1
ISPRS2024 | 视觉语言模型 | 基于Transformer和视觉基础模型的跨视角遥感图像检索方法
A Transformer and Visual Foundation Model-Based Method for Cross-View Remote Sensing Image Retrieval
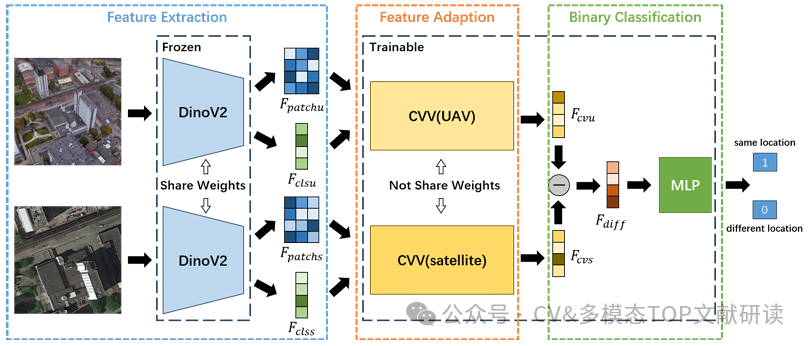
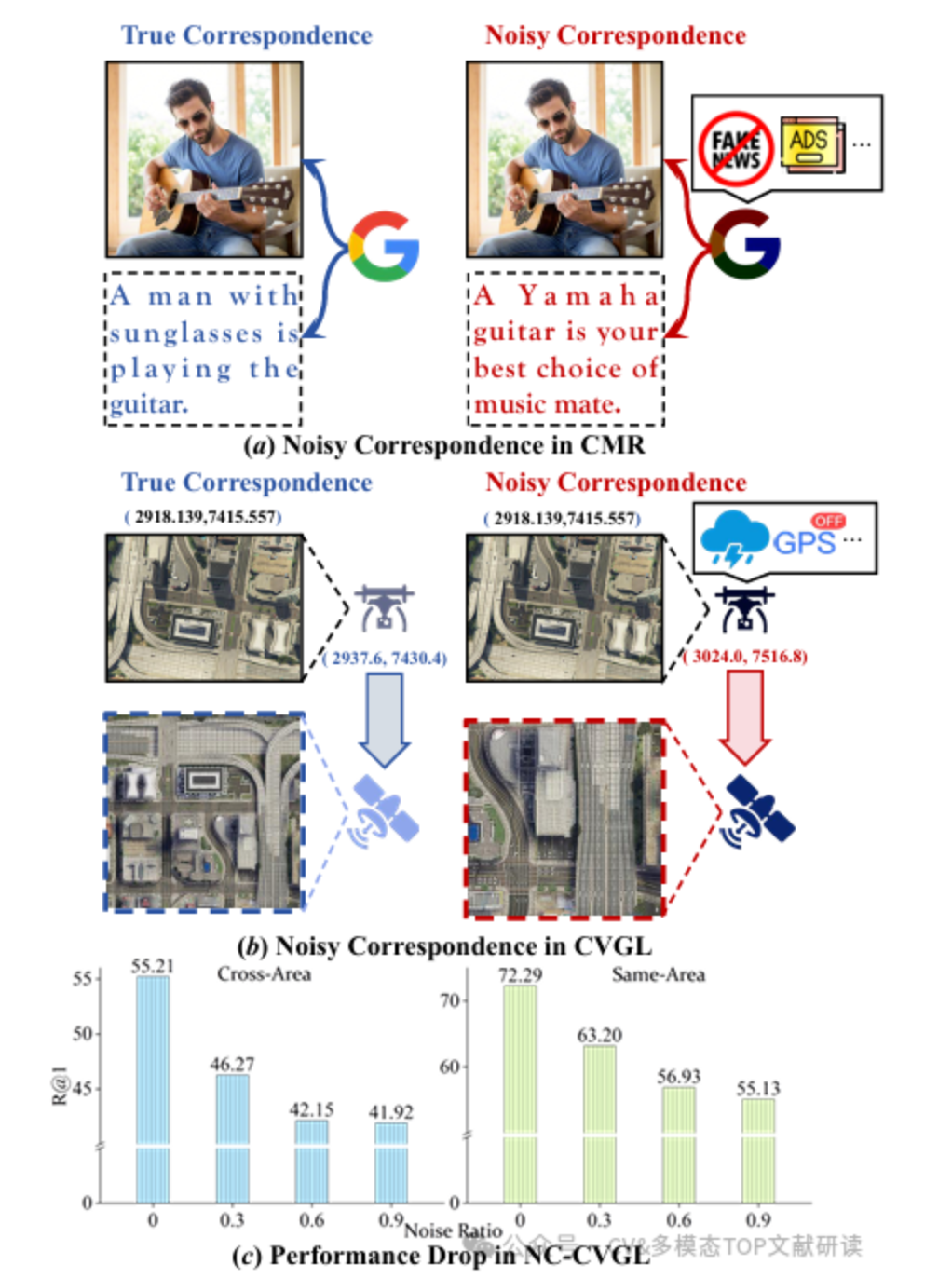
arXiv2025 | 视觉语言模型 | PAUL:针对嘈杂对应下的稳健跨视角地理定位的不确定性引导分区与增强
PAUL: Uncertainty-Guided Partition and Augmentation for Robust Cross-View Geo-Localization under Noisy Correspondence
ISPRS2025 | 视觉语言模型 | 通过分段和共同区域特征匹配实现交叉视图地理定位
Cross-view geolocation via segmentation and common region feature matching