论文链接:https://arxiv.org/abs/2512.24601
我们从推理时扩展的角度出发,研究如何让大型语言模型(LLMs)能够处理任意长度的提示词。为此,我们提出了递归语言模型(RLMs)—— 这是一种通用的推理策略,它将长提示词视为外部环境的一部分,允许大型语言模型通过编程方式检查、分解这些提示词,并针对提示词的片段递归调用自身。我们发现,递归语言模型(RLMs)能够成功处理比模型上下文窗口多两个数量级的输入;即便对于较短的提示词,在四项不同的长上下文任务中,其性能也显著优于基础大型语言模型(LLMs)和常见的长上下文框架,同时每次查询的成本相当(甚至更低)。
这篇论文核心是解决大语言模型(比如 GPT-5)“记不住长内容” 的问题,提出了一种叫 “递归语言模型(RLM)” 的新方法,用通俗的话讲清楚就是:
1. 现有大模型的痛点
咱们平时用的大模型都有个 “记忆上限”—— 比如最多能处理 27 万个词,超过这个长度就会 “断片”(论文里叫 “上下文衰退”),越长的内容处理得越差。比如让它读一本几百万字的书再回答问题,或者分析一个超大的代码库,它要么直接处理不了,要么答得乱七八糟。
而且之前的解决办法都有缺陷:比如把长内容 “浓缩总结”,但会丢关键细节;或者让模型调用工具检索,但只能处理特定任务,不够通用。
2. RLM 的核心思路:把长内容当 “外部文件”,让模型自己 “翻着看 + 拆着做”
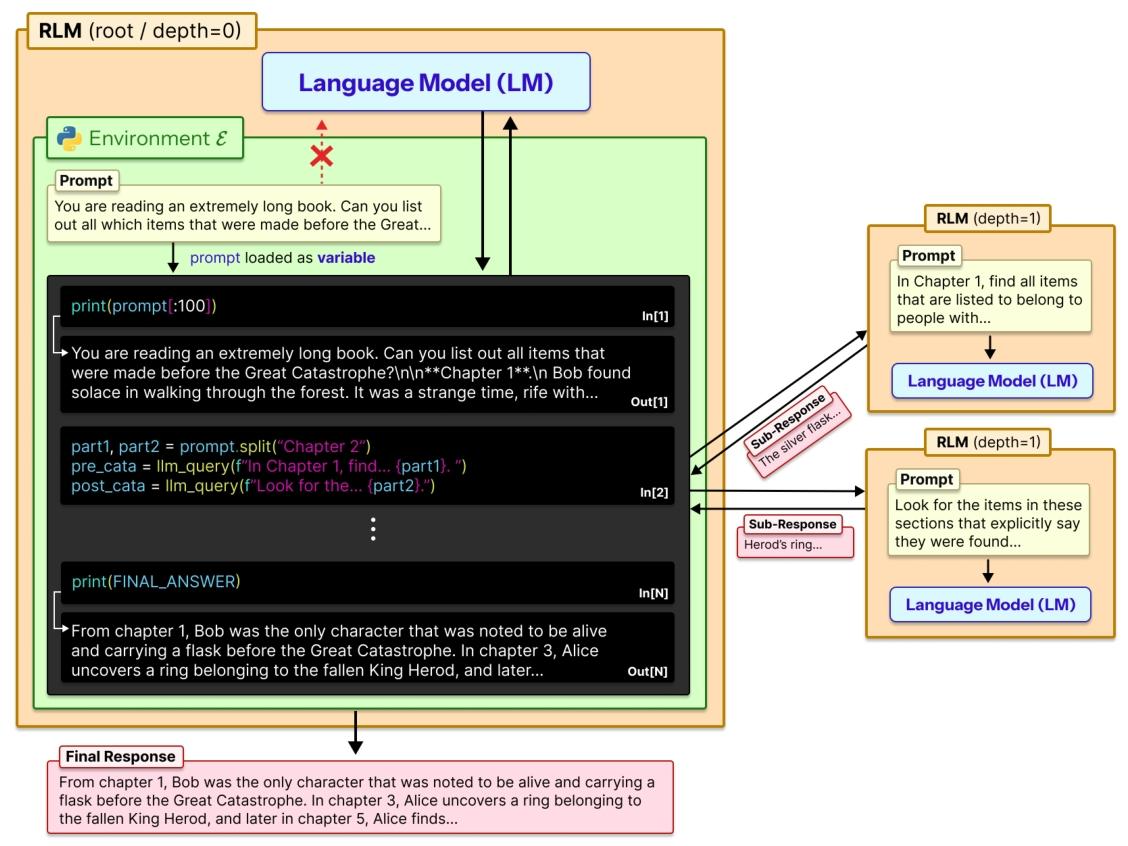
RLM 不直接把所有长内容塞给模型,而是搞了个 “中转站”—— 一个 Python 编程环境(类似咱们电脑上的记事本 + 计算器),把长文本存在这个环境里当 “变量”。然后让模型做三件事:
- 自己写简单代码 “偷看” 内容:比如只看前 100 字、用关键词搜索相关片段,不用从头到尾读;
- 把大任务拆成小任务:比如分析 1000 篇文档,就拆成 10 组,每组 100 篇;
- 递归调用自己解决小任务:让模型自己调用 “小号模型”(比如用 GPT-5-mini 处理片段),把小结果汇总成最终答案。
简单说,普通模型是 “一次性读完所有内容再答题”,RLM 是 “先看目录、挑重点、分章节读,最后汇总”,还能自己检查答案对不对。
3. RLM 厉害在哪?
- 能处理超长篇内容:比普通模型的 “记忆上限” 多两个数量级(比如普通模型最多处理 27 万词,RLM 能处理上千万词);
- 答题更准:不管是找信息、分析代码、多文档推理,都比普通模型和其他方法(比如总结、检索)强很多,尤其是内容越长、任务越复杂,优势越明显。比如 “OOLONG-Pairs” 任务,普通模型几乎得 0 分,RLM 能得 58 分(满分 100);
- 花钱不多:处理同样的长任务,RLM 的成本和普通模型差不多,甚至更便宜 —— 因为它只挑有用的内容看,不用全量处理。
4. 举个实际例子
比如让 RLM 找 “某小镇美食节选美冠军”(需要读 830 万词的 1000 篇文档):
- RLM 先写代码搜索 “美食节”“选美” 这些关键词,快速定位到相关文档片段;
- 调用小号模型分析这个片段,找到候选人 “Maria Dalmacio”;
- 再用两个小号模型验证答案,确认没错后,返回最终结果。
整个过程不用读完全部 830 万词,又快又准。
5. 小缺点和未来方向
- 偶尔会 “做无用功”:比如有的模型会反复验证答案,浪费时间和成本;
- 对模型的 “编程能力” 有要求:太简单的模型不会写代码,用不了 RLM;
- 未来可以让模型更聪明地拆分任务、支持多线程处理,还能专门训练适合 RLM 的模型,进一步提升效率。
总结下来,RLM 就像给大模型配了个 “智能文件管理器 + 助手团队”,让它不用硬记所有内容,而是通过 “查资料、拆任务、找帮手” 的方式,高效搞定超长内容的处理,而且不额外多花钱。

