re库使用教程
在学习使用re库之前,需要先了解正则表达式的基础规则,然后再学习re库的各接口使用
正则表达式基础规则
字符匹配
. # 匹配任意单个字符,默认不匹配换行符,除非标志位有re.S支持匹配所有的单个字符
\w # 匹配任意字母、数字或下划线,等价于[0-9A-Za-z_]
\W # 匹配任意非字母数字下划线字符,等价于[^a-zA-Z0-9_]
\d # 匹配任意数字,等价于[0-9]
\D # 匹配任意非数字,等价于[^0-9]
\s # 匹配任意空白字符,包括空格、制表符\t、换行符\n等
\S # 匹配任意非空白字符,等价于[^\t\n\r\f\v]
[abc] # 匹配括号内任意字符
[^abc] # 匹配不在括号内的任意字符
[a-z] # 匹配范围内的任意字符
锚点
^ # 匹配字符串的开头,多行模式下匹配每一行的开头, ^world
$ # 匹配字符串的结尾,多行模式下匹配每一行的结尾, world$
\b # 匹配单词边界,单词与非单词字符之间的位置
\B # 匹配非单词边界
量词
* # 匹配字符或者子模式0次或多次
+ # 匹配字符或者子模式1次或多次
? # 匹配字符或者子模式0次或多次
{n} # 匹配字符或者子模式恰好n次
{n,} # 匹配字符或者子模式至少n次
{n,m} # 匹配字符或者子模式至少n次,最多m次
*? # 尽可能少的匹配字符
+?
??
分组或引用
(...) # 括号内表达式分组,捕获匹配的内容, (ab)+匹配abab
\1 # 匹配前面捕获的分组内容
\2 # 匹配前面捕获的分组内容
(?:..) # 非捕获式匹配,不保存分组内容
` # 匹配多个模式中的任意1个
其它特殊符号
\ # 转义字符,\.意味着只匹配.
条件判断
ret=None
if not ret:print('hello') # 此时会走到这个分支
if type(ret) is not list:print('var ret is not list type')
函数嵌套
print('hello')
def hi():print('name')def happy(func): # 支持使用func代替要传入的函数对象print('appache')func()happy(hi)
re库正则表达式
re库支持正则表达式,兼容perl的正则表达式
match接口
从起始位置开始匹配,匹配成功返回匹配的对象,否则返回None
re.match(pattern, string, flags=0)
re.match(pattern, string).span() # 返回匹配到的跨度范围(start, end)
search接口
从整个字符串内容中搜寻匹配样式的字符串,并返回第1个成功的匹配,匹配不成功返回None
re.search(pattern, string, flags=0)
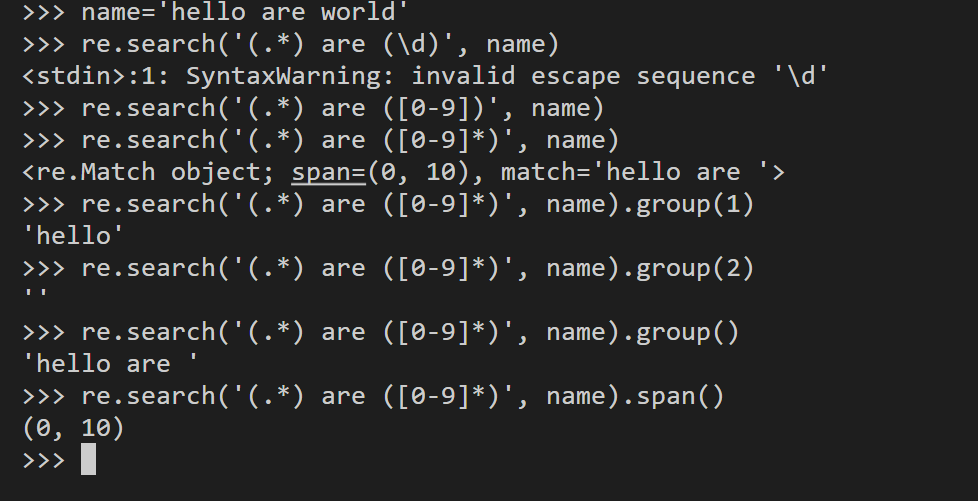
name='hello are world'
obj=re.search('(.*) are ([0-9]*))', name) # 返回匹配对象
obj=re.search(r'(.*) are (\d*))', name)
obj.group() # 显示所有匹配的元素
obj.group(1) # 显示第1个匹配组的元素
obj.group(2) # 显示第2个匹配组的元素
sub替换接口
替换字符串中的匹配项
re.sub(pattern, repl, string, count=0, flags=0)
# repl要替换成的字符串(或者函数),string原始的字符串, count=0代表替换所有匹配
compile编译接口
用于编译正则表达式,生成一个正则表达式对象,可以给match、search、findall函数使用
pattern=re.compile(pattern[, flags])
pattern.match('ssahdiashdi', 3, 10) # 从第3个字符到第10个字符之间匹配
pattern.findall('sssssasdada') # 找到所有的匹配,返回列表
split划分接口
re.split(pattern, string[, maxsplit=0, flags=0]) # maxsplit指定划分次数,如果设置为0,代表不限制次数
标志位
# 可选的flags是如下
re.I # 忽略大小写
re.L # 表示特殊字符集
re.M # ^和$默认只匹配字符串的开头和结尾,不会进行多行的开头和结尾匹配
re.S # 使.匹配所有字符,默认.不匹配换行符
re.x # 允许正则表达式中包含空白字符和注释
re.U # 启用unicode模式,匹配unicode字符
re.A # 只匹配ASCII字符
re.A | re.I # 组合标志位