Scikit-learn 深度技术解析:架构、设计与实现原理
1. 整体介绍
1.1 项目概况
Scikit-learn(通常写作 scikit-learn 或 sklearn)是一个基于 Python 的开源机器学习库。项目托管于 GitHub,地址为 https://github.com/scikit-learn/scikit-learn。作为机器学习领域最受欢迎的库之一,截至当前分析,其在 GitHub 上拥有超过 50,000 个 Star 和 23,000 个 Fork,体现了其广泛的社区采纳度和影响力。
项目始于 2007 年,是 David Cournapeau 的 Google Summer of Code 项目。如今,它由一个活跃的志愿者团队维护,是 Python 科学计算生态(SciPy 栈)的核心组成部分之一。
1.2 主要功能与定位
Scikit-learn 的核心使命是提供一套简单高效的工具,用于数据挖掘和数据分析。其设计哲学强调:
- 一致的API:所有估计器(Estimator)都遵循
fit、predict、transform等统一接口。 - 良好的文档:提供全面的用户指南、API 参考和示例。
- 丰富的算法:覆盖了监督学习、无监督学习、模型选择、数据预处理等机器学习全流程。
- 生产就绪:强调代码质量、测试覆盖率和性能优化。
其功能架构可以概括为以下核心模块:
- 分类、回归、聚类、降维:实现经典机器学习算法。
- 模型选择:提供交叉验证、超参数调优(
GridSearchCV,RandomizedSearchCV)工具。 - 数据预处理:包括标准化、编码、特征提取等。
- 流水线(Pipeline):将多个处理步骤串联,封装为单一估计器。
1.3 解决的问题与目标用户
面临的问题:
- 算法实现复杂:机器学习算法理论深厚,从零实现成本高、易出错。
- 接口不统一:不同算法库的 API 各异,增加了学习成本和集成难度。
- 工程化困难:将实验原型转化为稳定、可维护的生产代码存在挑战。
- 评估与调优繁琐:手动实现可靠的模型评估、验证和超参数优化流程工作量大。
目标用户与场景:
- 数据科学家/分析师:快速进行数据探索、建模实验和原型开发。
- 机器学习工程师:构建可靠、可复现的机器学习流水线并部署。
- 研究人员与学生:学习机器学习原理,复现和对比算法。
- 教育领域:作为机器学习课程的实践工具。
1.4 解决方案与演进优势
传统/旧方式:
在 scikit-learn 出现之前或早期,用户可能需要:
- 混合使用 MATLAB、R、Weka 等工具,工作流割裂。
- 直接使用 SciPy/NumPy 手动实现算法,对数学和编程要求极高。
- 依赖多个独立、接口不兼容的 Python 库。
Scikit-learn 的新方式:
- 统一接口:
fit、predict、transform、score等模式成为标准,降低了认知负荷。 - 功能集成:在一个库内集成了从数据清洗到模型部署的全套工具链。
- 工业级质量:严格的代码审查、持续的集成测试和详尽的文档保证了库的稳健性。
- 社区驱动:活跃的社区贡献带来了持续的算法更新、性能优化和问题修复。
1.5 商业价值预估
从代码成本角度看,要构建一个同等规模、质量和算法覆盖度的专有机器学习库,需要投入一个由数十名资深算法和系统工程师组成的团队数年时间,开发成本可能达到数千万人民币级别。
从覆盖问题空间效益看,scikit-learn 解决的是机器学习应用中的 “基础设施” 问题。它极大地降低了各行各业应用机器学习的门槛:
- 金融风控:信用评分、欺诈检测。
- 推荐系统:用户兴趣建模。
- 工业预测:设备故障预警、销量预测。
- 生物信息:基因序列分析。
其效益并非直接产生收入,而是通过赋能其他业务系统,提升其智能化水平和决策效率,从而产生间接但巨大的经济价值。据估算,其全球用户群体节省的开发和时间成本每年可达数十亿美元量级。
2. 详细功能拆解(产品与技术视角)
Scikit-learn 不仅仅是一个算法集合,更是一个精心设计的机器学习框架。其核心功能设计围绕以下几个关键抽象展开:
-
估计器(Estimator)抽象:
- 产品视角:提供统一的“模型”概念。用户无需关心内部实现,只需知道如何“训练”(
fit)和“使用”(predict/transform)。 - 技术视角:由
BaseEstimator类定义基础协议,包括参数管理(get_params/set_params)、克隆(clone)和验证。
- 产品视角:提供统一的“模型”概念。用户无需关心内部实现,只需知道如何“训练”(
-
预测器(Predictor)与转换器(Transformer):
- 产品视角:区分“有监督学习”(输入
X和y,输出预测)和“无监督/特征工程”(输入X,输出变换后的X)。 - 技术视角:通过
ClassifierMixin、RegressorMixin、TransformerMixin等 Mixin 类,为BaseEstimator注入特定行为(如score方法)。
- 产品视角:区分“有监督学习”(输入
-
元估计器(Meta-Estimator):
- 产品视角:提供“模型增强”功能,如集成学习(
Bagging,AdaBoost)、多输出学习、模型选择工具。 - 技术视角:通过
MetaEstimatorMixin标识,并利用BaseEstimator的嵌套参数管理能力(estimator__param语法)来组合其他估计器。
- 产品视角:提供“模型增强”功能,如集成学习(
-
流水线(Pipeline)与特征联合(FeatureUnion):
- 产品视角:将数据预处理、特征工程、建模等步骤串联或并联,形成一个可重复部署的完整工作流。
- 技术视角:本身也是估计器,通过实现标准的
fit/transform/predict接口,内部按顺序调用各步骤的对应方法。
-
模型选择与评估框架:
- 产品视角:提供系统化的方法来评估模型泛化能力、比较不同算法、搜索最佳超参数。
- 技术视角:
cross_val_score、GridSearchCV等函数/类实现了重采样策略,并与估计器接口无缝集成,通过克隆机制保证实验的独立性。
3. 技术难点与核心因子
-
内存与计算效率:
- 难点:处理大规模数据时,需要高效利用内存并支持并行计算。
- 因子:深度集成 NumPy 数组操作;利用
joblib进行智能缓存和并行化;通过 Cython 编写核心算法循环;使用threadpoolctl控制原生线程库(如 OpenMP、MKL)的线程数以避免过度订阅。
-
API 的一致性与可扩展性:
- 难点:在保持数百个算法接口统一的同时,允许第三方和用户自定义算法无缝集成。
- 因子:基于 Mixin 和抽象基类的设计模式;严格的贡献指南和代码审查;通过
__sklearn_tags__协议实现动态能力发现。
-
随机数生成(RNG)控制:
- 难点:确保算法(尤其是涉及随机性的,如随机森林、SGD)的结果在给定种子下可复现,同时支持并行环境。
- 因子:定义
random_state参数规范;在setup_module和测试框架中通过SKLEARN_SEED环境变量全局控制;在并行作业中正确分发子 RNG。
-
元数据路由:
- 难点:在复杂的流水线或元估计器中,如何将
fit等方法的额外参数(如样本权重sample_weight)正确路由到内部需要它的子估计器。 - 因子:引入
_MetadataRequester和get_metadata_routing机制(从提供代码的_routing_enabled()检查可见),这是一个较新的高级特性。
- 难点:在复杂的流水线或元估计器中,如何将
-
输入/输出数据容器兼容性:
- 难点:支持多种输入类型(NumPy 数组、SciPy 稀疏矩阵、pandas DataFrame)并按要求输出。
- 因子:
_SetOutputMixin和set_outputAPI;在输入时使用check_array等验证和转换函数。
4. 详细设计图
4.1 核心架构图
4.2 核心工作流序列图(以 Pipeline.fit 为例)
4.3 核心类图(简化)
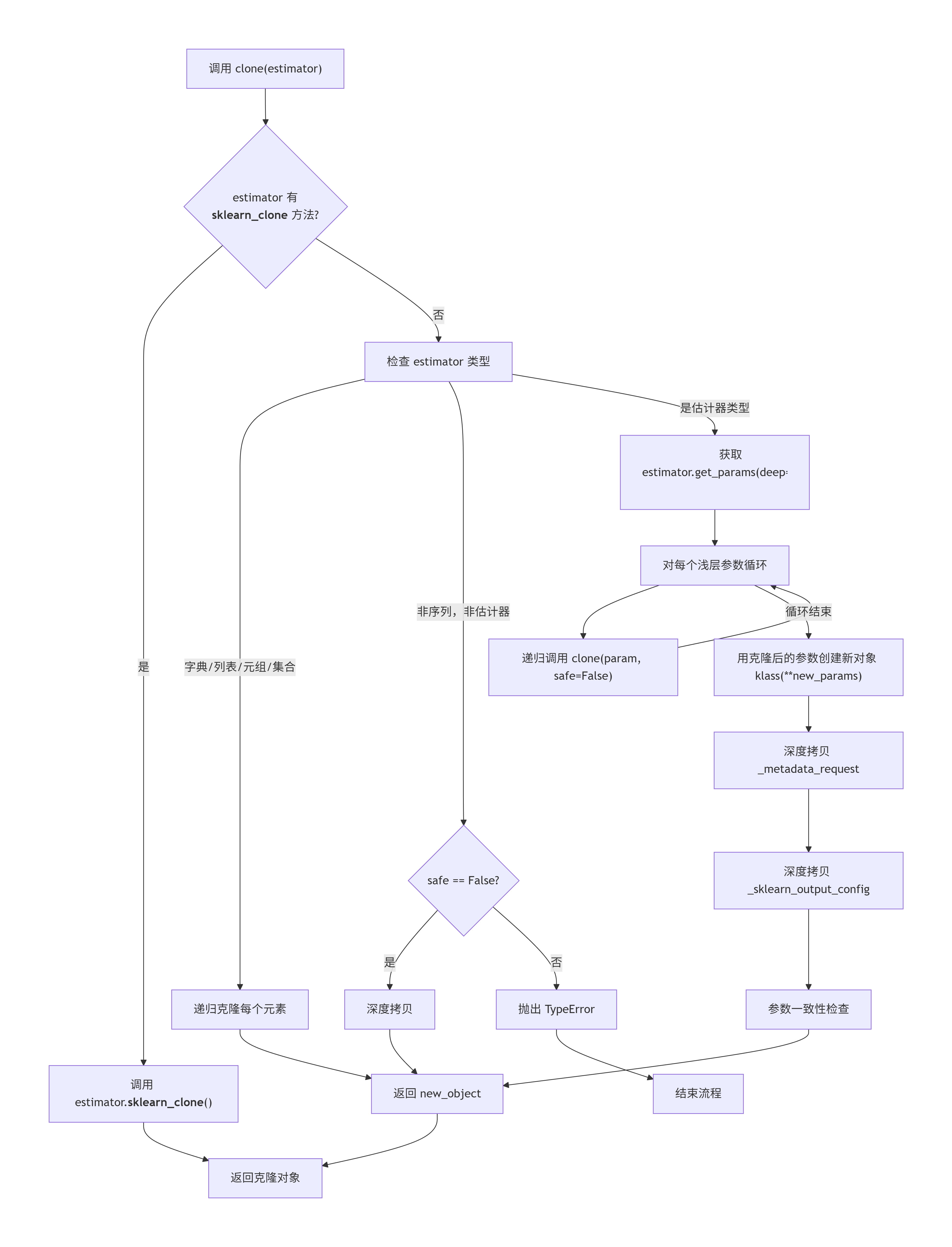
4.4 核心函数 clone 的拆解流程图
5. 核心函数与类解析
5.1 BaseEstimator:所有估计器的基石
BaseEstimator 通过元编程和约定,实现了估计器的核心生命周期管理。
核心方法 get_params 和 set_params 解析:
这两个方法使得 scikit-learn 的估计器能与 GridSearchCV 等元估计器协同工作,实现自动化超参数调优。
def get_params(self, deep=True):"""获取此估计器的参数。通过反射获取 __init__ 中定义的参数名,然后读取实例属性。如果 deep=True,则递归地对子估计器调用 get_params。"""out = dict()for key in self._get_param_names(): # 1. 获取参数名列表value = getattr(self, key)if deep and hasattr(value, "get_params") and not isinstance(value, type):# 2. 递归处理嵌套估计器,参数名用‘__’连接deep_items = value.get_params().items()out.update((key + "__" + k, val) for k, val in deep_items)out[key] = valuereturn outdef set_params(self, **params):"""设置此估计器的参数。支持通过‘__’语法设置嵌套估计器的参数。例如: pipeline.set_params(svm__C=10)"""if not params:return selfvalid_params = self.get_params(deep=True) # 用于验证nested_params = defaultdict(dict)for key, value in params.items():key, delim, sub_key = key.partition("__") # 分割嵌套参数if key not in valid_params:raise ValueError(f"Invalid parameter {key!r}...")if delim:# 嵌套参数,临时存储nested_params[key][sub_key] = valueelse:# 直接参数,直接设置属性setattr(self, key, value)valid_params[key] = value# 处理嵌套参数,递归调用子估计器的 set_paramsfor key, sub_params in nested_params.items():valid_params[key].set_params(**sub_params)return self # 支持链式调用
设计亮点:
_get_param_names方法:通过inspect模块分析__init__方法的签名,自动获取参数名。这使得开发者只需在__init__中声明参数,无需额外维护参数列表。- 嵌套参数语法:
param__subparam的语法设计非常巧妙,它通过字符串操作和递归,将复杂的嵌套对象参数管理变得简单统一。 - 返回
self:set_params返回self,支持链式调用,例如estimator.set_params(a=1).fit(X, y)。
5.2 clone 函数:实现估计器的安全复制
clone 是模型选择和交叉验证的基石,它创建了一个参数相同但未拟合的估计器副本。
def clone(estimator, *, safe=True):"""构造一个具有相同参数的新未拟合估计器。"""# 优先级:如果估计器定义了自定义克隆方法,则使用它if hasattr(estimator, "__sklearn_clone__") and not inspect.isclass(estimator):return estimator.__sklearn_clone__()# 否则,使用默认实现return _clone_parametrized(estimator, safe=safe)def _clone_parametrized(estimator, *, safe=True):"""克隆的默认实现。"""klass = estimator.__class__# 获取“浅层”参数(即直接传递给__init__的参数)new_object_params = estimator.get_params(deep=False)# 关键:递归克隆每一个浅层参数for name, param in new_object_params.items():new_object_params[name] = clone(param, safe=False)# 使用克隆后的参数实例化一个新对象new_object = klass(**new_object_params)# 复制元数据请求和输出配置(用于较新的API)try:new_object._metadata_request = copy.deepcopy(estimator._metadata_request)except AttributeError:passif hasattr(estimator, "_sklearn_output_config"):new_object._sklearn_output_config = copy.deepcopy(estimator._sklearn_output_config)return new_object
技术难点与解决方案:
- 避免拟合状态被复制:
clone不复制任何以_结尾的属性(这是 scikit-learn 的约定,表示拟合后的状态),只复制构造参数。 - 处理随机状态:文档中特别说明,如果
random_state是整数,则克隆是“精确的”;否则是“统计的”。这要求算法内部正确使用random_state参数来初始化其内部 RNG。 - 递归克隆:通过
get_params(deep=False)获取顶层参数,然后对每个参数递归调用clone,确保了嵌套结构(如Pipeline中的步骤列表)也被正确复制。
5.3 Mixin 类:灵活的行为注入
Mixin 类是多继承的一种应用,用于为 BaseEstimator 添加特定功能。
class ClassifierMixin:"""所有分类器的Mixin类。"""def __sklearn_tags__(self):# 调用父类的 __sklearn_tags__,然后修改标签tags = super().__sklearn_tags__()tags.estimator_type = "classifier"tags.classifier_tags = ClassifierTags()tags.target_tags.required = True # 分类器需要 yreturn tagsdef score(self, X, y, sample_weight=None):"""默认使用准确率作为评分。"""from sklearn.metrics import accuracy_scorereturn accuracy_score(y, self.predict(X), sample_weight=sample_weight)
设计价值:
- 分离关注点:
BaseEstimator负责通用管理,ClassifierMixin负责分类-specific 的逻辑(如score方法)。 - 动态标签系统:
__sklearn_tags__方法返回一个Tags对象,该对象描述了估计器的能力(如是否支持多输出、是否需要y等)。这使得像is_classifier这样的工具函数无需硬编码类型检查,只需读取标签。这是一个运行时类型自省的优雅设计。 - 组合性:一个类可以通过继承多个 Mixin 来组合功能(尽管需注意方法解析顺序 MRO)。
5.4 _fit_context 装饰器:统一的参数验证上下文
def _fit_context(*, prefer_skip_nested_validation):"""装饰器,用于在上下文管理器中运行估计器的 fit 方法。"""def decorator(fit_method):@functools.wraps(fit_method)def wrapper(estimator, *args, **kwargs):global_skip_validation = get_config()["skip_parameter_validation"]# 如果已经拟合且是 partial_fit,则跳过验证partial_fit_and_fitted = (fit_method.__name__ == "partial_fit" and _is_fitted(estimator))if not global_skip_validation and not partial_fit_and_fitted:estimator._validate_params() # 验证构造参数# 在配置上下文中运行 fit 方法,控制内部验证的粒度with config_context(skip_parameter_validation=(prefer_skip_nested_validation or global_skip_validation)):return fit_method(estimator, *args, **kwargs)return wrapperreturn decorator
作用:
- 性能优化:在
fit内部可能调用其他函数或子估计器,通过config_context控制是否跳过它们的参数验证,避免重复检查。 - 灵活性:
prefer_skip_nested_validation参数允许元估计器(如Pipeline)在fit时跳过其内部步骤的验证(因为步骤的参数在构建Pipeline时已被验证过)。 - 全局控制:用户可以通过
sklearn.set_config全局关闭参数验证,用于生产环境以提升性能。
总结
Scikit-learn 的成功并非偶然,它是在清晰的设计哲学指导下,通过一系列精妙的技术抽象和扎实的工程实践构建而成的。其核心价值体现在:
- 一致且直观的 API 设计:降低了机器学习的使用门槛和认知负担。
- 模块化与组合性:通过估计器、Mixin、流水线等抽象,实现了算法和组件的灵活复用。
- 对可复现性和工程化的重视:从
clone、random_state到_fit_context,处处体现了对生产环境需求的考量。 - 强大的生态系统集成:深度融入 Python 科学计算栈,并与
pandas、matplotlib等库良好协作。
尽管近年来深度学习框架崛起,但 scikit-learn 在传统机器学习、特征工程、模型选择与评估以及作为轻量级、可解释模型的解决方案方面,仍然保持着不可替代的地位。其代码库本身也是一个学习软件架构和 API 设计的优秀范本。