1. 论文介绍
论文题目:Rethinking Graph Structure Learning in the Era of LLMs
论文领域:图神经网络, LLM
论文地址:https://arxiv.org/abs/2503.21223
论文代码:无
论文背景:

2. 论文摘要
近年来,LLMs 的出现促使研究人员将语言描述整合进图中,旨在从数据中心角度提升模型编码能力。这种图表示方式称为文本属性图(TAGs)。回顾以往进展表明,图结构学习(GSL)是提升数据利用性的关键技术,与高效 TAG 学习高度相关。然而,大多数 GSL 方法针对没有文本信息的传统图量身打造,凸显了开发新 GSL 范式的必要性。尽管动机明确,但仍然具有挑战性:(1)在大型语言模型(LLM)时代,鉴于大型语言模型(LLM)庞大参数,我们如何定义 GSL 合理的优化目标?(2)我们如何设计一个高效的模型架构,实现 LLM 无缝集成以实现这一优化目标?对于问题 1,我们将现有的 GSL 优化目标重新表述为树优化框架,将重点从获得训练良好的边缘预测器转向语言感知树采样器。对于问题 2,我们提出解耦且无训练的模型设计原则用于 LLM 集成,将重点从计算密集型微调转向更高效的推理。基于此,我们提出了大型语言与树辅助(LLaTA),利用基于树的上下文学习来增强对拓扑和文本的理解,实现可靠的推断并生成更好的图结构。对 11 个数据集的广泛实验表明,LLaTA 具有灵活性——任何骨干都具有;可扩展性优于其他 LLM 增强的图学习方法;有效性——实现 SOTA 预测性能。
3. 相关介绍
3.1 相关知识
作者的观察
观察一: 优化目标:图学习器作为边预测器,高度依赖于端到端训练,伴随着特定的下游骨干
问题一: 如何为LLM增强型GSL定义一个合理的优化目标?
回答一: 本文提出一个新的优化框架以现有的GSL优化目标重新表述为基于树的优化任务(定义良好的语言感知树采样器),以实现保持拓扑的结构优化。
观察二:模型架构: 现有的图学习器通常和定制的指令数据集或特定的图学习主干组成,并以监督学习进行模型参数更新
问题二: 如何将LLM无缝集成到模型架构中,实现高效的GSL
回答二: 基于解耦和无训练的设计原则,高效的LLM推断而非微调
3.1 结构熵
结构熵(SE),是量化图拓扑结构动态复杂性的有效测量方法。
通过最小化SE,可以减少结构不确定性并捕捉固有模式,从而以稳健且可解释的方式来支持下游任务。
3.2 文本属性图(TAG text-attributed graphs)
文本属性图指的是一种特殊的图数据结构,节点V代表实体(用户,商品,论文),边E代表实体间的关系(好友,引用,购买),文本属性T是关键,每个节点关联一段原始文本。
3.3 结构熵
结构熵用来衡量一个网络的无序度或不确定性。
- 基于度分布的熵,(所有节点的度差不多则熵高,若只有少数的超级枢纽节点,熵就低)
- 基于编码/社区的二维结构熵 (越符合网络真实结构的划分,结构熵就越低)
结构编码树,通过使用贪心算法来最小化SE(结构熵)。
结构编码树是为了计算图的结构熵也引入的数据结构,将图转为一个层次化的树状结构。
3.4 拓扑感知树
一种显式保留了原始图拓扑连接信息的层级结构。普通的结构编码树只关注 谁属于哪个组,(层级归属),拓扑感知树在此基础上还关注了“组和组之间是怎么连接的”(拓扑关系)
关注点:层级+连接
构建方式:在构建树的过程中,显式地将原始图中的边映射到树上,或者根据拓扑相似性来决定树的父子关系。
关键特性: 保留连接,拓扑距离敏感,上下文感知。
3.5 基于树的大语言模型推理(Tree-prompted LLM Inference)
一种将树形结构数据作为关键上下文输入给LLM,以引导模型进行更精准、更有逻辑推理的技术。
本来LLM是处理序列的,难以处理树状结构。最直接的方式是线性遍历树,把它拍扁喂给LLM。该方法的问题是丢失层级感知,注意力分散,推理逻辑弱。
应用: 将输入组织为树, 形成了思维树,能够对多个下一步进行评估和剪枝,找到最优的树路径。
3.6 对比的相关算法
基于SE的方法:现有的基于结构编码的方法都是利用结构编码树进行各种图任务
传统的GSL方法:可分为基于度量的方法,概率抽样法,可直接学习的方法。
基于LLM的GSL方法:GraphEdit(通过边预测器来添加邻居,通过精细调优的LLM优化节点连接性),LLM4RGNN(利用精细调优的LLM推断节点相关性,用于训练边预测器),LangGSL(将大语言模型和图结构学习结合,共同优化节点特征和图结构)
4. 核心算法
基于树的GSL优化管线和流程为
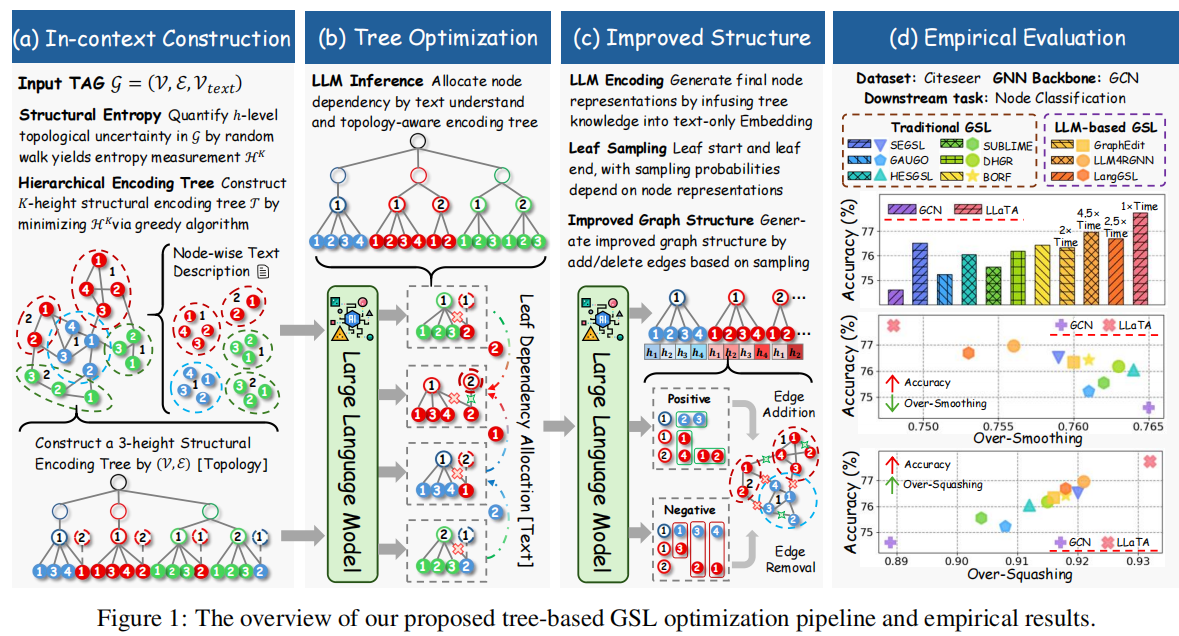
根据该框架,给出了本文的核心算法LLaTA算法
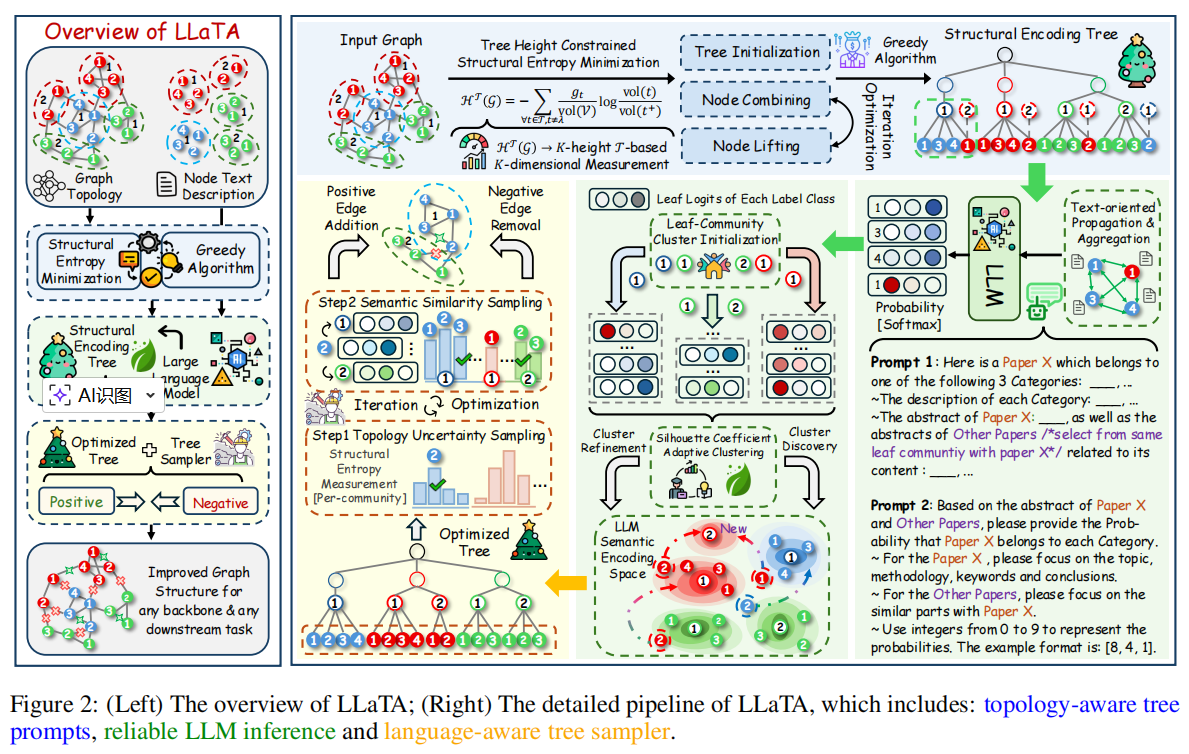
4.1 拓扑感知上下文构建
通过高质量提示实现高效的上下文学习,结构熵是构建这些提示的基础,用于捕捉局部和全局拓扑结构。
编码树和拓扑信息捕捉之间的关系

低层社区中的隐性全局约束:在结构编码树 𝒯 中,每个低层群 𝒞ℓ 落捕捉局部拓扑,但由于结构熵采用层级随机游走表述,隐含保留全局结构约束。
4.2 树提示的LLM推理
这些推断随后被用来优化编码树,增强低层社区内的同源性,并为后续的 GSL 奠定坚实基础。
关键思想是低层社区中的节点通常表现出高连接性和同质性,从而实现高效的文本共享。
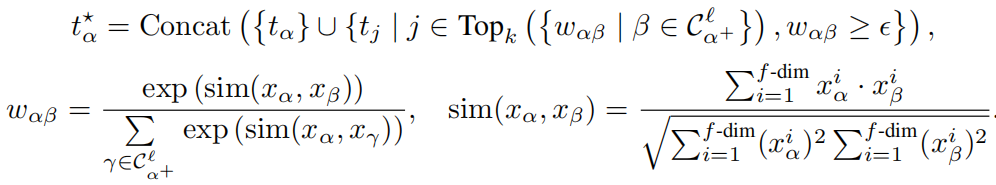
4.3 叶片导向两步采样(Leaf-oriented Two-step Sampling)
采用了两步采样技术,以平衡运行效率和实际性能
高熵节点需要监督
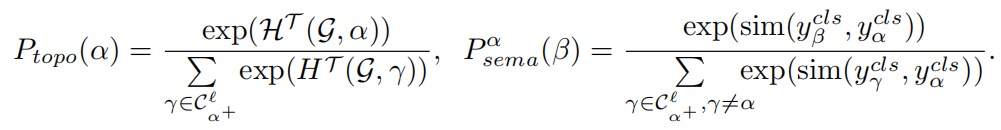
拓扑不确定性采样:
GSL 的核心是消除结构噪声并提升数据效用。值得注意的是,这种噪声通常只出现在某些子结构中,而非整个图。
语义相似性抽样:
选择节点后 α ,我们进一步确定候选邻居。
5. 实验设置
从四个维度来分析LLaTA算法的,效果,可解释性,稳健性,效率。
基线
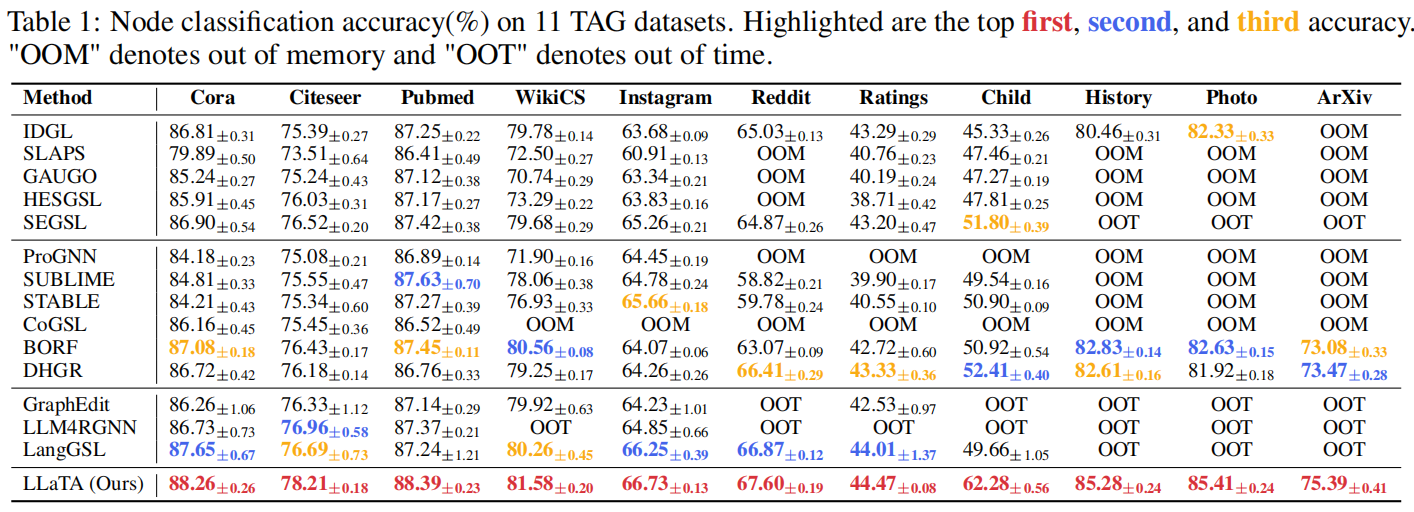
对比了LLaTA和其实14个GSL算法,数据集使用了11个广泛采用的TAG数据集。
节点分类的准确率
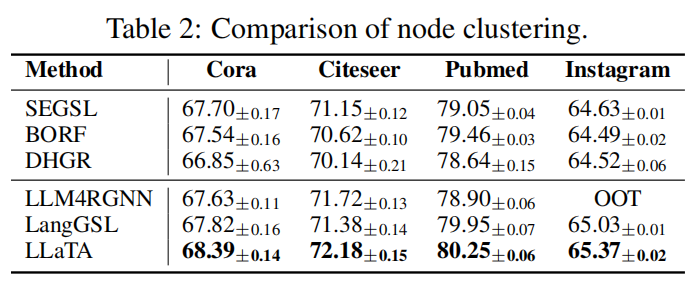
节点聚类的准确率
消融实验
分别去除LLaTA的各个模块,如TO(树优化),SAM为采样过程,LLM表示基于一跳邻居和随机游走序列的拓扑感知树上下文信息的LLM推断。
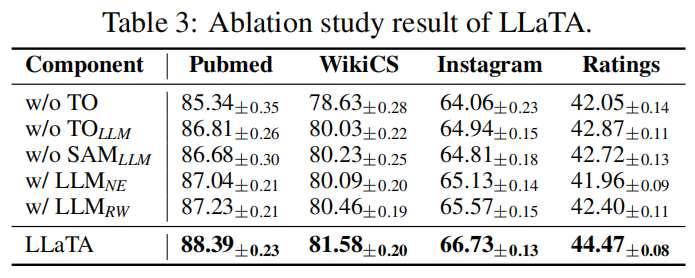
得到以下结论:
(1)移除 TO 会导致性能显著下降,表明树在基于 LLM 的 GSL 中起着关键作用。
(2) 用初始节点特征来指导 TO 和 SAM 替代 LLM 推断结果会导致性能下降。这凸显了 LLM 生成的上下文信息的关键作用,因为仅靠初始节点特征无法捕捉复杂的语义关系。
(3) 利用一跳邻居和随机游走序列提供拓扑感知的上下文信息也会导致性能下降。
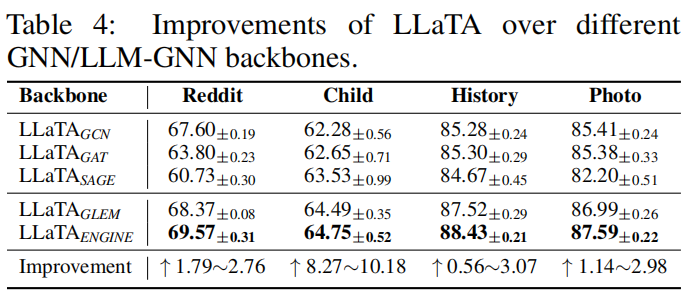
鲁棒性分析
LLaTA算法采用不同的GNN算法作为backbone的效果
6. 总结
LLaTA 重新思考 GSL 与大型语言模型的集成,提出了一个新的优化框架,解决了文本信息整合的挑战。随后,我们提出 LLaTA 作为该新框架的实例化,利用结构编码树实现高效的上下文中 LLM 学习。这使得 LLM 能够全面理解原始图中的拓扑和文本洞见,最终依靠可靠的推断以获得更好的图结构。
7. 个人感悟
代码没有公开,算法运行在对比效果上有一个较大提升,算法复现是个值得思考的问题。