论文信息
论文标题:Faking Fake News for Real Fake News Detection: Propaganda-Loaded Training Data Generation
论文翻译:为真实虚假新闻检测伪造虚假新闻:富含宣传性的训练数据生成
论文作者:黄恭翔,凯瑟琳·麦基翁,普雷斯拉夫·纳科夫,崔叶进,姬衡
论文来源:ACL 2023
发布时间:2023
论文地址:https://aclanthology.org/2024.naacl-long.313/
论文代码:https://github.com/khuangaf/FakingFakeNews
总结:
1 研究动机&&研究背景
2 方法
框架
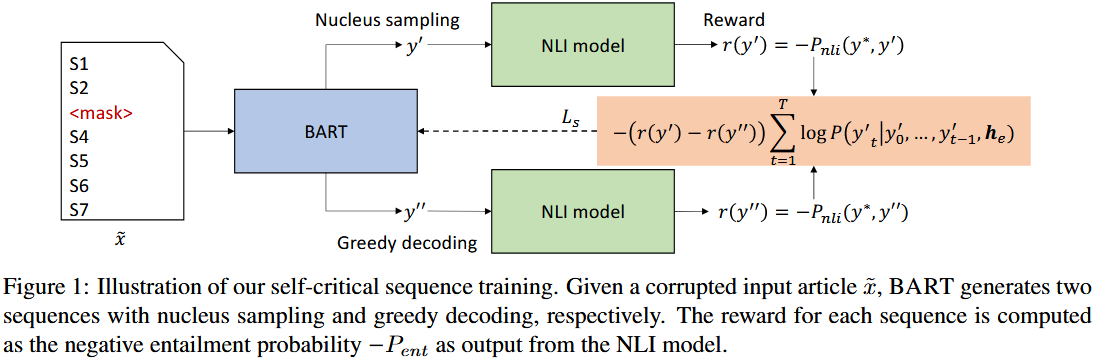
2.1 Disinformation Generation(虚假信息生成)
-
-
-
原新闻显著句(真实):“NATO 战机于周四在布雷加附近误炸了反叛军坦克纵队,造成至少 5 名反叛军士兵死亡。”
-
仅用 MLE 训练的 BART 生成句:“NATO 的军事行动导致反叛军人员伤亡,相关事件发生在布雷加地区。”
-
分析:生成句虽然简化了 “误炸”“坦克纵队”“至少 5 人死亡” 等细节,但核心事实(NATO 在布雷加地区的行动造成反叛军伤亡)与原句完全蕴含一致 —— 原句的信息能推导出生成句的结论,生成内容并未虚假,无法用于训练虚假信息检测器。
-
-
2.2 Propaganda Generation(宣传手法生成)
流程:
2.3 Intermediate Pre-training(中间预训练)
3 实验
3.1 数据集(Data)
1. 核心数据集:PROPANEWS
2. 评估数据集
| 数据集名称 | 数据来源 | 样本构成(真实 / 虚假) | 说明 |
|---|---|---|---|
| SNOPES | 事实核查网站 SNOPES | 430/280 | 剔除无法访问 URL 的文章 |
| POLITIFACT | 事实核查网站 POLITIFACT | 517/369 | 剔除无法访问 URL 的文章 |
3. 对比用生成训练数据
| 数据类型 | 说明 |
|---|---|
| GROVER-GEN | Zellers et al. (2019) 提出,先基于原文生成标题,再基于标题生成正文 |
| GROVER-GEN-1SENT | GROVER-GEN 的变体,仅生成 1 个句子替换原文显著句 |
| FACTGEN | Shu et al. (2021) 提出,通过事实检索器从外部语料获取支持信息,提升生成文本的事实一致性 |
| FACTGEN-1SENT | FACTGEN 的变体,仅生成 1 个句子替换原文显著句 |
| FAKEVENT | Wu et al. (2022) 提出,基于句子的操纵知识元素逐句生成 |
| FAKEVENT-1SENT | FAKEVENT 的变体,仅生成 1 个句子替换原文显著句 |
| PN-SILVER | 复用本文生成数据,但未经过人工验证(无标注者筛选) |
3.2 Baselines
1. 检测模型
2. 生成方法对比基准
3.3 实验内容
实验1:人类撰写虚假信息检测性能评估
实验目标
验证PROPANEWS训练的检测器在SNOPES/POLITIFACT(人类撰写虚假新闻)上的性能优势。
实验设计
用不同训练数据训练4种检测模型,评估AUC指标(4次运行取均值±标准差),配对bootstrap检验显著性。
实验结果
|
训练数据
|
ROBERTA-LARGE(SNOPES)
|
GROVER-LARGE(SNOPES)
|
ROBERTA-LARGE(POLITIFACT)
|
GROVER-LARGE(POLITIFACT)
|
|
GROVER-GEN
|
57.65 (±7.6)
|
52.77 (±2.1)
|
48.42 (±2.2)
|
49.53 (±0.1)
|
|
FACTGEN
|
48.46 (±2.2)
|
51.79 (±3.6)
|
41.98 (±5.4)
|
50.47 (±4.9)
|
|
FAKEVENT
|
46.33 (±2.6)
|
50.27 (±5.9)
|
45.36 (±1.2)
|
47.40 (±1.3)
|
|
PN-SILVER
|
60.39* (±3.9)
|
55.23* (±5.8)
|
51.52** (±3.4)
|
52.39** (±4.1)
|
|
PROPANEWS
|
65.34** (±4.5)
|
60.43** (±6.2)
|
53.03** (±3.7)
|
54.09** (±2.8)
|
实验结论
-
PROPANEWS训练的模型性能最优,ROBERTA-LARGE在SNOPES上AUC达65.34,显著高于所有Baseline生成数据。
-
无人工验证的PN-SILVER也优于传统生成方法,证明本文生成策略(虚假信息+宣传手法)的有效性。
-
单一句子替换(-1SENT变体)导致GROVER-GEN和FACTGEN性能大幅下降,因生成句与上下文不连贯。
实验2:消融实验(宣传手法的有效性验证)
实验目标
分析“诉诸权威(AA)”和“情绪化语言(LL)”对检测性能的贡献。
实验设计
对比PROPANEWS及其3种消融版本(w/o AA、w/o LL、w/o AA&LL)训练的模型AUC。
实验结果
|
训练数据
|
ROBERTA-LARGE(SNOPES)
|
GROVER-LARGE(SNOPES)
|
ROBERTA-LARGE(POLITIFACT)
|
GROVER-LARGE(POLITIFACT)
|
|
PROPANEWS
|
65.34** (±4.5)
|
60.43** (±6.2)
|
53.03** (±3.7)
|
54.09** (±2.8)
|
|
PROPANEWS w/o AA
|
63.21** (±3.2)
|
58.28** (±4.2)
|
50.78* (±1.8)
|
53.22** (±3.7)
|
|
PROPANEWS w/o LL
|
64.65** (±1.8)
|
56.93** (±5.3)
|
51.92** (±3.4)
|
51.68* (±1.4)
|
|
PROPANEWS w/o AA&LL
|
61.83* (±4.9)
|
52.82 (±3.3)
|
52.77** (±2.7)
|
50.93 (±2.7)
|
实验结论
-
移除“诉诸权威”或“情绪化语言”后,模型AUC均下降(如PROPANEWS w/o AA比原版低2.13),证明两种宣传手法均能提升检测泛化性。
-
即使移除两种宣传手法,PROPANEWS w/o AA&LL仍优于多数Baseline,说明本文生成的虚假信息本身已贴近人类撰写风格。
实验3:生成质量评估实验
实验目标
验证生成数据的 plausibility(可信度)及宣传手法的影响。
实验设计
AMT标注者对PROPANEWS和GROVER-GEN各100篇文章评分(1=低可信度,3=高可信度),并评估宣传手法的影响程度。
实验结果
-
plausibility评分:PROPANEWS平均2.25分,GROVER-GEN平均2.15分。
-
宣传手法影响:PROPANEWS高可信度样本中,29.2%标注者认为宣传手法“高度影响”其判断。
实验结论
-
本文生成数据的可信度略高于GROVER-GEN,证明“贴近人类宣传策略”的生成逻辑更优。
-
宣传手法能显著提升虚假新闻的可信度,进一步验证了在训练数据中注入宣传手法的必要性。
实验4:相似性分析实验
实验目标
量化生成数据与人类撰写虚假新闻的风格相似度。
实验设计
用MAUVE指标计算PROPANEWS、GROVER-GEN与POLITIFACT虚假新闻的分布相似度。
实验结果
-
PROPANEWS与POLITIFACT虚假新闻的MAUVE相似度为17.1%。
-
GROVER-GEN与POLITIFACT虚假新闻的MAUVE相似度为13.7%。
实验结论
PROPANEWS生成数据与人类撰写虚假新闻的风格相似度高于GROVER-GEN,说明本文生成方法能更好地模拟人类虚假新闻的特征。
实验5:数据规模影响实验
实验目标
探究PN-SILVER规模对检测性能的影响,及与人类撰写数据(SNOPES)的差距。
实验设计
将PN-SILVER扩展至2-10倍规模,训练ROBERTA-LARGE并在POLITIFACT上评估AUC。
实验结果
-
PN-SILVER规模扩大至5倍前,模型AUC持续提升。
-
规模超过5倍后,性能趋于平稳,无显著增长。
-
同等规模下,SNOPES(人类撰写数据)训练的模型AUC更高。
实验结论
-
生成数据规模扩大能提升检测性能,但存在瓶颈(5倍后饱和)。
-
生成数据与人类虚假新闻在风格、意图上仍有差距,需进一步优化生成策略。
相关问题
Q1:抽取式摘要模型 vs 抽象式摘要模型
-
抽取式摘要模型
-
定义:从原文中直接抽取关键句子 / 短语,按逻辑顺序拼接成摘要,不产生新词汇或新表达。
-
核心逻辑:“筛选 + 重组”,本质是对原文重要信息的 “搬运”,不涉及语义的深度改写。
-
示例(对应前文研究):Liu and Lapata (2019) 的抽取式摘要模型,通过计算句子在原文中的重要性得分(如是否易被纳入摘要),筛选出 “显著句”(如新闻中影响核心语义的句子)。
-
-
抽象式摘要模型
-
定义:基于原文语义理解与重构,生成原文中不存在的新句子,可概括、改写、融合原文信息,更贴近人类写作逻辑。
-
核心逻辑:“理解 + 创造”,需捕捉原文语义核心,再用新的语言表达输出,可能包含原文无直接对应的词汇或句式。
-
示例:BART(Lewis et al., 2020)、GPT 系列,前文研究中用 BART 生成虚假信息替换显著句,就是基于原文上下文进行的抽象式生成。
-