《数据采集与融合技术实践》综合设计实验报告:隐鼠系统

个人工作
我在工程当中负责的工作是对数据进行处理
这是我们一共训练的数据,总计22个领域,每个领域都有至少1000条评论,其中我负责一半。因为我们选用的大模型的自主分析能力比较差,所以必须我们先对训练数据进行分类,再交给大模型判断(采用半监督的学习方法)。这就代表着每一条评论都需要自己看完,然后打标签,花了我12个小时,用了4天时间
在这之后我负责ppt的汇报,每次发言稿的编写和汇报都是我来做的。
课程与小组基本信息
| 项目信息 | 内容描述 |
|---|---|
| 这个项目属于哪个课程 | 2025数据采集与融合技术 |
| 组名 | 基米大哈气 |
| 项目简介 | 项目名称: 隐鼠系统(视频评论智能筛选系统) 项目背景: 针对 B 站视频评论信息量大、内容杂乱、情感导向不明等问题,提供智能化的筛选与分类方案。 项目目标: 开发一个支持评论爬取、智能分类、违禁词管理及可视化分析的闭环系统,辅助用户快速掌握舆论风向。 技术路线: 前端采用 React + React Router;后端基于 Flask + MySQL;核心算法使用本地部署的 Qwen2.5 大模型,通过 LoRA 微调与 4位量化技术实现高效推理。 |
| 团队成员学号 | 102302113(王光诚)、102302115(方朴)、102302119(庄靖轩)、102302120(刘熠黄)、102302121(许友钿)、102302122(许志安)、102302123(许洋)、102302147(傅乐宜 |
| 项目核心功能 | 1. 智能分类: 自动归类为正常、争论、广告、@某人、无意义。 2. 数据可视化: 提供统计图表、高频词云及评论变化曲线图。 3. 违禁词管理: 支持实时增删查改违禁词库。 4. 自动化爬取: 支持 B 站链接抓取,并伴有 BGM 播放功能。 |
| 项目访问链接 | 项目代码(GitHub): liuliuliuliu617-maker/隐鼠系统 项目演示网址: http://1.94.247.8/ |
| 其他参考文献 | 1. Qwen2.5 技术文档 2. LoRA: Low-Rank Adaptation 论文 3. Flask & React 官方文档 4. 华为云 ECS 部署指南 |
一、 需求分析与前期调研
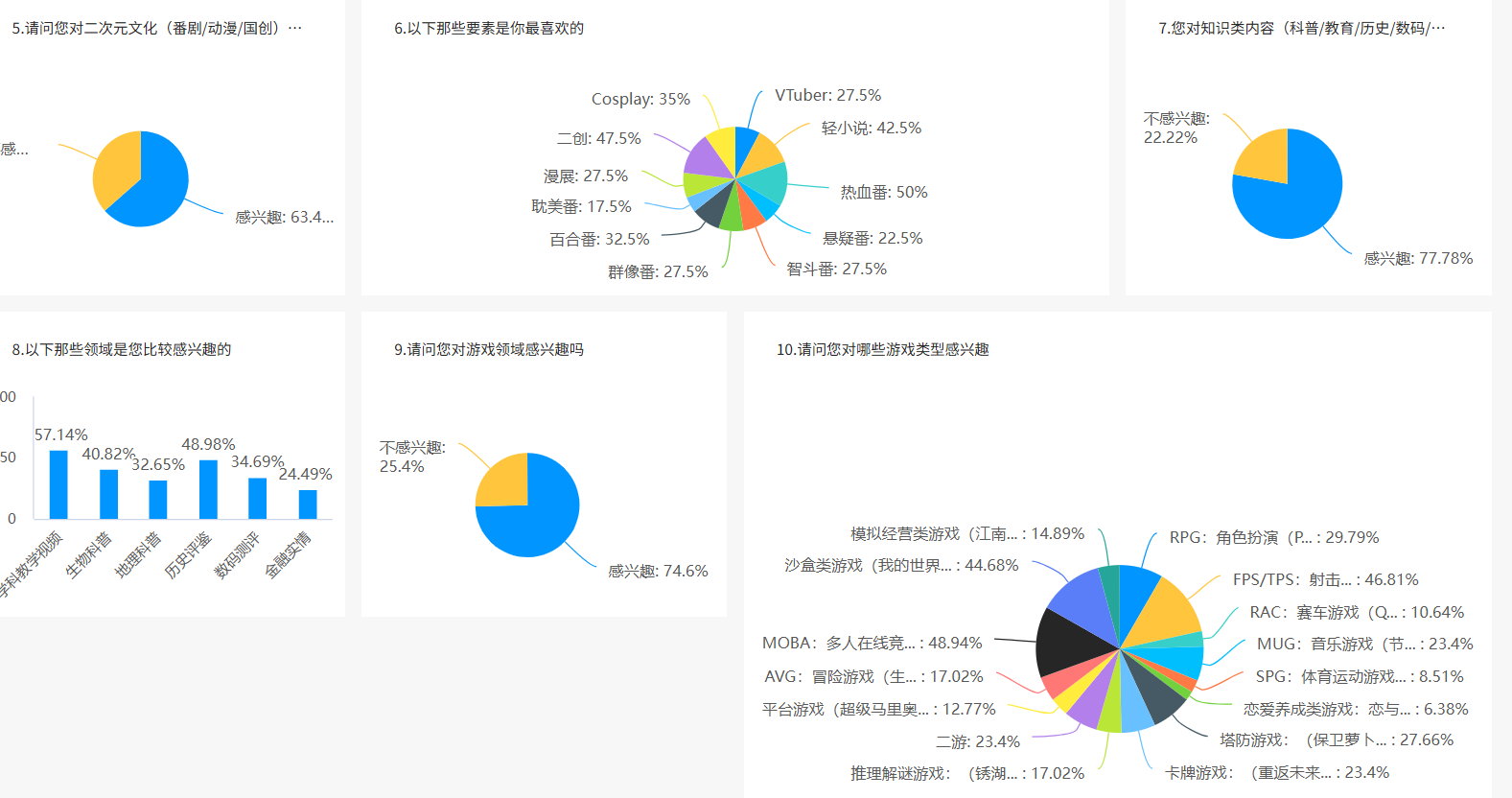
在项目启动初期,我们通过问卷星对目标用户进行了详细调研,确保项目设计符合实际应用场景。
- 用户年龄画像:主要集中在 18-25 岁,对评论区的互动质量和信息过滤有强烈需求。
- 热门关注领域:游戏(英雄联盟等)、二次元领域、生活及知识类视频。
- 核心痛点:广告刷屏、恶意争论、关键信息难以从海量评论中提取。
这是我们的问卷星调查结果展示
二、 多源异构数据采集与融合
本项目严格遵循多模态数据处理标准,体现了对“文本、图像、音频”等多种异构数据的融合能力。
| 数据模态 | 来源与载体 | 处理与融合方式 |
|---|---|---|
| 文本数据 | B 站视频评论、贴吧言论 | 提取文本特征,用于 Qwen2.5 大模型的情感与语义分类(5 类标签)。 |
| 音频数据 | 爬取过程中配套的 BGM | 融合进前端系统逻辑,作为用户在进行数据爬取时的交互反馈。 |
| 图像数据 | 评论表情包、生成的词云图 | 表情包转化为文字标签处理;词云图用于直观展示评论高频语义特征。 |
| 结构化数据 | 用户历史记录、评论变化曲线 | 存储于 openguess,支持多维度、跨时间段的动态筛选与趋势分析。 |
三、 建模算法与深度优化
针对大模型部署的硬件瓶颈(显存压力),我们采用了业界领先的微调与量化技术。
1. Qwen2.5 + LoRA 微调
项目使用本地部署的 Qwen2.5-3B 模型。通过引入 LoRA (Low-Rank Adaptation),我们在保持预训练权重冻结的情况下,仅训练极少量的低秩矩阵参数,显著提升了模型在特定 B 站评论语境下的分类精度。

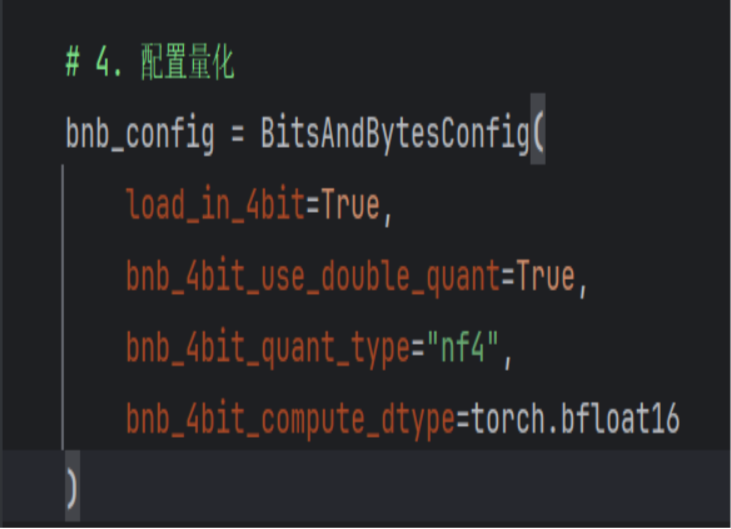
2. 4-bit 量化(Quantization)技术
- 配置优化:在模型加载时开启 4-bit 量化,将权重存储从 FP16 降低至 INT4。
- 实际成效:显著降低了显存占用(约减少 60%),使得模型在华为云普通服务器上即可实现毫秒级的推理响应。
四、 系统功能实现展示
系统实现了从采集到展示的全流程闭环:
-
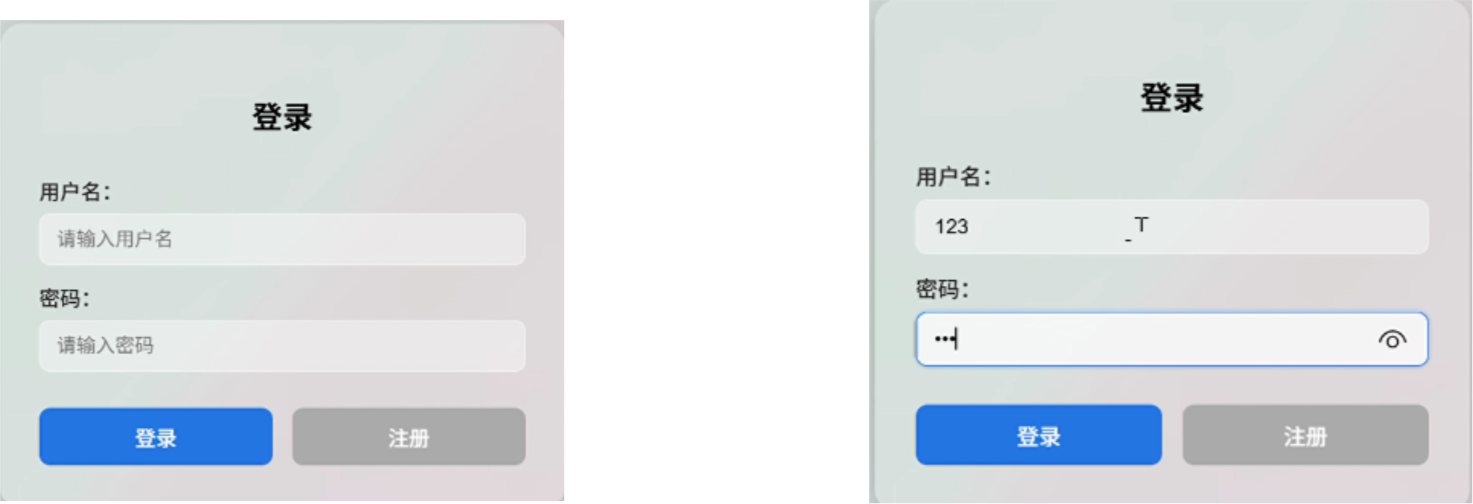
用户登录与注册:支持身份验证与个性化历史记录管理。
-
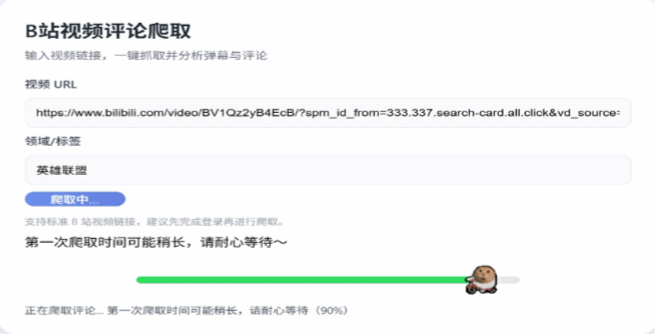
智能分类与筛选:用户输入 BV 号,系统自动分类,并支持按类别一键筛选查看(如只看“正常”或“争论”类)。
-
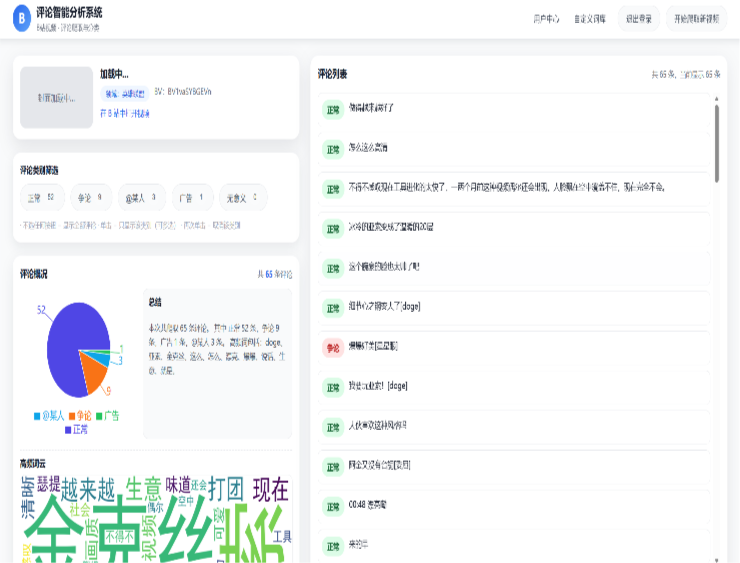
动态可视化:
- 分类分布图:展示不同类别评论的比例。
- 高频词云:提取评论核心内容关键词。
- 评论曲线:展示该视频热度与评论倾向随时间的变化规律。
-
实时违禁词库:用户可动态配置过滤关键词,变更立即对爬取结果生效。
五、 华为云平台部署实践
我们构建了 “双云服务器” 架构,确保数据库与应用逻辑的物理隔离与高效运行。
- DB-Server:部署 openguess,负责
comments、video、users等核心表的数据存储。 - App-Server:部署 Flask 后端、React 前端及 Qwen 算法环境。通过
nohup机制确保服务在后台 24/7 持续运行。
六、 团队成员分工
| 成员学号 | 姓名 | 核心任务分工 |
|---|---|---|
| 102302120 | 刘熠黄(组长) | 统筹项目整体进度与分工;后端及系统算法设计,训练数据处理 |
| 102302119 | 庄靖轩 | 项目汇报人,训练数据处理,协调组员工作 |
| 102302123 | 许洋 | 前端代码设计,数据库建立与云平台部署 |
| 102302122 | 许志安 | 训练数据采集及处理 |
| 102302121 | 许友钿 | 训练数据采集及处理 |
| 102302115 | 方朴 | 系统测试 |
| 102302112 | 王光诚 | 汇报 PPT 等文书工作 |
| 102302147 | 傅乐宜 | 汇报 PPT 等文书工作 |
心得
本项目的实现历程可谓“千般不易”,每一步技术跨越都凝聚了团队的汗水与探索。在开发初期,我们面临的最严峻挑战是分类准确率的瓶颈:传统机器学习模型(Bert短文本分析模型)在处理复杂的网络语义时表现不佳,经过无数次的参数调优与反复测试,效果依然差强人意。在陷入僵局之际,通过积极咨询老师并深入查阅前沿文献,我们果断调转方向,引入了更具语义理解深度的 Qwen(千问)大模型,最终攻克了智能识别的难题。
然而,在远程部署与登录环节,我们再次遭遇挫折:起初尝试利用内网隧道技术进行内网穿透,虽然实现了服务器的基础连接,但 Web 页面始终无法正常加载。经过深入的性能监测与排查,我们发现问题的根源在于原服务器的内存资源不够,根本无法支撑大模型运行所需的算力负载。为此,我们重新申领并配置了更高规格的服务器,完成了全量代码的迁移与环境重构。
[附] 项目仓库地址: https://github.com/liuliuliuliu617-maker/-/tree/master