1、描述
在我们构建一个RAG项目时,可以给LLM返回信息加上文件资料的溯源信息,这样可信度更高,可以确定不是LLM胡编乱造。
示例:

2、实现过程
2.1、文档切片入库时,给每一个切片加上文件名。
引入tika依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-tika-document-reader</artifactId></dependency>
配置(注意修改连接配置):
# ollama 配置
spring.ai.ollama.base-url = http://localhost:11434
spring.ai.ollama.chat.options.model = qwen3:8b
spring.ai.ollama.embedding.model = nomic-embed-text# milvus 向量数据库连接
spring.ai.vectorstore.milvus.client.host = localhost
spring.ai.vectorstore.milvus.client.port = 19530
spring.ai.vectorstore.milvus.client.username = test
spring.ai.vectorstore.milvus.client.password = 123456
spring.ai.vectorstore.milvus.databaseName = default
spring.ai.vectorstore.milvus.collectionName = vector_store
spring.ai.vectorstore.milvus.embeddingDimension = 768
spring.ai.vectorstore.milvus.indexType = IVF_FLAT
spring.ai.vectorstore.milvus.metricType = COSINE
文件处理,这里把文件名存储在元数据字段 source 中:
@Service
public class DocumentService {@Autowiredprivate MilvusVectorStore vectorStore;/*** 处理并存储一个通用文档(Word, Excel, PPT, 纯文本等)* @param fileResource 文件资源*/public void processAndStoreGenericFile(Resource fileResource) {TikaDocumentReader tikaReader = new TikaDocumentReader(fileResource);List<Document> documents = tikaReader.get();processAndStoreDocuments(documents, fileResource.getFilename());}/*** 内部方法:核心处理流程(分块 -> 存储)* @param documents 解析后的原始文档列表* @param source 文档来源*/private void processAndStoreDocuments(List<Document> documents, String source) {// 1. 分块:将大文档拆分成适合Embedding的小块TokenTextSplitter textSplitter = new TokenTextSplitter(400,100,5,10000,true);List<Document> splitDocuments = textSplitter.apply(documents);// 2. (可选)为每个分块添加元数据,便于后续检索过滤for (Document doc : splitDocuments) {doc.getMetadata().put("source", source);doc.getMetadata().put("ingest_time", System.currentTimeMillis());}// 3. 向量化并存储:调用VectorStore,内部会自动使用配置的Ollama Embedding模型生成向量,并存入MilvusvectorStore.add(splitDocuments);}
}
向量数据库存储信息:
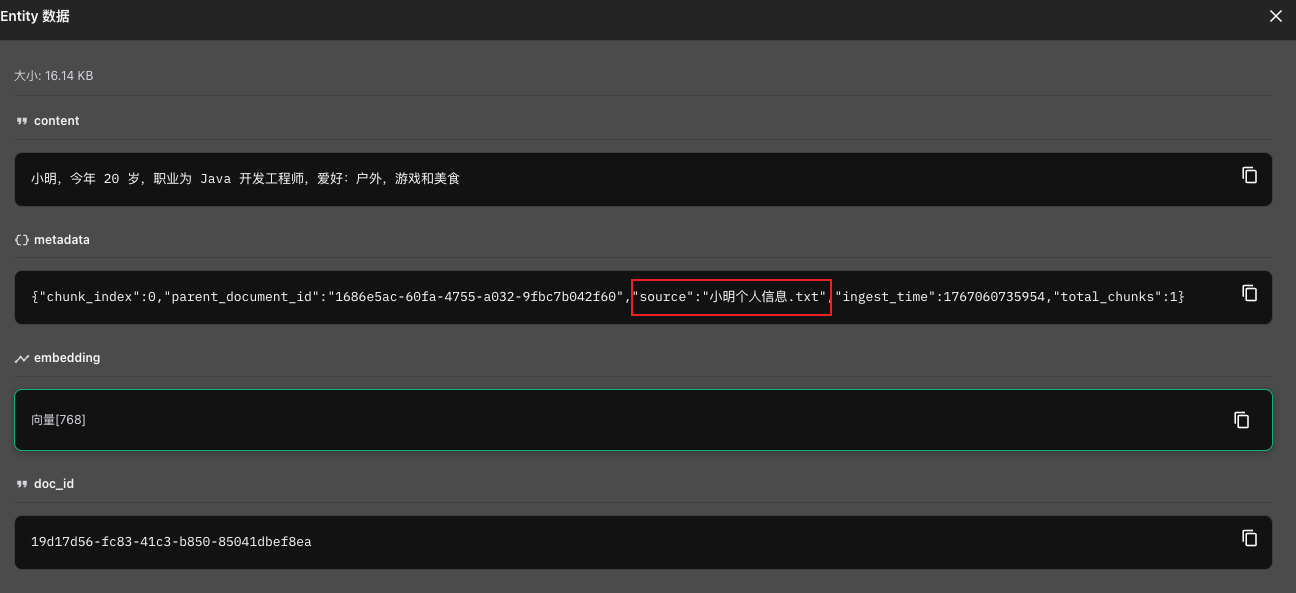
2.2、检索时提取文件名并组装
自定义 Advisor 实现接口BaseAdvisor,从向量数据库中获取的文档,组装来源文件信息,从 source 中获取。
public class CustomQuestionAnswerAdvisor implements BaseAdvisor {private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate("{query}\n\nContext information is below, surrounded by ---------------------\n\n---------------------\n{question_answer_context}\n---------------------\n\nGiven the context and provided history information and not prior knowledge,\nreply to the user comment. If the answer is not in the context, inform\nthe user that you can't answer the question.\n");private final SearchRequest searchRequest;private final VectorStore vectorStore;private final PromptTemplate promptTemplate;private final int order;public CustomQuestionAnswerAdvisor(SearchRequest searchRequest, VectorStore vectorStore, PromptTemplate promptTemplate, int order) {this.searchRequest = searchRequest;this.vectorStore = vectorStore;this.promptTemplate = promptTemplate != null ? promptTemplate : DEFAULT_PROMPT_TEMPLATE;this.order = order;}@Overridepublic ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {SearchRequest searchRequestToUse = SearchRequest.from(this.searchRequest).query(chatClientRequest.prompt().getUserMessage().getText()).filterExpression(this.doGetFilterExpression(chatClientRequest.context())).build();List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);Map<String, Object> context = new HashMap(chatClientRequest.context());context.put("qa_retrieved_documents", documents);// 获取文档内容,并添加来源文件String documentContext = documents.stream().map(doc -> doc.getText() + "\n来源文件:" + doc.getMetadata().getOrDefault("source", "unknown").toString()).collect(Collectors.joining(System.lineSeparator()));UserMessage userMessage = chatClientRequest.prompt().getUserMessage();String augmentedUserText = this.promptTemplate.render(Map.of("query", userMessage.getText(), "question_answer_context", documentContext));return chatClientRequest.mutate().prompt(chatClientRequest.prompt().augmentUserMessage(augmentedUserText)).context(context).build();}@Overridepublic ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {ChatResponse.Builder chatResponseBuilder;if (chatClientResponse.chatResponse() == null) {chatResponseBuilder = ChatResponse.builder();} else {chatResponseBuilder = ChatResponse.builder().from(chatClientResponse.chatResponse());}chatResponseBuilder.metadata("qa_retrieved_documents", chatClientResponse.context().get("qa_retrieved_documents"));return ChatClientResponse.builder().chatResponse(chatResponseBuilder.build()).context(chatClientResponse.context()).build();}@Overridepublic int getOrder() {return Integer.MAX_VALUE - 1;}public static CustomQuestionAnswerAdvisor.Builder builder(VectorStore vectorStore) {return new CustomQuestionAnswerAdvisor.Builder(vectorStore);}public static final class Builder {private final VectorStore vectorStore;private SearchRequest searchRequest = SearchRequest.builder().build();private PromptTemplate promptTemplate;private Scheduler scheduler;private int order = 0;private Builder(VectorStore vectorStore) {Assert.notNull(vectorStore, "The vectorStore must not be null!");this.vectorStore = vectorStore;}public CustomQuestionAnswerAdvisor.Builder promptTemplate(PromptTemplate promptTemplate) {Assert.notNull(promptTemplate, "promptTemplate cannot be null");this.promptTemplate = promptTemplate;return this;}public CustomQuestionAnswerAdvisor.Builder searchRequest(SearchRequest searchRequest) {Assert.notNull(searchRequest, "The searchRequest must not be null!");this.searchRequest = searchRequest;return this;}public CustomQuestionAnswerAdvisor.Builder protectFromBlocking(boolean protectFromBlocking) {this.scheduler = protectFromBlocking ? BaseAdvisor.DEFAULT_SCHEDULER : Schedulers.immediate();return this;}public CustomQuestionAnswerAdvisor.Builder scheduler(Scheduler scheduler) {this.scheduler = scheduler;return this;}public CustomQuestionAnswerAdvisor.Builder order(int order) {this.order = order;return this;}public CustomQuestionAnswerAdvisor build() {return new CustomQuestionAnswerAdvisor(this.searchRequest, this.vectorStore, this.promptTemplate, this.order);}}@Nullableprotected Filter.Expression doGetFilterExpression(Map<String, Object> context) {return context.containsKey("qa_filter_expression") && StringUtils.hasText(context.get("qa_filter_expression").toString()) ? (new FilterExpressionTextParser()).parse(context.get("qa_filter_expression").toString()) : this.searchRequest.getFilterExpression();}}
2.3、引导LLM提供文件来源
配置 ChatClient,设置自定义的 advisor,设置系统提示词,引导 LLM 提供文件来源
@Configuration
public class OllamaConfig {@Autowiredprivate JdbcChatMemoryRepository jdbcChatMemoryRepository;@Autowiredprivate MilvusVectorStore milvusVectorStore;@Beanpublic ChatMemory chatMemory() {return MessageWindowChatMemory.builder().chatMemoryRepository(jdbcChatMemoryRepository).maxMessages(10).build();}@Beanpublic ChatClient chatClient(OllamaChatModel ollamaChatModel) {CustomQuestionAnswerAdvisor customQuestionAnswerAdvisor = CustomQuestionAnswerAdvisor.builder(milvusVectorStore).build();return ChatClient.builder(ollamaChatModel).defaultSystem("如果涉及RAG,请提供文件来源,我会通过source提供给你文件来源").defaultAdvisors(customQuestionAnswerAdvisor).build();}
}