@
- 0. 代码版本
- 1. 整体文件
- 2. 原始物料的爬取
- 2.1 爬虫文件
- 2.2 流程图示
- 2.3 流程描述
- 2.3.1
start_requests - 2.3.1
SinanewsPipeline
- 2.3.1
- 3. 新闻画像的处理
- 3.1 相关文件
- 3.2 流程图示
- 3.3 流程描述
- 3.3.1
update_new_items() - 3.3.2
update_dynamic_feature_protrail() - 3.3.3
update_redis_mongo_protrail_data - 3.3.4
news_to_redis.py - 3.3.5
log_process.py
- 3.3.1
- 4. 用户画像的处理
- 4.1 相关文件
- 4.2 流程图示
- 4.3 流程描述
- 4.3.1 user_protrail.py
- 4.3.2 user_to_mysql.py
- 5. 自动化构建流程
0. 代码版本
该专栏的博客当中涉及的所有代码,均为组队学习期间的版本,大概在2021年12月12日左右,某一个可能的参考版本链接如下:
https://github.com/datawhalechina/fun-rec/tree/9bcfafaae339c443cc7911b9070bf52adef9e994
1. 整体文件
在D:\Project\fun-rec\codes\news_recsys\news_rec_server\materials\文件夹下,主要是新闻物料的获取及处理流程:
PS D:\Project\fun-rec\codes\news_recsys\news_rec_server\materials> tree /f /a
卷 Data 的文件夹 PATH 列表
卷序列号为 7876-8A9C
D:.
|---process_material.py
| 控制新闻画像更新逻辑
| 1.处理新闻画像
| 2.更新新闻动态画像
| 3.生成前端展示画像并备份
|
|---process_user.py
| 控制用户画像更新逻辑
| 1.存储用户曝光数据
| 2.更新用户画像
|
|---README.md
| 项目说明
|
|---update_redis.py
| 控制Redis更新逻辑
| 更新Redis数据
|
+---material_process
| 物料处理文件夹
|
|-------log_process.py
| 从日志当中将阅读等行为更新到用户的画像表
|
|-------news_protrait.py
| 1.对新闻进行画像处理、添加阅读量等属性
| 2.更新MongoDB当中的新闻画像备份
| 3.从Redis更新MongoDB中新闻画像的动态属性例如点赞量
|
|-------news_to_redis.py
| 分别将新闻的动态和静态属性更新到Redis
|
|-------README.md
| 项目说明
|
|-------utils.py
| 关键词提取工具
|
+---news_scrapy
| |
| |---monitor_news.py
| | 监控目前爬取数量的进度
| |
| |---scrapy.cfg
| | scrapy的默认配置文件
| |
| \+--sinanews
| \--爬虫文件夹
| \-
| |---items.py
| | 定义新闻数据的字段
| |
| |---middlewares.py
| | 中间件部分,经手请求和响应
| |
| |---pipelines.py
| | 持久化部分,将数据存入数据库
| |
| |---run.py
| | 爬虫执行的代码,串起整个流程
| |
| |---settings.py
| | 爬虫的一些设置
| |
| |---__init__.py
| | 项目保留文件,似乎无实意
| |
| \+--spiders
| \--爬虫的具体代码
| \-
| |---sina.py
| | 发出请求和解析回应
| |
| |---__init__.py
| | 项目保留文件,似乎无实意
|
\+--user_process\--用户处理部分\-|---user_protrail.py| 对用户进行画像处理:| 1.获取兴趣爱好:喜欢的新闻类别、关键词、热度、点赞次数| 2.获取历史行为特征:阅读、点赞、收藏||---user_to_mysql.py| 记录用户的曝光数据:某个用户在某个时间阅读了某个新闻||----------------------------------------------------------
2. 原始物料的爬取
2.1 爬虫文件
PS D:\Project\fun-rec\codes\news_recsys\news_rec_server\materials\news_scrapy> tree /f /a
卷 Data 的文件夹 PATH 列表
卷序列号为 7876-8A9C
D:.
| monitor_news.py
| 监控模块
| 查看该集合当前的文档数量
| 比较其与我们设定的数量的差异
|
| scrapy.cfg
| scrapy的配置文件,写明项目名称
|
\---sinanews\--具体的项目文件夹\-| items.py| 定义爬取的每一条信息数据| 规定其中各个字段的含义|| middlewares.py| 中间件,请求和响应都将经过他| 可以配置请求头、代理、cookie、会话维持等| 暂时没有有效使用过这个高级用法|| pipelines.py| 项目管道文件,将爬取的数据进行持久化存储| 也就是将爬取的数据存入MongoDB数据库| 具体地,是存入SinaNews库的new_<current_date>集合|| run.py| 定义scrapy的在命令行的运行命令| 运行该文件即为运行整个项目|| settings.py| scrapy的配置文件,写明数据库的host等|| __init__.py| 项目的初始化文件,此处为空|\---spiders\--爬虫文件夹\-| sina.py| 定义具体的爬虫,包括request以及对返回内容的解析| start_requests函数根据新闻类别lid、页码page以及一个随机数r拼接出url| 然后回调parse函数,parse再回调parse_content函数|| __init__.py| 爬虫初始化文件,此处为空|\---------------------------------------------------
2.2 流程图示
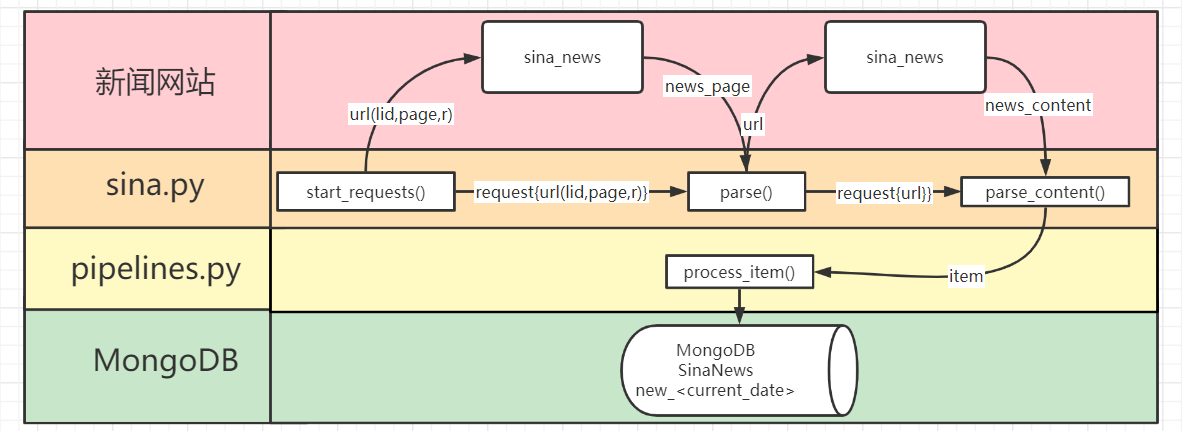
2.3 流程描述
2.3.1 start_requests
爬虫的主体应该是在spiders文件夹下的sina.py文件里面
该文件先初始化了新闻的类别以及请求新闻的基础url结构
然后通过start_requests函数填充新闻类别lid、新闻所在网页的编号page以及随机数r
以此得到了一个完整的新闻请求连接,该请求应该是返回某个类别中一整页的新闻
start_requests是一个迭代器,其返回了一个Request,并回调parse函数来解析网页内容
在parse函数对网页内容的解析当下,其逐个处理单条新闻数据,填充新闻的标题、类别等
parse也是一个迭代器,其对于网页上解析出的每一条新闻数据,也返回了一个Request
并回调parse_content函数来解析每一条新闻数据的新闻内容,现在新闻数据只缺内容了
最后的parse_content函数也是迭代器,其填充了单条新闻数据item的content部分
至此,单调的新闻数据item的所有部分填充完毕,由迭代器parse_content返回
然后,应该跳回到parse函数,解析当前网页上的下一条新闻数据
当该网页上的所有的数据都被解析完毕以后,跳回到start_requests,开始下一页
2.3.1 SinanewsPipeline
至于持久化存储的模块,则应该是在sinanews文件夹下的pipelines.py文件里面
其SinanewsPipeline类有一个爬虫引擎crawler调用的类方法from_crawler
这个类方法用配置settings.py文件的数据库host等信息,新建一个SinanewsPipeline类实例
然后该实例基本就由爬虫引擎操作,具体是scrapy架构核心的哪一部分还不太清楚
在爬虫开始的时候,引擎会调用open_spider函数来用host等连接对应的数据库
在爬虫运行的过程中,引擎会调用process_item函数来对每一条新闻数据进行处理
这里的process_item函数承接的应该是上文parse_content函数返回的新闻数据item
process_item函数会先判断item是否符合我们在item.py当中定义的新闻格式SinanewsItem
具体的操作是使用isinstance函数来判别item是否是SinanewsItem类的实例
在符合新闻数据格式SinanewsItem的情况下,我们对该条数据进行去重判别
这里的去重操作就是判断该新闻的时间戳在不在当天的时间范围之内
如果在,那就是当天的新闻,就存入存入SinaNews库的new_<current_date>集合
不是的话就去除,此处的去除操作是不存入数据库,这里仅依据时间戳去重
3. 新闻画像的处理
3.1 相关文件
PS D:\Project\fun-rec\codes\news_recsys\news_rec_server\materials\material_process> tree /f /a
卷 Data 的文件夹 PATH 列表
卷序列号为 7876-8A9C
D:.`log_process.py`在2021年12月12日附近的代码版本当中这个文件与项目的其他部分并无关系其引用只在自身文件内,看起来像测试其作用是将日志表中用户的阅读记录抽出从`<log.userid, log.newsid, log.actiontype, log.actiontime>`到`<userRead.userid, userRead.newid, userRead.actiontime>``news_protrait.py`新闻画像处理的主要文件1.首先是`update_new_items`将添加新的数据也就是从`MongoDB`中`SinaNews`库的当天爬取的`new_<current_date>`集合更新到`MongoDB`中`NewsRecSys`库的`FeatureProtrail`集合2.然后是`update_dynamic_feature_protrail`函数从`Redis`的`dynamic_news_info`也就是`Redis[2]`当中将当天各新闻最新的点赞数量、收藏数量等动态特征更新到`MongoDB`的`NewsRecSys`库的`FeatureProtrail`集合3.最后,将最新的新闻展示数据,例如内容等前端数据使用`update_redis_mongo_protrail_data`函数从`MongoDB`的`NewsRecSys`库的`FeatureProtrail`集合更新到`MongoDB`的`NewsRecSys`库的`RedisProtrail`集合`news_to_redis.py`根据`MongoDB`的`NewsRecSys`库的`RedisProtrail`集合使用`news_detail_to_redis`函数分离标题、内容、类别、时间等静态属性存入`Redis`的`static_news_info`也就是`Redis[1]`分离点赞数量、收藏数量等动态属性存入`Redis`的`dynamic_news_info`也就是`Redis[2]``README.md`说明文件`utils.py`使用`jieba`定义了一个关键词提取函数该函数在`news_protrait.py`被调用旨在根据新闻内容重新提取关键词
3.2 流程图示
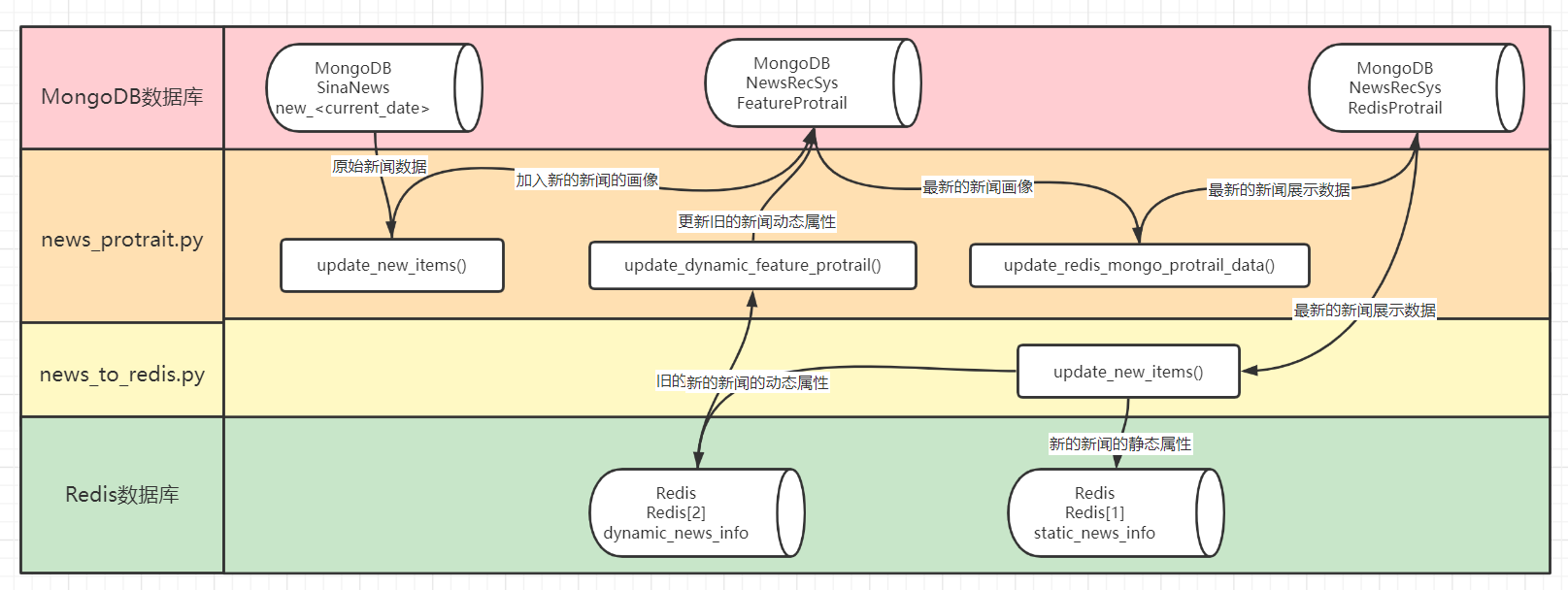
3.3 流程描述
新闻画像处理流程的控制应该是在process_material.py文件当中
该文件依次进行物料更新、动态属性更新,和展示数据更新,注意次序
物料更新的地方在news_protrait.py文件当中
3.3.1 update_new_items()
其先用update_new_items()添加新的新闻画像,也就是处理新物料
当天新爬取的数据在MongoDB中SinaNews的new_<current_date>集合
update_new_items()函数会增加阅读量、点赞量等属性,将其处理成为画像
3.3.2 update_dynamic_feature_protrail()
然后将新闻画像存入MongoDB中NewsRecSys库的FeatureProtrail集合
这个函数的作用就是,从Redis更新新闻画像当中的动态属性到MongoDB
因为点赞量这样的东西,一般是变化比较频繁的,所以最新的在Redis里面
但是Redis显然不是一个长久存储的地方,所以我们将其存回新闻画像当中
也就是从Redis的dynamic_news_info也就是Redis[2]当中
将当天各新闻最新的点赞数量、收藏数量等动态特征
更新到MongoDB的NewsRecSys库的FeatureProtrail集合
也就是上面将原始新闻处理成为画像然后再插入数据的那个集合
3.3.3 update_redis_mongo_protrail_data
至此,当天新爬取的新闻已经入库,之前旧的新闻的动态属性也已更新
所以现在就从最新的、完整的、全部的新闻画像当中,挑选出展示的部分
也就是从MongoDB的NewsRecSys库的FeatureProtrail新闻画像挑选数据
更新到MongoDB的NewsRecSys库的RedisProtrail集合用于前端展示
3.3.4 news_to_redis.py
这个地方比较神奇,暂且先将其放在这里说明,因为其控制文件与上面的不一样
上面三个部分是由process_material.py控制,而这里则是由update_redis.py来控制
其主要的作用是,将处理好的新的新闻数据,从MongoDB更新到Redis来支持前端
也就是,根据MongoDB的NewsRecSys库的RedisProtrail集合
分离标题、内容、类别、时间等静态属性,存入Redis的static_news_info也就是Redis[1]
分离点赞数量、收藏数量等动态属性,存入Redis的dynamic_news_info也就是Redis[2]
3.3.5 log_process.py
怎么说呢,这个地方更加的神奇,让我觉得是这个项目版本的问题之一,2021年12月12日附近
根据文中的代码来看,其作用应该是从日志文件当中分检出用户阅读行为,存入对应的行为表当中
即从MySQL的loginfo库中log_Y-m-d表,<log.userid, log.newsid, log.actiontype, log.actiontime>
到MySQL的userinfo库中的user_read表,<userRead.userid, userRead.newid, userRead.actiontime>
但是实际上来说,用户的like和collection行为在server.py的actions()函数当中已经写入MySQL
但是用户的read行为并没有被检出,其他地方都没有写入MySQL的userinfo库中的user_read表
整个系统当中貌似只有MySQL的loginfo库中log_Y-m-d表包含了所有用户read行为的记录
但是MySQL内loginfo库的log_Y-m-d表中同时混杂所有用户所有like和collection的历史记录
而且这整个系统当中也只有这个log_process.py文件完成了从日志文件当中分检出用户阅读行为的操作
但是这个LogProcess类只在该文件内有过实例化,其他地方没有调用,该文件本身也没有被控制调用过
所以理论上MySQL的userinfo库中的user_read表是空的,设计上应该由本文件来维护,但实际上好像没有
4. 用户画像的处理
4.1 相关文件
PS D:\Project\fun-rec\codes\news_recsys\news_rec_server\materials\user_process> tree /f /a
卷 Data 的文件夹 PATH 列表
卷序列号为 7876-8A9C
D:.`user_protrail.py`这里主要是用于用户画像的处理首先是`update_user_protrail_from_register_table`函数其遍历`MySQL`的`userinfo`数据库的`register_user`表对于每一个用户,调用`_user_info_to_dict`函数生成用户画像`_user_info_to_dict`函数在生成画像的时候会用`get_statistical_feature_from_history_behavior`分类统计用户行为对于每一类行为如`like`,函数会读取`MySQL`中`userinfo`库的`user_likes`表调用`_gen_statistical_feature`生成对该用户此时段内该行为的数据统计例如该统计有用户`15`天内`like`文章的`top3`类别、平均热度、数量等总的来说,对一段时间内,例如十五天,其中喜欢和收藏操作的新闻根据`MySQL`中`userinfo`库的`user_likes`和`user_collections`表统计得出其`Top3`类别、`Top3`关键词、平均热度和数量如果是新用户,历史数据为空,新增这些属性就好,因为用`defaultdict`允许为空如果是老用户,那就读取`MySQL`当中对应的表做时段内的统计就好最终将这个用户画像存入`MongoDB`中`NewsRecSys`库的`UserProtrail`集合`user_to_mysql.py`这个文件也挺神奇的,主要作用是存储用户的曝光列表这里的曝光列表定义为:我们为该用户所生成的推荐列表也就是说,曝光列表记录了系统给该用户推荐过的所有的新闻而曝光列表的作用,就是在给用户生成新的推荐时,避免重复推荐具体流程为`user_exposure_to_mysql`从`Redis`读取数据也就是`Redis`的`user_exposure`库,又名`Redis[3]`然后使用`_transfor_json_for_user`转换格式最后存入`MySQL`的`userinfo`库中`exposure_Y-m-d`表这里的Redis数据库似乎并不是按天存储的,而是存历史所有反倒是MySQL,是按天来存的,每天在`userinfo`存一个曝光表但问题是,每次推荐的时候过滤的曝光列表,是根据`Redis`的也就是说,每次我们的推荐,都要过滤掉此前所有的历史推荐没有子文件夹
4.2 流程图示
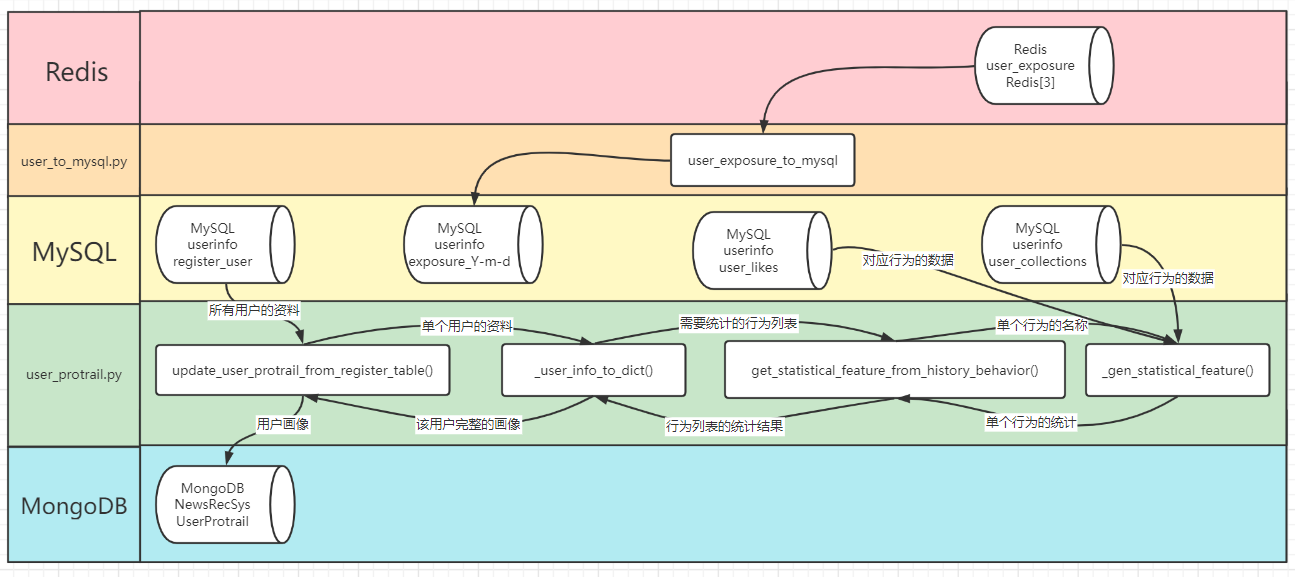
4.3 流程描述
用户画像的处理大概也是两个部分吧,一个是构建画像,一个是记录曝光表
4.3.1 user_protrail.py
先说构建画像部分,其实也就如同上图所示,是一个连续调用的过程
update_user_protrail_from_register_table遍历MySQL的userinfo数据库的register_user表
访问其中的每一个用户信息,然后调用_user_info_to_dict函数生成用户画像
其实也就是增加了对某时段内历史行为的统计,例如该行为历史下top3的关键词
在增添了这些属性之后,就要判断新旧用户了,新用户没有历史,属性为空即可
那么对于旧用户来说,得调用函数get_statistical_feature_from_history_behavior()
去访问MySQL中userinfo库的user_likes表和userinfo库的user_collections表
查找该用户过去时段,此处为15天,该时段内的like和collections记录
对于查找出来的每一类行为记录,调用_gen_statistical_feature函数
统计得出该类行为的Top3类别、Top3关键词、平均热度和数量
然后向上返回到get_statistical_feature_from_history_behavior()
得到该用户过去15天内关于like和collections的统计数据
再返回到_user_info_to_dict,相当于说完全补全了用户画像
再返回到最初的update_user_protrail_from_register_table函数
并尤其写入到MongoDB中NewsRecSys库的UserProtrail集合
4.3.2 user_to_mysql.py
至于记录曝光表,也很简单,就是从Redis到MySQL的流动
具体流程为user_exposure_to_mysql从Redis读取数据
也就是Redis的user_exposure库,又名Redis[3]
然后使用_transfor_json_for_user转换格式
最后存入MySQL的userinfo库中exposure_Y-m-d表
此处Redis是全部的推荐历史,而MySQL是一天一个表
但是推荐引擎是根据Redis来过滤新生成的推荐列表的
5. 自动化构建流程
爬虫的控制是由脚本crawl_news.sh完成的,在crontab有定时
新闻画像的处理逻辑在process_material.py中调用函数执行
由offline_material_and_user_process.sh脚本控制,由crontab有定时
用户画像的处理逻辑在process_user.py中调用函数执行
同样由offline_material_and_user_process.sh脚本控制,由crontab有定时
更新Redis的代码news_to_redis.py由update_redis.py控制逻辑
同样由offline_material_and_user_process.sh脚本控制,由crontab有定时