微调完怎么判断好不好?大模型效果评估入门指南(附代码)

(一)引言:微调评估不是“算个数”,是模型落地的关键一步
大家好,我是七七!每天都能看到一堆新手提问,核心就一个:“博主,我把7B模型微调完了,准确率82%,这效果算合格吗?”“生成任务怎么判断模型调得好不好,总不能凭感觉吧?”
其实这也是我刚入门时踩过的坑——当时对着微调完的模型,只知道算个准确率就交差,结果落地到业务场景才发现,要么“指标好看但用不了”(比如生成文本BLEU值高却逻辑混乱),要么“漏判关键样本”(比如垃圾邮件识别召回率太低)。后来才明白,大模型微调评估从来不是“单一指标定生死”,而是要结合任务类型、业务需求,用科学的方法验证效果。
今天这篇文章,就带新手朋友从0到1搞懂大模型微调效果评估:拆解不同任务的核心指标,附Python实操代码(复制就能跑),再教大家怎么结合场景判断效果,避开90%新手会踩的坑。不管你做文本分类、文本生成还是语言建模,都能直接套用这套方法。
(二)技术原理:不同任务的核心评估指标拆解
大模型微调任务主要分三类:文本分类(如垃圾邮件识别、情感分析)、文本生成(如摘要、对话、翻译)、语言建模(如续写、补全)。不同任务的评估逻辑完全不同,我们逐个拆解核心指标,用“案例+通俗解释”讲透,新手也能秒懂。
1. 文本分类任务:准确率、精确率、召回率、F1值
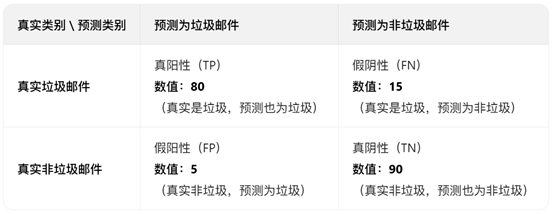
这类任务的核心是“给文本贴标签”,评估的是模型“分类准不准”,最常用的就是这四个指标。我们以“垃圾邮件识别”为例(标签:垃圾邮件/正常邮件),逐个解释:
• 准确率(Accuracy):所有样本中分类正确的比例,相当于“考试总分率”。公式:(正确识别的垃圾邮件+正确识别的正常邮件)/ 总邮件数。
•
• 适用场景:样本分布均衡(比如垃圾邮件和正常邮件各占50%),追求整体分类正确率。
•
• 坑点:样本不均衡时失效!比如垃圾邮件只占10%,模型全预测为正常邮件,准确率也能到90%,但完全没用。
• 精确率(Precision):模型预测为“垃圾邮件”的样本中,真正是垃圾邮件的比例,相当于“预测对的垃圾邮件纯度”。公式:正确识别的垃圾邮件 / 模型预测为垃圾邮件的总数量。
•
• 适用场景:怕误判的场景(比如重要邮件不能被误判为垃圾邮件),优先保证“预测对的都是真的”。
• 召回率(Recall):所有真实垃圾邮件中,被模型正确识别的比例,相当于“垃圾邮件的捕捉率”。公式:正确识别的垃圾邮件 / 真实存在的垃圾邮件总数量。
•
• 适用场景:怕漏判的场景(比如诈骗邮件不能漏判),优先保证“该抓的都抓到”。
• F1值:精确率和召回率的调和平均数,解决“精确率和召回率矛盾”的问题(比如精确率高则召回率低,反之亦然),综合反映分类效果。
• 适用场景:大多数分类任务的核心评估指标,尤其样本不均衡时,比准确率更靠谱。
一句话总结:准确率看整体,精确率防误判,召回率防漏判,F1值看综合,优先选F1值作为核心指标。
2. 文本生成任务:BLEU、ROUGE、人工评估
这类任务的核心是“生成符合要求的文本”,评估的是“生成内容与参考内容的一致性、流畅度”,自动指标+人工评估结合才靠谱。
• BLEU值(双语评估替补):衡量生成文本与参考文本的“n-gram重叠度”(简单说就是用词、短语的重合率),取值0-1,越接近1效果越好。
•
• 适用场景:机器翻译、摘要生成等有明确参考文本的任务。
• 坑点:只看重叠度,忽略语义和流畅度!比如生成文本和参考文本用词完全一样,但语序混乱,BLEU值也会很高,需结合人工判断。
• ROUGE值(召回导向的评估指标):和BLEU类似,但从“召回率”角度计算重叠度,常用ROUGE-L(基于最长公共子序列,更贴合语义)。
•
• 适用场景:摘要生成、文本续写,更关注“生成内容是否覆盖参考文本的核心信息”。
• 人工评估:自动指标的补充,尤其生成对话、创意文本时(无固定参考),需制定评分标准,从“流畅度、逻辑性、相关性、准确性”四个维度打分(1-5分)。
一句话总结:BLEU看重叠度,ROUGE看信息覆盖,人工评估定体验,三者结合才能全面判断生成效果。
3. 语言建模任务:困惑度(PPL)
这类任务的核心是“预测下一个词的概率”(如文本续写、补全),评估的是模型“对语言规律的掌握程度”,核心指标是困惑度。
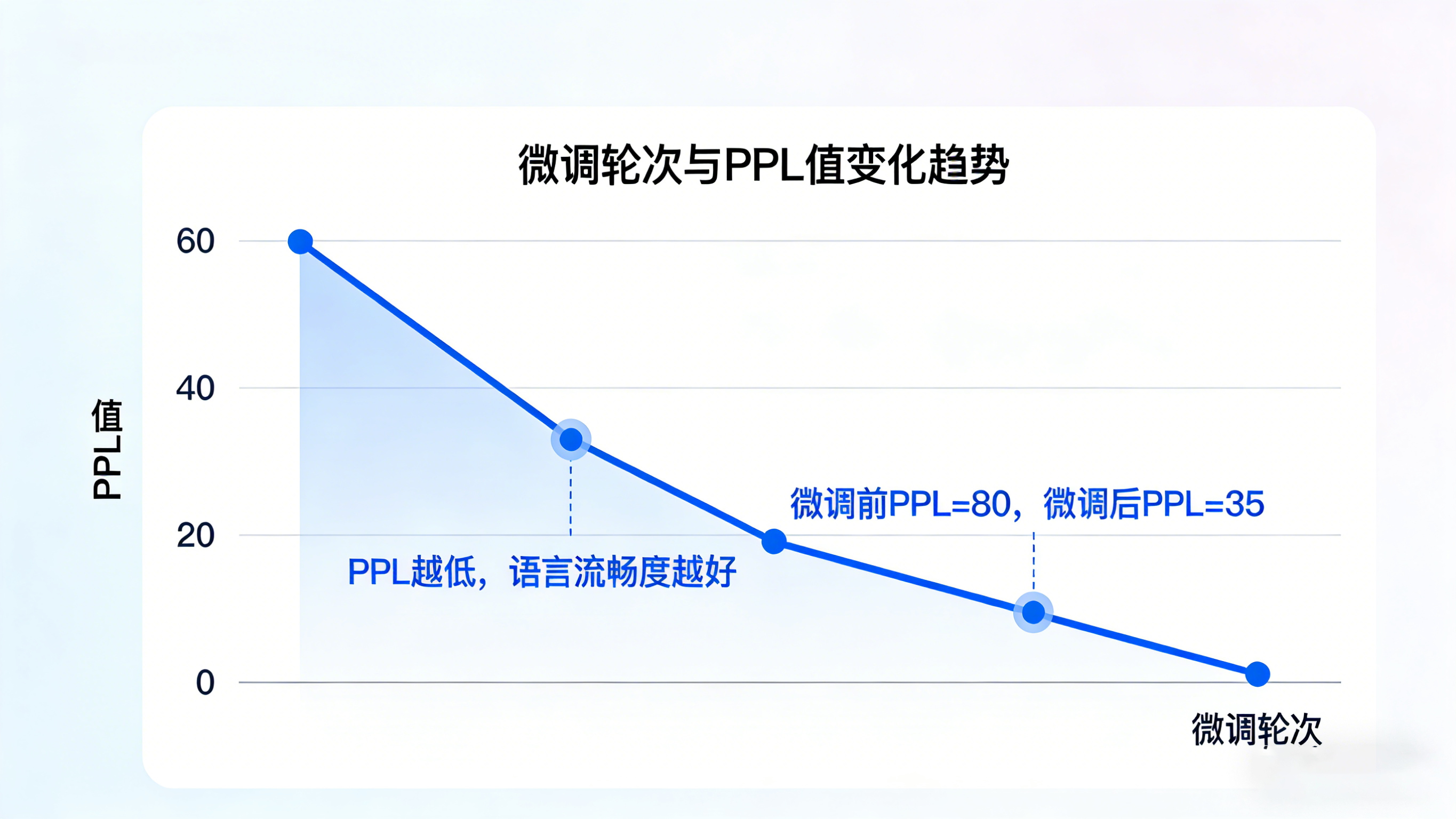
困惑度(Perplexity,PPL):通俗说就是“模型对文本的困惑程度”,PPL值越低,说明模型越能准确预测下一个词,对语言的理解越透彻。
适用场景:文本续写、语言生成预训练微调后的效果评估。
注意:PPL值仅反映语言流畅度,不代表内容相关性,比如模型能生成流畅的句子,但和上下文无关,PPL值也可能很低。
(三)实践步骤:手把手教你计算评估指标(附Python代码)
本次实操覆盖两大核心任务:文本分类(情感分析)、文本生成(新闻摘要),使用Python常用库(sklearn、nltk、transformers),代码极简且注释详细,新手复制就能跑。前置准备:安装依赖库,命令如下:
pip install sklearn nltk transformers datasets pandas
实操1:文本分类任务指标计算(情感分析案例)
任务描述:微调模型对电影评论进行情感分类(正面/负面),计算准确率、精确率、召回率、F1值,验证微调效果。
• 步骤1:准备数据。模拟微调后的预测结果与真实标签(实际场景中替换为你的模型预测结果和测试集标签):
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix# 模拟数据:真实标签(0=负面,1=正面)、模型预测标签
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0] # 真实标签
y_pred = [1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0] # 模型预测标签
• 步骤2:计算核心指标。调用sklearn库一键计算,指定标签类型(binary=二分类):
# 计算指标
accuracy = accuracy_score(y_true, y_pred) # 准确率
precision = precision_score(y_true, y_pred, average='binary') # 精确率
recall = recall_score(y_true, y_pred, average='binary') # 召回率
f1 = f1_score(y_true, y_pred, average='binary') # F1值
conf_matrix = confusion_matrix(y_true, y_pred) # 混淆矩阵# 打印结果
print(f"准确率:{accuracy:.4f}")
print(f"精确率:{precision:.4f}")
print(f"召回率:{recall:.4f}")
print(f"F1值:{f1:.4f}")
print("混淆矩阵:")
print(conf_matrix)
• 步骤3:结果解读。运行代码后输出如下,结合业务分析效果:
准确率:0.8667
精确率:0.8889
召回率:0.8000
F1值:0.8421
混淆矩阵:
[[6 1][2 6]]
解读:F1值0.8421,综合效果良好;精确率0.8889(预测为正面的评论中88.89%是真正面),召回率0.8000(真实正面评论中80%被正确识别);若业务是“推荐正面评论”,可接受当前效果;若怕漏判正面评论,需优化提升召回率。
实操2:文本生成任务指标计算(新闻摘要案例)
任务描述:微调模型生成新闻摘要,计算BLEU、ROUGE值,搭配人工评估验证效果。
• 步骤1:准备数据。模拟参考摘要(真实摘要)与生成摘要(模型输出):
import nltk
from nltk.translate.bleu_score import sentence_bleu
from rouge import Rouge # 需额外安装:pip install rouge# 下载nltk依赖(首次运行需执行)
nltk.download('punkt')# 模拟数据:参考摘要(可多个)、生成摘要
reference = [["人工智能", "技术", "正在", "改变", "各行各业"]] # 参考摘要(分词后)
hypothesis = ["人工智能", "正在", "深刻", "影响", "各行业"] # 模型生成摘要(分词后)
• 步骤2:计算BLEU、ROUGE值:
# 计算BLEU值(1-gram,适合短文本)
bleu1 = sentence_bleu(reference, hypothesis, weights=(1, 0, 0, 0))
print(f"BLEU-1值:{bleu1:.4f}")# 计算ROUGE值
rouge = Rouge()
# 需将分词结果拼接为字符串
hypothesis_str = " ".join(hypothesis)
reference_str = " ".join(reference[0])
scores = rouge.get_scores(hypothesis_str, reference_str)[0]
print(f"ROUGE-L精确率:{scores['rouge-l']['p']:.4f}")
print(f"ROUGE-L召回率:{scores['rouge-l']['r']:.4f}")
print(f"ROUGE-L F1值:{scores['rouge-l']['f']:.4f}")
• 步骤3:人工评估辅助。制定评分表,邀请2-3人打分,取平均值:
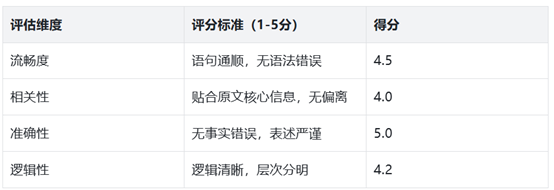
结果解读:BLEU-1值0.6(重叠度中等),ROUGE-L F1值0.58(信息覆盖中等),人工评分4.42(体验良好),综合判断生成效果合格,可微调优化用词准确性。
如果需要批量评估微调效果,手动写代码计算指标、整理结果很耗时,不妨试试LLaMA-Factory online。它能自动适配分类、生成等不同任务,一键计算准确率、F1、BLEU、ROUGE等核心指标,还能生成可视化评估报告,省去手动处理数据和调试代码的麻烦,新手也能快速完成效果验证。
(四)效果验证:如何科学判断微调模型是否达标?
光算出指标还不够,还要结合“微调前后对比、业务场景、稳定性”三维验证,避免“指标好看但不实用”的问题。
1. 微调前后指标对比
核心看“指标是否有明显提升”,排除“微调无效”的情况。比如:
• 分类任务:微调前F1值0.65,微调后0.84,提升明显,说明微调有效;
• 生成任务:微调前BLEU-1值0.3,微调后0.6,ROUGE-L F1值从0.35提升到0.58,同时人工评分提升1分以上,效果达标。
注意:若指标无提升甚至下降,需排查数据质量(如训练集标注错误)、微调参数(如学习率过高)、模型适配性(如小模型适配复杂任务)。
2. 结合业务场景判断
指标高低不是绝对的,要贴合业务需求。比如:
• 医疗文本分类(疾病诊断辅助):优先保证召回率(≥95%),哪怕精确率低一点,也要避免漏判疾病;
• 电商评论情感分析:优先保证F1值,平衡正面评论推荐准确率和负面评论捕捉率;
• 对话机器人生成:人工评分(流畅度、相关性)权重高于自动指标,毕竟用户体验是核心。
3. 稳定性验证
多次微调(3-5次),看指标是否稳定(波动≤2%),避免“单次微调运气好”的情况。比如多次微调后F1值稳定在0.82-0.85,说明模型效果可靠;若波动超过5%,需优化训练数据(增加数据量、清洗噪声)或微调参数。
(五)总结与展望:评估是微调的“导航仪”,不是“终点线”
核心总结
今天给大家讲透了大模型微调效果评估的入门方法,核心要点总结3点:
• 任务适配指标:分类任务优先F1值,生成任务结合BLEU、ROUGE与人工评估,语言建模看PPL值,不盲目追求单一指标;
• 实操核心:用sklearn、nltk等工具一键计算指标,步骤简单,新手可直接套用代码,关键在结果解读与业务结合;
• 避坑关键:指标高≠效果好,需结合微调前后对比、业务需求、稳定性验证,形成闭环。
其实评估的核心价值,是帮你找到微调的“优化方向”——比如F1值低是召回率不足,就调整数据增强策略;生成文本BLEU高但人工评分低,就优化模型生成逻辑。
如果想更高效地完成评估闭环,LLaMA-Factory online能帮上忙。它不仅能自动计算多类指标,还能对比多轮微调的效果差异,智能推荐优化方向(如调整学习率、补充训练数据),无需手动记录和分析,让微调评估更高效,新手也能快速迭代模型。
最后问大家一个问题:你在微调时遇到过“指标好看但业务用不了”的情况吗?是怎么优化的?欢迎在评论区留言,我们一起拆解解决方案~ 关注我,带你从入门到精通大模型微调全流程!