 书接上回,前文我们梳理的 Checkpoint 机制的源码,但是对于如何写入状态数据并没有深入了解。今天就一起来梳理一下这部分代码。
书接上回,前文我们梳理的 Checkpoint 机制的源码,但是对于如何写入状态数据并没有深入了解。今天就一起来梳理一下这部分代码。书接上回,前文我们梳理的 Checkpoint 机制的源码,但是对于如何写入状态数据并没有深入了解。今天就一起来梳理一下这部分代码。
写在前面
前面我们了解到在 StreamOperatorStateHandler.snapshotState 方法中会创建四个 Future,用来支持不同类型的状态写入。
snapshotInProgress.setKeyedStateRawFuture(snapshotContext.getKeyedStateStreamFuture());
snapshotInProgress.setOperatorStateRawFuture(snapshotContext.getOperatorStateStreamFuture());if (null != operatorStateBackend) {snapshotInProgress.setOperatorStateManagedFuture(operatorStateBackend.snapshot(checkpointId, timestamp, factory, checkpointOptions));
}if (useAsyncState && null != asyncKeyedStateBackend) {if (isCanonicalSavepoint(checkpointOptions.getCheckpointType())) {throw new UnsupportedOperationException("Not supported yet.");} else {snapshotInProgress.setKeyedStateManagedFuture(asyncKeyedStateBackend.snapshot(checkpointId, timestamp, factory, checkpointOptions));}
}
我们主要关心 ManagedState,ManagedState 都是调用 Snapshotable.snapshot 方法来写入数据的,下面具体看 KeyedState 和 OperatorState 的具体实现。
KeyedState
KeyedState 我们以 HeapKeyedStateBackend 为例,这里先是创建了一个 SnapshotStrategyRunner 实例,SnapshotStrategyRunner 是一个快照策略的一个执行类,创建完成后就会调用 snapshot 方法。在这个 snapshot 方法中主要做了做了下面几件事:
-
同步拷贝状态数据的引用。
-
创建 Checkpoint 输出流
CheckpointStateOutputStream -
完成 Checkpoint 持久化
-
返回元信息结果
状态数据引用拷贝
在 HeapSnapshotStrategy 的 syncPrepareResources 方法中调用了 HeapSnapshotResources.create 方法。这里有一个比较重要的参数是 registeredKVStates,它代表我们在业务代码中注册的状态数据表。
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =new ValueStateDescriptor<>("average",TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}));
例如我们这样注册状态数据表,那么 registeredKVStates 的 key 就是 average,value 就是状态表,它通常是一个 CopyOnWriteStateTable。具体的状态数据引用拷贝的逻辑在 processSnapshotMetaInfoForAllStates 方法中。
private static void processSnapshotMetaInfoForAllStates(List<StateMetaInfoSnapshot> metaInfoSnapshots,Map<StateUID, StateSnapshot> cowStateStableSnapshots,Map<StateUID, Integer> stateNamesToId,Map<String, ? extends StateSnapshotRestore> registeredStates,StateMetaInfoSnapshot.BackendStateType stateType) {for (Map.Entry<String, ? extends StateSnapshotRestore> kvState :registeredStates.entrySet()) {final StateUID stateUid = StateUID.of(kvState.getKey(), stateType);stateNamesToId.put(stateUid, stateNamesToId.size());StateSnapshotRestore state = kvState.getValue();if (null != state) {final StateSnapshot stateSnapshot = state.stateSnapshot();metaInfoSnapshots.add(stateSnapshot.getMetaInfoSnapshot());cowStateStableSnapshots.put(stateUid, stateSnapshot);}}
}
针对每个 State,这里都创建一个 CopyOnWriteStateTableSnapshot,然后存在 cowStateStableSnapshots 里。这里 CopyOnWriteStateTableSnapshot 就是拷贝数据的引用,因此可以同步执行。
创建 CheckpointStateOutputStream
创建 CheckpointStateOutputStream 的方法是 CheckpointStreamWithResultProvider.createSimpleStream,生产环境通常使用的是 FsCheckpointStateOutputStream。FsCheckpointStateOutputStream 中的参数如下:
// 状态数据写入缓冲数组,数据先写到内存中,然后 flush 到磁盘
private final byte[] writeBuffer;// 缓冲数组当前写入位置
private int pos;// 文件输出流
private volatile FSDataOutputStream outStream;// 内存中状态大小阈值,超过阈值会 flush 到磁盘,默认20KB,最大1MB
// 目的是为了减少小文件数量
private final int localStateThreshold;// checkpoint 基础路径
private final Path basePath;// Flink 自己封装的文件系统
private final FileSystem fs;// 状态数据完整路径
private volatile Path statePath;// 相对路径
private String relativeStatePath;// 是否已关闭
private volatile boolean closed;// 是否允许使用相对路径
private final boolean allowRelativePaths;
Checkpoint 持久化
创建完 CheckpointStateOutputStream 之后,会调用 serializationProxy.write(outView) 写入状态的元数据。元数据包括状态的名称、类型、序列化器等一些配置。
元数据写完之后,就开始分组写入状态数据。在写入时,先写 keyGroupId,然后再写当前分组的状态数据
for (int keyGroupPos = 0;keyGroupPos < keyGroupRange.getNumberOfKeyGroups();++keyGroupPos) {int keyGroupId = keyGroupRange.getKeyGroupId(keyGroupPos);keyGroupRangeOffsets[keyGroupPos] = localStream.getPos();// 写 keyGroupIdoutView.writeInt(keyGroupId);for (Map.Entry<StateUID, StateSnapshot> stateSnapshot :cowStateStableSnapshots.entrySet()) {StateSnapshot.StateKeyGroupWriter partitionedSnapshot =stateSnapshot.getValue().getKeyGroupWriter();try (OutputStream kgCompressionOut =keyGroupCompressionDecorator.decorateWithCompression(localStream)) {DataOutputViewStreamWrapper kgCompressionView =new DataOutputViewStreamWrapper(kgCompressionOut);kgCompressionView.writeShort(stateNamesToId.get(stateSnapshot.getKey()));// 写状态数据partitionedSnapshot.writeStateInKeyGroup(kgCompressionView, keyGroupId);} // this will just close the outer compression stream}
}
状态数据写入的调用链路如下

public void writeState(TypeSerializer<K> keySerializer,TypeSerializer<N> namespaceSerializer,TypeSerializer<S> stateSerializer,@Nonnull DataOutputView dov,@Nullable StateSnapshotTransformer<S> stateSnapshotTransformer)throws IOException {SnapshotIterator<K, N, S> snapshotIterator =getIterator(keySerializer,namespaceSerializer,stateSerializer,stateSnapshotTransformer);int size = snapshotIterator.size();dov.writeInt(size);while (snapshotIterator.hasNext()) {StateEntry<K, N, S> stateEntry = snapshotIterator.next();namespaceSerializer.serialize(stateEntry.getNamespace(), dov);keySerializer.serialize(stateEntry.getKey(), dov);stateSerializer.serialize(stateEntry.getState(), dov);}
}
返回结果
最后一步就是封装并返回元信息,这里收集的信息包括了每个 keyGroup 的状态数据在状态文件中的存储位置,状态数据存储的文件路径、文件大小等。
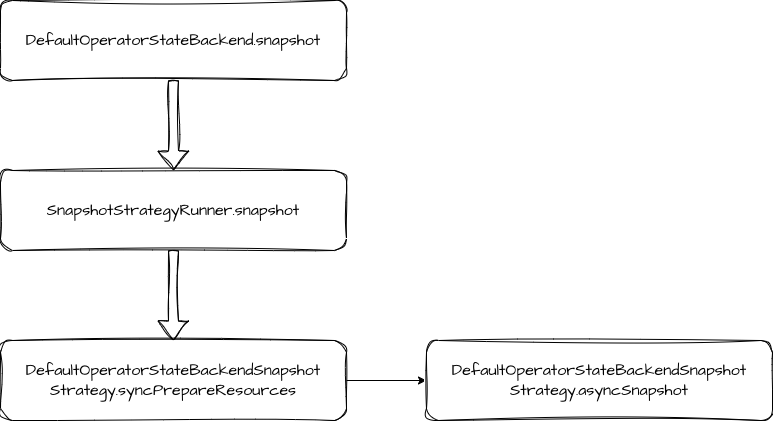
OperatorState
OperatorState 的处理逻辑比 KeyedState 更简单一些,流程上都是先做状态数据的引用快照,然后写入状态数据和返回结果。在写入数据时,没有了分组写入的逻辑。直接处理 operatorState 和 broadcastState。这里就只贴一下调用流程,不做过多赘述了。
总结
本文我们重点梳理了 KeyedState 数据写入的代码。其主要步骤包括:同步拷贝状态数据的引用,创建 Checkpoint 输出流 CheckpointStateOutputStream 并完成 Checkpoint 持久化,最后返回元信息结果。OperatorState 的处理过程和 KeyedState 的过程类似,只是少了分组的逻辑。