告别盲目试错!大模型微调核心参数的“油门、档位与里程

(一)引言:参数没调对,微调全白费
大家好,我是七七!刚入门大模型微调时,我踩过最致命的坑就是“瞎调参数”——拿着7B模型,随便设个学习率、batch_size就跑训练,结果要么模型不收敛(损失一动不动),要么显存直接炸了,折腾两三天都没调出正经效果。
后来跟身边的技术大佬请教才明白:大模型微调的核心不是“跑通代码”,而是“调好参数”。就像开车,油门(学习率)、档位(batch_size)、里程(训练轮次)没配合好,再棒的“车子”(模型)也跑不出好效果。新手之所以调参难,本质是没搞懂每个参数的作用,更不知道背后的基础逻辑。
今天这篇文章,就带新手朋友从0到1吃透大模型微调的3大核心参数(学习率、batch_size、epochs),用大白话讲清原理,附PyTorch实操步骤(复制就能跑),再分享一套“新手友好型”调参逻辑,帮你告别盲目试错。

(二)技术原理:3大核心参数拆解(通俗版)
大模型微调的核心目标,是让预训练模型“适配具体任务”(比如用通用模型微调做情感分析),而学习率、batch_size、epochs这三个参数,直接决定了“模型怎么学、学多久、学得稳不稳”。每个参数都讲透“作用+比喻+默认范围+避坑点”,新手也能秒懂。
1. 学习率(Learning Rate, LR):模型学习的“油门”
核心作用:控制模型参数更新的幅度,也就是“每一次学习后,模型调整自身参数的力度”。
通俗比喻:像开车踩油门,油门踩太猛(学习率太高),车子容易冲出去(模型参数震荡,不收敛,损失忽高忽低);油门踩太轻(学习率太低),车子龟速前进(模型学习缓慢,训练很久效果也没提升);只有油门力度适中,才能平稳加速(模型快速收敛,效果稳步提升)。
基础范围与适配场景:
通用默认值:2e-5 ~ 5e-5(微调7B/13B模型最常用,适配大多数文本任务);小模型/简单任务(如二分类):可适当提高到5e-5 ~ 1e-4;大模型/复杂任务(如多轮对话):建议降低到1e-5 ~ 2e-5,避免参数震荡。
新手必避坑:
不要用预训练的学习率(预训练LR通常是1e-4以上,微调时用这么高,模型必崩);学习率不是固定不变的,可搭配“warmup(热身)”(前几轮用小LR,避免一开始冲太猛),后续文章会讲进阶调度策略。
2. 批量大小(Batch Size):模型学习的“运输车”
核心作用:控制每次送入模型训练的数据量,也就是“模型一次学多少样本”。
通俗比喻:像运输车拉货,每辆车拉太多(batch_size太大),超出载重(显存不够),直接抛锚(OOM报错);每辆车拉太少(batch_size太小),运输效率低(模型训练速度慢,且容易受单一样本噪声影响,训练不稳定);拉货量适中(适配显存的最大batch_size),效率和稳定性兼顾。
基础范围与适配场景(按显卡显存划分):
16G显卡(如RTX 3090/4070):微调7B模型,batch_size建议设2~4(FP16精度下);24G显卡(如RTX 4090):微调7B模型,batch_size可设48;微调13B模型,设24;8G显卡(入门级):只能设1~2,需搭配后续讲的“梯度累积”弥补效果。
新手必避坑:
不要盲目追求大batch_size,优先保证“不OOM”,再谈效率;batch_size变了,学习率可适当调整(大batch_size可略提高LR,小batch_size可略降低,保持“有效学习率”稳定)。
3. 训练轮次(Epochs):模型学习的“复习次数”
核心作用:控制整个训练集被模型学习的总次数,也就是“模型把所有训练样本重复学几遍”。
通俗比喻:像学生复习考试内容,复习太少(epochs太少),知识点没记牢(模型欠拟合,效果差);复习太多(epochs太多),容易死记硬背(模型过拟合,训练集效果好,测试集效果差);复习次数适中,才能既掌握知识点又灵活运用。
基础范围与适配场景:
通用默认值:35轮(大多数文本任务,如情感分析、文本摘要,这个范围足够);训练数据量少(如几千条样本):可设58轮,避免欠拟合;训练数据量多(如几万条样本):可设2~3轮,避免过拟合,同时节省训练时间。
新手必避坑:
不要以“训练轮次越多越好”为标准,要观察“验证集损失”,当验证集损失开始上升时,说明已经过拟合,应立即停止训练;可搭配“早停(Early Stopping)”策略,自动停止过度训练,后续会讲实操。
(三)实践步骤:手把手调参实操(7B模型情感分析案例)
本次实操以“文本情感分析”为任务(二分类:正面/负面),用Llama 2 7B模型,适配16G显卡(FP16精度),工具用PyTorch+Transformers,步骤清晰到新手能直接复制跑。核心逻辑:先设基础参数跑通训练,再单参数微调优化效果。
前置准备:安装依赖库,命令如下:
pip install torch transformers accelerate peft datasets pandas scikit-learn
步骤1:设置基础参数(新手安全版)
先按16G显卡适配,设置“不OOM、易收敛”的基础参数,避免一开始就踩坑:
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer
from datasets import Dataset
import pandas as pd
from sklearn.metrics import f1_score, accuracy_score# 1. 基础参数配置(16G显卡7B模型专属)
model_name = "meta-llama/Llama-2-7b-hf" # 模型名称
lr = 2e-5 # 学习率(新手默认值)
batch_size = 2 # 批量大小(16G显存安全值)
epochs = 3 # 训练轮次(通用默认值)
num_labels = 2 # 情感分类任务,2个类别(正面/负面)
output_dir = "./llama2-sentiment" # 模型保存路径# 2. 加载模型和Tokenizertokenizer = AutoTokenizer.from_pretrained(model_name)
# 开启FP16精度,节省显存
model = AutoModelForSequenceClassification.from_pretrained(model_name,torch_dtype=torch.float16,num_labels=num_labels
).to("cuda")
步骤2:准备训练数据(模拟情感分析数据集)
模拟1000条电影评论数据(实际场景中替换为你的数据集即可),处理为模型可接受的格式:
# 模拟情感分析数据(text=评论内容,label=0=负面,1=正面)
data = {"text": ["这部电影太精彩了,推荐大家去看", "剧情拖沓,浪费时间", "演员演技在线,值得二刷"] + ["电影很好看" for _ in range(498)] + ["不推荐观看" for _ in range(497)],"label": [1, 0, 1] + [1]*498 + [0]*497
}
df = pd.DataFrame(data)
# 划分训练集、验证集(8:2)
train_df = df.sample(frac=0.8, random_state=42)
val_df = df.drop(train_df.index)
# 转换为Hugging Face Dataset格式
train_dataset = Dataset.from_pandas(train_df)
val_dataset = Dataset.from_pandas(val_df)# 数据预处理函数(分词)
def preprocess_function(examples):return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)# 应用预处理
tokenized_train = train_dataset.map(preprocess_function, batched=True)
tokenized_val = val_dataset.map(preprocess_function, batched=True)
步骤3:配置训练参数,启动微调
用Transformers的TrainingArguments配置训练细节,包含前面设置的核心参数,同时添加简单评估逻辑:
# 评估指标计算函数
def compute_metrics(eval_pred):logits, labels = eval_predpredictions = torch.argmax(torch.tensor(logits), dim=-1)return {"accuracy": accuracy_score(labels, predictions),"f1": f1_score(labels, predictions, average="binary")}# 配置训练参数
training_args = TrainingArguments(output_dir=output_dir,per_device_train_batch_size=batch_size, # 单卡训练batch_sizeper_device_eval_batch_size=batch_size,learning_rate=lr,num_train_epochs=epochs,logging_steps=10, # 每10步打印一次日志evaluation_strategy="epoch", # 每轮评估一次save_strategy="epoch", # 每轮保存一次模型fp16=True, # 开启FP16精度,节省显存load_best_model_at_end=True, # 训练结束后加载效果最好的模型metric_for_best_model="f1", # 以F1值为标准选择最优模型weight_decay=0.01, # 轻微权重衰减,防止过拟合
)# 初始化Trainer,启动训练
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_train,eval_dataset=tokenized_val,compute_metrics=compute_metrics
)# 开始微调
trainer.train()
步骤4:单参数微调优化(新手核心逻辑)
基础参数跑通后,若效果不佳(如F1值低、损失不收敛),按“先调学习率→再调batch_size→最后调epochs”的顺序,单参数微调(每次只改一个参数,排除干扰),优化逻辑如下:
• 学习率微调:若基础LR=2e-5训练后损失不下降,可试1.5e-5(降低)或3e-5(提高),对比F1值和损失变化;
• batch_size微调:若基础batch_size=2训练稳定,可尝试调到4(若显存足够),训练速度会提升,同时可把LR略提高到2.5e-5;
• epochs微调:若训练3轮后验证集损失还在下降,说明欠拟合,可加到5轮;若3轮后验证集损失上升,说明过拟合,可降到2轮。
新手单参数微调试错成本很高,每次调整都要等几小时训练结束才能看到效果。推荐试试LLaMA-Factory online,它能根据你的显卡型号(16G/24G)和模型规模(7B/13B),自动推荐适配的基础参数组合,还能实时展示参数调整对损失、指标的影响,省去反复试错的时间,新手也能快速找到最优参数。
(四)效果评估:如何判断参数调得好不好?
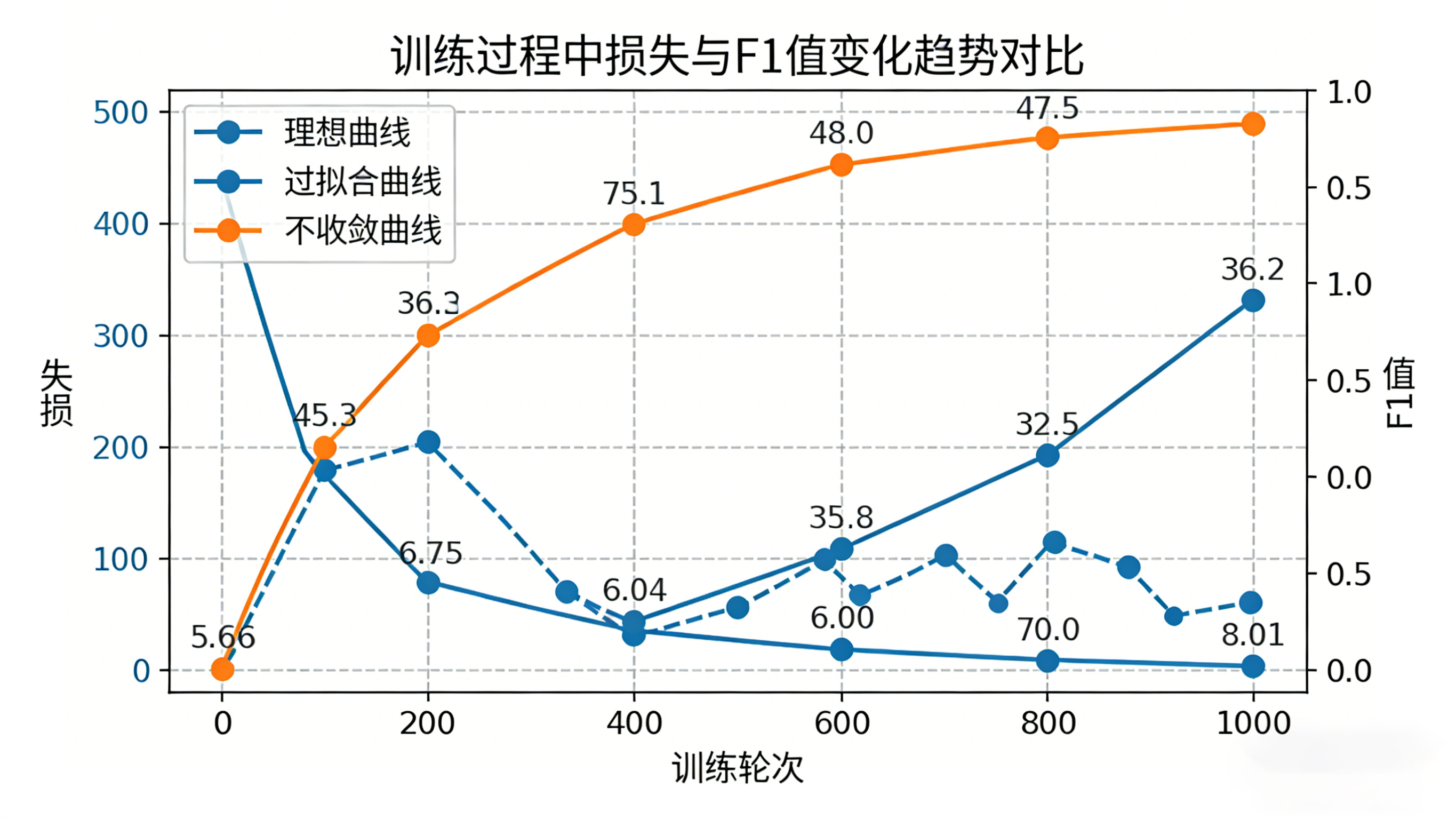
调参不是“改完参数就完事”,要通过“损失变化、指标提升、稳定性”三个维度验证效果,避免“参数调错还不知道”。
1. 看损失变化(判断模型是否收敛)
训练过程中观察“训练集损失(train_loss)”和“验证集损失(eval_loss)”:
理想情况:两者均稳步下降,且差距不大(说明模型收敛,无过拟合/欠拟合);异常情况1:训练集损失下降,验证集损失上升→过拟合,需减少epochs或增加权重衰减;异常情况2:两者都不下降→学习率太低,或参数初始化有问题,需提高学习率重新训练;异常情况3:损失波动很大→学习率太高,或batch_size太小,需降低学习率或增大batch_size(搭配梯度累积)。
2. 看核心指标(判断模型效果好不好)
结合任务类型看指标,比如情感分析看F1值、准确率:
调参后指标提升(如F1值从0.75提升到0.85)→ 参数调整有效;指标无变化或下降→ 参数调整不当,需回滚到上一组参数;优先看验证集指标,而非训练集指标(训练集指标高可能是过拟合)。
3. 看稳定性(判断参数是否可靠)
用同一组参数重复训练2~3次,看指标波动是否≤2%:
波动小(如F1值稳定在0.83~0.85)→ 参数可靠,模型效果稳定;波动大(如F1值在0.78~0.86之间)→ 可能是batch_size太小,或数据噪声大,需增大batch_size(搭配梯度累积)或清洗数据。
(五)总结:新手调参的核心逻辑的与进阶方向
核心总结
今天给大家讲透了大模型微调的3大核心参数,以及新手专属的调参逻辑,最后梳理3个关键要点,帮你快速上手:
• 参数逻辑:学习率控“更新力度”,batch_size控“学习效率”,epochs控“学习次数”,三者相辅相成,优先保证“不OOM、能收敛”,再追求“效果优、速度快”;
• 调参顺序:先设基础默认值(LR=2e-5、batch_size=2~4、epochs=3)跑通训练,再单参数微调,每次只改一个参数,避免干扰;
• 避坑核心:不盲目追求大参数,不照搬预训练参数,以“损失变化、指标提升、稳定性”为判断标准,拒绝“凭感觉调参”。
如果想快速掌握调参逻辑,又不想反复踩坑,LLaMA-Factory online是个很适合新手的工具。它不仅能自动适配硬件推荐基础参数,还能可视化展示不同参数组合的训练效果,甚至提供“参数微调建议”,帮你快速找到优化方向,省去手动记录、对比的麻烦,让调参从“盲目试错”变成“科学优化”。