Redis之Set:从无序唯一到智能存储,解锁用户画像/社交/统计全场景应用 - 实践
文章目录
- 本篇摘要
- Redis之Set(集合)
- 常见指令
- **1. 基础操作指令**
- **2. 集合间操作指令**
- **3. 随机与移动操作**
- 小总结
- set内部编码方式
- 举个例子理解
- **Redis的Set 应用场景**
- **1. 用户标签画像(精准推荐)**
- **2. 社交共同好友(关系链分析)**
- **3. 独立访客统计(UV去重)**
- 本篇小结

本篇摘要
本文围绕Redis集合(Set)展开,介绍其无序唯一、自动去重特性及核心指令(SADD/SREM/SMEMBERS等基础操作、集合运算指令、随机移动指令),解析intset/hashtable内部编码规则(整数且≤512用intset省内存,否则用hashtable),并给出用户标签、共同好友、UV统计等应用场景。
Redis之Set(集合)

无序且唯一:Set 存储不重复的元素,且元素无固定顺序(类似数学中的集合)。
自动去重:添加重复元素时自动忽略。
高效操作:支持交集、并集、差集等集合运算。
常见指令
1. 基础操作指令
SADD key member [member ...]- 功能:向集合添加一个或多个成员(自动去重)。
- 示例:
SADD tags "redis" "db" "cache" - 返回值:成功添加的成员数量(重复成员不计)。
- 时间复杂度:O(1)(每个成员)。
如:
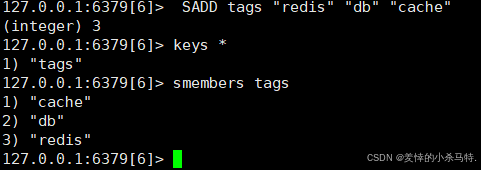
发现是无序的。
SREM key member [member ...]- 功能:移除集合中指定成员。
- 示例:
SREM tags "db" - 返回值:实际移除的成员数量。
- 时间复杂度:O(1)(每个成员)。
如:

当然这里也能移除很多。
SMEMBERS key- 功能:返回集合所有成员(无序)。
- 示例:
SMEMBERS tags - 注意:大集合可能阻塞,推荐用
SSCAN分批获取。 - 时间复杂度:O(N)(N为集合大小)。
如:

SCARD key- 功能:获取集合成员数量。
- 示例:
SCARD tags - 时间复杂度:O(1)。
如:

SISMEMBER key member- 功能:检查成员是否在集合中。
- 示例:
SISMEMBER tags "cache" - 返回值:1(存在)或 0(不存在)。
- 时间复杂度:O(1)。
如: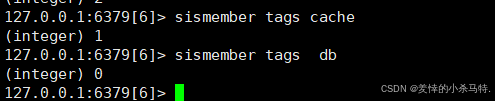
SSCAN key cursor [MATCH pattern] [COUNT count]- 功能:增量式迭代集合成员(解决
SMEMBERS阻塞问题)。 - 示例:
SSCAN tags 0 (或者sscan tags 0 match r* 10) - 返回值:
[新游标, [成员1, 成员2, ...]]。 - 时间复杂度:每次调用 O(1),完整迭代 O(N)。
- 功能:增量式迭代集合成员(解决
如:

遍历完返回0,然后就是全部个数。
2. 集合间操作指令
SUNION key [key ...]- 功能:返回多个集合的并集(不存储结果)。
- 示例:
SUNION tags tag2 - 时间复杂度:O(N)(N为所有集合成员总数)。
如: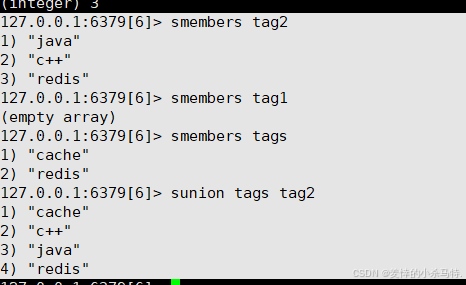
SUNIONSTORE destination key [key ...]- 功能:计算并集并存储到目标集合。
- 示例:
SUNIONSTORE des tags tags2 - 返回值:结果集合的成员数量。
- 时间复杂度:O(N)。
如:
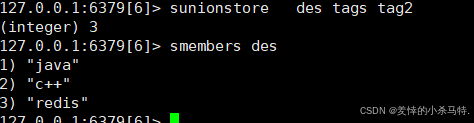
SINTER key [key ...]- 功能:返回多个集合的交集。
- 示例:
SINTER ag2 des - 时间复杂度:O(N*M)(最差情况)。
如:
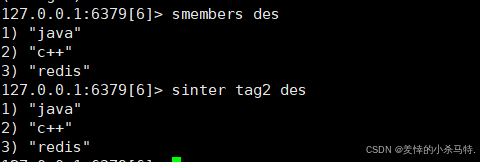
这里只有一种可能。
SINTERSTORE destination key [key ...]- 功能:计算交集并存储到目标集合。
- 示例:
sinterstore des1 tag2 des - 时间复杂度:O(N*M)。
如:
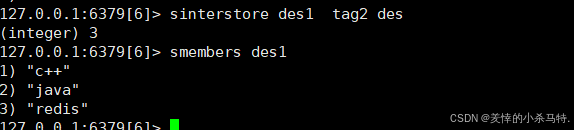
SDIFF key [key ...]- 功能:返回第一个集合与其他集合的差集。
- 示例:
SDIFF tag1 tag2 /sdiff tag2 tag1 ``` - 时间复杂度:O(N)。
如:
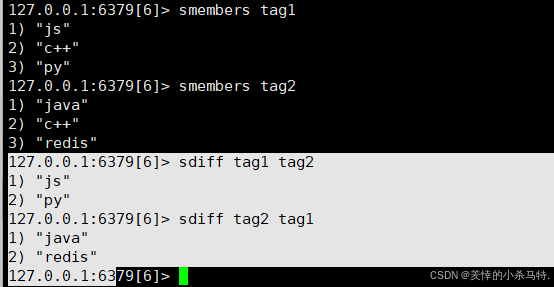
这里先后顺序决定是否不一样。
SDIFFSTORE destination key [key ...]- 功能:计算差集并存储到目标集合。
- 示例:
SDIFF t1 tag1 tag2 /sdiff t2 tag2 tag1 - 时间复杂度:O(N)。
如:
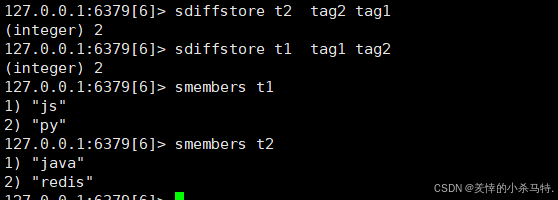
3. 随机与移动操作
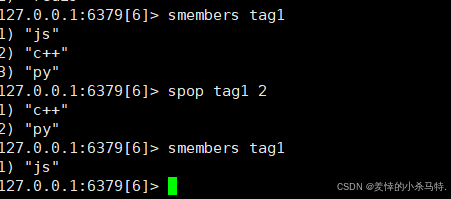
SPOP key [count]- 功能:
随机移除并返回集合中一个或多个成员。 - 示例:
SPOP tag1 2 - 返回值:被移除的成员(数组形式)。
- 时间复杂度:O(1)(单个成员)。
- 功能:
如:
SMOVE source destination member- 功能:将成员从源集合移动到目标集合。
- 示例:
SMOVE tag2 tag1 c++ - 返回值:1(成功)或 0(成员不存在)。
- 时间复杂度:O(1)。
如:
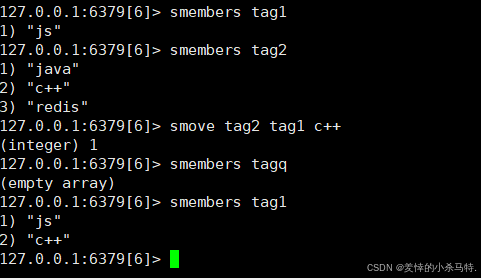
注:如果tag1有对应的元素,那么它只会从tag2中移除然后无法加入tag1。
小总结
| 指令类别 | 指令 | 功能简述 | 时间复杂度 | 关联内部编码 | 备注 |
|---|---|---|---|---|---|
| 基础操作 | SADD key member... | 向集合添加一个或多个成员(自动去重) | O(1) 每个成员 | INTSET(小整数集合) HT(大集合/非整数) | 整数且数量少时用 INTSET,否则转 HT |
SREM key member... | 移除集合中指定成员 | O(1) 每个成员 | HT | ||
SMEMBERS key | 返回集合所有成员(无序,大集合可能阻塞) | O(N)(N为集合大小) | HT | 大集合建议改用 SSCAN 分批获取 | |
SCARD key | 获取集合成员数量 | O(1) | HT/INTSET 均直接统计 | ||
SISMEMBER key member | 检查成员是否在集合中 | O(1) | HT(哈希表快速查找) INTSET | ||
SSCAN key cursor [MATCH pattern] [COUNT count] | 增量式迭代集合成员(解决 SMEMBERS 阻塞问题) | 每次调用 O(1),完整遍历 O(N) | HT | 通过游标分批获取,避免全量阻塞 | |
| 集合间运算 | SUNION key [key...] | 返回多个集合的并集(不存储结果) | O(N)(N为所有集合成员总数) | HT | 遍历所有集合成员计算并集 |
SUNIONSTORE dest key [key...] | 计算并集并存储到目标集合 | O(N) | HT | 结果存入 dest,返回成员数 | |
SINTER key [key...] | 返回多个集合的交集 | O(N*M)(最差情况,依赖集合大小) | HT | 需遍历多个集合的公共成员 | |
SINTERSTORE dest key [key...] | 计算交集并存储到目标集合 | O(N*M) | HT | 结果存入 dest | |
SDIFF key [key...] | 返回第一个集合与其他集合的差集(顺序影响结果) | O(N) | HT | 如 SDIFF A B 是 A 有但 B 没有的成员 | |
SDIFFSTORE dest key [key...] | 计算差集并存储到目标集合 | O(N) | HT | 结果存入 dest | |
| 随机与移动操作 | SPOP key [count] | 随机移除并返回集合中一个或多个成员 | O(1)(单个成员) | HT | 从集合中随机弹出元素 |
SMOVE source dest member | 将成员从源集合移动到目标集合(原子操作) | O(1) | HT | 若成员不存在于源集合则失败,目标集合自动创建 |
set内部编码方式
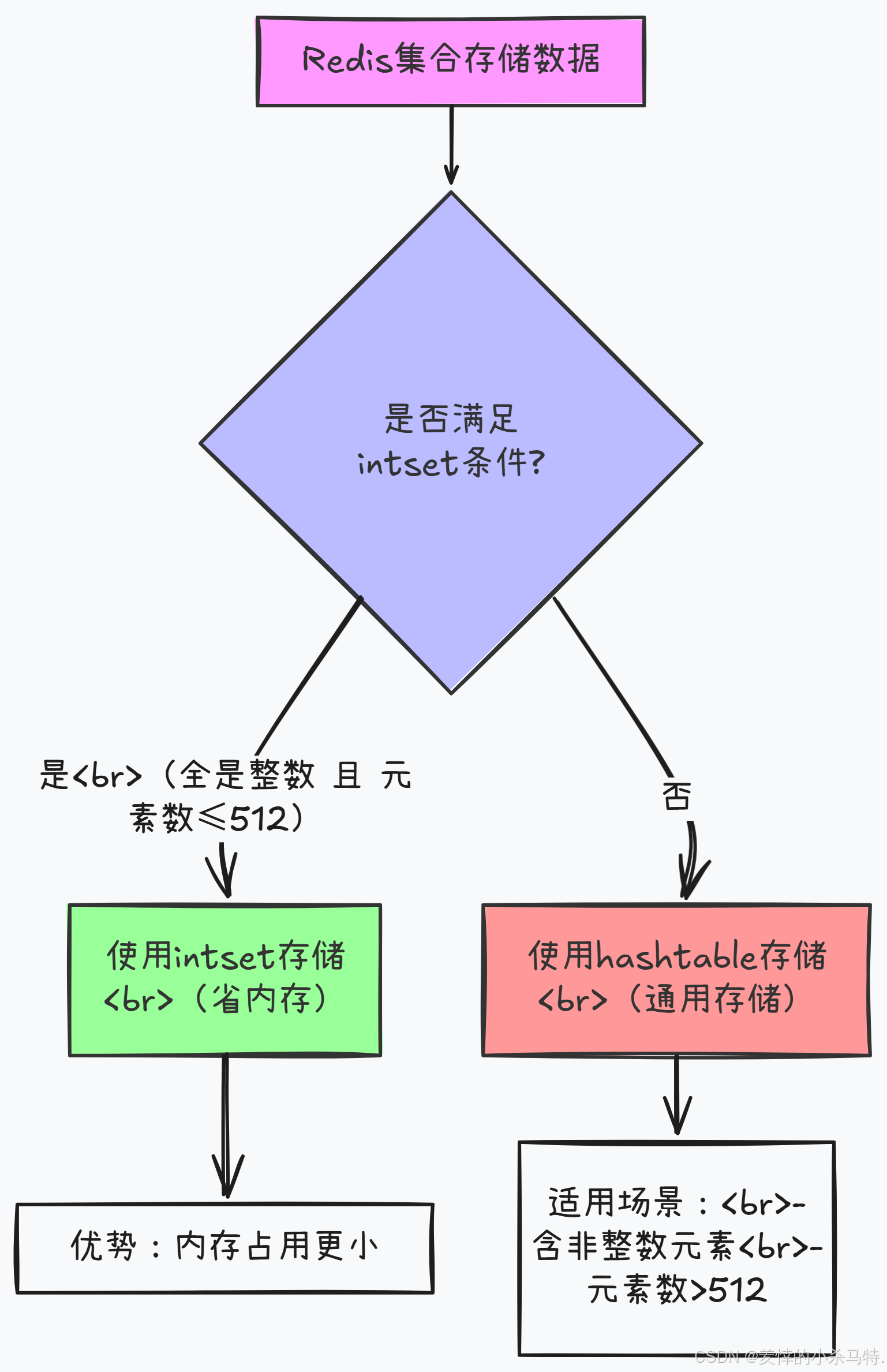
Redis里的集合(set)存数据时,内部有两种“存储方式”,具体用哪种,取决于集合里存的是啥、有多少数据:
intset(整数集合,类似于整数数组):
- 条件:集合里全是整数,并且元素个数小于等于512个(这个512是Redis默认配置,能改)。
- 好处:用intset存更省内存。
hashtable(哈希表):
- 只要上面intset的两个条件有一个不满足,Redis就用hashtable存。比如:
- 元素个数超过512个;
- 集合里有非整数的元素(比如字符串、对象等)。
- 只要上面intset的两个条件有一个不满足,Redis就用hashtable存。比如:
如下:
举个例子理解
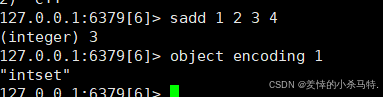
- 例子1:满足intset条件 → 用intset存
往集合setkey里加4个整数(1、2、3、4),因为元素少(≤512)且全是整数,所以用object encoding setkey查存储方式,结果是"intset"。
如:
- 例子2:元素超过512个 → 用hashtable存
往集合setkey里加513个整数(超过512了),这时候不满足intset条件,查存储方式结果是"hashtable"。
这里太多就不演示了。
- 例子3:有非整数元素 → 用hashtable存
往集合setkey里加一个字符串"a"(不是整数),查存储方式结果也是"hashtable"。
如:
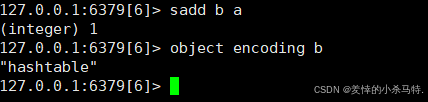
一句话概括:Redis集合存数据时,优先选省内存的intset;但只要数据不满足“全是小整数且数量少”,就会自动切换成更通用的hashtable来存。
Redis的Set 应用场景
1. 用户标签画像(精准推荐)
- 功能:存储用户特征标签(如性别、兴趣、行为),实现“千人千面”推荐,还有就是根据用户常访问的加入set中,最后根据set元素分析用户兴趣,实现这种推送功能。
- 核心操作:
SADD user:1:tags "sports"(添加标签)SINTER user:1:tags user:2:tags(计算共同兴趣)
- 优势:自动去重,快速交集运算。
2. 社交共同好友(关系链分析)
- 功能:通过集合交集计算用户共同好友(如QQ/微信)。
- 核心操作:
SINTER friends:Alice friends:Bob(返回Alice和Bob的共同好友)
3. 独立访客统计(UV去重)
- 功能:统计网站唯一访问用户数(同一用户多次访问仅计1次)。
- 核心操作:
SADD uv:20230820 "192.168.1.1"(记录IP)SCARD uv:20230820(获取UV数)
- 优势:利用Set唯一性天然去重,比数据库统计高效。
本篇小结
Redis集合是高效存储唯一元素的工具,支持丰富操作与集合运算,内部通过intset/hashtable智能编码省内存,广泛应用于标签、社交、统计等场景,是开发中实用的数据结构。