在数据分析中,我们常说:“一张好的图表胜过千言万语。”
但很多时候,我们做出来的图表却是“千言万语堵在心口难开”。读者看了半天,抓不住重点。
这是为什么?
因为人类的视觉感知遵循一套被称为 格式塔(Gestalt) 的心理学原理。
简单来说,当我们看到一组物体时,大脑会自动将它们视为一个整体或一种模式,而不是孤立的碎片。
下面我们用 Python 的 Matplotlib 库,来演示 格式塔(Gestalt) 心理学中的 6 个核心原理,看看如何利用这些原理“控制”读者的注意力。
1. 邻近原理:距离产生“关系”
邻近原理就是距离越近,关系越亲,我们的大脑会自动把靠得近的物体归为一类。
就像在一个派对上,站在一起聊天的几个人,你会下意识觉得他们是一伙的。
# 邻近原理
# 创建测试数据
np.random.seed(42)
data_a = np.random.normal(5, 1.5, 30)
data_b = np.random.normal(10, 1.5, 30)
data_c = np.random.normal(15, 1.5, 30)# 不使用邻近原理
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))# 左侧:未应用邻近原理(所有点均匀分布)
all_data = np.concatenate([data_a, data_b, data_c])
x_positions = np.arange(90)
ax1.scatter(x_positions, all_data, alpha=0.7)
ax1.grid(True, alpha=0.3)# 右侧:应用邻近原理(按组聚集)
for i, (data, x_offset) in enumerate(zip([data_a, data_b, data_c], [0, 30, 60])):x_positions = np.arange(len(data)) + x_offsetax2.scatter(x_positions, data, alpha=0.7, label=f'组{i+1}')plt.tight_layout()
plt.show()
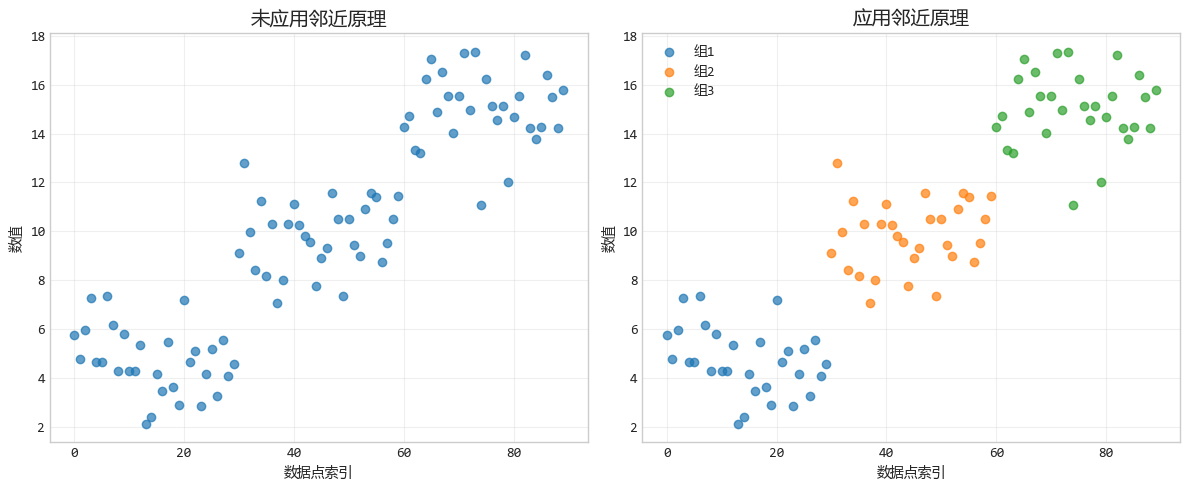
设计要点:将相关的数据点或元素放在靠近的位置,可以让观众自然地理解它们属于同一类别或具有某种关联。
2. 相似原理:相似的“性格”吸引
相似原理就是长得像的,就是一家人,当物体在颜色、形状或大小上相似时,大脑会将它们分为一组。
比如在足球场上,穿着相同颜色球衣的人,你不需要看清他们的脸,就知道他们是队友。
# 相似原理
# 创建测试数据
categories = ["A", "B", "C", "D", "E"]
values1 = [12, 16, 14, 18, 15]
values2 = [8, 11, 9, 12, 10]
x_pos = np.arange(len(categories))# 相似原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))# 左侧:未应用相似原理(随机颜色和样式)
bars1 = ax1.bar(x_pos - 0.2, values1, 0.4, color=colors1, edgecolor="black")
bars2 = ax1.bar(x_pos + 0.2, values2, 0.4, color=colors2, edgecolor="black", hatch=hatches[0]
)# 为每组条形添加不同图案
for i, bar in enumerate(bars2):bar.set_hatch(hatches[i % len(hatches)])# 右侧:应用相似原理(一致的颜色和样式)
ax2.bar(x_pos - 0.2, values1, 0.4, color="skyblue", edgecolor="black", label="数据集1")
ax2.bar(x_pos + 0.2, values2, 0.4, color="lightcoral", edgecolor="black", label="数据集2"
)plt.tight_layout()
plt.show()
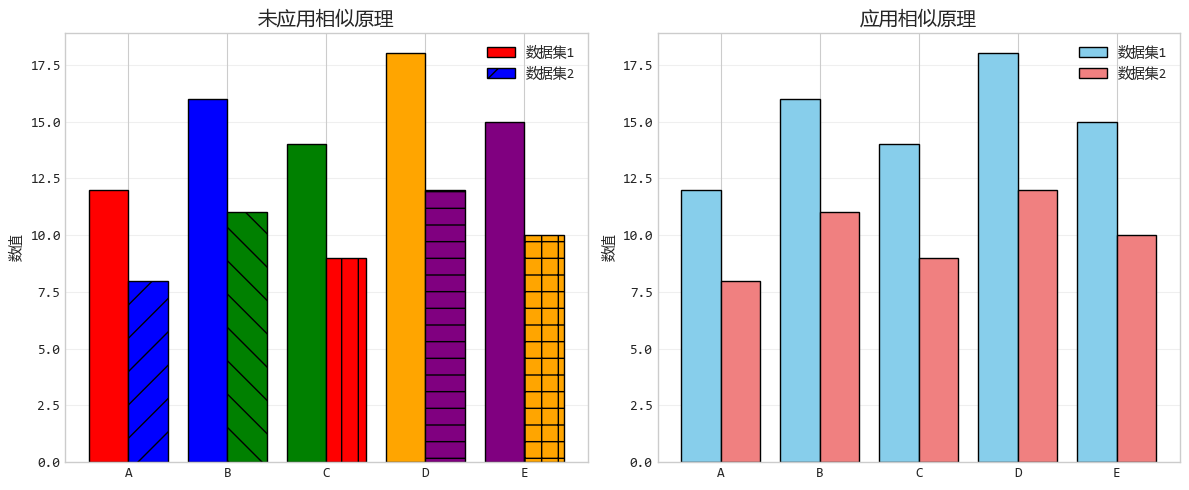
设计要点:使用一致的颜色、形状或样式来表示相同类型的数据,可以大大降低观众的认知负担。
3. 包围原理:边界创造"归属感"
包围原理就是有围墙的地方就是家。如果在某些物体周围加上边界或背景色,它们就被视为一个独立的群体。
这个原理甚至比 “邻近” 和 “相似” 更强大。
比如,草地上散落着羊群,一旦你用栅栏圈住其中几只,大家就会认为这几只是被特别选中的。
# 包围原理
# 创建测试数据
np.random.seed(42)
x1 = np.random.normal(2, 0.8, 50)
y1 = np.random.normal(3, 0.8, 50)x2 = np.random.normal(5, 0.8, 50)
y2 = np.random.normal(5, 0.8, 50)# 包围原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))# 左侧:未应用包围原理
ax1.scatter(x1, y1, alpha=0.7, color="blue")
ax1.scatter(x2, y2, alpha=0.7, color="red")# 右侧:应用包围原理
from matplotlib.patches import Ellipseax2.scatter(x1, y1, alpha=0.7, color="blue", label="组A")
ax2.scatter(x2, y2, alpha=0.7, color="red", label="组B")# 添加包围区域
ellipse1 = Ellipse((2, 3), width=4, height=3, edgecolor="blue")
ellipse2 = Ellipse((5, 5), width=4, height=3, edgecolor="red")ax2.add_patch(ellipse1)
ax2.add_patch(ellipse2)plt.tight_layout()
plt.show()
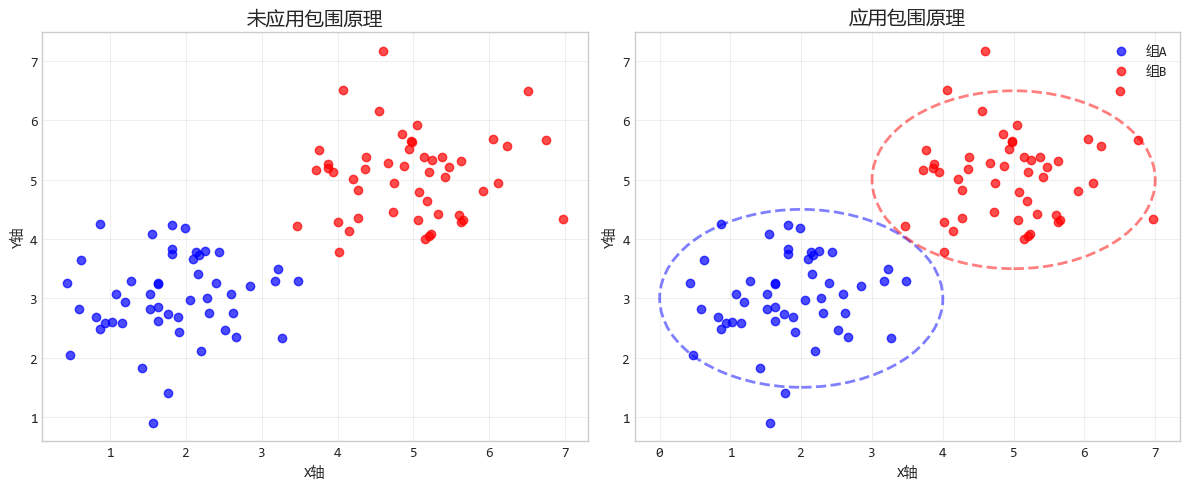
设计要点:使用边界、背景色或容器将相关的数据元素包围起来,可以明确地告诉观众这些元素属于同一组。
4. 闭合原理:大脑的"自动补全"
闭合原理就是大脑是天生的“补图高手”。即使图形不完整,只要有足够的提示,大脑也会自动脑补出缺失的部分。
比如看到一个虚线画圆,你不会觉得那是断断续续的线段,你会直接说:“这是一个圆”。
# 闭合原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))# 创建一些不完整的数据点
np.random.seed(42)
angles = np.linspace(0, 2*np.pi, 7)[:-1] # 故意少一个点形成不闭合
radii = np.random.uniform(3, 5, 6)
x = radii * np.cos(angles)
y = radii * np.sin(angles)# 左侧:不完整的形状(未利用闭合原理)
ax1.plot(x, y, 'o-', linewidth=2, markersize=8)# 右侧:闭合的形状(应用闭合原理)
# 添加缺失的点使形状闭合
angles_closed = np.linspace(0, 2*np.pi, 7)
radii_closed = np.append(radii, radii[0]) # 回到起点
x_closed = radii_closed * np.cos(angles_closed)
y_closed = radii_closed * np.sin(angles_closed)ax2.plot(x_closed, y_closed, 'o-', linewidth=2, markersize=8)
ax2.fill(x_closed, y_closed, alpha=0.3) # 填充增强闭合感plt.tight_layout()
plt.show()
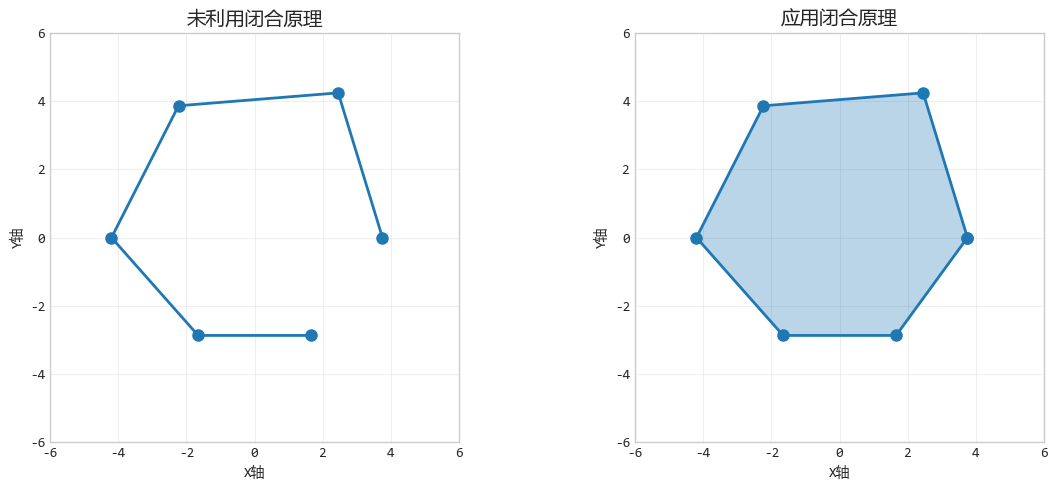
设计要点:我们不需要展示每一个细节,可以利用观众的自动补全能力来简化图表。
但要注意,过于不完整的图形可能导致误解。
5. 连续原理:流畅的"视觉路径"
连续原理就是顺藤摸瓜。我们的视线倾向于跟随平滑、连续的路径,而不是剧烈折线或不规则的排列。
比如排队时,如果队伍弯弯曲曲但每个人都看着前一个人的后脑勺,你知道这还是一条队。
# 连续原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))# 创建数据
np.random.seed(42)
time = np.arange(0, 10, 0.1)
signal1 = np.sin(time) + np.random.normal(0, 0.1, len(time))
signal2 = np.cos(time) + np.random.normal(0, 0.1, len(time))# 左侧:不连续的展示
ax1.plot(time[:50], signal1[:50], 'b-', linewidth=2, label='信号A (第一部分)')
ax1.plot(time[70:], signal1[70:], 'b--', linewidth=2, label='信号A (第二部分)')
ax1.plot(time[:40], signal2[:40], 'r-', linewidth=2, label='信号B (第一部分)')
ax1.plot(time[60:], signal2[60:], 'r--', linewidth=2, label='信号B (第二部分)')# 右侧:连续的展示
ax2.plot(time, signal1, 'b-', linewidth=2, label='信号A')
ax2.plot(time, signal2, 'r-', linewidth=2, label='信号B')plt.tight_layout()
plt.show()
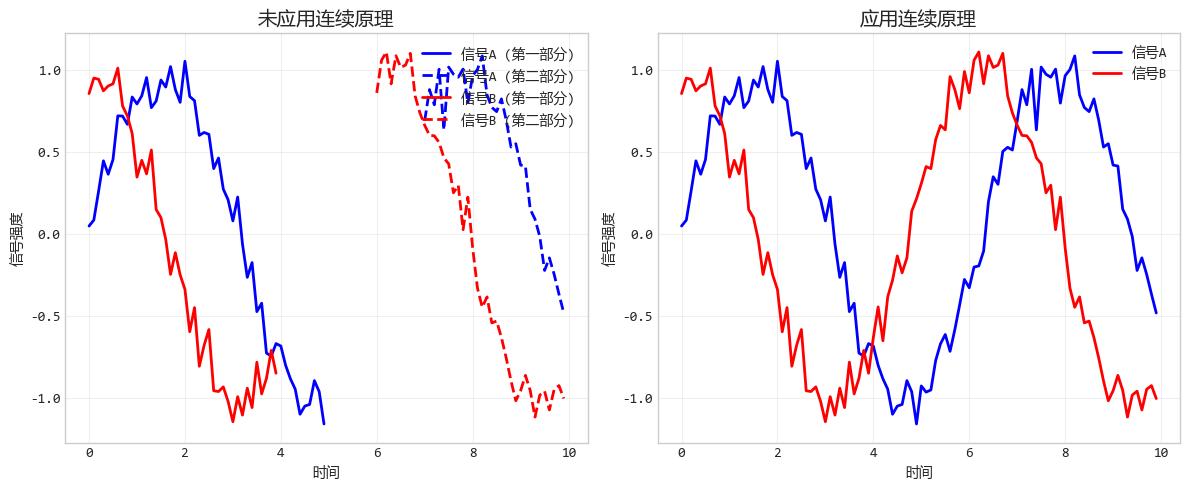
设计要点:保持线条、形状或元素的连续性可以帮助观众追踪数据的变化趋势。在折线图、面积图中尤其重要。
6. 连接原理:看得见的"关系线"
连接原理就是藕断丝连。被线连接的物体,被视为强关联。这个视觉信号比颜色和距离都要强。
比如,两个人站得再远,如果手里牵着一根绳子,你也会觉得他们俩在互动。
# 连接原理示例 - 散点图版本
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))# 创建散点数据:4个相关点集,每个点集有5个点
np.random.seed(42)
n_points = 5
n_groups = 4# 为每组生成相关点
groups = []
for i in range(n_groups):center_x = np.random.uniform(2, 8)center_y = np.random.uniform(2, 8)# 生成围绕中心的相关点x_points = center_x + np.random.normal(0, 0.8, n_points)y_points = center_y + np.random.normal(0, 0.8, n_points)# 添加一些趋势trend = np.random.uniform(-1, 1)y_points = y_points + trend * (x_points - center_x)groups.append((x_points, y_points))# 左侧:未应用连接原理(独立的散点)
colors = ["blue", "red", "green", "orange"]
markers = ["o", "s", "^", "D"]for i, (x_points, y_points) in enumerate(groups):ax1.scatter(x_points,y_points,color=colors[i],marker=markers[i],alpha=0.7,s=80,label=f"数据集{i+1}",)# 右侧:应用连接原理(连接相关散点)
for i, (x_points, y_points) in enumerate(groups):# 首先绘制连接线# 按照x值排序,使连接线更有序sorted_indices = np.argsort(x_points)sorted_x = x_points[sorted_indices]sorted_y = y_points[sorted_indices]ax2.plot(sorted_x,sorted_y,color=colors[i],linewidth=2,alpha=0.5,linestyle="--",label=f"数据集{i+1}趋势线",)# 然后绘制散点(在线上方,避免被线遮挡)ax2.scatter(x_points,y_points,color=colors[i],marker=markers[i],alpha=0.7,s=80,edgecolor="black",linewidth=1,)plt.tight_layout()
plt.show()
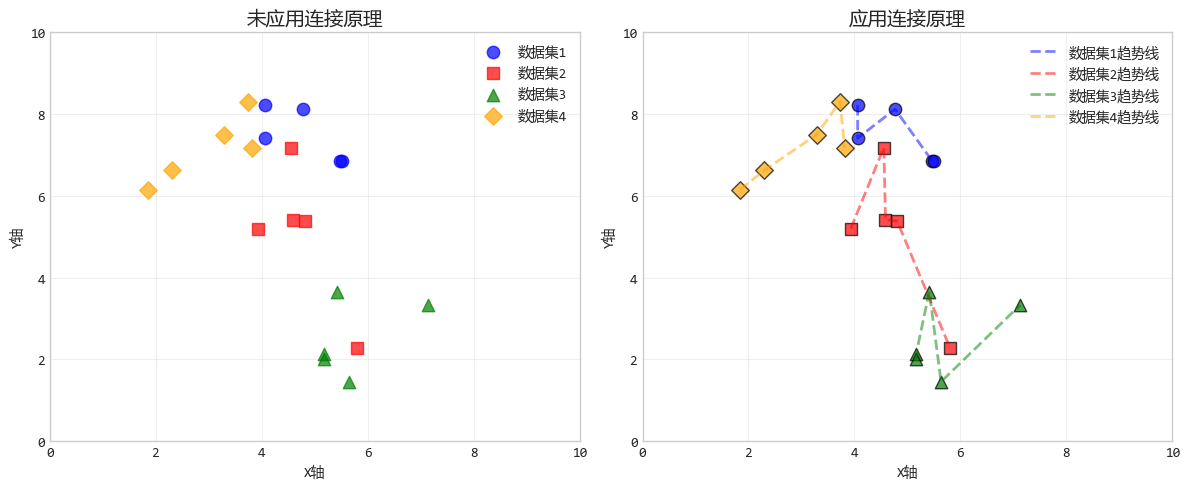
设计要点:在散点图中,连接相关数据点的线可以帮助观众识别出数据的模式、趋势或分组关系。
这就像在地图上连接各个城市来显示旅行路线一样,使相关的点之间建立了明确的视觉联系。
7. 总结
做数据可视化,不仅仅是写代码画图,更是一场 “注意力争夺战”。
通过这 6 个格式塔原理,我们不是在改变数据本身,而是在优化数据的呈现方式,让读者的脑力消耗降到最低。
每次我们画图时,不妨问自己一句:
- “这些数据应该是一组吗?它们靠得够近吗?”(邻近)
- “重点数据突出了吗?”(包围/相似)
- “视线流动顺畅吗?”(连续)
最好的可视化不是展示所有数据,而是引导观众看到最重要的信息。格式塔原理就是我们实现这一目标的强大工具。
希望这篇文章能帮助你在创建数据可视化时,更加有意地引导观众的注意力。