一、先试试:直接导入网页
如果你第一次用 NotebookLM,多半会很自然地想:网页链接我都拿到了,直接丢进去不就完事了?
确实,NotebookLM 添加来源时可以选择 “网站(Website)”,然后粘贴你想导入的网址,把网页内容当作资料源塞进你的知识库。
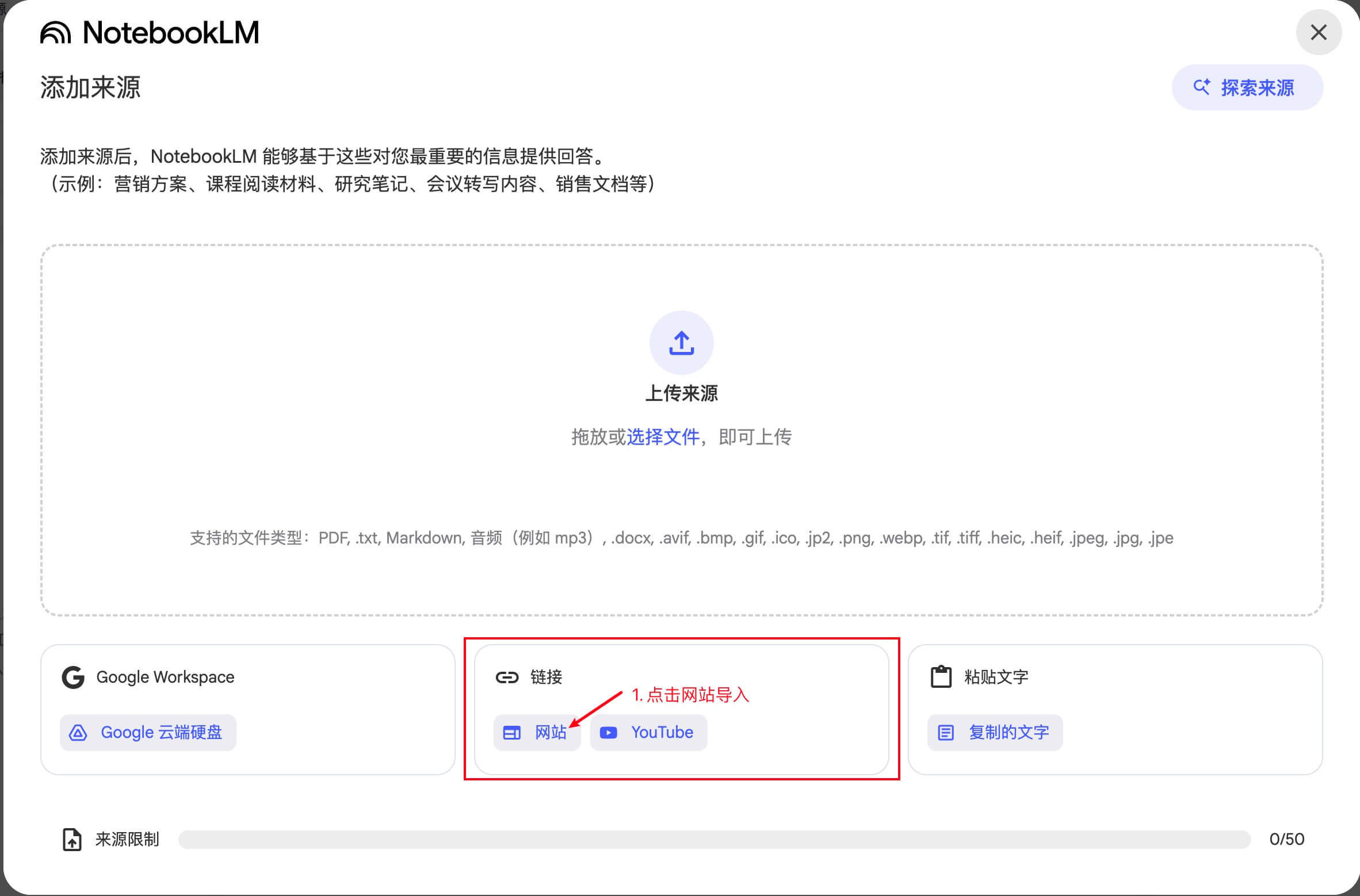
但注意:这一步“看起来很简单”,也是最容易让人卡住的一步。下面我们把坑先讲透,避免你反复试到怀疑人生。
二、为什么会失败:常见坑与原因
NotebookLM 支持网址导入没错,但现实世界更复杂:你会经常遇到抓取失败,导致网页怎么都导不进去。
这里随便找一篇我发布的文章
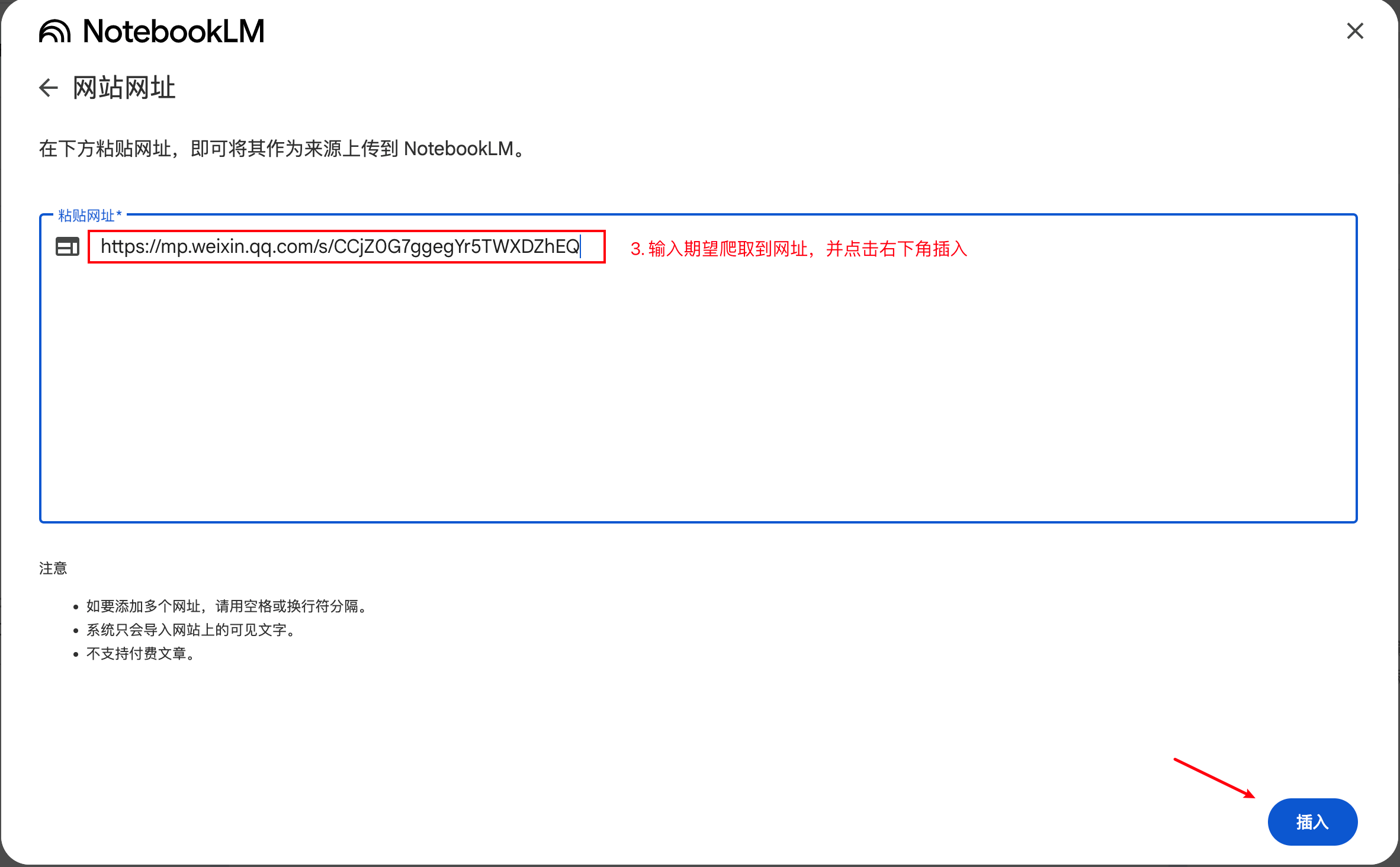
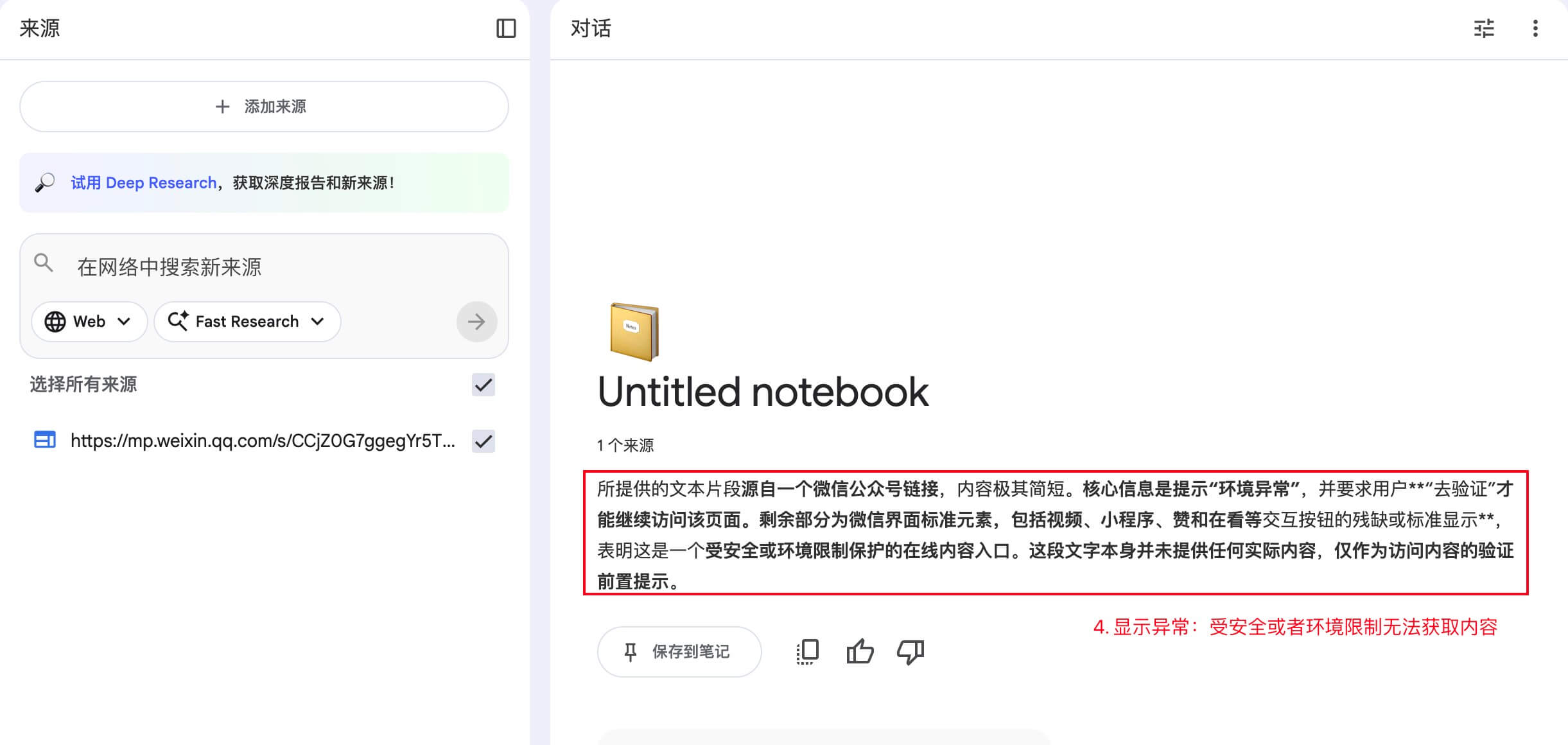
你会看到哪些报错?
当你把链接贴进去时,系统可能会给你一个 红色标签,意思很明确:它“够不着”这个网页。常见提示包括:
- 系统返回 “无效 URL” 警告(有些站点会频繁出现这个提示)。
- 系统提示 “上传失败,因为抓取 URL 时发生错误”(Upload failed due to an error fetching the URL)。
- 系统提示 “上传失败,因为发生了瞬时错误”(Upload failed due to a transient error)。
如果你发现某些新闻源/内容站点特别难导入——别慌,这大概率不是你操作问题。
背后的真正原因
这事儿看起来像“NotebookLM 不好用”,但很多时候真相是:网站不让它抓。
常见原因包括:
- AI 屏蔽机制:越来越多网站会阻止 AI 工具或 AI 代理访问页面内容。
- 付费墙与反制措施:部分文章受付费墙保护,会加更强的限制,防止被搬运。
- 网站选择退出:站点可能选择“退出”某些抓取行为,例如阻止 NotebookLM 可能使用的 Google-Extended 爬虫访问其内容。
- 瞬时错误:有些“瞬时错误”确实可能是服务侧波动或爬虫稳定性问题,属于你无法控制的外部因素。
三、终极解法:转 PDF 再导入
你可能会想:那我复制网页内容,粘贴进去总行吧?
很多时候——不行。要么排版乱、要么缺图、要么被截断;而“打印为 PDF”也经常因为站点脚本/分页/懒加载,导出来的 PDF 依然残缺。
更稳的思路是:把网页完整“打包”成 NotebookLM 更爱吃的格式——一份结构稳定的 PDF,再用“文件来源”上传。
方案:GoFullPage 一键转 PDF
当网站阻止内容收集,或你直接导入提示“无效 URL”时,可以用浏览器扩展把整页内容抓下来再导出 PDF。
-
工具简介:推荐使用名为 “GoFullPage(Full Page Screen Capture)” 的浏览器扩展程序,用于捕获整个网页内容并导出文件。
-
操作流程:
说明:使用其他浏览器同学,可以自行到对应浏览器商店搜索“GoFullPage”查找对应插件安装,这里以 chrome 浏览器安装为例说明安装过程
-
在 chrome 浏览器中安装并启用 GoFullPage 扩展。

-
点击插件管理入口,将刚刚安装到 gofullpage 固定在外面,方便操作

-
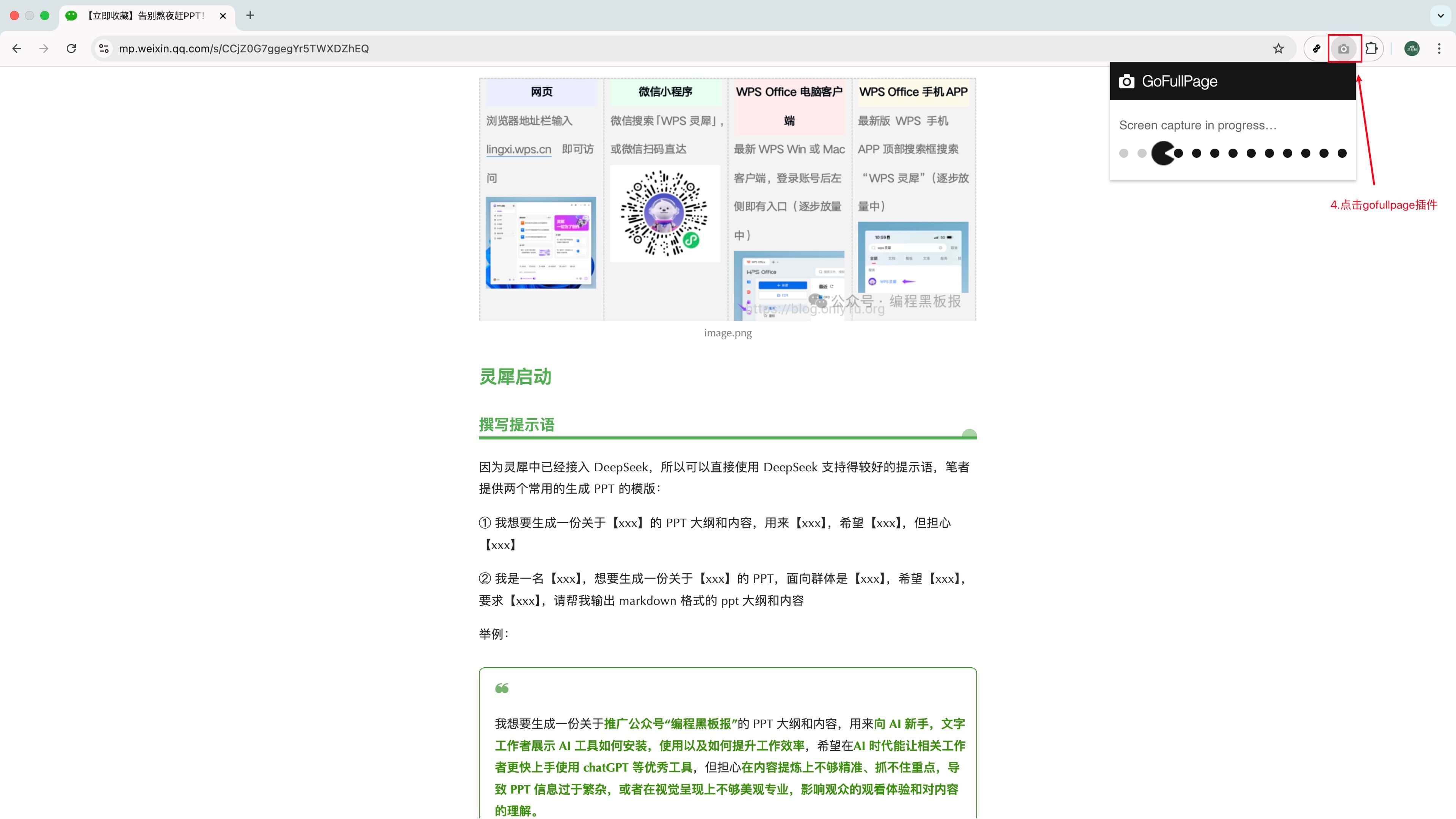
输入框中再次输入之前爬取失败网址,看成败人生豪迈,大不了重头再来

-
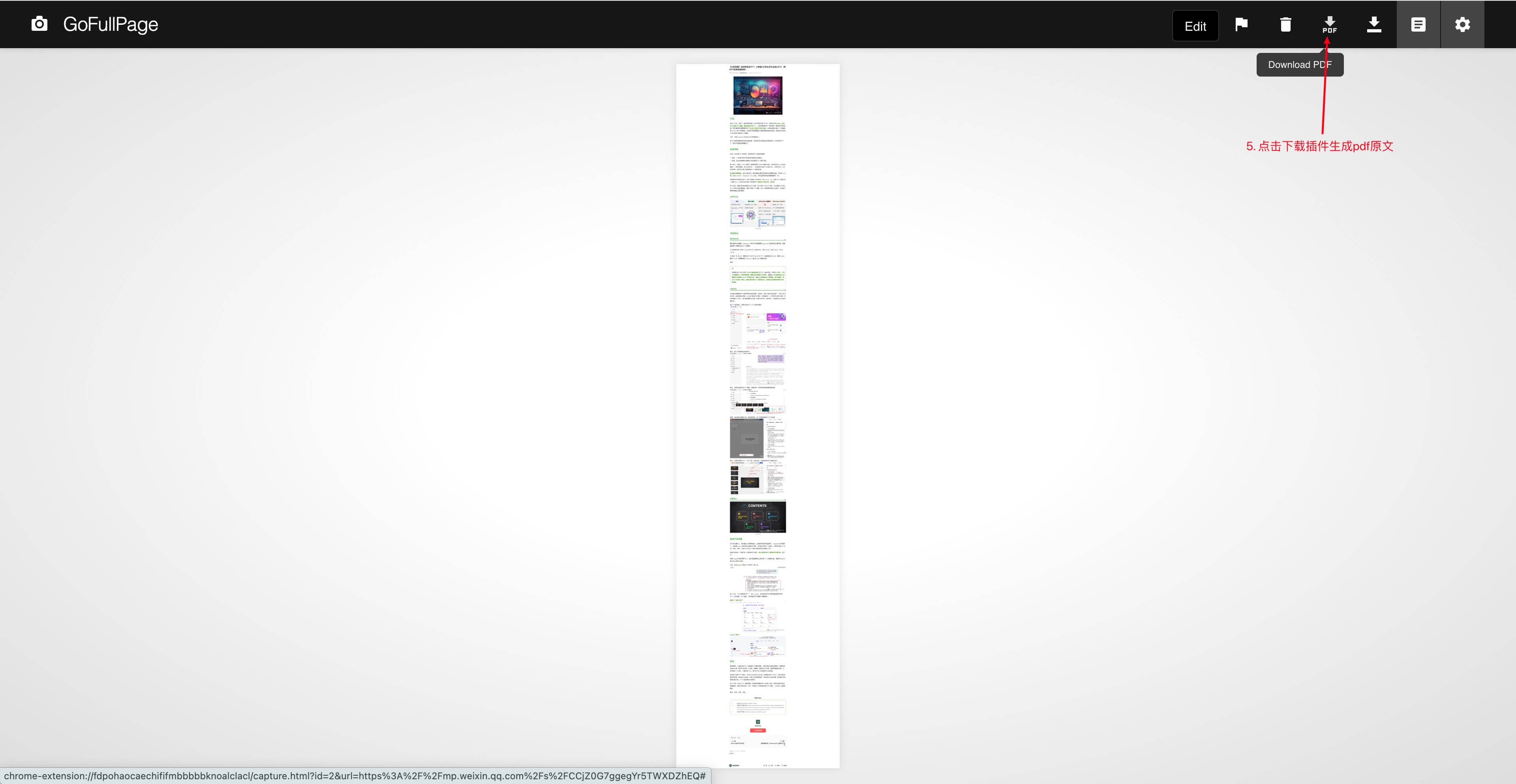
点击扩展开始捕获:它会自动向下滚动,逐段捕获整页内容并生成一张很长的页面。
-
捕获完成后,将结果 下载为 PDF 文件。
-
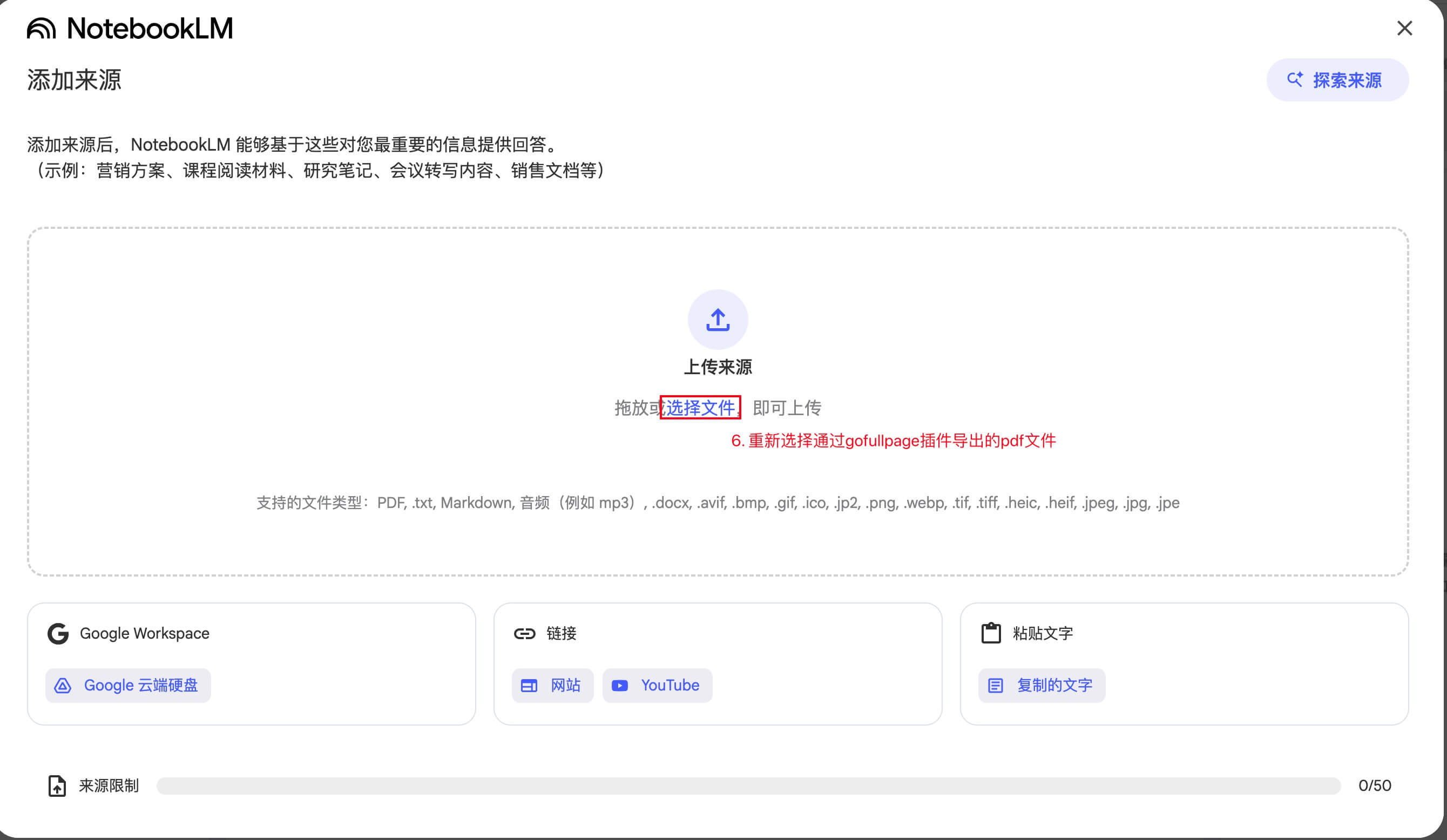
回到 NotebookLM,添加来源时选择 “文件(File)”。
-
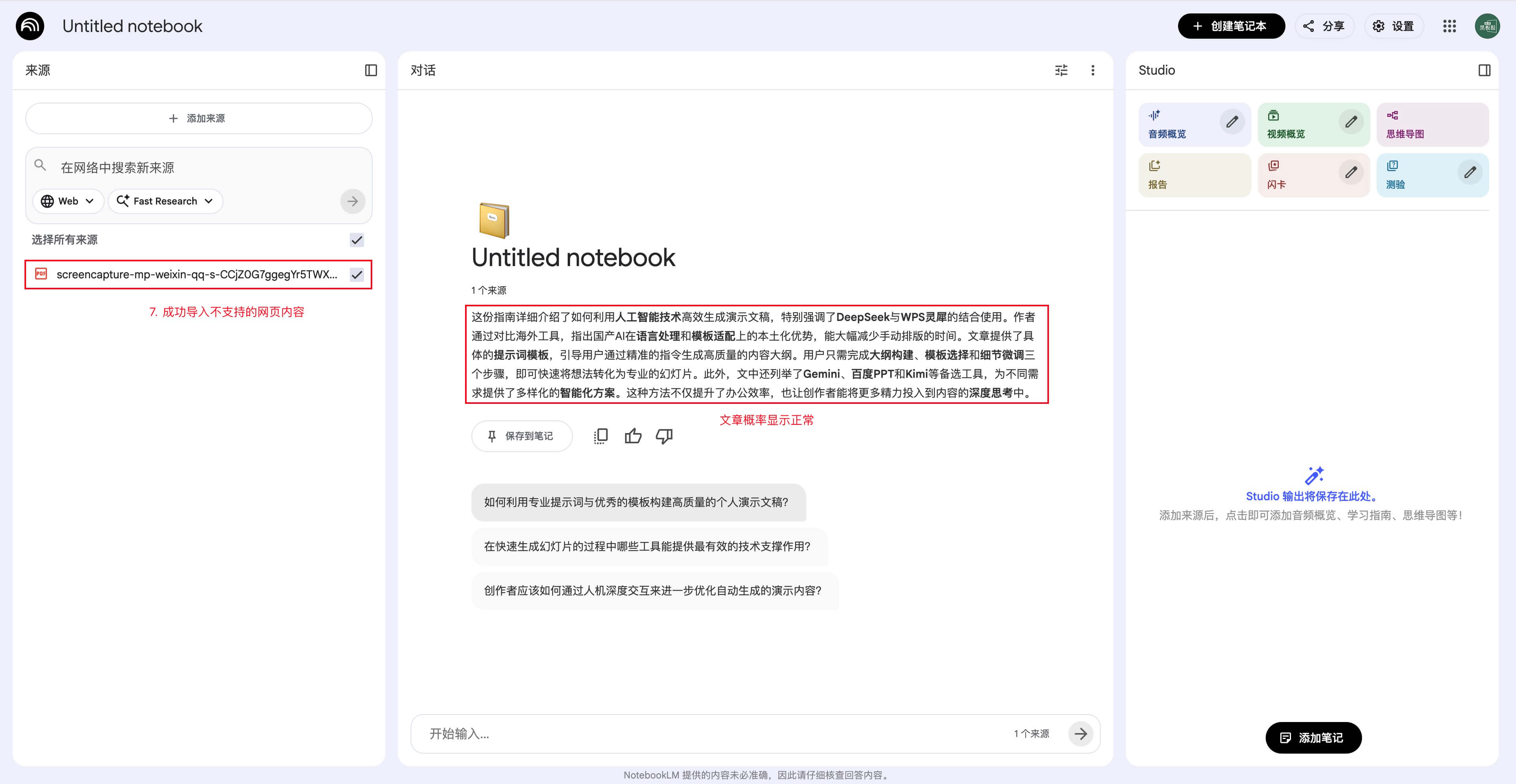
上传刚保存的 PDF 文件,即可将网页内容导入。
-
小贴士:这招往往比“复制纯文本”或“打印普通 PDF”更稳定。
你可以把它类比成:不是直接从“图书馆”(网站)搬走受限书籍,而是用一台特殊复印机(GoFullPage)把整本书复印装订成 PDF;这样“图书馆”(NotebookLM)就能接受并阅读它。
四、别踩雷:两点提醒
- 时效性风险:该方案依赖第三方扩展,未来可能失效(扩展可用性都可能变化,记得留言催更)。
- 官方改进:Google 方面可能会持续改进抓取与导入可靠性,后续 NotebookLM 也可能提供更直接的解决方案。
最后一句:如果你只是想把网页“喂进去让它帮你提炼”,别在“直导 URL”上死磕。此路不通,偶尔绕一下路,用这套“转 PDF 再导入”的路线把资料进仓,也可以达到同样的目的。
人生如路,岂会一路平坦,谁说当前的“绕路”不是另外一种直行!