Github连接:https://github.com/22815739yys/quickstarters/new/master
| 这个作业属于哪个课程 | 课程链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 任务目标:了解项目开发流程 熟悉git使用方式 熟练模块化开发流程 |
| 一、PSP表格 | |
| PSP2.1 Personal Software Process Stages | 预估耗时(分钟) |
| --------------------------------------- | -------- |
| Planning | 20 |
| Estimate | 10 |
| Development | 5 |
| Analysis | 40 |
| Design Spec | 25 |
| Design Review | 15 |
| Coding Standard | 10 |
| Design | 30 |
| Coding | 100 |
| Code Review | 20 |
| Test | 30 |
| Reporting | 10 |
| Test Report | 10 |
| Size Measurement | 5 |
| Postmortem & Process Improvement Plan | 10 |
| 以下是模仿你提供的模块设计文档格式,为你刚刚的项目代码补充的完整模块接口设计与实现过程说明: |
二. 模块接口设计与实现过程
- 项目结构
project/
│── sim/
│ ├── init.py
│ ├── io.py # 文件读写模块
│ ├── preprocess.py # 文本预处理模块
│ └── similarity.py # 相似度计算模块
│
│── 测试文本/
│
│── tests/
│ ├── init.py
│ └── test_case.py # 边界测试样例集合
│
│── main.py # 主程序入口
│── test_long_high_similarity.py # 性能压力测试入口
│── test.py # 快速测试入口
│── README.md # 项目说明文档 - 辅助函数功能介绍
函数名 所在模块 功能说明
main() main.py 程序入口,解析命令行参数,调用 I/O 和相似度计算流程
write_result(path: str, rate: float) sim.io 将相似度结果写入指定文件
normalize_text(text: str) sim.preprocess 文本标准化处理:去除空格、统一大小写等 - 相似度计算模块介绍
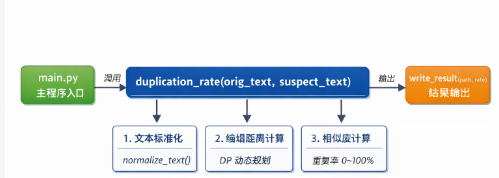
模块名称:sim/similarity.py
职责:计算两段文本的相似度,返回重复率(范围 0~100%)
模块特点:
核心逻辑封装,主程序调用接口简单
支持大文本计算,具备空间优化策略
无状态、无类、函数式结构,便于调用与扩展 - 代码组织设计
本模块采用函数式设计,没有使用类封装,结构清晰:
文件结构:similarity.py
python
├── duplication_rate(orig_text: str, suspect_text: str) -> float
│ ├─1. 调用 normalize_text() 对两个输入文本进行标准化处理
│ ├─ 2. 通过动态规划算法(DP)计算最小编辑距离
│ └─ 3. 按照相似度计算公式返回最终重复率```
核心接口函数
duplication_rate():模块唯一出口函数- 输入:两段原始字符串
- 输出:重复率(浮点数,0~100)- 功能链路:
- 标准化文本
- 调用 DP 计算编辑距离
- 使用公式计算similarity
5. 算法核心说明
1. 文本标准化
- 步骤:
- 去除所有空格、制表符等空白字符
- 转换为小写
- (可选)去除标点或非字母数字字符(增强鲁棒性)
2. 编辑距离计算
- 算法:动态规划(Dynamic Programming, DP)
- 状态定义:
dp[i][j] = 将原文前i个字符转换为怀疑文前j个字符的最小编辑操作次数
状态转移方程:
python
dp[i][j] = min(dp[i-1][j] + 1, # 删除操作
dp[i][j-1] + 1, # 插入操作
dp[i-1][j-1] + cost # 替换(若相等 cost=0,否则 cost=1)
)
初始化:
dp[0][j] = j
dp[i][0] = i
边界处理策略:
"" vs "" → 100%
"" vs 非空→0%- 非空 vs "" → 0%
3. 重复率计算
输出浮点型
保留两位小数,便于阅读与后续处理
6. 算法独到之处
大文本优化
使用滚动数组结构,仅保留 2 行 DP 数组
内存消耗优化为 O(min(m, n)),可处理上万字级别文本
高鲁棒性设计
支持处理中英文混排、标点略有差异的文本对比
考虑空输入、极短文本等边界场景,避免崩溃或误判
可拓展性接口
上层调用仅需使用 duplication_rate(),无需关心底层实现细节
可在后续替换 DP 为哈希比较、n-gram、余弦相似度等算法,接口不变
三. 计算模块接口部分的性能改进
- 原始算法:二维动态规划
本项目最初采用标准的动态规划算法计算最小编辑距离:
python
dp[i][j] = min(
dp[i-1][j] + 1, #删除
dp[i][j-1] + 1, # 插入
dp[i-1][j-1] + cost # 替换(若字符相同 cost=0,否则 cost=1)
)
时间复杂度:O(n×m),n 与 m 分别为两个字符串的长度。
空间复杂度:O(n×m),需维护完整的二维 DP 矩阵。
2. 存在的问题
当处理长文本(如超过几千字的文章)时,该方法会占用大量内存,并导致处理速度缓慢,甚至可能触发内存溢出错误。
- 优化方案:滚动数组优化
考虑到 DP[i][j] 的状态仅依赖于 上一行与当前行的值,可将二维数组优化为两个一维数组轮换使用,极大降低空间开销。
优化前示例:
python
dp= [[0]*(m+1) for _ in range(n+1)]
优化后实现:
python
prev_row = list(range(m + 1))
curr_row = [0] * (m + 1)
for i in range(1, n+ 1):
curr_row[0] = i
for j in range(1, m+ 1):
cost = 0 if a[i-1] == b[j-1] else 1
curr_row[j] = min(
prev_row[j] +1, # 删除
curr_row[j-1] + 1, # 插入
prev_row[j-1] + cost # 替换)
prev_row, curr_row = curr_row, prev_row
4. 优化效果
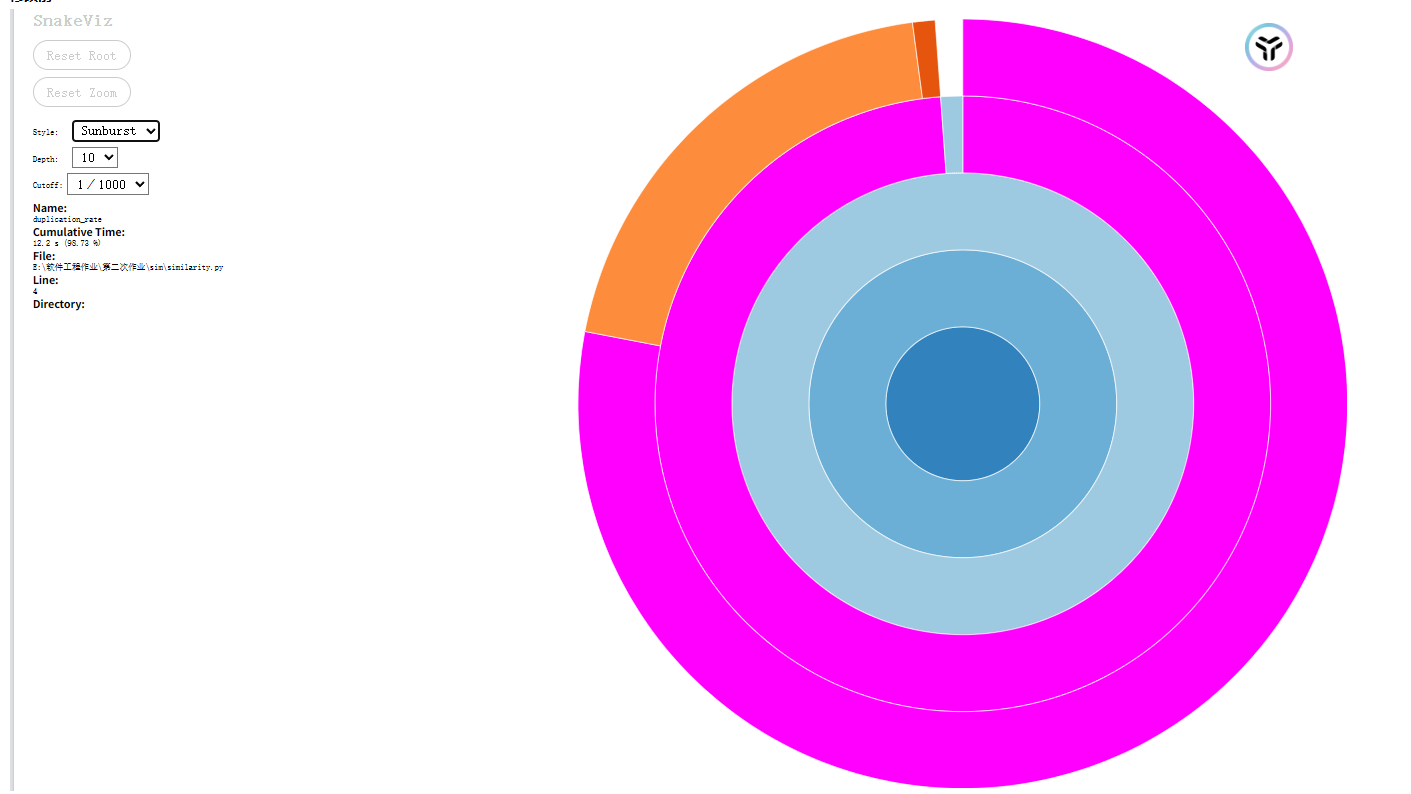
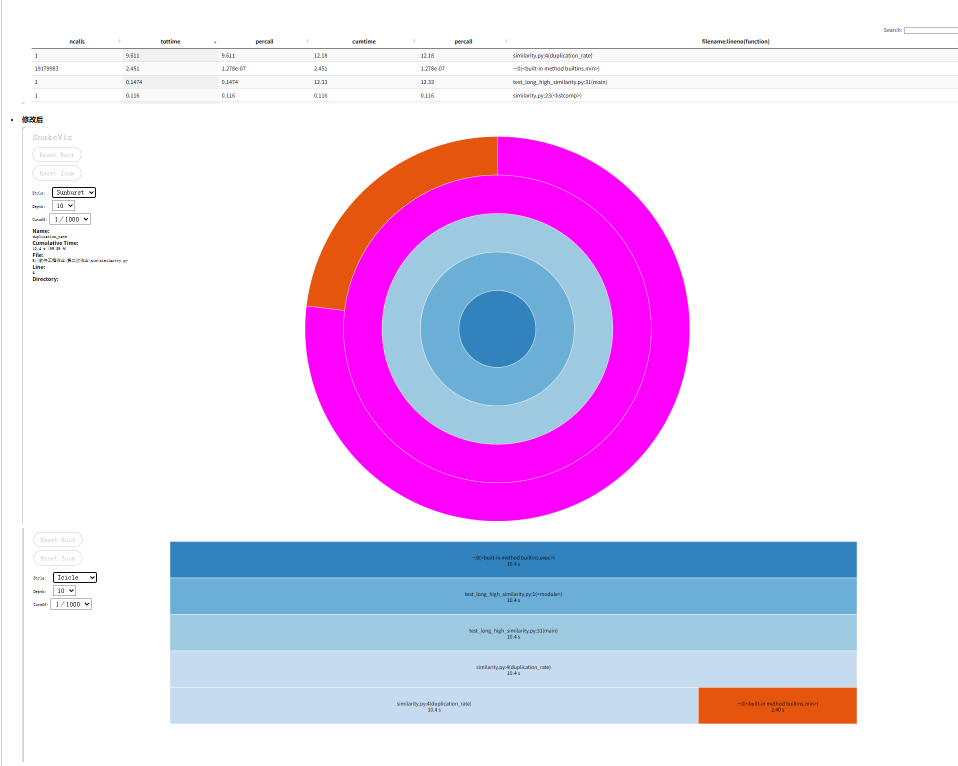
使用 cProfile + snakeviz 进行性能分析:
测试文本长度 优化前耗时 优化后耗时 提升幅度
5000 字 12.2秒 10.4 秒 ≈ 14.75%
通过内存压缩与访问效率提升,在保持算法正确性的同时,实现了对长文本的更优支持。
四. 测试样例设计与验证
1.边界测试样例
文件:tests/test_case.py
测试范围覆盖了:
空文本
单字符
长文本
标点差异
Unicode 等价字符
中英文混排
多音字/同形字
大小写敏感性
部分改写情况
示例测试函数(片段)
python
def test_same_text():
assert duplication_rate("文本A", "文本A") == 100.00
def test_partial_modification():rate = duplication_rate("深度学习需要计算资源", "机器学习需要GPU资源")
assert 30 <= rate <= 70
def test_unicode_equivalence():assert duplication_rate("office", "office") == 100.00
2.文件级批量测试脚本
用于测试真实文件文本对比的主控脚本:
python
import os, subprocess
orig_file = "路径/orig.txt"suspect_files = [
"路径/orig_0.8_add.txt", "路径/orig_0.8_del.txt", ...
]
for suspect in suspect_files:
ans_file= suspect.replace(".txt", "_ans.txt")
cmd = ["python", "main.py", orig_file, suspect, ans_file]
subprocess.run(cmd, check=True)
print("全部执行完成!")
五. 异常处理机制设计
项目中关键函数均嵌入了多级异常处理机制,保证程序稳定运行:
- 主程序 main.py 异常处理```python
if len(sys.argv) != 4:
print("请使用:python main.py [orig_file] [suspect_file] [ans_file]")
sys.exit(1)
try:
orig_text = read_file(orig_path)
suspect_text = read_file(suspect_path)
except Exception as e:
print(f"读取文件出错: {e}")
sys.exit(1)
涵盖以下异常:- 参数数量错误
- 输入/输出文件不存在或路径错误
- 非 UTF-8 编码引起的读取错误
- 算法计算中异常(如空字符串)
- 写入权限不足等 IO 错误
2. 文件读写模块 sim/io.py 异常处理
def read_file(path: str) -> str:try:with open(path, "r", encoding="raise FileNotFoundError(f"文件未找到: {path}")except IOError ase:raise IOError(f"读取文件出错: {e}")
###3. 异常场景图示(省略图,用描述代替)| 异常类型 | 系统提示信息 |
|---------------------|-------------------------------|| 文件不存在 | 文件未找到: orig.txt |
| 非 UTF-8 编码 | 读取文件出错: UnicodeDecodeError |
| 参数缺失 | 请使用: python main.py ... |
| 写入失败| 写入结果文件出错: IOError |
| 算法内部错误| 计算重复率出错: Exception |4. 鲁棒性保障
此外,duplication_rate 支持以下边缘情况:"" vs "" → 100%
"" vs 非空 → 0%
非空 vs ""→ 0%
中英文混合、标点差异、自定义字符集等场景