4.Method
图5是整体框架和流程
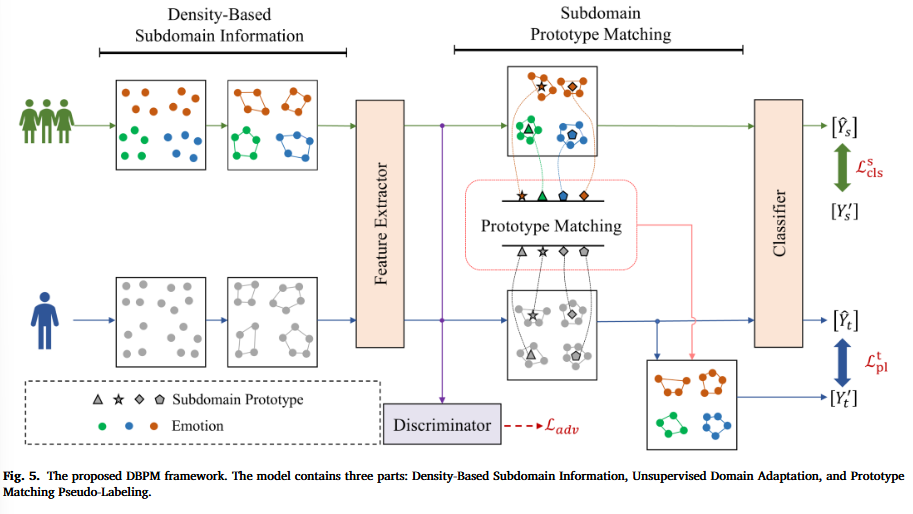
整体分析
首先上面的绿色小人表示源域数据,带有情绪标签;而下面一行的蓝色小人是目标域数据,没有标签。
-
Density-Based Subdomain Information先在每个域内部找子域结构:作者用DBSCAN在源域样本中挖掘出了若干个密度簇,这些簇就是论文中说的density-based subdomains(基于密度的子域),在目标域中,灰点表示目标域样本(无标签),同样用 DBSCAN 把目标域灰点分成若干簇(子域),在这里因为DBSCAN本来就是无监督聚类算法,不需要标签,这一步找出来了目标域的局部结构。
-
Feature Extractor + Discriminator做无监督域适配,对齐边缘分布:
源域样本和目标域样本都会进入同一个 Feature Extractor,得到特征表示为\(f(x_s)\)和\(f(x_t)\),其中Feature Extractor(特征提取器)是DANN里的一个模块;DANN 是由 Feature Extractor + 分类器 + 域判别器组成的一整套训练框架;然后是Discriminator(域判别器),它的作用是做对抗训练:让域判别器分不出这是源域还是目标域,从而逼迫 Feature Extractor 学到更域不变的特征,这两部分解决的是边缘分布差异,让源/目标在特征分布上更接近。
关于Feature Extractor和Discriminator的关系:D 用 F 的输出当输入,先用 F 把输入样本 (x) 编码成特征,D 接收这个特征 (z),去判断它来自哪个域(源域 or 目标域)。F要让 D 分不出来(让源/目标特征变得像)即“最大化”这个域判别损失,而D想让域分类正确,所以要最小化域判别损失,所以二者是一个 min-max 对抗。因此训练时两者“斗法”:D 越聪明,F 就要学得更会隐藏域差异;最终逼出“更域不变”的特征
- Subdomain Prototype Matching算子域原型并匹配:对每一个子域簇\(C_k\),计算出一个代表,这个代表就是原型,即簇内特征均值向量:
这样源域有一组子域原型;目标域也有一组子域原型
然后进行原型匹配(Prototype Matching),得到簇的伪标签(通常是距离最近/相似度最高),然后把这个簇的伪标签传播到簇内所有标签(cluster-wise),这样目标域的每一个子域决定好了一个情绪类别(该子域的伪标签)。
- Classifier用真标签监督源域,用伪标签监督目标域:Classifier分类器产生源域预测\([\hat{Y}_s]\),目标域预测\([\hat{Y}_t]\),在源域中用真实标签\([Y_s]\)去监督\([\hat{Y}_s]\),得到普通交叉熵分类训练\(\mathcal{L}_{\mathrm{cls}}^{s}\),然后利用原型匹配得到的伪标签\([Y_t]\)去监督\([\hat{Y}_t]\),同样得到交叉熵\(\mathcal{L}_{\mathrm{pl}}^{t}\),但是标签是伪的
4.1. Problem formulation问题形式化
整体问题为跨被试EEG情绪识别=UDA,因为把“新被试”看成一个新的数据域(domain),而我们没有这个新被试的标签,只能用别的被试(有标签)的数据去适配它。这正好符合 无监督领域自适应(UDA) 的定义。
将每一个被试看作为一个源域,所以多个被试代表整体任务为多源域策略,EEG 的个体差异很大,把每个人看成一个域更符合真实情况,并且后面“子域/原型”也更容易解释为“每个个体内部的分布结构”
模型组件为F+H+D,即特征提取器、分类器、域判别器
4.2 Density-based subdomain information 基于密度的子域信息
子域的划分用DBSCAN密度聚类算法,因为抗噪声:EEG 噪声大,DBSCAN 可以把离群点当 noise;不需要预设簇数:每个被试/每种状态的团块数量不固定;簇形状任意:EEG 特征团块可能不是圆形高斯团,DBSCAN 更灵活,而且这个划分过程要在靠近原始信号(或浅层特征)上做DBSCAN,因此此时的子域密度可分性更强。
4.3. Unsupervised domain adaptation无监督域适配
在定义ig.5 中间的“Feature Extractor + Discriminator + (L_{adv})”模块,主要想解决的就是“个体差异 = 域差异”问题,因为跨被试时,EEG 的分布差异很大,模型容易学到“某个人的特征”,而不是“情绪的特征”。域对抗的目的就是:去掉“人/域”的特征,让特征更通用。
而DANN的对抗训练就是:
- 对判别器:最小化这个域分类损失(分得越准越好)
- 对 特征提取器:反过来最大化它(让它分不出来) 直观来说就是让域不可分,主要解决了边缘分布,让源/目标的特征分布更接近
4.4 Subdomain prototype matching子域原型匹配
DANN只能进行粗对齐,他能做到的是让源/目标整体特征像,整体相似之后,具体的不同情绪类别可能还会有错位,简单的说就是要让细粒度对齐,按子域/簇来对齐情绪结构。具体的过程就是跟前面描述fig5的内容一样。
一句话总结为:DANN 负责“让源/目标特征空间整体变近”;子域原型匹配负责“让目标域的子域按情绪类别对齐到源域子域”,并以簇级方式生成伪标签。
4.5 Target pseudo-label loss 目标域伪标签损失
这一段就是又具体讲了一下损失,也说明了训练数据从哪里来:训练时同时用:源域样本,带真标签;目标域样本,配伪标签

混合源域自适应的预训练算法:在正式做子域原型匹配/伪标签之前,先用多源(多个被试)+ 目标域无标签做一轮 DANN 风格的预训练,把特征空间先对齐到一个比较可迁移的状态。
Input:训练轮数、K个源被试数据集(每个被试一个源域,带标签)、目标被试数据集(无标签)
Output:预训练后的模型参数,也就是 Feature Extractor、Classifier、Discriminator 都先训练到一个初始较好的状态。
1:合并多源域,先把所有有标签的源数据合在一起做监督训练。
2:按 epoch 循环
3:repeat(通常意味着遍历完一个 epoch 的数据)
4:从统一源域采一个 mini-batch
5:从目标域采一个 mini-batch
6:算源域分类损失
7:算域对抗/域对齐损失
8:算预训练总损失
9:更新模型参数,用梯度下降更新,实现上判别器和特征提取器的目标相反,但通过 GRL 可以写成统一“minimize”的形式
10:直到源域样本都处理完
11:end for结束预训练
4.6Learning with multi-source多源学习
问题所在:训练早期源/目标差异大 → 原型匹配 + 伪标签传播不可靠 → 错误会累积、影响收敛
分为两阶段学习框架:
1.mixed-source pretraining(混合源域预训练):先把特征空间对齐得“可用、稳定”
2.sequential multi-source training(顺序多源训练):再逐个源域与目标对齐,做更精细的原型匹配与伪标签学习
其中4.5的Algorithm1就是4.6的第一个阶段:用源域真标签先把“情绪分类能力”打牢,同时做域对抗让目标域特征先粗对齐,最后先得到一个比较稳定的特征空间初始化,为后面的原型匹配做准备。
但是混合源域不适合做原型匹配,不同源被试相对目标被试会有不同的偏差,比如:
- 源1可能和目标更像
- 源2可能差异很大
- 源3在某些情绪上更接近
如果把源1/2/3混在一起算原型或做匹配: - 原型会被“平均化”
- 掩盖了“哪个源域更接近目标”的结构
- 容易导致匹配错、伪标签不可靠
因此在做原型匹配时,使用顺序多源训练的思想:一次只拿一个源域(一个被试)与目标域对齐 + 做一对一原型匹配:
- 更精确地处理“源k ↔ 目标”的差异
- 更利于条件分布(类别结构)的细粒度对齐
- 原型匹配更可信

Algorithm2就是论文训练的核心:顺序多源训练+子域原型匹配生成伪标签 + 用三种损失联合更新,整体过程就是:每个epoch只选一个源被试域来和目标域进行对齐,先在这对(源k + 目标)上做 DBSCAN 子域划分 → 计算子域原型 → 原型匹配生成目标伪标签,然后用:

来更新网络,下个 epoch 换另一个源域,如此循环
逐行解释 Algorithm 2
input:epoch 数 (E),源被试数据集集合,目标被试数据
output:训练好的 DBPM 模型
1.用预训练模型初始化
2.for e = 1 to E do
3.选择“当前源域” e=1用源域1,e=2用源域2... 这就是“顺序多源”:一次只对齐一个源域,避免混合源域掩盖差异
4.对当前源域 + 目标域提取子域信息并算原型 在4.2和4.4中有定义
5.用原型匹配生成目标域伪标签
6.repeat(开始一个 epoch 内的 mini-batch 训练)
7.取源域 k 的一个 mini-batch
8.取目标域一个 mini-batch(带伪标签)
9-12 计算三种损失(对应 4.3 和 4.5) 域对抗损失(源k vs 目标);源域k 的真标签分类损失;目标域伪标签分类损失
13.更新参数
14.直到两个域的数据都处理完
15.end for(下一 epoch 换下一个源域)
5.Experiment
5.1. Emotional databases
实验使用了两个数据集:SEED和 SEED-IV
SEED 数据集包含 15 名被试的 EEG 数据,每名被试在不同时间参与了 3 次实验(3 个 session)。在每次 session 中,被试观看 15 段电影片段。每段片段开始前有 5 秒提示阶段(cue phase),片段结束后有 45 秒自评阶段(self-assessment phase),片段之间有 15 秒休息时间。三个 session 使用相同的电影片段,以诱发三种情绪状态:消极(negative)、中性(neutral)和积极(positive)。
SEED-IV 数据集同样包含 15 名被试的 EEG 数据,实验在 3 个不同日期进行,每天 1 次 session。在每次 session 中,被试观看 24 段不同的电影片段,用于诱发四种情绪状态:快乐(happiness)、悲伤(sadness)、恐惧(fear)和中性(neutrality)。与 SEED 不同的是,SEED-IV 的电影片段在不同 session/实验之间并不相同。两个数据集的 EEG 信号都使用 62 通道的 ESI Neuroscan 系统记录。
为与先前研究进行公平对比,两个数据集采用相同的预处理步骤。首先,将采样率下采样到 200 Hz,并使用带通滤波保留 0.3 Hz 到 50 Hz 的频率成分。在 SEED 数据集中,每个 trial 被分割为不重叠的 1 秒片段;而在 SEED-IV 数据集中,每个 trial 被分割为不重叠的 4 秒片段。每个片段都被视为一个用于模型训练的样本。接着,从五个预定义频带提取差分熵(Differential Entropy, DE)特征:Delta(1–3 Hz)、Theta(4–7 Hz)、Alpha(8–13 Hz)、Beta(14–30 Hz)和 Gamma(31–50 Hz)。对每个频带,将 62 个值(对应 62 个 EEG 通道)拼接起来,得到一个 310 维的特征向量。
在 SEED 数据集中,每个 session 包含 3394 个样本。对于 SEED-IV 数据集,三个 session 分别包含 851、832 和 822 个样本。
SEED原始采集得到的是多通道时间序列EEG(矩阵/3D向量),只是这篇论文把它预处理并提取成为DE特征向量(5个频带,每个频带62个通道)来训练,所以是向量化(展开后为310dimension)之后的结果。
5.2. Experiment settings
主要是特征提取器、域判别器、分类器的参数设置
首先:特征提取器、域判别器 和分类器都使用带ReLU激活函数的多层感知机(MLP)实现
- 特征提取器的结构设计为:310(输入层)– 64(隐藏层1)– ReLU 激活 – 64(隐藏层2)– ReLU 激活
- 域判别器的结构设计为:64(输入层)– 64(隐藏层1)– ReLU 激活 – dropout 层 – 1(输出层)– Sigmoid 激活
- 分类器的结构设计为:64(输入层)– 32(隐藏层1)– 64(隐藏层2)– (C)(输出层)
此外:使用 RMSprop 优化器更新参数;SEED 数据集的学习率为5e-5,SEED-IV 数据集为1e-3;batch size 设为 96;最大训练 epoch 为 1000;预训练 epoch 数设为 14;公式(7)中的超参数设为0.011,所有实验在一块 NVIDIA GeForce RTX 5070 Ti GPU 上进行,CUDA 版本为 12.8。


5.3Experiment protocols
在本文中,我们在两个数据集上开展跨被试实验,以评估 DBPM 的性能。为与先前研究保持一致,我们在跨被试实验中采用留一被试法(Leave-One-Subject-Out,LOSO)的交叉验证策略。具体来说,将某一名被试的样本用于测试,而其他被试的样本用于训练。我们在 SEED 和 SEED-IV 两个数据集的三个 session 上都进行了实验。在这些实验中,模型性能以准确率(accuracy)作为评估指标。
5.4 result
表1是作者在 SEED 和 SEED‑IV 两个数据集上做的 跨被试(cross-subject)情绪识别实验的结果,用来对比 DBPM 和一系列已有方法的性能。在这个跨被试实验里,训练用的数据和测试用的数据都来自同一个数据集(SEED或SEED-IV),只是按 被试(subject) 划分成源域/目标域;并且对 DBPM 这类 UDA 方法,还会把目标域数据在训练阶段以“无标签”的方式用来做自适应。
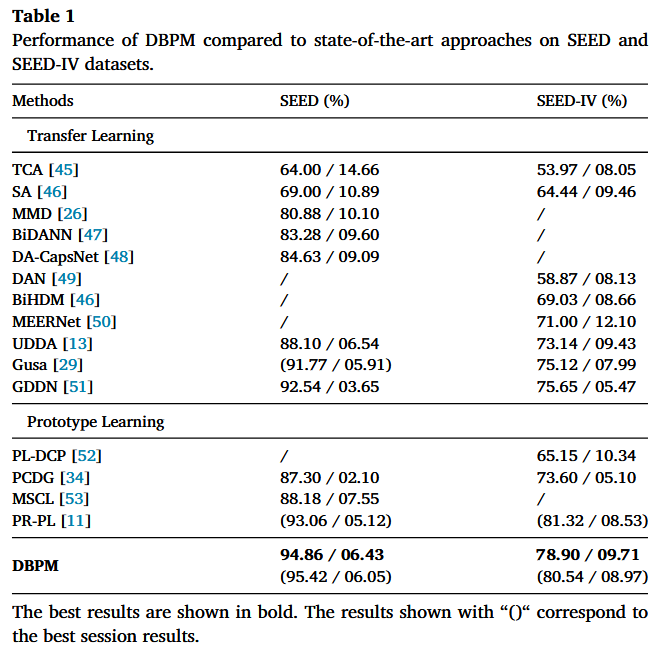
SEED数据集结果
分析:传统浅层迁移(TCA/SA)很低且方差大:说明跨被试差异大,浅层对齐不够。深度 UDA(BiDANN、DA‑CapsNet、UDDA、GDDN)明显更好,并且 std 逐渐变小,说明更稳。在 transfer learning 组里:最佳均值是 GDDN:92.54;
分析:Prototype learning 这组在 SEED 上能做到 93 左右(PR‑PL),已经接近/超过很多 transfer learning 方法,说明“原型/度量学习”在 EEG 情绪识别里确实有效。

分析:相比 transfer learning 里最强的 GDDN(92.54):提升 = 94.86 − 92.54 = 2.32 个百分点;相比 prototype learning 里最强的 PR‑PL(93.06):提升 = 1.80 个百分点
关于std:DBPM 的 std(6.43)并不算最小(GDDN 3.65 更稳),这意味着DBPM 平均更高,但跨 fold/subject 的波动仍存在;这也可能与伪标签策略、DBSCAN 聚类超参敏感等因素有关。
SEED-IV数据集结果
注意:SEED‑IV 更难(4 类、刺激片段跨 session 变化),所以整体准确率更低、std 往往更大。
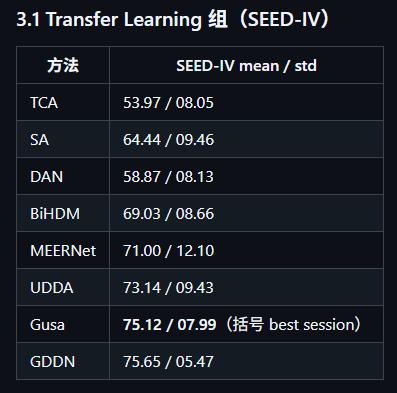
分析:迁移学习里最强均值是 GDDN:75.65;std 普遍比 SEED 更大(比如 MEERNet 12.10),符合“任务更难、更不稳定”。
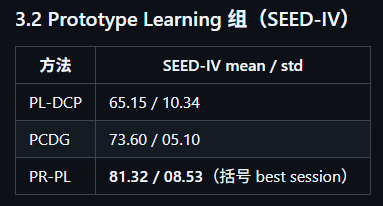
分析:????PR‑PL 在 SEED‑IV 上的 best session 达到 81.32,看起来非常强(甚至高于 DBPM 的均值)。但它没有给出非括号的“全 session 平均”结果(该格显示为 /),所以你不能直接拿它和 DBPM 的均值公平比较

分析:相比 transfer learning 最强 GDDN(75.65),提升 = 78.90 − 75.65 = 3.25 个百分点。
为什么 DBPM 在每个数据集下面会出现“两行/两个结果”?
不带括号的数:在 三个 session 的整体设置下得到的结果(通常是对三次 session 的 LOSO 结果做汇总后的 mean / std)
带括号的数:即 最佳单个 session 的结果(在 session1/2/3 里挑出表现最好的一次,再报告该 session 下的 mean / std)。
PR‑PL 在 SEED‑IV 这一列只给了括号里的“best session”结果,没有给不带括号的“总体结果”,因此要对比也只能对比最好的结果,而不是PR-PL的最好结果去对比DBPM的平均结果
--------------------------------------------------------------------------------------
表2的内容分析:
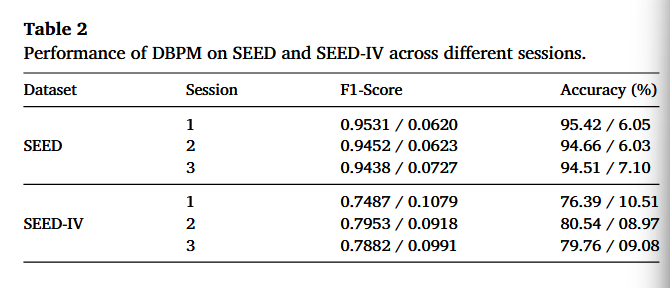
session基本可以理解为同一被试在不同时间(不同天/不同轮次)完成的一次完整实验记录,所以在SEED中的session就是每个被试做 3 个 session,这 3 个 session 在不同时间进行;每个 session里,被试观看 15 个电影片段(每个片段引发负/中/正之一);而且 三个 session 用的是同一组电影片段(为了控制刺激一致性)
对表2的质疑:作者的意思是说表2的目的是证明DBPM自己在不同session上的表现稳定、且F1与Accuracy一致,但是我认为table中没有与其他模型进行对比(即没有横向对比)
然后表2的准确率是:在 跨被试(LOSO)设置下,对某一个 session 的数据做情绪分类时得到的 分类准确率。
--------------------------------------------------------------------------------------
混淆矩阵:行:真实类别(Ground Truth);列:预测类别(Predicted);矩阵中的元素 M_ij 表示:真实类别是i的样本中,有多少被预测成了j。对角线M_ii:预测正确的数量(越大越好);非对角线M_ij:把i误判成j的数量(错误类型)
图6+图7
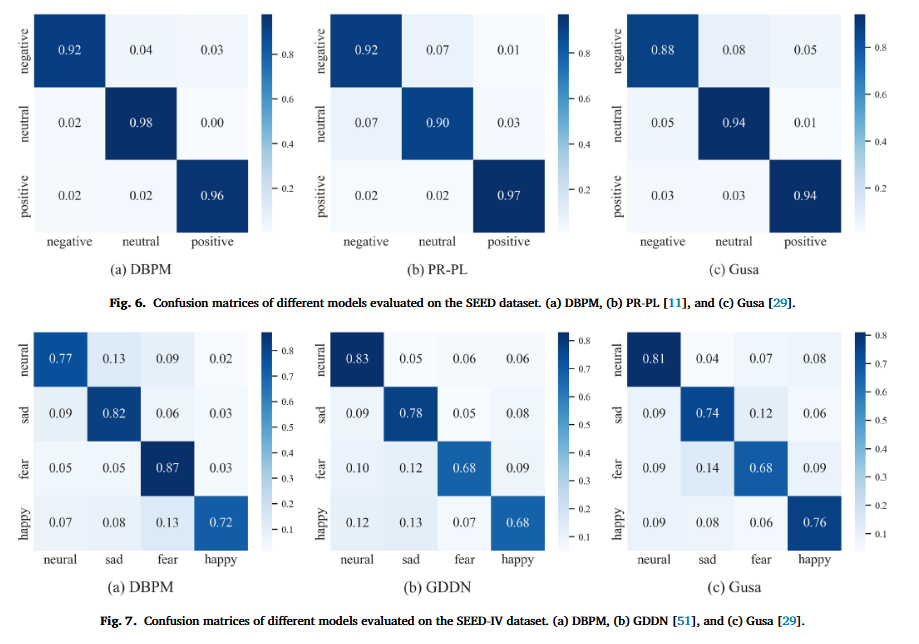
结果简单分析:DBPM在SEED的中性识别非常准确,并且减少了neutral↔negative 的互相错分;DBPM在SEED-IV在fear和sad这类更难/更极端的类别上识别准确率比其他的方法要好,但在 neutral、happy 上未必全面碾压(甚至略低)。
6. Disscusion
6.1. Ablation study
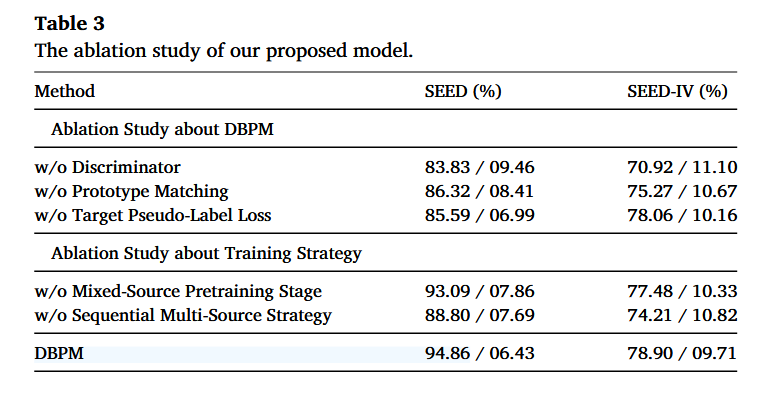
消融实验从两部分展开:1)关于 DBPM 组件的消融(Ablation Study about DBPM)2)关于训练策略的消融(Ablation Study about Training Strategy)
-
1)关于 DBPM 组件的消融(Ablation Study about DBPM)
①:w/o Discriminator(去掉域判别器/对抗对齐),没有域对齐后性能大幅下降,说明域判别器对缓解跨被试差异非常关键
②:w/o Prototype Matching(去掉原型匹配),原型匹配将源域的标签信息以伪标签形式迁移到目标域,如果改为直接使用模型输出作为伪标签,模型性能会下降。
③:w/o Target Pseudo-label Loss(去掉目标域伪标签损失),伪标签监督对 SEED 提升很明显;对 SEED-IV 提升较小(去掉后只小幅下降) -
2)关于训练策略的消融(Ablation Study about Training Strategy)
这部分研究“训练流程设计”带来的增益,
①w/o Mixed-Source Pretraining Stage(去掉混合源域预训练阶段),混合源域预训练能带来稳定增益,但不是最关键的那一个模块。

②w/o Sequential Multi-Source Strategy(去掉顺序多源策略),顺序多源训练对性能贡献很大,去掉后掉得明显

与SEED-IV相比,SEED数据集从原型匹配中获益更多,鉴于原型匹配需要稳定的分布对齐,这表明其有效性依赖于基线(baseline)的可靠性,