五任意维度,只要给原始的数据加上“时间顺序”或“位置顺序”,任意数据都可以化身为序列数据。在这里,我们展现几种常见的序列数据:
2.1 时间序列
2.1.1 二维时间序列
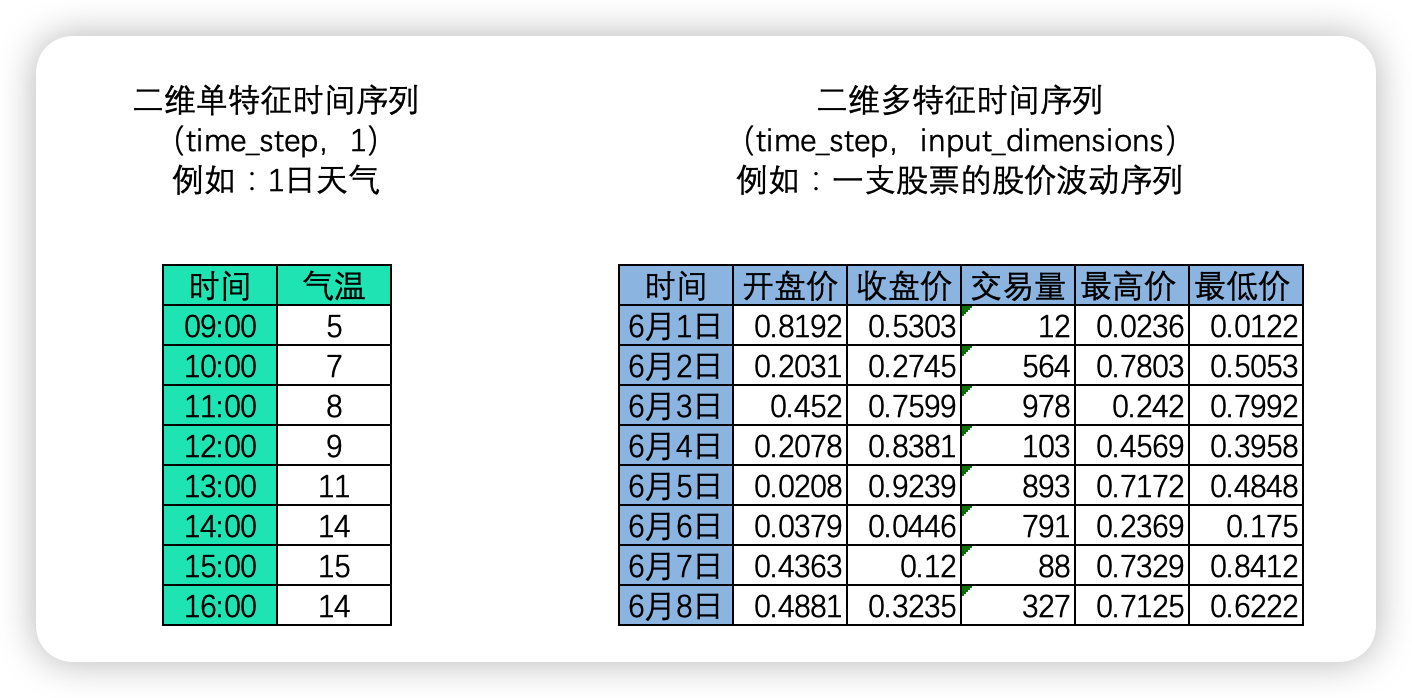
时间序列中,样本与样本之间的顺序是时间顺序,因此每个样本是一个时间点,时间顺序也就是time_step 这一维度上的顺序。这种顺序在自然语言处理领域叫做“时间步”(time_step),也被叫做“序列长度”(sequence_length),这正是我们要求算法必须去学习的顺序。在时序数据中,时间点可以是任意时间单位(分钟、小时、天),但时间点与时间点之间的间隔必须是一致的。
2.1.2 三维时间序列
在 NLP 领域中,我们常常一次性处理多个时间序列,如下图所示,我们可以一次性处理多支股票的股价波动序列——
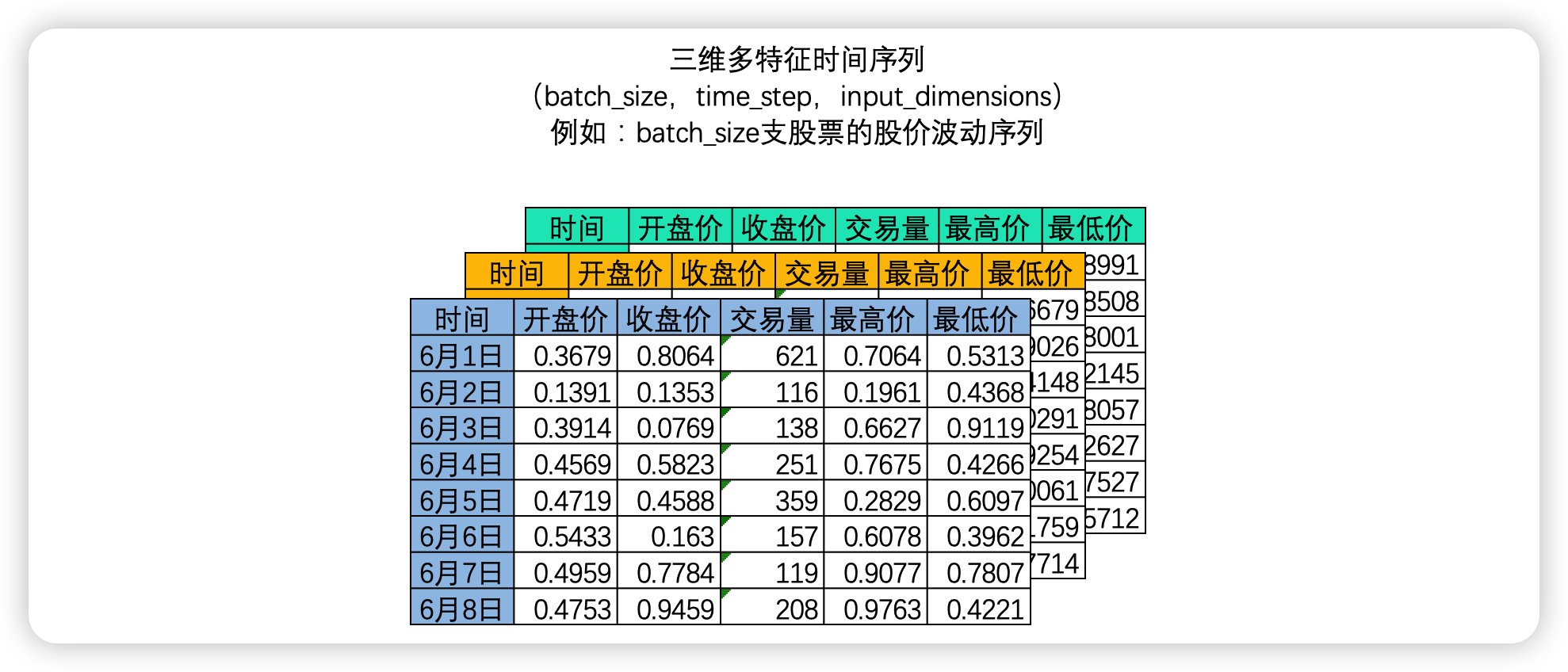
此时我们拥有的是一个三维矩阵,其中 batch_size 是样本量,也就是一共有多少个二维时间序列表单。你或许已经发现了,其实三维时间序列数据就是机器学习中定义的“多变量时间序列数据”。在多变量时间序列数据当中,时间和另一个因素共同决定唯一的特征值。在上面的例子中,每张时序二维表代表一支股票,因此在这个多变量时间序列数据中“时间”和“股票编号”共同决定了一个时间点上的值。相似的例子还可能是——不同用户在不同时间点上的行为,不同植物在不同季节时分泌的激素值、不同商家在不同时间点上的销售额等等……
2.2 文字序列
2.2.1 二维文字序列
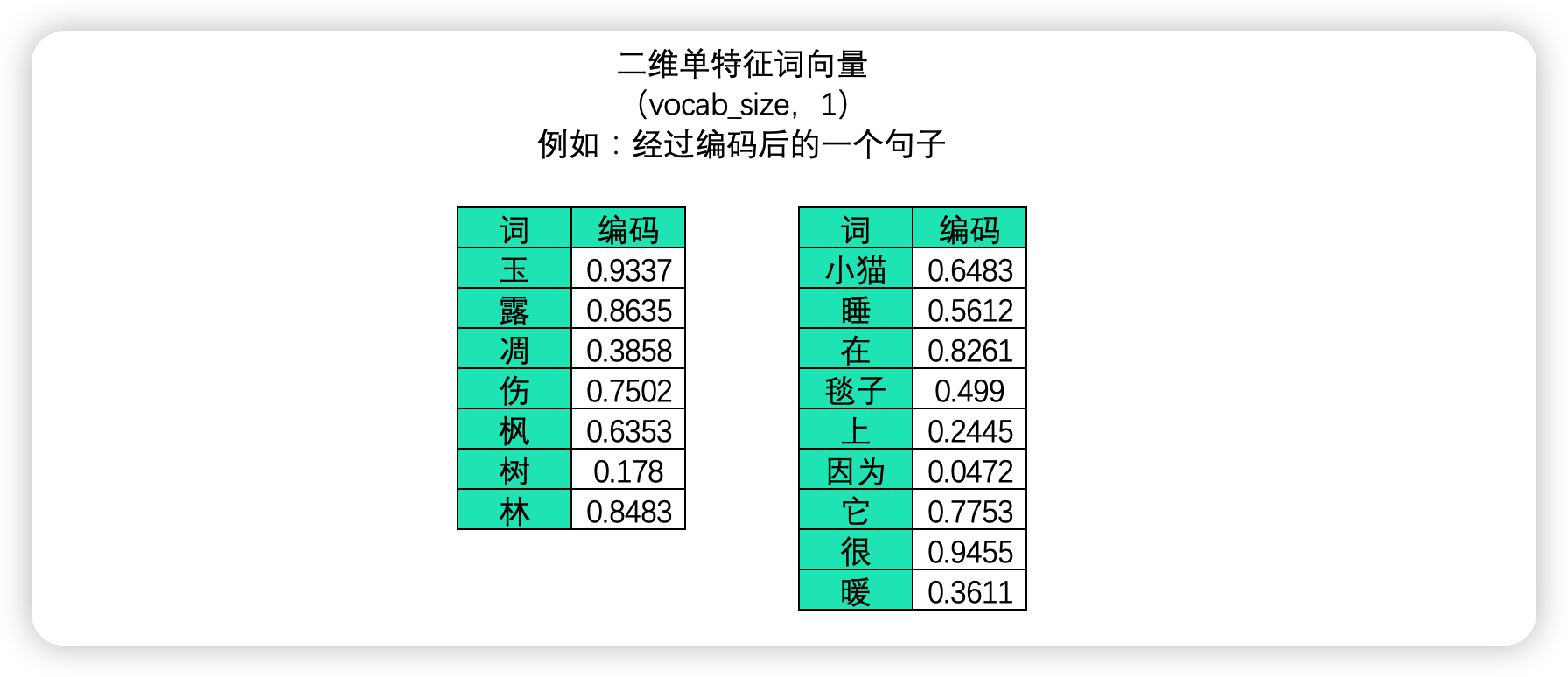
在文字数据中,样本与样本之间的联系大部分时候是词与词、字与字之间的联系,因此在文字序列中每个样本是一个单词或一个字(对英文来说大部分时候是一个单词,偶尔也可以是一个字母),故而在中文文字数据中,一张二维表往往是一个句子或一段话。此时,不能够打乱顺序的维度是 vocab_size,它代表了一个句子/一段话中的字词总数量。一个句子或一段话越长,vocab_size 也就会越大,因此这一维度的作用与时间序列中的 time_step 一致,vocab_size 在许多时候也被称之为是序列长度(sequence_length)。同样,vocab_size 这一维度上的顺序就是算法需要学习的顺序。
需要注意的是,文字序列是不能直接放入算法进行运行的,必须要要编码成数字数据才能供算法学习,因此在 NLP 领域中我们大概率会将文字数据进行编码。编码的方式有很多种,但无一例外的,文字编码的本质是用单一数字或一串数字的组合去代表某个字/词,在同一套规则下,同一个字会被编码为同样的序列或同样的数字,而使用一个数字还是一串数字则可以由算法工程师自行决定。下图是对句子分别进行 embedding 编码和独热编码后产生的二维表单:
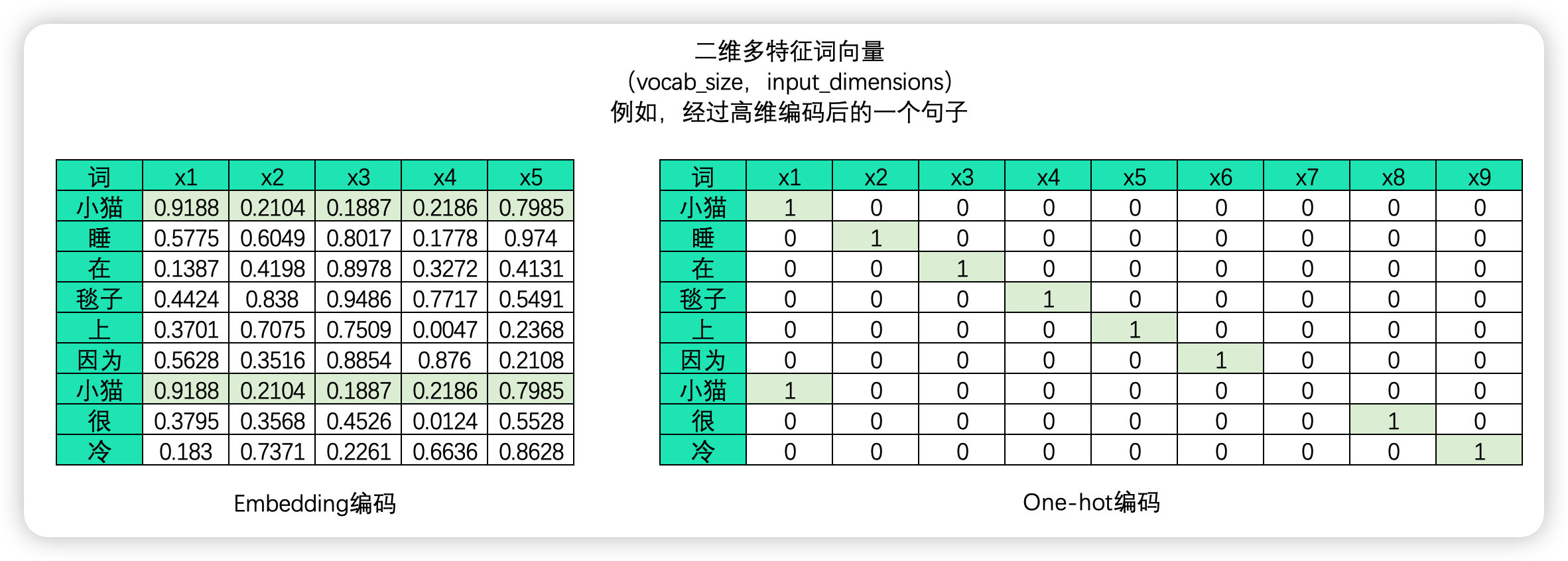
大部分时候,我们需要学习的肯定不止一个句子,当每个句子被编码成矩阵后,就会构成高维的多特征词向量。由于在实际训练时,所有句子或段落长度都一致的可能性太小(即所有句子的vocab_size 都一致的可能性太小),因此我们往往为短句子进行填充、或将长句子进行裁剪,让所有的特征词向量保持在同样的维度。
2.2.2 三维文字序列
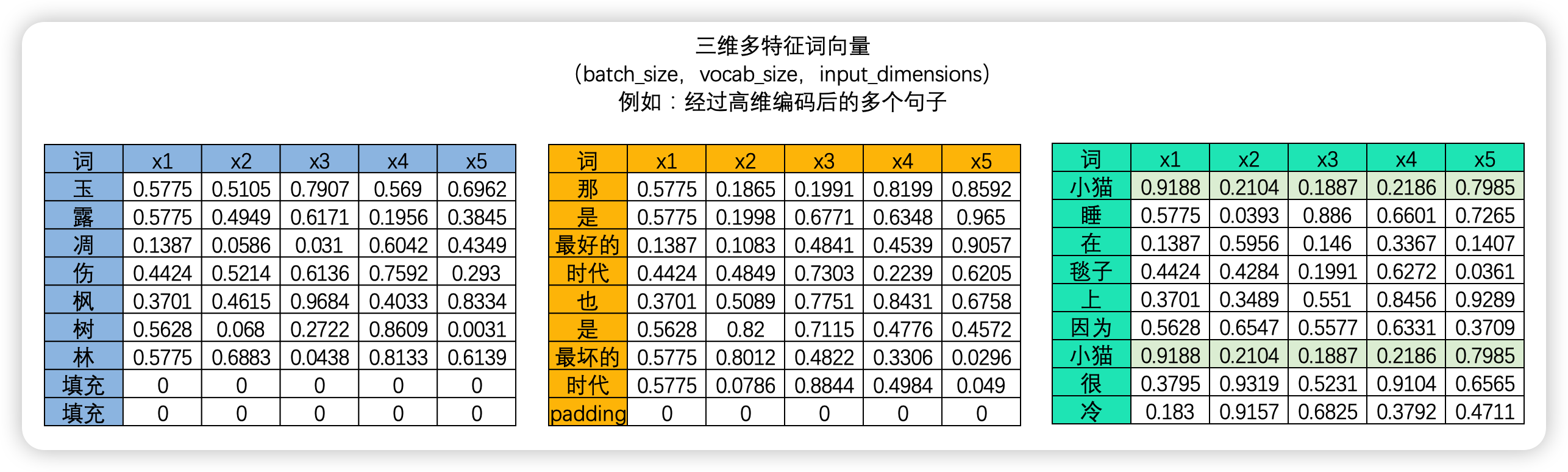
在这里限于公开课时间,我们就详细展开讲解语音数据和视频数据的状态了。但根据上面所绘制的图像,如果你层曾经学过计算机视觉、且很好地掌握了卷积神经网络,那我想你应该能够自己绘制出音频数据与视频数据的结构。
现在我们已经了解了时序数据和文本数据的一般结构,那请问循环神经网络是用于上述哪种结构的呢?
答案是,都可以!循环神经网络是深度学习中为数不多的、可以在网络架构不变的情况下、同时接受二、三维数据的网络,接下来就让我们看看循环神经网络是如何在序列数据上学习样本与样本之间的顺序的。