此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第五课的第一周内容,1.1的内容以及一些基础的补充。
本周为第五课的第一周内容,与 CV 相对应的,这一课所有内容的中心只有一个:自然语言处理(Natural Language Processing,NLP)。
应用在深度学习里,它是专门用来进行文本与序列信息建模的模型和技术,本质上是在全连接网络与统计语言模型基础上的一次“结构化特化”,也是人工智能中最贴近人类思维表达方式的重要研究方向之一。
这一整节课同样涉及大量需要反复消化的内容,横跨机器学习、概率统计、线性代数以及语言学直觉。
语言不像图像那样“直观可见”,更多是抽象符号与上下文关系的组合,因此理解门槛反而更高。
因此,我同样会尽量补足必要的背景知识,尽可能用比喻和实例降低理解难度。
本篇的内容关于序列数据和序列模型,是自然语言处理中基础内容。
1. 序列数据
在 NLP 中,一个最基础、也最核心的问题是:语言数据,和我们之前见过的数据,有什么本质不同?
答案可以简单概括为:它是有顺序的。
在机器学习中,我们把 ”顺序本身携带信息” 的数据称为序列数据。
最直观的例子就是一句话,同样是这几个词:
“我 吃 饭”
“饭 吃 我”
包含的词完全一样,但表达的含义却天差地别,这说明:在语言中,信息不仅存在于“有哪些元素”,还存在于“元素出现的顺序”。
这与我们之前在 CV 中常见的数据有所不同。
一张图像在进入模型之前,通常已经被表示为一个固定尺寸的二维像素网格。
无论我们先看左上角还是右下角,整幅图像的所有信息在输入时是同时存在的,模型面对的是一个“完整画面”。
在这种设定下,卷积网络更关注的是空间结构关系:哪些像素彼此相邻、哪些局部区域可以组成更高层的形状。
而语言数据的形式则不同,一句话并不是一个天然的“整体对象”,而是由词语按顺序依次出现的。
简单来说:在按序建模的假设下,模型对当前词的理解,往往依赖于之前已经出现的所有词所构成的上下文。
需要说明的是,这里的“按顺序”并不一定意味着模型必须像人一样一个词一个词地读。
在后续将要介绍的 Transformer 模型中,整句话的所有词可以被同时送入模型进行处理,但模型仍然需要通过显式地引入位置信息,来区分“哪个词在前、哪个词在后”。
再打个比方:
图像更像是一张已经摊开在桌面上的地图,所有信息一眼都在,模型在处理时不依赖显式的时间顺序,而是直接建模整体的空间结构关系。
而语言更像是一段正在播放的语音或文字流,我们从哪里听,哪里看,结果是截然不同的。
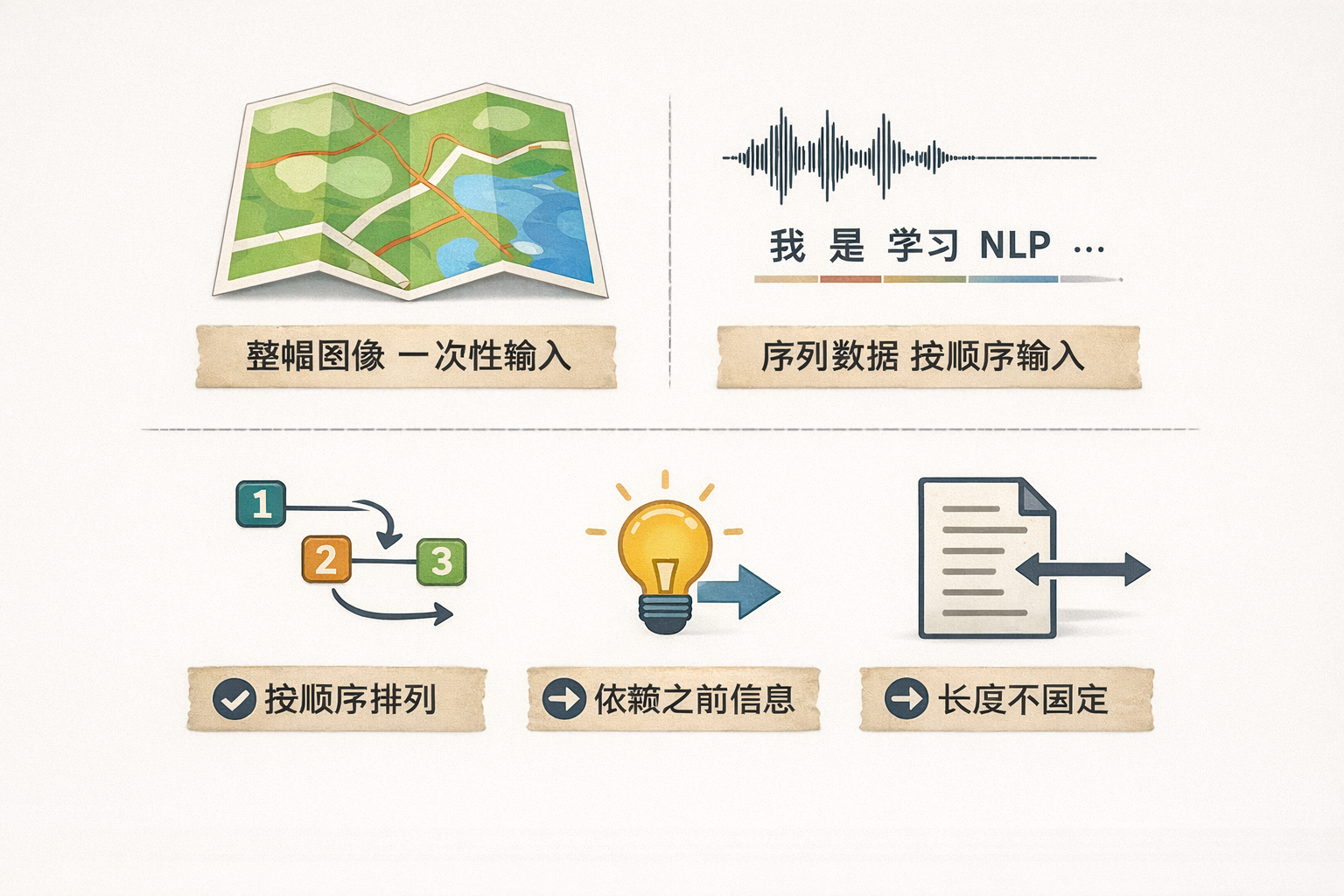
因此,在语言任务中,“先出现什么、后出现什么”本身就构成了信息的一部分,而不能被随意打乱
正因为这种差异,让CV 模型更擅长处理空间结构与局部模式,而 NLP 模型必须重点解决顺序、依赖关系以及上下文记忆的问题。
我们总结语言、语音、时间等序列数据的特征如下:
- 数据是按顺序排列的。
- 当前信息往往依赖于之前已经出现的内容。
- 数据长度通常不固定。
这些特征决定了:在处理序列数据时,模型必须显式地考虑顺序与上下文,而不能仅把输入当作一个无序的特征集合来处理。
2. 序列模型
我们分别看看,如果使用我们已经了解过的全连接网络和卷积网络来处理序列数据,效果会怎么样。
2.1 全连接网络:无法自然处理“顺序”
如果要应用全连接网络,最直接的想法是: 把一句话中的每个词表示成向量,再把这些向量拼接成一个长向量,送进全连接网络。
这种做法在形式上是可行的,但问题也非常明显:
首先,全连接网络要求固定长度输入,而语言序列的长度是天然不固定的。
一句话可以只有几个词,也可以非常长。为了满足输入要求,我们不得不进行截断或填充,这本身就引入了额外的工程复杂度。
其次,更关键的是:全连接网络并不具备“顺序感知”能力。在它看来,输入只是一个高维向量,各个维度之间没有“先后”这一概念。
模型本身并不知道:“这是第一个词”“这是第三个词”。
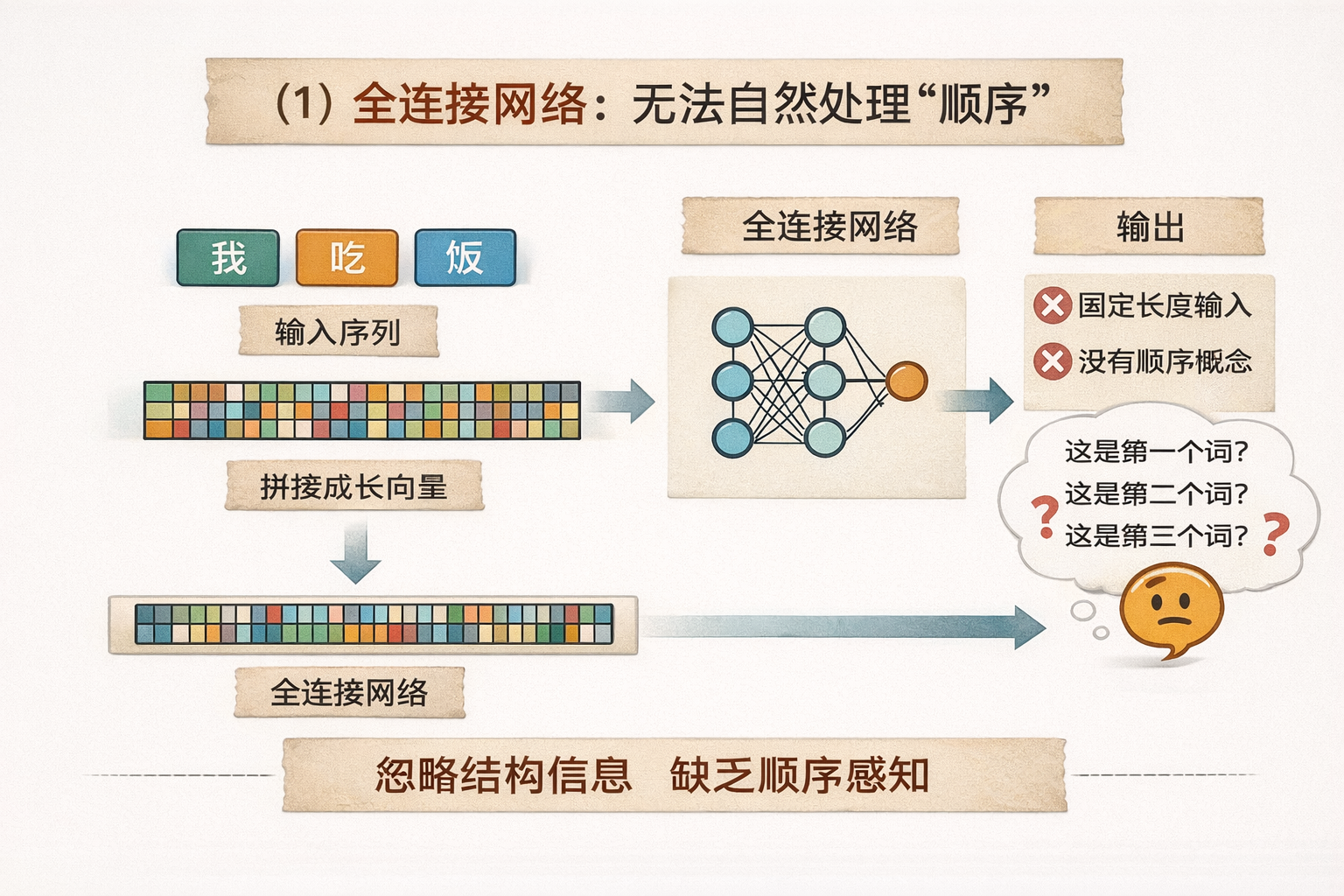
因此,这种处理方式天然忽略了语言中最重要的结构信息——顺序与依赖关系。不能用来处理序列数据。
2.2 卷积网络:擅长局部模式,但缺乏长期依赖
那卷积网络呢? 既然 CNN 能在图像中建模局部结构,是否也可以用于序列数据?
答案是:部分可以,但不够自然。
在序列上使用一维卷积时,卷积核可以捕捉局部连续片段,例如相邻几个词构成的短语或固定搭配。 从这个角度看,CNN 确实能够建模局部上下文信息。
在这里,我们需要引入一个概念:感受野(receptive field)。
感受野指的是卷积层中某个神经元能够“看到”的输入区域范围。
打个比方:
- 在图像中,如果一个卷积神经元的感受野是 \(3\times3\),它只能感知这九个像素的局部信息;
- 类似地,在序列上,一个卷积核的感受野就是它一次性能看到的连续词的数量。
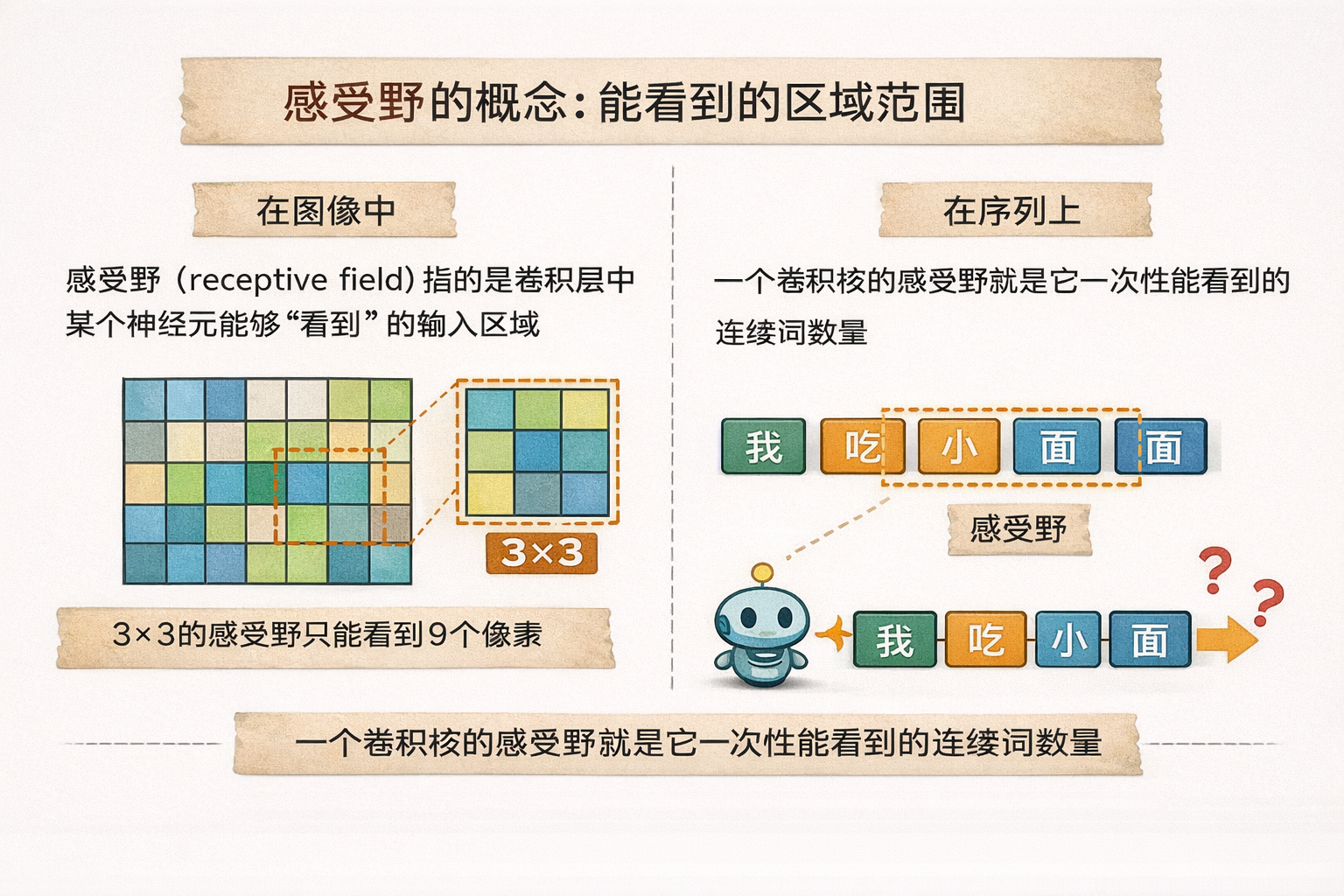
这就意味着,卷积网络在处理序列时天然擅长捕捉局部模式或短距离依赖,但如果想让模型理解“句首的词”与“句尾的词”之间的关系,就必须堆叠很多层卷积或人为扩大卷积核范围,才能覆盖整个序列。
简单来说,感受野越大,模型越容易捕捉长距离依赖,但这也带来了计算和训练上的问题。
这使得模型: - 对短距离依赖敏感。
- 对长距离依赖不够高效。
- 并且仍然缺乏一种明确的“时间状态”概念。
可以这样理解:
卷积网络更像是在扫描局部片段,而不是在沿着时间轴逐步理解一句话的发展过程,因此,虽然卷积对序列数据的处理能力强于全连接网络,但是它仍有所局限。
2.3 序列模型要解决的核心问题
通过以上对比可以看到,全连接网络和卷积网络并不是“不能”处理序列数据,而是处理方式与序列数据的本质存在冲突。
序列数据的核心特点在于:信息是随顺序逐步展开的、当前理解依赖于历史上下文且序列长度不固定。
因此,我们真正需要的是这样一类模型: 在处理当前输入的同时,能够保留并更新对“过去信息”的表示。
也就是说,序列模型的核心能力并不在于“输入形式”, 而在于它是否具备一种可随时间演化的内部状态,用来承载上下文信息,并参与后续决策。
后续我们将看到的 RNN、LSTM、GRU 以及 Transformer, 虽然实现方式不同,但都围绕着同一个目标展开: 让模型在理解当前内容时,不是孤立地“看这一刻”,而是基于整个上下文来判断。
这就是序列模型所具备的能力。
3. 序列模型的应用领域
序列模型在 NLP 中应用广泛,但需要注意的是:序列模型不一定要求输入和输出都是序列。它的核心能力在于能够保留上下文信息并处理随时间展开的数据。只要输入或输出中存在序列性质,序列模型就能发挥作用。
从输入和输出的角度,可以分为以下几类情况:
- 序列→序列: 输入和输出都是序列,例如机器翻译。模型需要根据输入序列的上下文生成对应的输出序列。
- 序列→标量或类别: 输入是序列,输出是单个值或类别,例如情感分析、文本分类。模型需要理解整段序列的语义,并输出整体判断。
- 标量或固定输入→序列: 输入不是序列,但模型需要生成序列作为输出,例如文本生成或对话系统中根据提示生成完整回答。
由此可见,序列模型的核心能力不是“必须处理序列输入或输出”,而是能够在处理过程中维护上下文信息。
来看看序列模型的一些常见应用领域:
| 任务 | 输入类型 | 输出类型 | 说明 |
|---|---|---|---|
| 文本分类 | 序列 | 类别 | 如情感分析、新闻分类,理解整段文本并输出单一标签 |
| 命名实体识别 (NER) | 序列 | 序列 | 对每个词进行标注,如“人名”“地名”等 |
| 机器翻译 | 序列 | 序列 | 将源语言句子转换为目标语言句子 |
| 文本生成 | 序列或标量 | 序列 | 根据输入文本或提示生成完整文本 |
| 语音识别 | 序列 | 序列 | 将语音信号转为文字序列 |
| 问答系统 | 序列 | 序列或标量 | 根据问题生成答案,答案可以是短文本或单一类别 |
| 时间序列预测 | 序列 | 序列或标量 | 如股价预测,根据历史序列预测未来数值 |
通过这个分类,可以清晰地看到:序列模型的核心是处理顺序和上下文,不必限制输入输出都为序列。只要有序列信息存在,它就可以发挥价值。
4. 总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 序列数据 | 数据元素按顺序排列,当前理解依赖历史上下文,长度不固定 | 图像像摊开的地图,一眼可见整体;语言像正在播放的语音或文字流,需要顺序感知 |
| 全连接网络处理序列 | 只能接受固定长度输入,无法天然感知顺序 | 只是把所有词拼成一个长向量,模型看不到先后顺序 |
| 卷积网络处理序列 | 能捕捉局部连续模式(短距离依赖),感受野有限,长距离依赖不高效 | 卷积像扫描局部片段,而不是沿时间轴理解整句话的发展 |
| 感受野 (Receptive Field) | 一个卷积神经元一次能够看到的输入区域 | 图像:3×3像素只能看到局部;序列:卷积核一次看到几个连续词 |
| 序列模型核心能力 | 通过可随时间演化的内部状态,保留并更新上下文信息,理解当前输入时考虑历史信息 | 模型像带记忆的阅读者,理解每个词时参考整段上下文 |
| 输入/输出类型灵活性 | 序列模型不要求输入输出都为序列,只要一方为序列即可发挥作用 | 输入是流,输出是判断或生成,模型记忆历史信息 |
| 序列模型应用 | NLP、语音、时间序列等领域,如文本分类、NER、机器翻译、文本生成、语音识别、问答、时间序列预测 | 依赖上下文信息,模型像“顺序感知器”,根据过去信息做当前决策 |