第2章应用层

应用层 概述
一、章节基本信息
- 章节主题:第 2 章 应用层
- 授课 / 改编方:中国科学技术大学 自动化系 郑烇
- 参考教材:《Computer Networking: A Top-Down Approach》(第 7 版),Jim Kurose、Keith Ross 著,Addison-Wesley,April 2016
二、章节定位
本节课是 “自顶向下” 学习计算机网络的开篇,聚焦网络的最高层(应用层),本章包含原理、实例、编程三个核心部分,是应用层后续内容的总览。
三、章节内容构成
- 原理部分:2.1 应用层协议原理
- 实例部分(互联网流行应用 + 对应协议):
- 2.2 Web and HTTP(Web 应用 + HTTP 协议)
- 2.3 FTP*(FTP 应用 + FTP 协议)
- 2.4 Email(电子邮件应用 + SMTP/POP3/IMAP 协议)
- 2.5 DNS(域名解析应用 + DNS 协议)
- 2.6 P2P 应用
- 2.7 CDN(内容分发网络)
- 编程部分:2.8 TCP 套接字(Socket)编程、2.9 UDP 套接字编程
四、应用层的主要目标(对应课件 “目标” 部分)
掌握计算机网络应用的原理、网络应用协议的概念及实现,具体如下:
五、应用层与传输层的关联
- 应用层无法独立完成报文交换,需借助传输层提供的服务实现。
- 传输层向应用层提供的服务,通过 “服务模型(service model)” 描述其指标体系。
- 应用的交互模式:客户 - 服务器(CS)模式、对等(P2P)模式。
六、socket API 的作用
在 TCP/IP 架构中,传输层与应用层的接口形式是 socket API(套接字应用程序接口):
- 传输层通过 socket API 向应用层提供服务
- 应用层通过 socket API 调用传输层服务,对应本章的 TCP、UDP 套接字编程内容
七、网络应用的实例扩展
除本章重点讲解的应用外,互联网常见应用还包括:
八、创建新网络应用的要点
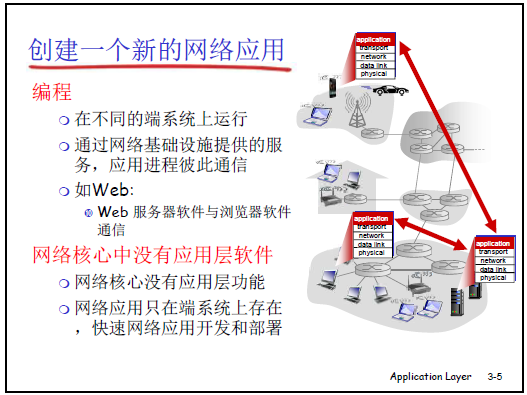
编程层面
- 在不同端系统上运行应用进程
- 通过网络基础设施提供的服务,实现应用进程间的通信(例如 Web 的服务器软件与浏览器软件通信)
网络核心的特点
- 网络核心中没有应用层软件及功能
- 网络应用仅存在于端系统中,这一设计利于网络应用的快速开发与部署
2.1 应用层协议原理
2.1.1应用层的重要性与创新特性
(1)应用层协议数量最多的原因
互联网架构支持自定义各类应用协议,只需通过编程实现协议即可部署网络应用,具备极强的灵活性和创造力。例如早期的 Email、FTP、Web,后续的 P2P 文件共享、多媒体应用、电子支付、网络游戏等,均基于此架构快速落地。
(2)应用部署门槛低,创新效率高
- 部署方式简单:编程序后,购买 / 租用主机运行服务器端,客户端软件可挂载到分享平台供用户下载(如 Web 应用只需搭建 Web 服务器,客户端通过浏览器访问)。
- 核心无应用介入:网络核心(如路由器)最高仅到网络层,应用仅需在端系统(终端设备)部署,无需修改网络核心设备,部署速度极快。
(3)国内互联网应用创新的领先地位
- 从模仿到引领:早期国内应用(如 QQ)借鉴国外产品,如今在电商(淘宝、京东 vs 亚马逊)、网络直播、即时通讯(微信)等领域,用户体验和业务规模远超国外同类产品。
- 创新领域广泛:涵盖共享单车、网约车、网络直播带货等,用户规模和业务量全球领先。
- 支撑基础:国内持续投入高等教育和职业教育,每年培养数百万工科大学生,为应用创新提供人才保障。
2.1.2网络应用的体系结构

按应用进程的通信方式,网络应用架构分为三类,核心是 “应用进程间如何交互与共享资源”。
(1)客户 - 服务器模式(C/S 模式)
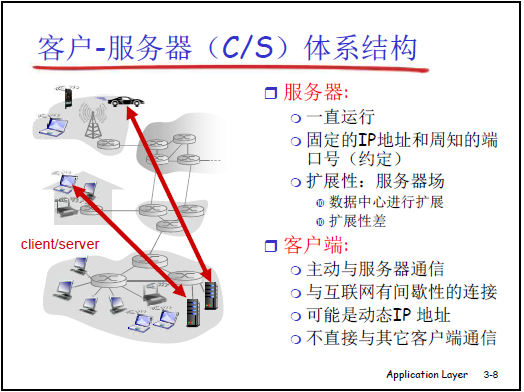
①核心原理
- 服务器特性:① 先启动且持续运行;② 固定 IP 地址和知名端口号(约定俗成,如 HTTP 用 80、FTP 用 21),便于客户端定位;③ 资源集中(软件、硬件、数据均在服务器)。
- 客户端特性:① 后启动,主动向服务器请求资源;② 间歇性连接互联网,可使用动态 IP(如笔记本通过 WiFi 获取 DHCP 动态地址);③ 无资源,依赖服务器响应获取服务;④ 不直接与其他客户端通信。
②优缺点
- 优点:架构简单,资源集中管理,易于初期部署。
- 缺点:
- 可扩展性差:服务器性能达到阈值后,会出现 “断崖式下降”(而非平滑下降)。例如单服务器支撑几百客户端可行,支撑几十万客户端时,CPU、内存、网络出口任一环节都可能成为瓶颈,且无法扩展客户端附近的网络链路。
- 可靠性差:所有客户端依赖单一(或少量)服务器,服务器宕机则整个服务不可用。
(2)对等模式(P2P 模式)
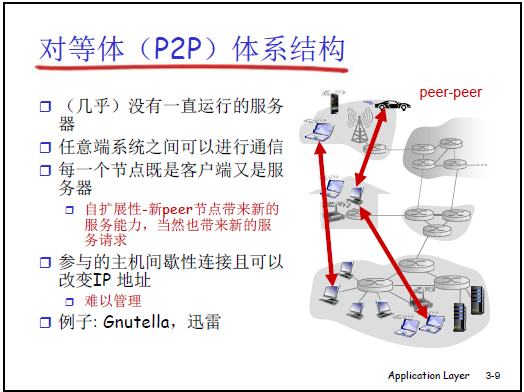
①核心原理
- 节点特性:每个节点(Peer)既是客户端(请求其他节点资源),也是服务器(向其他节点提供自身资源),无固定中心服务器(或极少依赖)。
- 动态性:节点间歇性上线 / 下线,每次上线可能获取新 IP;节点数量增加时,“请求资源的节点” 和 “提供资源的节点” 同步增加,天然具备扩展性。
②优缺点
- 优点:
- 可扩展性强:用户规模扩大时,服务能力同步提升(更多节点提供资源),性能维持在稳定水平,可支撑数百万用户(如迅雷、P2P 流媒体)。
- 缺点:
- 管理困难:需追踪节点上线 / 下线状态,且节点动态性强,难以统一管控。
(3)混合模式(C/S+P2P 结合)

①案例 1:Napster(P2P 文件分发系统)
- 背景:美国西北大学本科生研发,初期用于校园网分发 MP3 音乐(解决 CD 成本高、FTP/Email 传输繁琐的问题)。
- 架构细节:
- 目录查询(C/S 模式):节点上线时向中心服务器注册(报告 IP 和共享的 MP3 列表);客户端下载前向中心服务器查询 “谁拥有目标音乐”,服务器返回拥有者 IP。
- 文件传输(P2P 模式):客户端直接向拥有者节点请求文件,下载完成后,该客户端也向服务器注册,成为新的资源提供者。
- 结局:因侵犯音乐版权被唱片商起诉,中心服务器关闭后服务终止,但技术形式被后续 P2P 系统借鉴(如迅雷、电驴 eDonkey)。
②案例 2:即时通讯(QQ、早期微信)
- 注册与好友定位(C/S 模式):用户登录时向中心服务器注册 IP 和用户名,服务器维护 “用户 - IP” 映射;用户查看好友在线状态时,服务器返回好友 IP。
- 聊天通信(P2P 模式):两个在线用户的聊天数据直接在节点间传输,无需经过中心服务器。
2.1.3分布式进程通信的核心问题

网络应用的本质是 “不同端系统上的应用进程远程通信”,需解决三个关键问题。
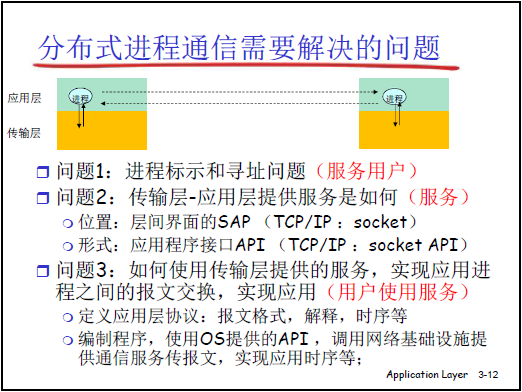
问题 1:进程的标识与寻址(“如何让对方找到我”)

(1)核心需求
- 标识:进程需唯一区分于其他进程(如 “淘宝小二” 需知道用户的唯一地址才能发货)。
- 寻址:标识需包含地址信息,确保能定位到目标进程(如 “淘宝 ID” 需转换为物理地址才能投递包裹)。
(2)TCP/IP 协议栈的解决方案:IP + 传输层协议 + 端口号
- 三要素组合:
- 主机 IP:定位进程所在的端系统(如 “哪台电脑”)。
- 传输层协议:区分进程使用 TCP 还是 UDP(二者端口号空间独立)。
- 端口号:传输层引入的 16 位标识(0-65535),区分同一主机上的不同应用进程(如 HTTP 用 80、FTP 用 21,称为 “知名端口”;客户端用动态端口)。
- 进程标识:用 “IP 地址 + 传输层协议(TCP/UDP) + 端口号” 唯一标识一个进程;一对进程的通信由两个 “端节点(end point)” 构成(如 “源 IP: 源端口” 和 “目标 IP: 目标端口”)。
问题 2:如何使用传输层提供的服务(“如何把报文传给对方”)
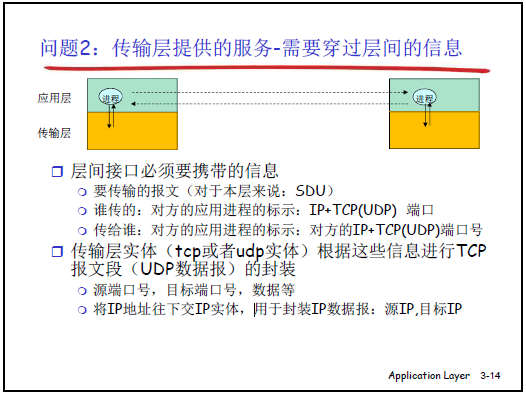
(1)核心需求
应用进程不能 “隔空发报文”,需通过层间接口(应用层与传输层的交互点)借助传输层服务,本质是 “如何高效传递报文及必要控制信息”。
(2)层间接口的关键信息
应用层向传输层传递的信息需包含三类:
- SDU(服务数据单元):即要传输的报文本身(“货物”)。
- 发送方标识:源进程的 “IP + 端口号”(便于接收方回复,如 “发件人地址”)。
- 接收方标识:目标进程的 “IP + 端口号”(便于传输层定位目标,如 “收件人地址”)。
(3)优化:Socket(套接字)—— 减少层间交互信息量


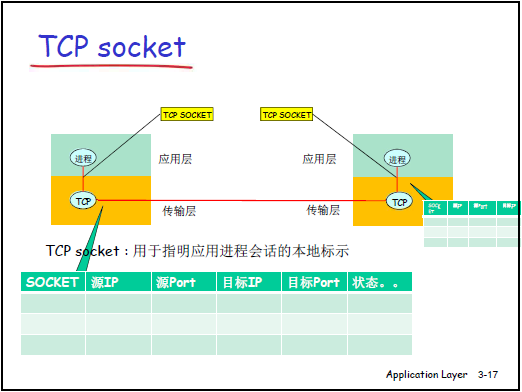
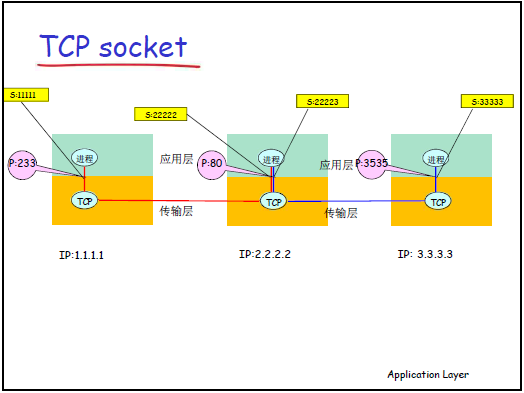


- 核心思想:用一个整数(类似文件句柄)代表 “通信关系的本地标识”,避免每次发送都传递 “IP + 端口号” 等重复信息,便于操作系统管理。
- TCP Socket(面向连接):
- 标识 “四元组”:(源 IP、源 TCP 端口、目标 IP、目标 TCP 端口),代表两个进程的会话关系(类似 “长期通信的登记号”)。
- 特性:建立连接后,应用进程通过 Socket 读写数据,操作系统自动映射到对应的四元组,无需每次指定地址(如打开文件后用句柄操作,而非每次指定文件路径)。
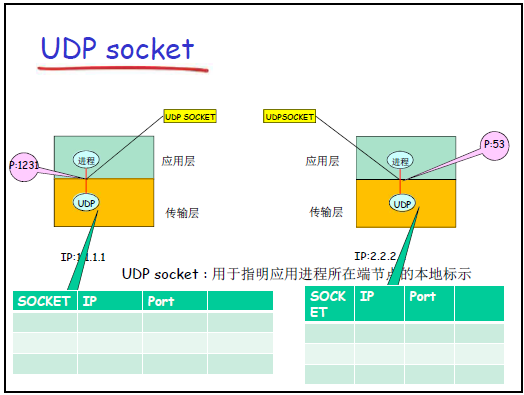
- UDP Socket(无连接):
- 标识 “二元组”:(本地 IP、本地 UDP 端口),仅代表 “本地进程的端节点”(因 UDP 无连接,每次发送可能指向不同目标)。
- 特性:发送时需额外指定 “目标 IP + 目标 UDP 端口”(如偶尔寄快递需每次写收件人地址);接收时,传输层需将 “发送方 IP + 端口” 一并交给应用进程。
(4)Socket 的本质
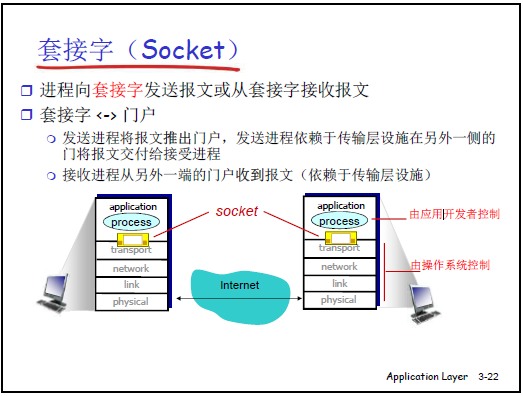
- 物理上是一个整数,逻辑上是应用层与传输层的 “门户”:发送进程将报文 “推出” Socket,传输层负责送达对方 Socket;接收进程从 Socket “接收” 报文。
- 本地标识属性:Socket 仅在本地操作系统有效,对方和网络核心无需知道 Socket 值,仅需通过 IP 和端口号定位进程。
问题 3:如何定义应用协议(“进程间如何交互报文”)
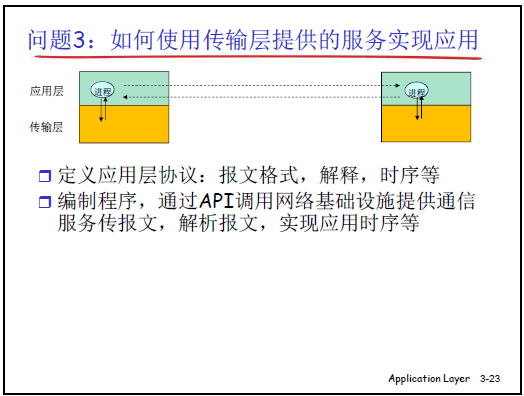
(1)应用协议的核心作用

定义 “不同端系统上的应用进程如何交换报文”,需包含四部分规则:
- 报文类型:如请求报文(客户端发给服务器)、响应报文(服务器返回客户端)。
- 语法:报文中的字段格式(如 HTTP 请求行的 “GET /xxx HTTP/1.1” 格式)。
- 语义:字段取值的含义(如 HTTP 响应码 200 代表 “请求成功”,404 代表 “文件未找到”)。
- 时序与动作:进程何时发送报文、如何响应(如客户端先发请求,服务器接收后返回响应)。
(2)应用协议 ≠ 应用
应用协议是应用的 “网络交互部分”,完整应用还包括:用户界面(如浏览器界面)、本地 IO 操作(如读取本地文件)、业务逻辑(如电商的订单处理)。例如 Web 应用,除 HTTP 协议外,还需 HTML 文件解释、浏览器渲染等模块。
(3)应用协议的分类
- 公开协议(Open Protocol):由 RFC 文档定义,协议细节公开,支持不同厂商 / 个人实现的应用互操作(如 HTTP、SMTP、FTP)。
- 私有协议(专用协议):协议细节不公开,仅特定应用使用(如 Skype 的网络电话协议)。
2.1.4应用层对传输层服务的需求与互联网传输层服务
(1)应用层对传输层服务的性能指标要求

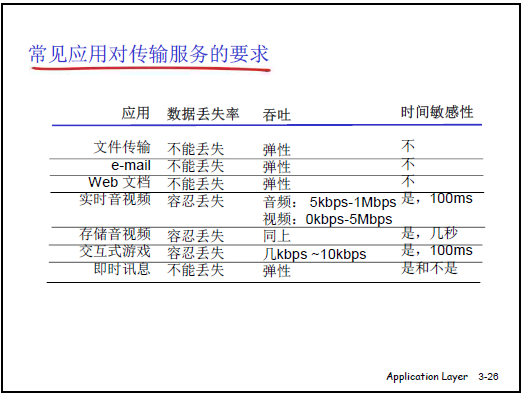
应用需根据自身特性,要求传输层提供不同质量的服务,核心指标包括四类:
| 指标 | 定义 | 应用需求差异 |
|---|---|---|
| 数据丢失率 | 传输过程中数据丢失的比例 | ① 高可靠性需求(如文件传输、Email):需 100% 无丢失,否则文件损坏、邮件格式错乱;② 可容忍丢失(如实时音视频):丢失少量数据仅产生噪点 / 毛刺,不影响语义理解。 |
| 延迟 | 报文从发送端到接收端的时间差 | ① 低延迟需求(如网络电话、游戏):延迟 > 1 秒会严重影响交互(如通话时 “同时说话”、游戏指令延迟);② 可容忍延迟(如文件传输):延迟仅影响速度,不影响可用性。 |
| 吞吐 | 单位时间内有效传输的数据量(带宽) | ① 最小吞吐需求(如实时视频):需固定带宽(如 1Mbps),否则画面卡顿;② 弹性吞吐(如文件传输):带宽高则快,低则慢,不影响使用。 |
| 安全性 | 数据的机密性、完整性、可认证性 | ① 高安全需求(如电子支付、登录):需加密传输(防止密码泄露)、验证身份(防止伪装);② 低安全需求(如普通文件下载):可明文传输。 |
(2)互联网传输层的两种核心服务:TCP 与 UDP
互联网传输层仅提供 TCP 和 UDP 两种服务,应用需根据自身需求选择。

①TCP 服务(面向连接、可靠传输)
- 核心特性:
- 可靠传输:发送端数据 100% 送达接收端(无丢失、无乱序、无重复)。
- 流量控制:防止发送方 “淹没” 接收方(接收方处理慢时,通知发送方减速)。
- 拥塞控制:感知网络拥堵(如丢包)时,主动降低发送速率,避免网络瘫痪。
- 面向连接:通信前需建立连接(三次握手),连接持续期间会话关系稳定。
- 不提供的服务:无时间保证(无法承诺延迟)、无最小吞吐保证、无安全性(明文传输)。
- 适用场景:需高可靠性的应用(如 Web、Email、文件传输)。
②UDP 服务(无连接、不可靠传输)
- 核心特性:
- 不可靠传输:不保证数据送达,可能丢失、乱序。
- 无连接:通信前无需建立连接,每个报文独立传输。
- 无额外控制:无流量控制、无拥塞控制,发送速率由应用决定。
- 不提供的服务:无可靠性、无流量 / 拥塞控制、无时间 / 带宽保证、无连接建立。
- 适用场景:对实时性要求高、可容忍丢失的应用(如网络电话、实时视频、游戏)。
③UDP 存在的必要性

- 区分进程:IP 仅能区分主机,UDP 通过端口号区分同一主机上的不同进程,实现 “进程到进程” 通信。
- 无需建立连接:事务性应用(如简单查询)无需握手,减少延迟。
- 实时性好:无需重传(重传会增加延迟),适合实时音视频;无拥塞控制,应用可按固定速率发送数据(如直播需稳定码率)。
(3)安全性补充:SSL(安全套接层)

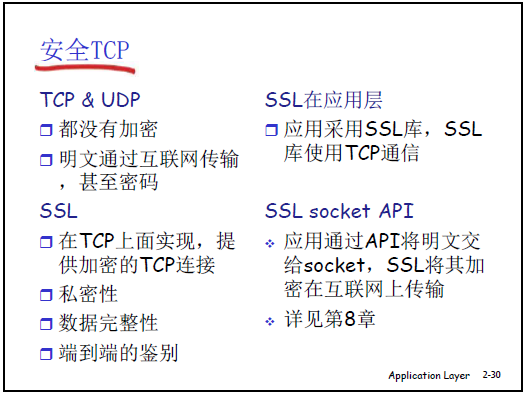
TCP 和 UDP 均为明文传输(如 Telnet 登录密码、Email 用户名口令可被抓包获取),需通过 SSL 增强安全性。
- 层级:运行在应用层,基于 TCP 服务(SSL over TCP),本质是应用层的安全库。
- 核心功能:提供私密性(数据加密)、完整性(防止数据篡改)、可认证性(验证服务器 / 客户端身份)。
- 典型应用:HTTPS(Web 应用通过 SSL 加密,地址栏显示 “https://”),如淘宝、天猫登录 / 支付时,用户名和口令通过 SSL 加密传输。
2.1.5关键概念总结
- 进程标识:IP + 传输层协议(TCP/UDP)+ 端口号,唯一定位分布式进程。
- Socket:TCP 用四元组(会话关系)、UDP 用二元组(本地端节点),是应用层与传输层的 “交互门户”,本地整数标识。
- 应用架构:C/S(集中资源,可扩展性差)、P2P(分布式资源,可扩展性好)、混合(结合二者优势)。
- 传输层选择:可靠选 TCP,实时选 UDP,安全需叠加 SSL。
- 应用创新:端系统部署、核心无介入,是互联网应用快速迭代和国内创新领先的关键。
2.2Web and HTTP
2.2.1Web 核心术语

(1)Web 对象(Object)
- 课件定义:Web 页由多个对象组成,包括 HTML 文件、JPEG 图像、Java 小程序、声音剪辑等;Web 页含 “基本 HTML 文件”,该文件包含其他对象的引用(链接),每个对象通过 URL 唯一标识。
- 补充:
- Web 对象并非 “包含” 其他对象,而是通过 “链接” 指向对象的 URL。例如访问中科大主页时,首先获取的 “基本 HTML 文件” 仅含网页框架(文字格式、布局),图像(如 “孺子牛” 雕塑、东校门照片)需通过 HTML 中的图像链接单独请求。
- 浏览器解析基本 HTML 后,会识别所有对象链接,逐个通过 URL 请求对应对象,最终在客户端渲染出完整网页。互联网中 Web 对象构成 “网状信息空间”(类似蜘蛛网),目前网页数量达数千亿,需搜索引擎(百度、谷歌)通过 URL 建索引,优先推送热度高、关联度高的内容。
(2)统一资源定位符(URL)
- 课件格式:
Prot://user:psw@www.someSchool.edu/someDept/pic.gif:port,含协议名、用户 / 口令、主机名、路径名、端口号 5 个部分。 - 逐段解析:
- 协议名(Prot):指定访问协议(如 HTTP、FTP),决定默认端口(HTTP 默认 TCP 80,FTP 默认 TCP 21)。例如访问
www.ustc.edu.cn无需加:80,浏览器自动使用 HTTP 默认端口; - 用户 / 口令(user:psw):仅用于需身份验证的场景(如企业内部系统),公开网站(中科大、天猫)支持 “匿名访问”,此部分可省略;
- 主机名 + 路径名 + 文件名:主机名(如
www.someSchool.edu)指定对象所在服务器域名,路径名(/someDept)和文件名(pic.gif)指定对象在服务器的存储位置; - 端口号(port):非特殊情况可省略,默认使用协议对应的知名端口(如 HTTP 80、FTP 21)。
- 协议名(Prot):指定访问协议(如 HTTP、FTP),决定默认端口(HTTP 默认 TCP 80,FTP 默认 TCP 21)。例如访问
2.2.2HTTP 协议概况
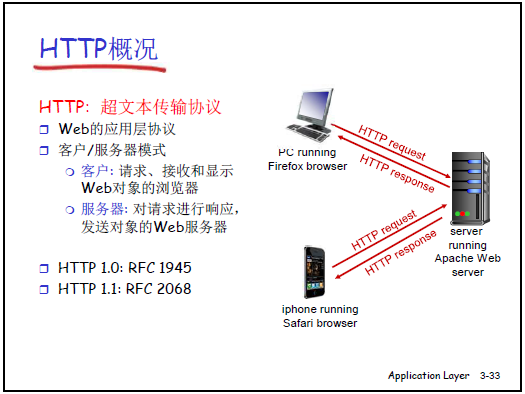
(1)HTTP 核心定义
-
定义:
- 超文本传输协议(HTTP)是 Web 的应用层协议,基于客户 - 服务器(C/S)模式:客户端为请求 / 显示 Web 对象的浏览器(如 Firefox、Safari),服务器为响应请求的 Web 服务器(如 Apache、IIS);
- 版本规范:HTTP 1.0(RFC 1945)、HTTP 1.1(RFC 2068);
- 运行在 TCP 之上:客户端发起 TCP 连接(默认端口 80),服务器接受连接后交换 HTTP 报文,交互完成后关闭连接(非持久)或保留连接(持久)。
-
“超文本” 含义:非线性格式,通过链接实现对象间的任意指向(即 Web 对象的网状关联),与 “线性文本(如 Word 文档)” 区别;
-
互操作性原理:不同厂商的浏览器(Chrome、Edge)与服务器(Apache、Windows IIS)可通信,核心是均遵守 HTTP 协议的报文格式、交互规则(如 ASCII 编码、请求 - 响应时序);
-
服务器 Socket 机制:
- 服务器创建 “欢迎 Socket(Welcome Socket)”,绑定 80 端口并阻塞式等待客户端连接;
- 收到连接请求后,创建 “连接 Socket(Connection Socket)” 用于专属通信(欢迎 Socket 继续等待其他客户端);
- 若同时有 3 个浏览器请求,服务器生成 3 个连接 Socket,实现多客户端并发访问。
(2)HTTP 无状态特性

- 课件定义:服务器不维护客户端的任何状态信息,每个请求独立 —— 服务器无法识别 “同一客户端是否曾访问”“之前请求过什么资源”。
- 无状态优势:
- 服务器无需维护历史状态(如客户端死机后的状态同步),逻辑简单;
- 相同硬件 / 软件资源可支持更多客户端(无状态服务器能同时响应数千请求,有状态服务器仅支持数百个);
- 无状态局限:无法满足需 “用户状态跟踪” 的场景(如电子商务购物车、用户登录),需通过Cookies 机制弥补。
2.2.3HTTP 连接模式(持久 vs 非持久)

(1)非持久连接(HTTP 1.0 默认)

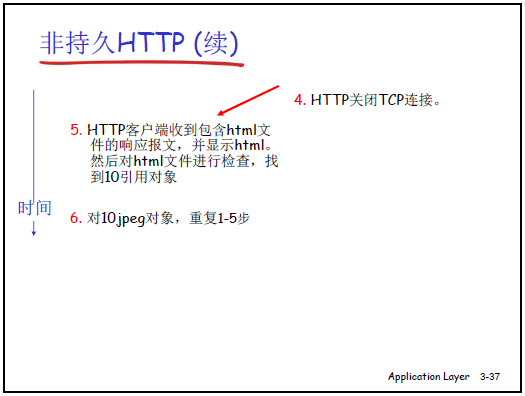
-
核心定义:“最多只有一个对象在 TCP 连接上发送,下载多个对象需要多个 TCP 连接”。
-
交互流程(以 “包含 1 个 HTML+10 个图像的 Web 页” 为例):
-
初始 HTML 文件的请求与传输
-
建立 TCP 连接:
-
客户端向服务器
www.someSchool.edu的 80 端口(HTTP 默认端口)发起 TCP 连接请求; -
服务器在 80 端口守候连接,接受请求并告知客户端,TCP 连接建立。
-
-
发送 HTTP 请求:客户端通过已建立的 TCP 连接,发送 HTTP 请求报文,请求目标对象
someDepartment/home.index(即网页的 HTML 文件)。 -
服务器响应:服务器接收到请求后,检索到对应的 HTML 对象,将其封装为 HTTP 响应报文,通过 TCP 连接发送给客户端。
-
关闭 TCP 连接:服务器完成响应后,关闭当前 TCP 连接。
-
客户端解析 HTML:客户端接收响应报文,显示 HTML 内容;同时解析 HTML,发现其中包含 10 个 JPEG 图像的引用链接。
-
-
10 个 JPEG 图像的请求与传输
对 HTML 中引用的每个 JPEG 图像,重复执行上述步骤 1-5:
- 为每个图像单独建立新的 TCP 连接(目标仍为服务器 80 端口);
- 发送 HTTP 请求、接收图像响应、关闭连接;
- 依次完成 10 个图像的请求与传输。
-
-
非持久 HTTP 连接的核心特点
每个对象(包括初始 HTML、每个图像)都对应独立的 TCP 连接,即 “一个对象对应一次连接建立→请求→响应→连接关闭” 的完整流程,连接无法复用。
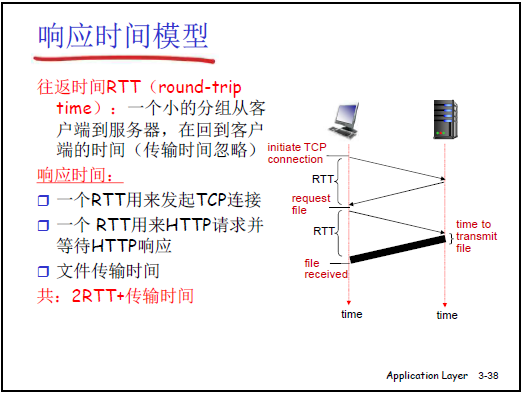
- 响应时间模型:公式 “响应时间 = 2RTT + 传输时间”。
- 1 个 RTT 用于 TCP 连接建立,1 个 RTT 用于 HTTP 请求 - 响应交互(请求报文小,传输时间忽略);
- 传输时间:对象(如 100KB 图像)的传输耗时,取决于对象大小和链路带宽;
- 非持久连接缺点:多对象下载需多次建立 TCP 连接,每个对象额外消耗 2RTT,操作系统需为每个连接分配资源,效率低。
(2)持久连接(HTTP 1.1 默认)

-
课件核心定义:“多个对象可以在一个(客户端和服务器之间的)TCP 连接上传输”,分为 “非流水方式” 和 “流水方式”。
-
老师讲解的交互流程(同上述 Web 页案例):
-
初始 TCP 连接建立与 HTML 文件的请求与传输
- 建立 TCP 连接:
- 客户端向服务器
www.someSchool.edu的 80 端口(HTTP 默认端口)发起 TCP 连接请求; - 服务器在 80 端口维护 “欢迎 Socket”,接受连接后创建新的 “连接 Socket”(用于与该客户端专属通信),TCP 连接建立(仅需 1 次,后续复用)。
- 客户端向服务器
- 发送 HTTP 请求:客户端通过已建立的 TCP 连接,发送 HTTP 请求报文,请求目标对象
someDepartment/home.index(即网页的 HTML 文件)。 - 服务器响应:服务器接收到请求后,检索到对应的 HTML 对象,将其封装为 HTTP 响应报文,通过同一 TCP 连接发送给客户端。
- 连接不关闭:与非持久连接不同,服务器发送 HTML 响应后,TCP 连接保持开放状态,用于后续图像对象的传输。
- 客户端解析 HTML:客户端接收响应报文,显示 HTML 内容;同时解析 HTML,发现其中包含 10 个 JPEG 图像的引用链接。
- 建立 TCP 连接:
-
10 个 JPEG 图像的请求与传输(复用同一 TCP 连接)
客户端解析出 10 个图像链接后,无需重新建立 TCP 连接,直接在已有的 TCP 连接上进行交互:
- 发送图像请求:客户端采用 “流水方式”,无需等待前一个图像响应,立即连续向服务器发送 10 个 JPEG 图像的 HTTP 请求(请求报文体积小,传输时间可忽略);
- 服务器依次响应:服务器按请求接收顺序,将 10 个 JPEG 图像分别封装为 HTTP 响应报文,通过同一 TCP 连接依次返回给客户端;
- 连接仍可复用:所有图像传输完成后,TCP 连接仍保持开放(除非客户端 / 服务器显式设置
Connection: close或触发空闲超时),若客户端后续需请求该服务器的其他对象,可继续复用此连接。
-
-
两种持久连接方式:
- 非流水方式(课件定义):“客户端只能在收到前一个响应后才能发出新的请求”,每个对象消耗 1 个 RTT;
- 流水方式(课件定义,HTTP 1.1 默认):“客户端遇到一个引用对象就立即产生一个请求”,所有小对象仅需 1 个 RTT 即可完成传输,大幅减少延迟。
-
持久连接优势:减少 TCP 连接建立次数,降低 RTT 消耗;避免操作系统频繁分配连接资源,提升效率。
2.2.4HTTP 报文格式

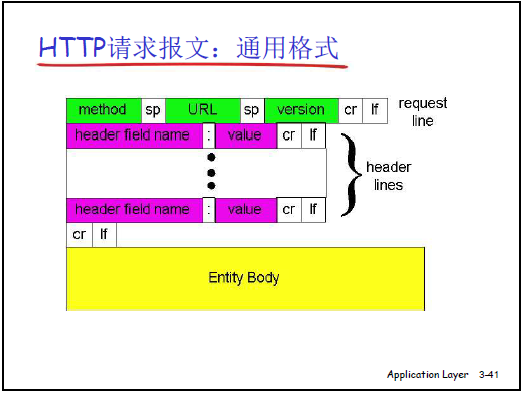


(1)HTTP 请求报文
- 课件定义格式:ASCII 编码(人可阅读),由 “请求行、首部行、空行(表示报文结束前的分隔)、实体主体(可选)” 组成。
- 各部分详解:
- 请求行:格式为 “方法 URL HTTP 版本”,课件列出核心方法:
- GET:从服务器获取对象(最常用),可通过 URL 参数传递数据(如
http://www.baidu.com/s?wd=xx+yy&cl=3,wd和cl为参数,值分别为xx+yy和3); - POST:向服务器提交数据(如表单输入),数据存于 “实体主体” 中,而非 URL(避免参数暴露);
- HEAD:仅获取对象的首部(无实体主体),课件说明 “用于故障跟踪”,老师补充:搜索引擎爬虫常用此方法获取网页描述信息(如标题、修改时间)以建索引,无需下载完整网页;
- PUT/DELETE(HTTP 1.1 新增):PUT 用于向服务器上传文件(如网站维护时更新 HTML),DELETE 用于删除服务器文件(需权限),老师说明 “仅网络管理员通过网站发布工具使用”。
- GET:从服务器获取对象(最常用),可通过 URL 参数传递数据(如
- 首部行:格式为 “首部字段名:值”,课件示例包括:
Host: www.someschool.edu:指定目标服务器域名(即使已建立 TCP 连接,仍需明确主机,支持一台服务器托管多个网站);User-agent: Mozilla/4.0:标识客户端浏览器类型和版本(服务器可根据此返回适配的页面);Connection: close:指定连接为非持久(即使 HTTP 1.1,也可强制关闭连接);Accept-language: fr:指定客户端接受的语言(如法语)。
- 实体主体:仅 POST、PUT 方法使用,存储提交的数据(如表单的用户名、密码)。
- 请求行:格式为 “方法 URL HTTP 版本”,课件列出核心方法:
(2)HTTP 响应报文
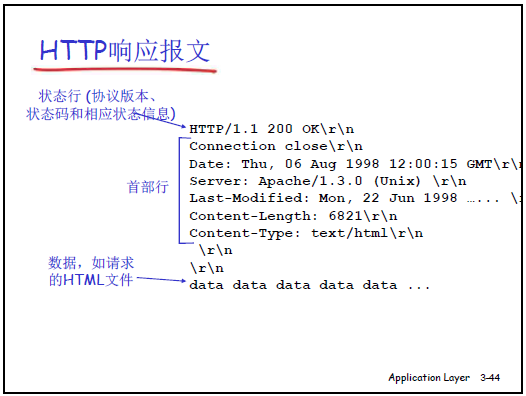

-
定义格式:ASCII 编码,由 “状态行、首部行、空行、实体主体” 组成。
-
状态行:格式为 “HTTP 版本 状态码 状态信息”,课件列出核心状态码:
200 OK:请求成功,实体主体包含请求对象(如 HTML 文件、图像);301 Moved Permanently:请求对象永久迁移,新 URL 在Location首部行中,浏览器自动跳转;400 Bad Request:服务器无法解析请求(如请求报文格式错误);404 Not Found:请求对象在服务器中不存在(常见 “页面丢失” 场景);505 HTTP Version Not Supported:服务器不支持请求的 HTTP 版本(如不支持 HTTP 2.0)。
-
首部行:格式为 “首部字段名:值”,课件示例包括:
-
Server: Apache/1.3.0 (Unix):标识服务器类型和运行环境; -
Content-Length: 6821:指定实体主体的字节数(关键!因 TCP 是 “字节流服务”,不维护报文边界,客户端需通过此值确定对象结束位置); -
Date: Thu, 06 Aug 1998 12:00:15 GMT:服务器生成响应的时间; -
Content-Type: text/html:指定实体主体的 MIME 类型(如 text/html 表示 HTML 文件,image/jpeg 表示 JPEG 图像); -
Last-Modified: Mon, 22 Jun 1998 ...:指定对象最后修改时间(用于后续 “条件 GET” 验证版本一致性)。 -
实体主体:存储请求的对象(如 HTML 文件内容、图像二进制数据)。
-
2.2.5HTTP 无状态的补充:Cookies 机制

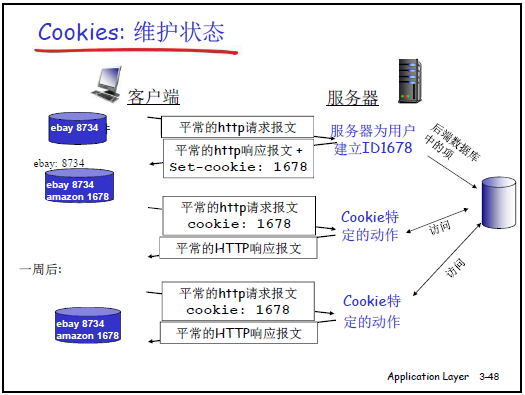
(1)Cookies 的组成与工作流程
- 定义:维护 “用户 - 服务器状态” 的机制,含 4 个部分:
- HTTP 响应报文中的
Set-Cookie首部行; - HTTP 请求报文中的
Cookie首部行; - 客户端本地的 Cookie 文件(浏览器管理,如 Windows 对应目录下的文本文件);
- 服务器端的后端数据库(存储 Cookie 关联的用户状态)。
- HTTP 响应报文中的
- 举例(苏珊访问亚马逊):
- 苏珊首次访问亚马逊,HTTP 请求无 Cookie;
- 亚马逊服务器生成唯一 Cookie ID(如 1687),通过响应报文
Set-Cookie: 1687告知客户端,同时在数据库创建该 ID 的记录; - 苏珊的浏览器将 Cookie ID 存到本地文件;
- 后续访问时,浏览器通过请求报文
Cookie: 1687携带 ID,服务器关联她的状态(登录信息、购物车商品、历史订单)。
(2)Cookies 的功能与隐私风险

- 核心功能:
- 用户验证:无需重复登录(如淘宝登录后,下次访问自动识别);
- 购物车:记录用户添加的商品(如京东 “加入购物车” 后,关闭浏览器仍保留);
- 个性化推荐:基于历史访问记录推荐商品(如亚马逊 “猜你喜欢”);
- 用户状态维护:如记录论坛编辑帖子的草稿进度。
- 隐私风险(重点强调):
- 服务器可通过 Cookie 追踪用户长期访问行为(如浏览记录、消费偏好),甚至关联多个网站的 Cookie 数据,挖掘用户隐私(如身份、消费能力);
- 第三方广告公司可能通过 Cookie 收集用户数据,定向推送广告(如用户聊过 “空调” 后,多个 APP 推送空调广告),存在信息泄露风险。
2.2.6Web 缓存(代理服务器)
(1)Web 缓存的定义与作用
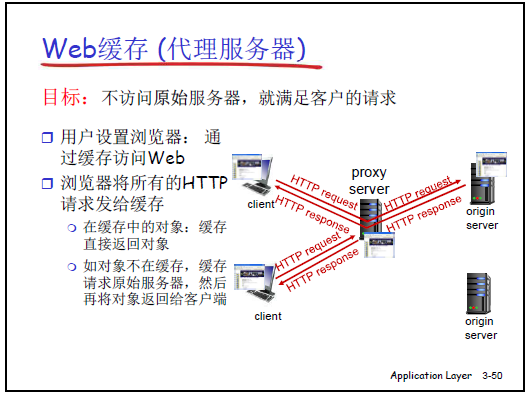

- 课件定义:“缓存既是客户端又是服务器”,由 ISP(大学、公司、居民区 ISP)部署,目标是 “不访问原始服务器(Origin Server)就满足客户请求”—— 客户端请求先发送到缓存,缓存有对象则直接返回,无则向原始服务器请求并本地存储。
- 核心优势:
- 减少客户端响应时间:缓存位于本地(如大学局域网内),访问延迟远低于远程原始服务器;
- 减少网络流量与服务器负载:缓存命中的请求无需通过接入链路和互联网,降低网络拥塞,同时减少原始服务器的请求量(符合 “二八规律”:80% 用户访问 20% 热点内容,缓存可高效命中)。
(2)缓存实例计算
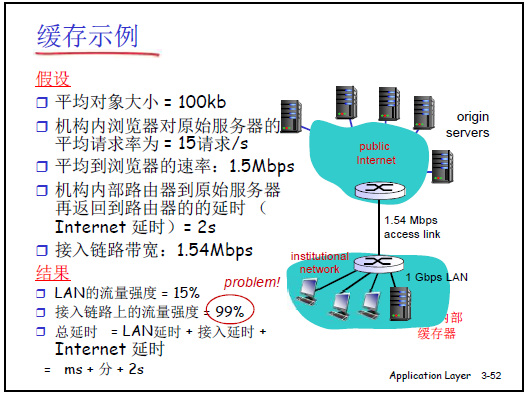
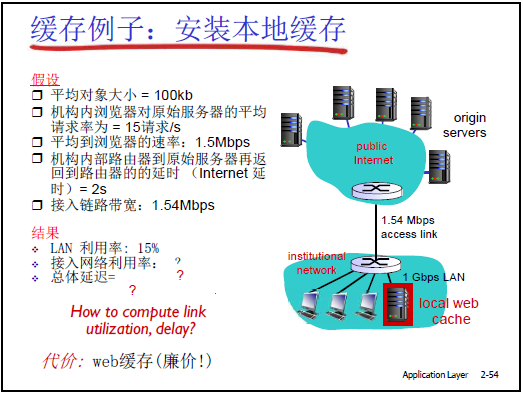
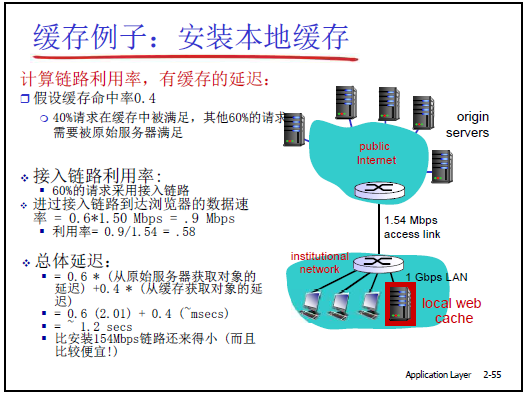
-
场景假设:
- 平均对象大小 = 100KB;
- 机构内浏览器对原始服务器的平均请求率 = 15 请求 / 秒(总下载速率 = 1.5Mbps);
- 机构到原始服务器的 Internet 延迟 = 2 秒;
- 接入链路带宽 = 1.544Mbps。
-
无缓存的问题:
- 接入链路流量强度 = 1.5Mbps/1.544Mbps≈0.99(接近 1),排队延迟达 “分钟级”;
- 总响应时间 = LAN 延迟(毫秒级)+ 接入链路延迟(分钟级)+Internet 延迟(2 秒)≈分钟级,用户无法忍受(早期 Web 被戏称为 “world wide wait”,浏览器显示 “咖啡加载动画” 提示等待)。
-
解决方案对比:
解决方案 课件 + 老师计算结果 成本与效果 土豪方案:扩容接入链路至 154Mbps 接入链路流量强度 = 1.5Mbps/154Mbps≈0.01,排队延迟可忽略,总响应时间≈2 秒 + LAN 延迟 成本极高(每月带宽费用增 100 倍),效果一般; 优化方案:部署本地缓存(命中率 0.4) 接入链路流量强度 = 0.6×1.5Mbps/1.544Mbps≈0.58,总响应时间≈1.2 秒 一次性投入(缓存服务器廉价),效果优于扩容(延迟更低),网络管理员推荐;
2.2.7条件 GET 方法
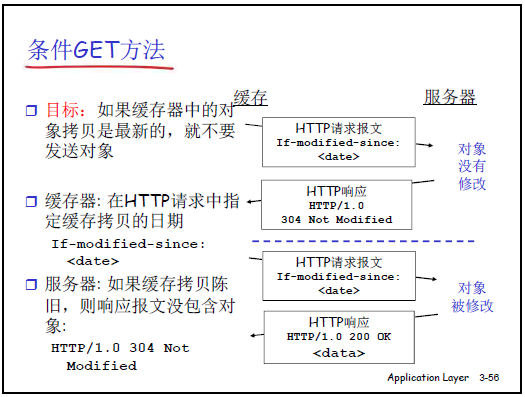
- 课件定义:目标是 “若缓存中的对象拷贝为最新,则不传输对象”,核心是请求报文中的
If-Modified-Since首部行。 - 讲解完整流程:
- 缓存首次获取对象时,存储对象的 “最后修改时间”(从原始服务器响应的
Last-Modified首部获取); - 客户端请求该对象时,缓存向原始服务器发送请求,首部行加
If-Modified-Since: [对象最后修改时间]; - 原始服务器判断:
- 若对象在该时间后未修改:返回响应
HTTP/1.0 304 Not Modified(无实体主体,仅首部行),缓存直接返回本地对象; - 若对象已修改:返回响应
HTTP/1.0 200 OK(含最新对象),缓存更新本地对象并返回给客户端。
- 若对象在该时间后未修改:返回响应
- 缓存首次获取对象时,存储对象的 “最后修改时间”(从原始服务器响应的
- 老师强调作用:解决 “缓存对象与服务器对象版本不一致” 问题,同时减少冗余数据传输(304 响应仅含首部,比 200 响应节省 90% 流量)。
2.3 FTP(文件传输协议)
2.3.1FTP 协议的基本定位与应用场景
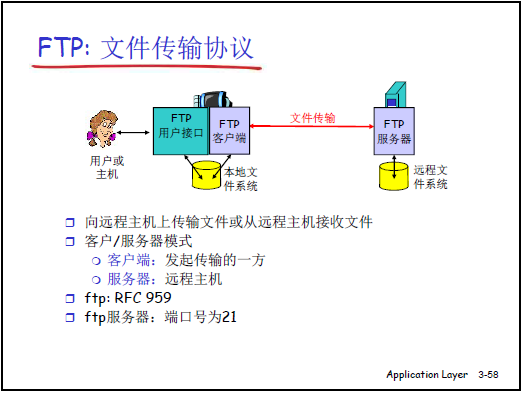
(1)核心内容
- FTP(File Transfer Protocol)是用于向远程主机传输文件或从远程主机接收文件的应用层协议,遵循客户 - 服务器(C/S)模式,对应的 RFC 文档为 RFC 959。
- FTP 服务器默认守候在TCP 21 号端口,客户端发起传输请求,服务器作为远程主机提供文件存储与访问能力。
(2)补充讲解
- 应用场景演变:FTP 是早期互联网文件共享的核心方式,如中国科学技术大学等机构曾长期维护 FTP 服务器,用于共享学术资源、软件等;用户通过 FTP 客户端上载文件到服务器,再由其他用户下载,还可在 BBS 等平台同步服务器文件目录信息。
- 现代替代方案:当前 FTP 使用频率下降,被迅雷、百度云盘、群文件分发等更便捷的工具替代,但 FTP 的 “客户端 - 服务器文件传输” 核心逻辑仍是基础网络应用设计的重要参考。
2.3.2FTP 的客户 - 服务器体系结构
(1)核心内容
FTP 的应用组件分为客户端与服务器两部分,具体结构如下:
| 组件类型 | 包含模块 | 功能描述 |
|---|---|---|
| FTP 客户端 | 用户接口、FTP 客户端软件、本地文件系统 | 发起文件传输请求(上载 / 下载),提供用户操作界面,管理本地文件的读取与存储 |
| FTP 服务器 | FTP 服务器软件、远程文件系统 | 守候在 TCP 21 号端口,接收客户端连接,管理远程文件系统的目录与文件,响应客户端的传输请求 |
(2)补充讲解
- 客户端角色:是 “发起传输的一方”,需主动与服务器建立连接,通过用户接口输入用户名、口令完成认证,再执行目录浏览、文件传输等操作。
- 服务器角色:是 “提供文件服务的远程主机”,需提前运行服务器软件并守候在 21 号端口,维护远程文件系统的权限(如哪些用户可访问哪些目录),并响应客户端的命令。
2.3.3FTP 的核心机制:控制连接与数据连接分离

(1)核心内容
- FTP 使用两个独立的 TCP 连接完成文件传输:
- 控制连接(Control Connection):服务器端端口为 21,用于传输用户认证信息(用户名、口令)、客户端命令(如目录列表、文件传输指令)及服务器响应(状态码、操作结果)。
- 数据连接(Data Connection):服务器端端口为 20,用于传输实际的文件数据(上载 / 下载的文件内容)或目录列表数据。
- 控制连接为 “带外(out of band)” 传输,数据连接为 “带内传输”,二者独立工作,确保命令交互与数据传输不冲突。
(2)补充讲解(连接建立与工作流程)
①控制连接的建立与作用
- 连接发起:FTP 服务器先运行,持续守候在 TCP 21 号端口;客户端主动向服务器的 21 号端口发起 TCP 连接请求,建立控制连接。
- 用户认证:在控制连接上,客户端以明文形式发送用户名(USER 命令)和口令(PASS 命令),服务器验证通过后允许后续操作(注:明文传输存在安全隐患,抓包工具可直接获取认证信息)。
- 命令交互:认证通过后,客户端通过控制连接向服务器发送操作命令(如查看目录、上传 / 下载文件),服务器通过控制连接返回响应(状态码 + 解释),整个命令交互过程仅在控制连接上进行。
②数据连接的建立与作用
- 连接发起:当客户端发送文件传输命令(如下载文件的 RETR 命令、上传文件的 STOR 命令)后,服务器主动向客户端的 20 号端口发起 TCP 连接请求,建立数据连接(与多数 C/S 应用中 “客户端主动建连接” 的逻辑不同,是 FTP 的独特设计)。
- 数据传输:仅在数据连接上传输实际数据 —— 下载时,服务器将文件数据通过数据连接发送给客户端;上传时,客户端将本地文件数据通过数据连接发送给服务器;传输完成后,服务器关闭当前数据连接(若需传输新文件,需重新建立数据连接)。
③关键特点
- 控制连接全程保持打开(直至客户端主动断开),用于持续的命令交互;数据连接 “按需建立、用完关闭”,每个文件传输(或目录列表获取)对应一个独立的数据连接。
- “带外传输” 的含义:控制命令(认证、操作指令)与数据(文件内容)在不同连接上传输,控制命令不占用数据连接带宽,避免命令交互阻塞数据传输。
(4)FTP 的命令与响应机制

①课件核心内容
- 命令(控制连接上传输,ASCII 文本格式):
- USER username:向服务器提交用户名,用于身份认证。
- PASS password:向服务器提交口令,完成身份认证。
- LIST:请求服务器返回当前目录的文件列表(列表数据通过数据连接传输)。
- RETR filename:从服务器的当前目录 “下载” 指定文件(客户端视角),文件数据通过数据连接传输。
- STOR filename:向服务器的当前目录 “上载” 指定文件(客户端视角),文件数据通过数据连接传输。
- 响应(控制连接上传输,ASCII 文本格式,含状态码 + 解释):
- 331 Username OK, password required:用户名验证通过,需进一步提交口令。
- 125 Data connection already open; transfer starting:数据连接已建立,即将开始数据传输。
- 425 Can’t open data connection:无法建立数据连接(如客户端 20 号端口被占用)。
- 452 Error writing file:文件写入失败(如服务器磁盘空间不足)。
②补充讲解
- 命令与响应的交互逻辑:客户端发送一条命令后,需等待服务器返回响应(状态码),确认命令执行结果后再发送下一条命令,避免命令冲突。
- 上载 / 下载的定义(客户端视角):
- 上载(STOR 命令):客户端将本地文件系统的文件发送到服务器的远程文件系统。
- 下载(RETR 命令):客户端从服务器的远程文件系统获取文件,保存到本地文件系统。
- (避免混淆:若以服务器为视角,“上载” 对应服务器 “接收”,“下载” 对应服务器 “发送”,但行业默认以客户端视角定义)。
2.3.5FTP 的状态特性
(1)核心内容
FTP 服务器会维护用户的状态信息,包括:用户当前所在的目录(如 “/home/user/docs”)、用户账户的权限(如是否允许上载)、与该用户对应的控制连接状态。
(2)补充讲解
- 有状态的必要性:FTP 需记录用户当前目录(否则客户端执行 “LIST” 命令时,服务器无法确定返回哪个目录的列表),且需关联用户账户与控制连接(确保同一控制连接下的命令来自已认证用户)。
- 与 HTTP 的对比:HTTP 协议初始设计为 “无状态”(服务器不维护客户端状态,每次请求独立),后续需通过 Cookie 补充状态管理;而 FTP 天然为 “有状态”,服务器需持续维护客户端的会话信息,直至客户端断开控制连接。
2.3.6FTP 与 HTTP 的关键差异(结合前文内容总结)
| 对比维度 | FTP | HTTP(参考 2.2 节内容) |
|---|---|---|
| 连接数量 | 两个独立 TCP 连接(控制连接 21、数据连接 20) | 单个 TCP 连接(非持久连接:一个连接传一个对象;持久连接:一个连接传多个对象) |
| 传输内容分离 | 控制命令(带外,控制连接)、数据(带内,数据连接)分离 | 控制信息(请求行、首部行)与数据(响应体)在同一连接传输(带内) |
| 状态特性 | 有状态(服务器维护用户当前目录、账户权限) | 无状态(服务器不维护客户端状态,需 Cookie 补充) |
| 核心用途 | 文件传输(上载 / 下载,需明确指定文件路径) | Web 资源获取(HTML、图片等,通过 URL 定位资源) |
| 认证方式 | 控制连接上明文传输用户名 + 口令 | 可选认证(如 Basic 认证,也可通过 Cookie、Token 认证,早期也存在明文风险) |
2.3.7后续知识点预告
关于 “FTP 客户端与服务器如何通过 Socket API 建立 TCP 连接”(如服务器调用socket()、bind()、listen()、accept()函数,客户端调用socket()、connect()函数),将在本章 2.8 节(TCP 套接字编程)和 2.9 节(UDP 套接字编程)中详细讲解,当前只需理解 “通过 Socket API 按规则调用,即可建立 TCP 连接” 的核心逻辑,无需深入底层函数调用顺序。
2.4 Email(电子邮件)
2.4.1电子邮件的核心组成与基本流转逻辑
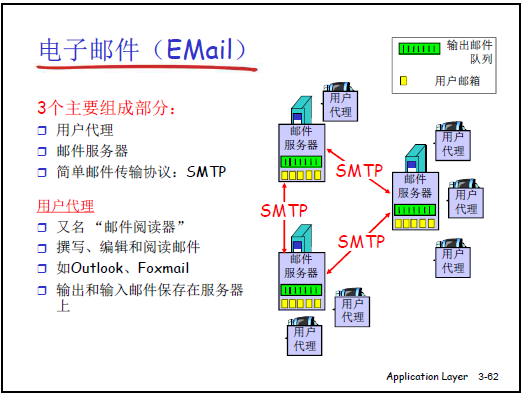
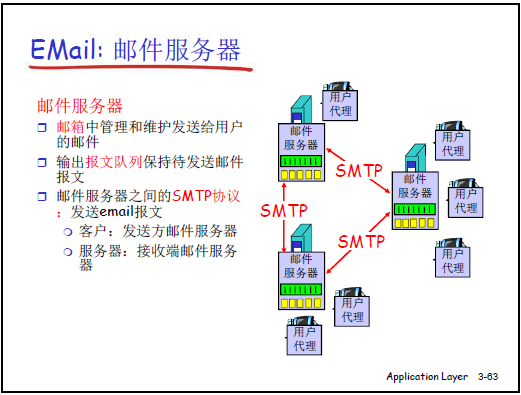
(1)课件核心要点
电子邮件系统包含 3 个主要组成部分:用户代理(User Agent)、邮件服务器(Mail Server)、简单邮件传输协议(SMTP);邮件服务器间通过 SMTP 通信,用户通过邮件访问协议(POP3/IMAP/HTTP)从服务器获取邮件。
(2)补充讲解
-
各组成部分的具体作用
-
用户代理:是用户与电子邮件系统交互的 “客户端软件”,负责撰写、编辑、发送、接收和显示邮件,相当于 “电子邮件应用的代理”。
举例:Outlook、Foxmail(常见桌面端);类比 Web 应用的用户代理是浏览器,FTP 应用的用户代理是 FTP 客户端软件,用户需通过该软件间接与服务器交互。
-
邮件服务器:始终运行(守候在 TCP 25 端口,SMTP 默认端口),核心作用有二:
① 接收用户代理发送的邮件,存入 “输出报文队列”,按顺序转发至目标邮件服务器(避免 “发送速度>转发能力” 导致的拥堵,部分服务器会设置 5-10 分钟 “攒批发送”,减少频繁连接的负载);
② 接收其他邮件服务器发来的邮件,存入对应用户的 “邮箱(Mailbox)”(每个用户在服务器上有专属邮箱,用于暂存他人发送的邮件)。
-
协议分工:
- 「发送端」用SMTP(推模式):将邮件从用户代理→源邮件服务器、源邮件服务器→目标邮件服务器;
- 「接收端」用POP3/IMAP/HTTP(拉模式):用户代理从目标邮件服务器的邮箱中拉取邮件,完成接收。
-
-
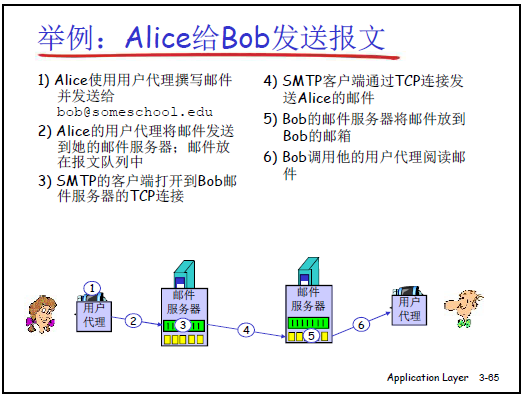
基本流转逻辑(“两推一拉”)
以 “Alice(中科大邮箱)给 Bob(谷歌邮箱)发邮件” 为例:
① 推 1:Alice 通过 Outlook(用户代理),用 SMTP 将邮件推至中科大邮件服务器的 “输出队列”;
② 推 2:中科大邮件服务器(SMTP 客户端)主动连接谷歌邮件服务器(SMTP 服务器),用 SMTP 将邮件推至 Bob 的专属邮箱;
③ 拉:Bob 打开 Foxmail(用户代理),用 POP3/IMAP/HTTP 从谷歌邮件服务器的邮箱中拉取邮件,完成接收。
2.4.2简单邮件传输协议(SMTP,RFC 2821)
(1)核心要点

SMTP 使用 TCP 协议(端口 25),直接在发送方与接收方邮件服务器间传输;传输分 3 阶段(握手、传输报文、关闭);命令 / 响应为 ASCII 文本格式;要求报文(首部 + 主体)为 7 位 ASCII 码。
(2)补充讲解
-
SMTP 的 “客户端 - 服务器” 角色动态性
SMTP 的客户端 / 服务器角色并非固定:
- 当 “用户代理→源邮件服务器” 传输时:用户代理是 SMTP 客户端,源邮件服务器是 SMTP 服务器;
- 当 “源邮件服务器→目标邮件服务器” 传输时:源邮件服务器(如中科大邮件服务器)是 SMTP 客户端,目标邮件服务器(如谷歌邮件服务器)是 SMTP 服务器。
-
传输三阶段的具体交互(ASCII 明文,可通过 Telnet 模拟)


以 “Alice 的邮件从源服务器→目标服务器” 为例,交互过程如下(红色为客户端命令,黑色为服务器响应):
阶段 交互内容(示例) 握手阶段 1. 服务器:220 hamburger.edu(TCP 连接就绪)
2. 客户端:HELO crepes.fr(告知自身身份)
3. 服务器:250 Hello crepes.fr, pleased to meet you(欢迎,握手成功)传输报文阶段 1. 客户端:MAIL FROM: alice@crepes.fr(指定发件人)
2. 服务器:250 alice@crepes.fr... Sender ok(发件人验证通过)
3. 客户端:RCPT TO: bob@hamburger.edu(指定收件人)
4. 服务器:250 bob@hamburger.edu ... Recipient ok(收件人验证通过)
5. 客户端:DATA(开始传输邮件内容)
6. 服务器:354 Enter mail, end with "." on a line by itself(提示 “以单独一行的‘.’结束”)
7. 客户端:Do you like ketchup?How about pickles?.(传输邮件正文,以 “.” 结束)
8. 服务器:250 Message accepted for delivery(邮件接收成功)关闭阶段 1. 客户端:QUIT(请求关闭连接)
2. 服务器:221 hamburger.edu closing connection(关闭连接) -
SMTP 的关键特性与局限性
- 特性 1:持久连接:一次 TCP 连接可传输多个邮件(如中科大服务器向谷歌服务器发多个用户的邮件,无需频繁断连重连),提升传输效率;
- 特性 2:推模式:与 HTTP 的 “拉模式”(客户端请求→服务器响应)不同,SMTP 主动将邮件 “推” 向目标服务器;
- 特性 3:多对象封装:HTTP 一个响应报文仅含一个对象(如一个 HTML 文件),而 SMTP 一个报文可包含多个对象(如邮件正文 + 多张图片附件);
- 局限性:仅支持 7 位 ASCII 码:无法直接传输中文、可执行文件(.exe)、图片(.jpg)等非 ASCII 内容,需通过 MIME 扩展解决;
- 安全隐患:明文传输:命令、响应(含发件人、用户名信息)均为明文,易被窃取或伪造(如伪造 MAIL FROM 字段发送虚假邮件),后续可通过 SSL/TLS 加密(如 SMTPS,端口 465)弥补。

2.4.3邮件报文格式与 MIME 扩展(多媒体邮件扩展)

(1)核心要点
- RFC 822 定义文本报文格式:首部(Header)+ 空行 + 主体(Body);
- MIME(RFC 2045、2056,多媒体邮件扩展):为解决非 ASCII 内容传输,在报文首部添加额外行,申明内容类型、编码方式。
(2)补充讲解
-
RFC 822 文本报文格式细节
-
首部:由多个 “字段名:值” 对组成,常见字段及作用:
字段名 作用示例 To 收件人邮箱(如 “To: bob@hamburger.edu”) From 发件人邮箱(如 “From: alice@crepes.fr”) Subject 邮件主题(标题,如 “Subject: Picture of yummy crepe”) CC 抄送:将邮件副本发送给其他接收者,所有收件人可见抄送对象(如抄送领导,同事可查看) BCC 暗抄送:将邮件副本发送给其他接收者,主收件人不可见暗抄送对象(隐私性更强) -
空行:严格分隔首部与主体,是报文格式的核心分隔标志(无空行则首部与主体会混淆);
-
主体:邮件正文,原始仅支持 7 位 ASCII 字符(英文可正常传输,中文会乱码)。
-
-
MIME 扩展的作用与原理

-
核心问题:SMTP 仅支持 7 位 ASCII,非 ASCII 内容(如中文 “你好”、JPEG 图片二进制流)无法直接传输;
-
解决思路:通过 MIME 字段声明编码规则,将非 ASCII 内容 “转换” 为 ASCII 格式传输,接收端再 “还原” 为原始内容;
-
关键 MIME 字段(示例):
From: alice@crepes.fr To: bob@hamburger.edu Subject: Picture of yummy crepe. MIME-Version: 1.0 # 声明MIME版本 Content-Transfer-Encoding: base64 # 声明编码方式为Base64 Content-Type: image/jpeg # 声明内容类型为JPEG图片 base64 encoded data ..... # Base64编码后的图片数据 -
Base64 编码原理:将非 ASCII 的二进制数据(如中文的 2 字节、图片的二进制流)按规则映射为 ASCII 字符集中的 64 种可打印字符(0-9、A-Z、a-z、+、/),传输后接收端通过反向映射还原原始数据(虽增加约 33% 的数据量,但解决了兼容性问题)。
-
2.4.4邮件访问协议(从邮件服务器获取邮件)
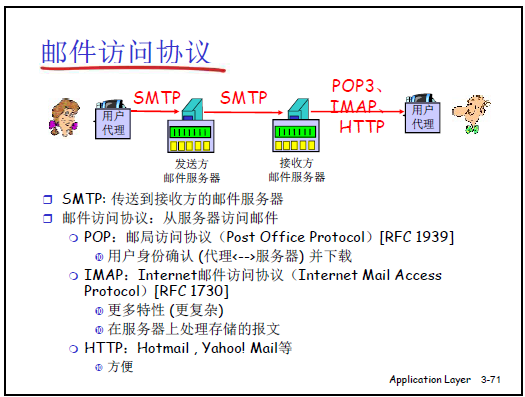
(1)核心要点
邮件访问协议用于用户代理从邮件服务器的 “用户邮箱” 中获取邮件,主要包括 3 类:
- POP3(RFC 1939):邮局访问协议,简单的 “下载型” 协议;
- IMAP(RFC 1730):Internet 邮件访问协议,复杂的 “管理型” 协议;
- HTTP:用于 Web 邮件(如 Hotmail、Yahoo! Mail),借助 HTTP 的文件传输能力实现邮件收发。
(2)邮局访问协议(POP3,Port 110)
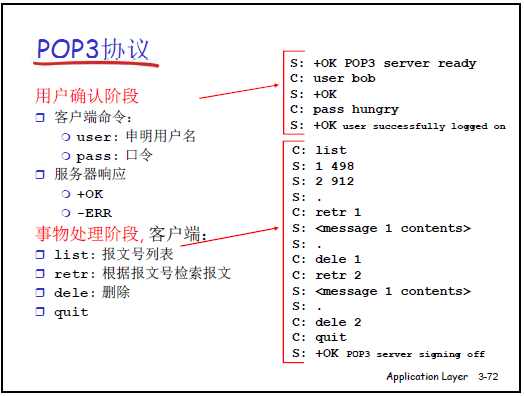
-
核心定位:功能简洁的 “下载工具”,仅支持身份认证与邮件下载,适用于单设备(如个人 PC)使用场景。
-
交互三阶段:
-
用户确认阶段(认证):
- 客户端发送
USER <用户名>(如 “user bob”),服务器返回+OK(用户名有效); - 客户端发送
PASS <密码>(如 “pass hungry”),服务器返回+OK(认证成功)或-ERR(密码错误); - 安全问题:用户名、密码均为明文传输,需结合 SSL/TLS(如 POP3S,Port 995)加密。
- 客户端发送
-
事务处理阶段:
-
常用命令:
命令格式 作用示例 LIST 请求邮件列表(如服务器返回 “1 498”“2 912”,表示 1 号邮件 498 字节、2 号 912 字节),以 “.” 结束 RETR <邮件号> 下载指定邮件(如 “retr 1” 下载 1 号邮件),服务器返回邮件内容,以 “.” 结束 DELE <邮件号> 标记指定邮件为删除(如 “dele 1”),断开连接后生效 -
两种下载模式:
模式 特点 优缺点 下载并删除 下载后服务器删除该邮件 优点:不占用服务器空间;缺点:仅单设备可见,其他设备(如手机)无法获取 下载并保留 下载后服务器保留该邮件 优点:多设备(平板、PC)可重复获取;缺点:长期占用服务器空间
-
-
关闭阶段:客户端发送
QUIT,服务器返回+OK(关闭连接,标记删除的邮件生效)。
-
-
关键特性:无状态协议。因 POP3 不支持远程目录维护(无法在服务器邮箱创建文件夹),服务器仅需记录 “用户是否认证”“用户邮箱” 等基础信息,无需跟踪邮箱内文件的操作状态(如邮件是否被移动)。
(3) Internet 邮件访问协议(IMAP,Port 143)

- 核心定位:功能复杂的 “邮件管理工具”,支持下载与远程目录维护,适用于多设备同步(如手机、平板、PC)场景。
- 核心特性(对比 POP3):
- 远程目录维护:用户可在客户端远程管理服务器邮箱的文件夹(如创建 “工作邮件”“个人邮件” 文件夹,将邮件在文件夹间移动、标记 “已读 / 未读”);
- 有状态协议:服务器需维护客户端的操作状态(如当前访问的文件夹、邮件的读取状态),确保多设备同步(如手机标记 “已读”,电脑打开时也显示 “已读”);
- 精细带宽控制:支持仅下载邮件首部(主题、发件人),再决定是否下载正文与附件(如手机流量环境下,先看主题再选择性下载),节省带宽。
(4)HTTP 协议(Web 邮件场景)
- 核心定位:借助 HTTP 的 “上载 / 下载” 能力,实现无客户端的邮件访问(如网页版 QQ 邮箱、Yahoo! Mail)。
- 原理:
- 发送邮件:用户在浏览器(HTTP 客户端)填写邮件内容,通过 HTTP POST 将内容上传至 Web 邮件服务器,服务器再通过 SMTP 将邮件转发至目标服务器;
- 接收邮件:用户通过浏览器发送 HTTP GET 请求,Web 邮件服务器从用户邮箱读取邮件,封装为 HTTP 响应返回给浏览器;
- 优势:无需安装专用客户端(如 Outlook),跨设备、跨系统(Windows、macOS、手机浏览器)均可访问,兼容性极强。
2.5.5电子邮件协议流转全景总结
| 链路类型 | 涉及协议 | 方向 | 核心动作 |
|---|---|---|---|
| 发送链路(推) | SMTP(Port 25) | 用户代理→源邮件服务器 | 上传邮件至源服务器队列 |
| 发送链路(推) | SMTP(Port 25) | 源邮件服务器→目标邮件服务器 | 转发邮件至目标服务器用户邮箱 |
| 接收链路(拉) | POP3/IMAP/HTTP | 用户代理→目标邮件服务器 | 从用户邮箱拉取邮件至本地 |
| 扩展支持 | MIME | 全链路 | 解决非 ASCII 内容传输 |
| 安全增强 | SSL/TLS | 全链路 | 加密 SMTP/POP3/IMAP 的明文数据 |
2.5 DNS(Domain Name System)
2.5.1DNS 的必要性 —— 为什么需要 DNS

- IP 地址的局限性:IP 地址(如 IPv4 的 32 位、IPv6 的 128 位数字)是主机 / 路由器的唯一标识,但存在 “难记忆、无实际意义” 的问题,不符合人类使用习惯(例如用户更易记www.ustc.edu.cn,而非202.38.64.1)。
- 核心需求:实现 “有意义的字符串(域名)” 到 “IP 地址” 的转换,衔接人类认知习惯与网络底层的 IP 寻址需求 —— 用户输入域名后,需通过 DNS 将其转换为 IP 地址,才能让应用(如浏览器、邮件客户端)与目标服务器建立连接。
2.5.2DNS 的历史 —— 从集中式到分布式的演进

-
ARPANET 时期的集中式方案:
-
早期 ARPANET 采用 “平面命名”(主机名无层次,如 “alice”“bob”),通过一台集中维护站管理Hosts.txt文件,记录所有主机名与 IP 的映射关系;
-
每台主机需定时从维护站下载Hosts.txt更新本地映射。
-
-
集中式方案的缺陷:
-
重名问题:主机数量激增后,平面命名易出现全球重名,难以分配唯一标识;
-
管理难题:Hosts.txt文件体积膨胀,更新、发布、查找效率极低;
-
可靠性差:集中维护站宕机则全网无法解析。
-
-
演进方向:为解决集中式缺陷,DNS 采用 “层次化命名 + 分布式解析” 的设计,替代传统集中式方案。
2.5.3DNS 的总体思路与核心目标

-
总体思路:
-
命名机制:分层的、基于域的树状命名结构,避免重名;
-
解析机制:通过若干分布式数据库(名字服务器)协同完成 “域名→IP” 转换;
-
传输依赖:运行在 UDP 之上,使用 53 号知名端口(无需 TCP 握手,降低解析延迟,契合 “轻量、快速” 需求);
-
复杂性定位:核心功能在网络边缘(端系统的应用层)实现,而非核心网络,降低核心网络负担。
-
-
核心目标:
-
基础目标:实现 “主机名→IP 地址” 的高效、可靠转换;
-
扩展目标:
-
主机别名转换(Host aliasing):将易记的 “别名” 转换为服务器的 “规范名”(如www.ibm.com(别名)→servereast.backup2.ibm.com(规范名));
-
邮件服务器别名转换(Mail server aliasing):将邮件地址中的域名(如user@ustc.edu.cn)转换为邮件服务器的规范名及 IP;
-
负载均衡(Load Distribution):为同一域名(如www.taobao.com)分配多台服务器 IP,根据用户位置、服务器负载动态选择,平衡压力。
-
-
2.5.4DNS 系统需解决的三大核心问题

(1)问题 1:如何命名设备 —— 层次化名字空间(The DNS Name Space)


-
解决的核心痛点:平面命名易重名,无法满足海量设备(百亿 / 千亿级)的唯一标识需求。
-
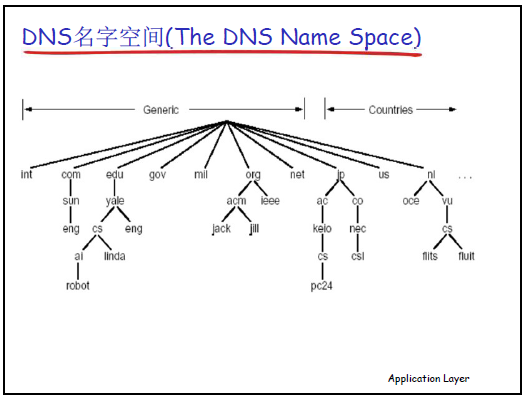
解决方案:层次树状命名结构:
-
结构层级(从顶层到底层):
-
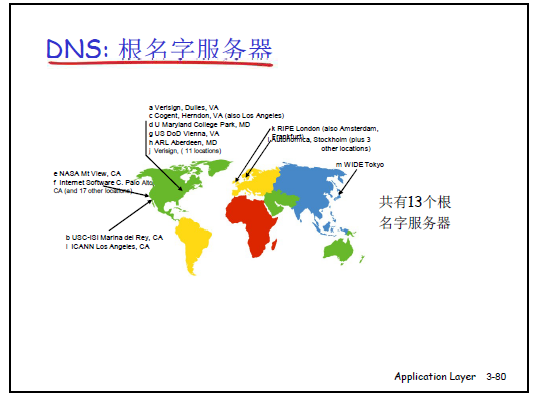
根(Root):全球共 13 个根名字服务器(分布于北美、欧洲、日本等,中国大陆暂无),避免单根宕机导致全网解析失效;
-
顶级域(Top-Level Domains, TLD):分两类:
-
通用顶级域(Generic TLD):如.com(商业)、.edu(教育)、.gov(政府)、.net(网络服务)、.org(非营利组织);
-
国家 / 地区顶级域(Country-Code TLD):如.cn(中国)、.us(美国)、.jp(日本)、.uk(英国);
-
-
子域(Subdomains):顶级域下可划分二级域(如.edu.cn(中国教育网)、.com.cn(中国商业)),二级域可进一步划分三级域(如ustc.edu.cn(中国科学技术大学)),以此类推;
-
主机(Host):树状结构的 “树叶”,每个主机属于某一子域(如www.ustc.edu.cn中,www是主机名,对应科大的 Web 服务器)。
-
-
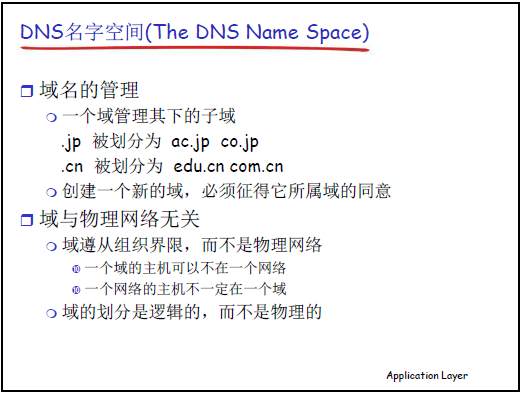
域名规则:
-
域名格式:从 “底层(主机 / 子域)” 向 “顶层(根)” 遍历,各层级用 “.” 分隔(如主机域名www.auto.ustc.edu.cn,子域域名auto.ustc.edu.cn);
-
域的管理:子域需经上级域同意才能创建(如创建auto.ustc.edu.cn,需ustc.edu.cn域管理者授权);
-
域与物理网络无关:域是 “逻辑划分”,同一域的主机可分布在不同物理网络(如科大子域的主机可在合肥、北京、苏州等地),同一物理网络的主机也可属于不同域。
-
-
(2)问题 2:如何完成 “名字→IP” 转换 —— 分布式解析机制





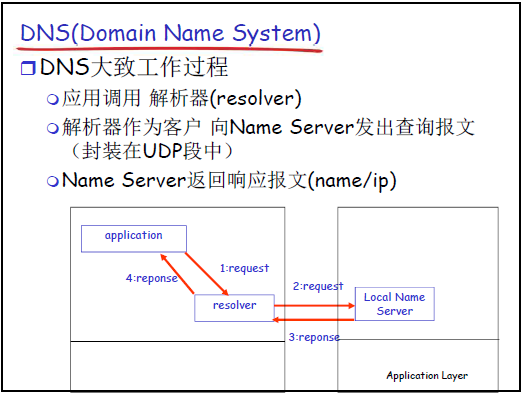

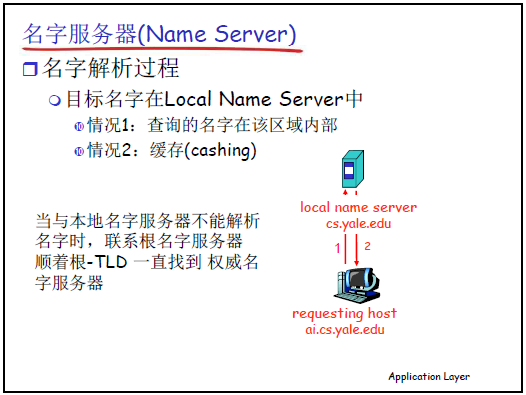
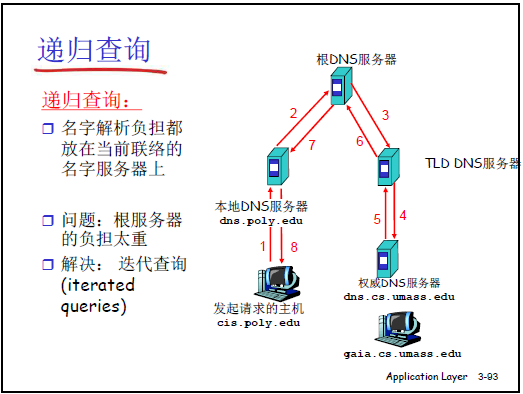
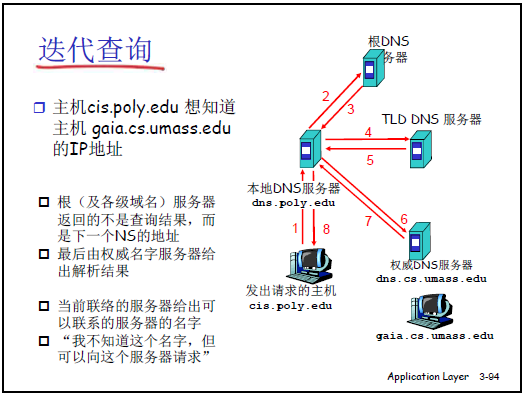

-
集中式解析的缺陷:若用单台名字服务器维护全球所有域名 - IP 映射,会面临 “单点故障(服务器宕机则全网失效)、通信容量不足(查询请求过载)、维护复杂(增删域名需频繁修改单库)” 的问题。
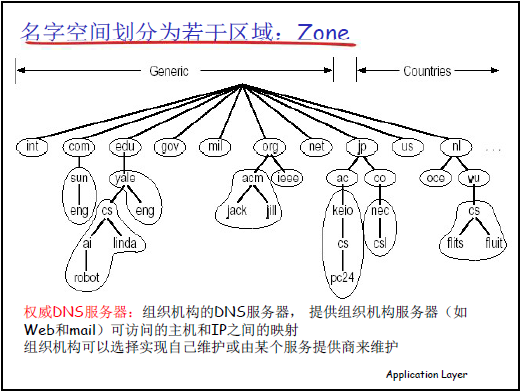
-
解决方案:分布式解析(区域划分 + 名字服务器协同)
-
区域(Zone)划分:
-
将 DNS 层次化名字空间拆分为 “互不相交的区域”,每个区域是树状结构的一部分(如ustc.edu.cn可作为一个区域,包含其下所有子域和主机);
-
每个区域部署 “权威名字服务器”(Authoritative Name Server),维护该区域内域名 - IP 映射的 “权威记录”(信息最准确,由区域管理者维护,不可随意篡改)。
-
-
名字服务器的类型与角色:
-
根名字服务器:全球 13 个,负责指向各顶级域的权威服务器(仅存储 “顶级域→顶级域权威服务器” 的映射,不存储具体主机的映射);
-
顶级域(TLD)服务器:负责指向二级域的权威服务器(如.edu.cn的 TLD 服务器存储 “ustc.edu.cn→ustc.edu.cn权威服务器” 的映射);
-
权威名字服务器:负责本区域内所有域名的 “域名→IP” 映射(如ustc.edu.cn的权威服务器存储www.ustc.edu.cn、mail.ustc.edu.cn等主机的 IP);
-
本地名字服务器(Local Name Server):
-
非层次化结构的 “代理服务器”,由用户设备通过 DHCP 自动配置或手工设置(如家庭网络的本地服务器通常是路由器 IP,企业 / 学校通常有专用本地服务器);
-
用户发起 DNS 查询时,先发送到本地名字服务器,本地服务器优先查询自身缓存,缓存无结果则逐层向根、TLD、权威服务器查询。
-
-
-
解析流程(以 “主机 cis.poly.edu 查询 gaia.cs.umass.edu 的 IP” 为例):
-
两种查询方式:
类型 定义 流程(以本地服务器为核心) 递归查询 本地服务器接收用户查询后,全程代为向根、TLD、权威服务器查询,最终将结果返回用户 用户→本地服务器(请求)→本地服务器→根→TLD→权威服务器(逐层查询)→权威服务器→TLD→根→本地服务器→用户(返回结果) 迭代查询 本地服务器向某一级服务器查询时,仅获取 “下一级服务器地址”,需自行继续查询 用户→本地服务器(请求)→本地服务器→根(根返回 TLD 地址)→本地服务器→TLD(TLD 返回权威服务器地址)→本地服务器→权威服务器(获取 IP)→本地服务器→用户 -
关键依赖:上层域需维护两条核心记录,确保解析可向下追溯:
-
NS记录:格式(子域名称,子域权威服务器名称,NS,TTL),如(ustc.edu.cn,dns.ustc.edu.cn,NS,86400);
-
A记录:格式(权威服务器名称,权威服务器 IP,A,TTL),如(dns.ustc.edu.cn,202.38.64.5,A,86400)。
-
-
-
性能优化:缓存机制
-
原理:非权威服务器(如本地服务器、TLD 服务器)查询到域名 - IP 映射后,会将该记录缓存,默认TTL(生存时间)为 2 天(86400 秒 ×2);
-
作用:
-
提升效率:后续相同域名查询可直接从缓存获取,无需逐层查询;
-
保证一致性:TTL过期后,缓存记录自动删除,需重新查询权威服务器,避免目标服务器 IP 变更导致缓存失效。
-
-

-
(3)问题 3:如何维护 DNS 系统 —— 域与记录的增删改查

-
核心维护对象:资源记录(Resource Record, RR)——DNS 分布式数据库的基本单元,所有域名 - IP 映射均以 RR 形式存储。
-
RR 格式:(domain_name, ttl, type, class, value)
-
domain_name:域名(如www.ustc.edu.cn、ustc.edu.cn);
-
ttl:生存时间(单位:秒),决定记录在缓存中的保留时长;
-
class:类别,Internet 环境下固定为IN(Internet);
-
type:记录类型(核心类型如下);
-
value:记录值(随type变化)。
-
-
核心 RR 类型:
类型 作用 示例(domain_name, ttl, type, class, value) A 主机名→IP 地址(仅 IPv4) (www.ustc.edu.cn,86400,A,IN,202.38.64.1) NS 域→该域的权威服务器名称 (ustc.edu.cn,86400,NS,IN,dns.ustc.edu.cn) CNAME 别名→规范名(主机别名转换) (www.ibm.com,86400,CNAME,IN,servereast.backup2.ibm.com) MX 域名→邮件服务器名称(邮件别名转换) (ustc.edu.cn,86400,MX,IN,mail.ustc.edu.cn)
-
-
新增一个域的流程(以 “在.com 域中创建networkutopia.com” 为例):
-
步骤 1:向.com域的注册机构(如 Network Solutions)提交申请,提供networkutopia.com的权威服务器信息(包括权威服务器名称,如dns1.networkutopia.com;权威服务器 IP,如212.212.212.1);
-
步骤 2:注册机构在.com的 TLD 服务器中添加两条 RR 记录:
-
NS 记录:(networkutopia.com,dns1.networkutopia.com,NS,86400);
-
A 记录:(dns1.networkutopia.com,212.212.212.1,A,86400);
-
-
步骤 3:在networkutopia.com的权威服务器中添加内部服务的 RR 记录:
-
Web 服务器:(www.networkutopia.com,86400,A,IN,212.212.212.2);
-
邮件服务器:(networkutopia.com,86400,MX,IN,mail.networkutopia.com)、(mail.networkutopia.com,86400,A,IN,212.212.212.3);
-
-
步骤 4:等待全球 DNS 服务器缓存更新,新增域即可被全网解析。
-
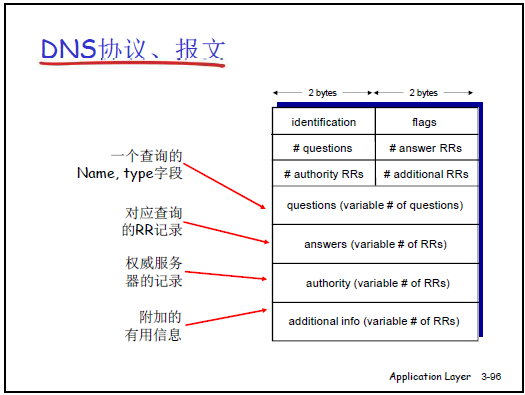
2.5.5DNS 协议与报文格式
- 协议特点:DNS 查询报文与响应报文格式完全相同,仅通过 “标志位” 区分查询 / 响应。
- 报文结构(从首部到数据区):
| 字段 | 长度(字节) | 作用 |
|---|---|---|
| 标识符(Identification) | 2 | 唯一标识一次查询 / 响应,确保客户端能匹配请求与响应 |
| 标志位(Flags) | 2 | 包含 “查询 / 响应”“递归请求 / 可用”“权威响应” 等标识(如0x0100表示响应、权威) |
| 问题数(# Questions) | 2 | 表示 “问题区” 包含的查询条目数量(通常为 1) |
| 回答数(# Answers) | 2 | 表示 “回答区” 包含的 RR 记录数量(查询成功则≥1,失败则为 0) |
| 权威数(# Authority RRs) | 2 | 表示 “权威区” 包含的权威服务器 RR 数量 |
| 附加数(# Additional RRs) | 2 | 表示 “附加区” 包含的额外 RR 数量(如权威服务器的 A 记录,避免二次查询) |
| 问题区(Questions) | 可变 | 存储查询的域名和类型(如查询www.ustc.edu.cn的 A 记录) |
| 回答区(Answers) | 可变 | 存储查询结果(如www.ustc.edu.cn对应的 A 记录) |
| 权威区(Authority) | 可变 | 存储权威服务器的 RR 记录(如ustc.edu.cn的 NS 记录) |
| 附加区(Additional) | 可变 | 存储权威服务器的 A 记录(如dns.ustc.edu.cn的 A 记录) |
2.5.6DNS 的安全性与健壮性

-
常见攻击类型及防护:
-
DDoS 攻击(分布式拒绝服务):
-
攻击目标:根名字服务器、TLD 服务器;
-
攻击方式:发送海量 Ping 请求或 DNS 查询,占用服务器带宽和算力;
-
防护措施:
-
根服务器:部署流量过滤器(防火墙),过滤异常请求;
-
本地服务器:缓存 TLD 服务器 IP,无需频繁查询根,降低根服务器负载;
-
-
效果:根服务器从未被成功攻击瘫痪,TLD 服务器攻击影响有限(依赖缓存)。
-
-
重定向攻击:
-
攻击方式:
-
中间人攻击:截获用户 DNS 查询,伪造错误 IP(如将www.bank.com指向钓鱼网站 IP);
-
DNS 中毒:向名字服务器发送伪造的 RR 记录,使其缓存错误映射;
-
-
防护难点:需分布式截获和伪造,技术门槛高,实际成功案例少。
-
-
利用 DNS 的 DDoS 放大攻击:
- 攻击方式:伪造目标 IP 发送 DNS 查询(查询报文小),服务器返回大量 RR 记录(响应报文大),利用 “响应> 查询” 的流量差攻击目标;
- 效果:放大倍数有限(通常 10-100 倍),且易被运营商检测,影响较小。
-
-
总体健壮性:DNS 通过 “多根冗余、分布式解析、缓存优化、流量防护”,成为 Internet 中可靠性最高的应用层服务之一。
2.5.7DNS 核心知识点总结
-
本质:应用层基础性服务,为其他应用(Web、FTP、Email)提供 “域名→IP” 转换支撑;
-
核心设计:层次化名字空间(解决命名)+ 分布式解析(解决转换)+ 资源记录(解决维护);
-
关键特性:
-
复杂性在边缘(端系统应用层),核心网络无 DNS 功能;
-
依赖 UDP 53 端口,轻量快速;
-
缓存优化性能,TTL 保证一致性;
-
支持别名转换、负载均衡等扩展功能;
-
-
核心价值:连接人类 “易记域名” 与网络 “IP 寻址”,是 Internet 正常运行的基石。
2.6 P2P 应用
2.6.1纯 P2P 架构的定义与核心特点(对应课件 “纯 P2P 架构” 示意图)
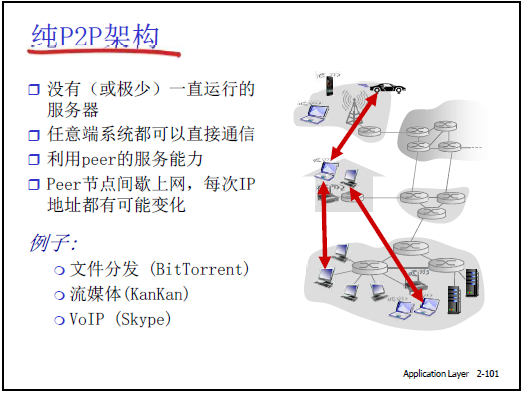
(1)架构定义
- 无(或极少)一直运行的中心服务器
- 任意端系统(Peer 节点)可直接通信;
- 每个 Peer 节点既是客户端也是服务器:在某会话中请求其他 Peer 资源时为客户端,在另一会话中为其他 Peer 提供资源时为服务器;
- 节点特性:间歇性连接、IP 地址可能动态变化,整体架构难以集中管理;
- 典型例子:Gnutella 、迅雷。
(2)核心优势
①极强的可扩展性
- 随 Peer 节点数量增加,请求资源的节点与提供服务的节点同步增加(新节点既消耗资源也贡献资源),系统可轻松扩展到数百万甚至上千万用户级;
- 对比 C/S 模式:C/S 因依赖中心服务器,用户量激增时服务器会成为瓶颈,难以支撑大规模用户。
②高可靠性
- 无单点故障风险:业务由成千上万个 Peer 节点共同提供,单个节点宕机不会导致整个系统瘫痪;
- 流量分布式:避免 C/S 模式中 “服务器宕机则全业务中断” 的问题(如 Skype、微信语音通话,即使部分节点下线,其他节点仍可通信)。
③低成本
- 无需购买 / 维护昂贵的中心服务器及大带宽网络,成本分散到每个 Peer 节点(用户仅承担自身设备成本);
- 对比 C/S 模式:C/S 需承担服务器硬件、软件许可证、带宽租赁等巨额运营成本(如视频点播 C/S 服务器,每月需向 ISP 支付高额流量费)。
④应用场景(老师补充实例)
- 文件分发:BitTorrent(BT)、迅雷;
- 流媒体:KanKan(国内方案,首次进入国外顶级教材);
- 实时通信:VOIP(Skype)、微信 / QQ / 钉钉语音 / 视频通话(基于 P2P 优化,效果优于早期 Skype)。
2.6.2文件分发时间对比:C/S 模式 vs P2P 模式
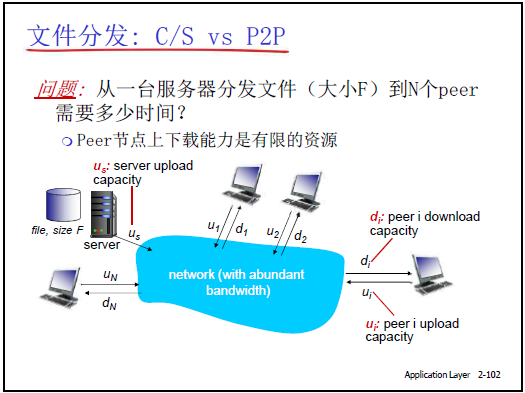
(1)前提定义
- 文件大小:F;
- 服务器上载带宽:Us;
- Peer 节点:第i个 Peer 的上载带宽Ui、下载带宽Di,客户端总数N;
- 客户端最小下载带宽:dmin(所有 Peer 中下载最慢的节点带宽)。
(2)C/S 模式文件分发时间
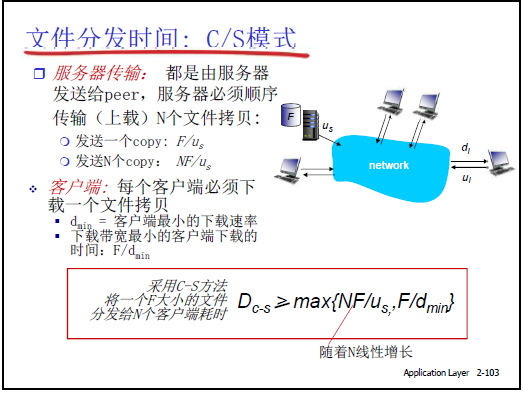
①时间下限公式
\(D_{C/S} \ge \max \left\{ \frac{NF}{U_s}, \frac{F}{d_{min}} \right\}\)
②公式含义
- NF/Us:服务器需向N个客户端各上载 1 份文件,总上载量NF,受服务器带宽Us限制的时间;
- dmin:每个客户端需下载 1 份文件,最慢客户端(dmin)的下载时间(决定所有客户端的 “最慢完成时间”)。
③瓶颈分析
- N 较小时(如 8 个客户端):服务器带宽Us富裕(如Us=10Ui),瓶颈是dmin(客户端下载能力不足),下载时间较短;
- N 极大时(如 100 万客户端):服务器需上载 100 万份文件,NF/Us成为瓶颈,时间随N 线性增加(例:8 个客户端 1 秒,100 万客户端需 100 万秒,约 11.5 天,完全不可忍受);
- 本质:C/S 模式中客户端上载能力被浪费,所有负载集中于服务器。
(3)P2P 模式文件分发时间

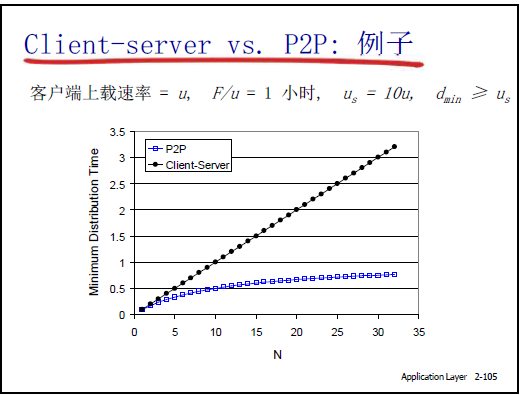
①时间下限公式
\(D_{P2P} \ge \max \{ \frac{F}{U_s}, \frac{F}{d_{min}}, \frac{NF}{u_s + \sum u_i} \}\)
②公式含义
- \(\frac{F}{U_s}\):服务器仅需上载 1 份文件(文件首次进入网络),是服务器侧的最小时间;
- \(\frac{F}{d_{min}}\):与 C/S 一致,最慢客户端的下载时间;
- $ \frac{NF}{u_s + \sum u_i} $:总下载量NF由 “服务器上载带宽Us+ 所有 Peer 上载带宽总和∑ui” 共同承担,体现 P2P“人人为我,我为人人” 的协作特性。
③优势分析(老师结合曲线)
- N 极大时:\(\sum u_i\)随N增加而增大,分母\(u_s + \sum u_i\)显著提升,时间增加平缓(非线线性);
- 对比曲线:
- C/S 曲线:随N(0-35)线性上升,N=35 时时间约 3.5 小时;
- P2P 曲线:随N缓慢上升,N=35 时时间约 1 小时,优势随N增大更明显;
- 本质:P2P 将 “服务器单点负载” 转化为 “全网 Peer 协作负载”,可扩展性远优于 C/S。
2.6.3P2P 文件分发实例:BitTorrent(BT)
(1)核心概念
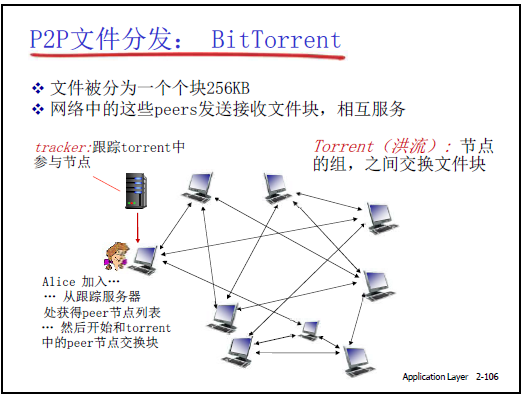
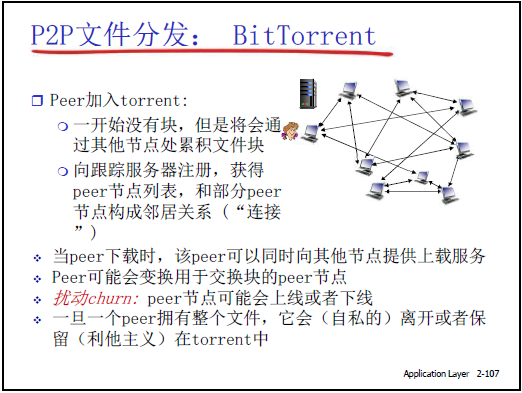
- 洪流(Torrent):一组交换同一文件块的 Peer 节点集合(如 “计算机网络课件.torrent” 对应的所有下载 / 上传节点);
- 跟踪服务器(Tracker):维护 Torrent 中活跃 Peer 列表,新 Peer 加入时需注册并获取 Peer 邻居列表;
- 文件分块:将文件分割为 256KB 的独立块,Peer 通过交换块完成文件下载(避免单块过大导致的传输失败);
- 扰动(Churn):Peer 动态上线 / 下线,部分 Peer 下载完整个文件后成为 “种子(Seed)”—— 可选择离开(利己)或留下(利他,继续为他人提供上载)。


(2)块请求策略
①bitmap 状态同步(对应课件 “bitmap 表格图”)
- Peer 定期向邻居发送 “位图(bitmap)”:1 个比特标识 1 个块的持有状态(1 = 拥有,0 = 未拥有);
- 作用:所有 Peer 通过 bitmap 实时知晓其他节点的块持有情况(如 Alice 的 bitmap 显示 “块 1-4 为 1,块 5-10 为 0”,则知道需向邻居请求块 5-10)。
②分阶段请求逻辑(老师结合 “吸血鬼” 实例)
- 阶段 1:新 Peer(吸血鬼,无块):
- 策略:随机请求块(饥不择食),先获取 4 块文件;
- 原因:无块时无法为他人提供服务,随机请求可快速获得 “服务资本”;
- 阶段 2:拥有 4 块后:
- 策略:稀缺优先(请求 Torrent 中最少见的块);
- 目的:避免稀缺块因 Peer 下线丢失(如某块仅 1 个 Peer 拥有,若该 Peer 下线则全网无法获取),保障集体利益;
- 关联:稀缺块持有者会被更多 Peer 请求,间接提升自身被服务的优先级(利他即利己)。
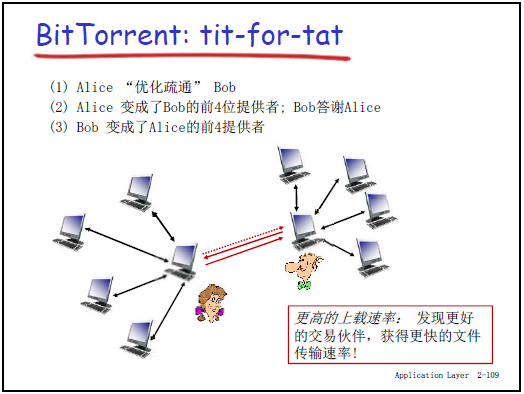
(3)块发送策略:一报还一报(Tit-for-Tat)
①核心逻辑
- Peer 仅向 “对自己提供最大带宽” 的 4 个邻居发送块(优化疏通,避免撒胡椒面式的带宽浪费);
- 例:Alice 的邻居中,Bob 提供的下载带宽最大,则 Alice 优先向 Bob 发送块,其余邻居排队。
②动态调整机制(老师补充细节)
- 每 10 秒:重新评估邻居带宽,更新 “top4 带宽提供者” 列表,优先服务新列表中的节点;
- 每 30 秒:随机选择 1 个排队的邻居发送块(“优化疏通试探”);
- 目的:避免错过高带宽潜力节点(如某排队节点实际带宽高但未被发现),提升全网整体传输速率;
- 良性循环实例:
- Alice 随机向 Bob 发送块(优化疏通);
- Bob 成为 Alice 的 top4 带宽提供者,开始向 Alice 提供高带宽服务;
- Bob 成为 Alice 的 top4,Alice 继续优先服务 Bob,双方带宽持续提升。
2.6.4P2P 文件共享的核心问题与解决方案

P2P 文件共享需解决 2 大核心问题:资源定位(找到有目标文件的 Peer)、节点动态管理(处理 Peer 加入 / 退出),分三类解决方案:
(1)集中式目录
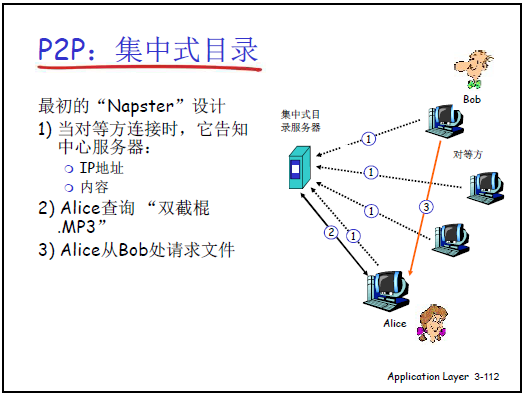
①工作原理
- Peer 注册:Peer 上线时向中心目录服务器上报 “自身 IP + 共享文件列表”;
- 资源查询:用户(如 Alice)输入关键字(如 “双截棍.MP3”),客户端向目录服务器请求;
- 文件传输:服务器返回有该文件的 Peer 列表(如 Bob),Alice 与 Bob 直接建立 HTTP 连接下载;
- 资源更新:Alice 下载完成后,向目录服务器注册该文件,成为新的服务节点(可向他人提供下载)。
②问题

- 单点故障:目录服务器宕机则整个系统瘫痪;
- 性能瓶颈:百万级 Peer 同时注册 / 查询时,服务器负载过高;
- 版权风险:服务器易被定位,版权方可追责(Napster 因提供非授权 MP3 目录服务被关闭)。
(2)全分布式

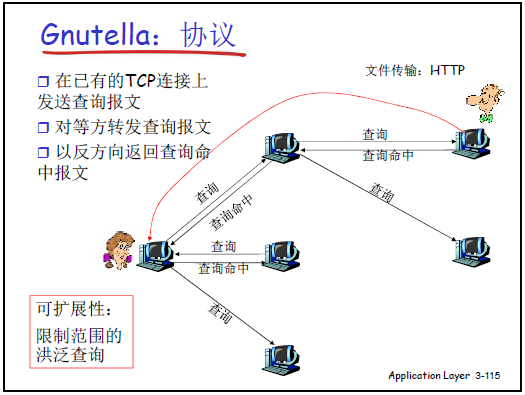

①架构特点
- 无中心服务器,Peer 通过 TCP 连接构成 “覆盖网(Overlay Network)”—— 逻辑网络,边为 Peer 间的协作关系(非物理链路,如 X 与 Y 有 TCP 连接则为邻居);
- 协议开源:任何人可实现 Gnutella 客户端(类似 HTTP 与浏览器的关系),支持多版本互通。
②资源定位:查询洪泛(Flooding)
- Alice 向所有邻居发送查询请求(如 “双截棍.MP3”);
- 邻居收到请求后,除 “入站 Peer” 外,向所有其他邻居转发请求;
- 拥有文件的 Peer(如 Bob)沿原路径反向返回 “查询命中” 消息;
- Alice 收到消息后,直接与 Bob 建立连接下载。
③优化与问题(老师补充)
- 查询优化:
- TTL(生存时间):设置跳数限制(如 5-7 跳),避免查询无限循环;
- 记录已转发查询:避免重复转发同一请求;
- 问题:
- 覆盖网构建复杂:新 Peer 需通过 “死党列表”(软件配置的常在线 Peer IP)发起 Ping,接收 Pong 后选 8-10 个邻居;
- 查询效率低:泛洪导致网络负载大,实际使用中 “难以找到资源”,后期开源仍未普及。
(3)混合体
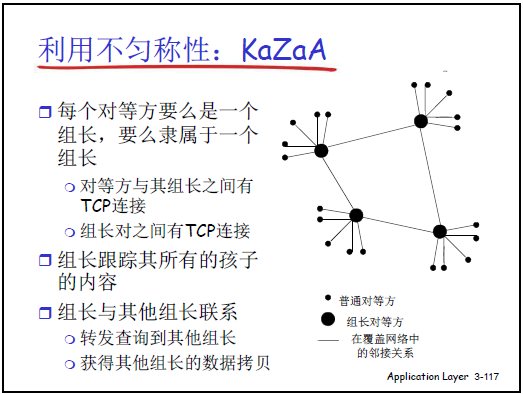


①架构设计
- Peer 分两类:组长(Super Peer) 和组员(Ordinary Peer);
- 层级关系:组员仅连接 1 个组长,组长间建立 TCP 连接构成骨干网;
- 集中与分布式结合:组内集中(组长跟踪组员内容),组间分布式(组长间转发查询)。
②资源定位流程
- 组员向组长发送关键字查询(如 “周杰伦 - 青花瓷.MP3”);
- 组长匹配组员共享内容,若命中则返回 “文件哈希值 + Peer IP”;
- 若未命中,组长向其他组长转发查询,接收结果后汇总返回;
- 组员用 “文件哈希值”(唯一标识,避免同名文件混淆)向目标 Peer 请求下载。
③优化策
- 请求排队:限制并行上载数量,保障每个传输的带宽;
- 激励优先权:优先服务上载多的用户,鼓励利他行为;
- 并行下载:从多 Peer 下载同一文件的不同块(利用 HTTP 字节范围首部),提升速率。
2.6.5结构化 P2P:分布式哈希表(DHT)

(1)核心思想
- 用哈希表实现资源与 Peer 的精准映射:Peer 和资源均分配唯一 ID(哈希值,如 16 字节),构建有序覆盖网(如环形),按规则路由查询;
- 优势:解决非结构化 P2P 的查询效率低问题,是现代 P2P 的主流技术。
(2)关键机制
①ID 分配
- Peer ID:由 Peer 的 IP 地址哈希生成(如 IP=1.1.1.1→哈希值 = 88);
- 资源 ID:由文件内容哈希生成(如 “计算机网络课件.pdf”→哈希值 = 78)。
②环形覆盖网
- Peer 按 ID 大小首尾相接构成环(如 ID=5→88→199→1011→5);
- 存储规则:约定资源 ID 落在某 Peer ID 范围内则由该 Peer 管理(如 ID 6-88 的资源由 ID=88 的 Peer 管理,ID 89-199 的资源由 ID=199 的 Peer 管理)。
③查询流程
- 用户查询资源 ID=78→按环形拓扑路由到 ID=88 的 Peer;
- ID=88 的 Peer 返回资源所在的 Peer 列表(或直接提供资源);
- 优势:精准路由(非泛洪),查询效率高,副本数量少(无需多节点备份)。
(3)应用与延伸
- 现代 P2P 文件分发:迅雷、BitTorrent 改进版均基于 DHT;
- 细节:DHT 的节点维护、路由优化等内容在 “高级计算机网络” 课程中深入,本章了解基本原理即可。
2.7 CDN
2.7.1背景:视频业务的重要性与核心挑战

-
视频是互联网杀手级应用
-
定义:占网络流量比重大(七八成甚至更高)、最能吸引用户的业务。
-
核心问题:如何向百万级并发用户提供高质量的视频播放服务?
- 传统方案局限:早期服务器仅支持几十 / 几百并发,无法满足大规模需求。
-
-
两大核心挑战
-
规模性挑战:需同时向海量用户提供 “流化服务”(实时播放)。
-
异构客户端挑战:不同设备需求差异大(手机需低解析度,100 寸电视需高解析度(如 1080P)),且设备处理能力、网络带宽不一致。
-
2.7.2视频基础与压缩技术


-
视频的本质
-
视频是图像序列:依赖人眼 “视网膜滞留效应”(图像消失后滞留若干毫秒),帧率常见 24 帧 / 秒(电影)、60 帧 / 秒(游戏)。
-
图像是像素的有序序列(Pixel 序列)。
-
-
视频必须压缩的原因与原理
-
原因:未压缩视频带宽极大(远超网络承载能力),需通过压缩降低码率。
-
压缩基础:利用视频的 “空间冗余” 和 “时间冗余”
-
空间冗余:同一帧内像素颜色相似(如蓝天区域),可描述 “某像素值持续多少个像素”。
-
时间冗余:相邻帧中 “不动的部分多、动的部分少”(如人物说话时,背景不变),仅传输动的部分。
-
-
-
压缩标准与编码技术
-
码率类型
-
CBR(固定码率):压缩后码率固定(如 1M/2Mbps),适合带宽稳定场景。
-
VBR(可变码率):静态场景(如风景)码率低,动态场景(如打斗)码率高,更节省带宽。
-
-
编码标准
-
国际标准:H.264(AVC)、H.265(HEVC)。
-
我国标准:IVS(高级视频编码),由科大吴峰校长助理(原院长)与导师高文院士联合提出,属国际标准。
-
-
(3)可伸缩编码(科大优势):由科大信息学院李卫平千人提出,可根据设备需求提供不同解析度(如手机 320×240、PC 1920×1080、电视 4K),适配异构客户端。
-
2.7.3视频点播的流化服务:Streaming 与 DASH


-
流化服务(Streaming) vs 下载播放(Download and Play)
-
下载播放:全量下载视频文件后再播放,等待时间长(如几 G 文件需几小时),体验差。
-
流化服务:边下载边播放(客户端有缓冲区),大幅减少播放延迟(缓冲 7-8 秒即可开始,会员无广告更快),后续章节会讲 RTP 协议封装流化内容。
-
-
DASH(动态自适应 HTTP 流化):解决异构与网络差异
-
定义:基于 HTTP 的动态自适应流化技术,适配不同客户端和网络状况。
-
核心原理:
- (1)视频预处理:将视频切成8-10 秒的块,每块生成 “低 / 中 / 高解析度”“不同编码” 的多个版本。
- (2)Manifest 文件(告示文件):记录视频关键信息 —— 视频描述、块数量、每块持续时间、各版本块的 URL(存储位置)。
-
客户端流程:
-
先下载 Manifest 文件并解析;
-
根据实时网络带宽(测带宽)、屏幕尺寸(设备需求)、缓冲区剩余量(避免卡顿),动态选择请求的块:
-
带宽大 + 缓冲区满:请求高解析度块(提升体验);
-
带宽小 + 缓冲区快空:请求低解析度块(避免 “努力缓冲中” 卡顿)。
-
-
-
DASH 的局限:若所有客户端都向 “少数源服务器” 请求块,会出现 3 个问题:
- ① 客户端到服务器跳数多(网络质量不可控);
- ② 网络重复流量多(多人下同一视频,浪费资源);
- ③ 源服务器单点故障 / 性能瓶颈(并发过高崩溃)。
-
2.7.4CDN(内容分发网络):解决 DASH 局限,实现内容加速


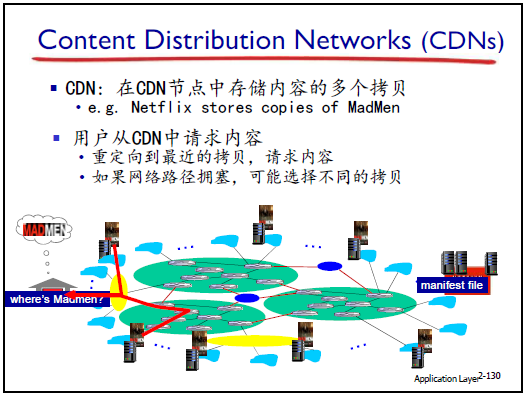
-
CDN 的定义与目标
-
定义:在应用层构建的 “内容分发网络”,通过分布式缓存节点,让用户 “靠近内容” 获取服务。
-
目标:解决源服务器集中的问题(跳数多、重复流量、单点故障 / 拥塞),提升视频播放质量。
-
-
CDN 的核心角色
-
新增角色:CDN 运营商(如美国阿卡米、中国蓝讯),ICP(内容提供商,如 CCTV、百度、网飞)需购买 CDN 服务。
-
原有角色:终端用户、ISP、ICP(源服务器)。
-
-
CDN 工作原理(三步)
- 部署缓存节点:CDN 运营商在全球范围部署缓存节点(存储视频块)。
- 内容预先部署:ICP(如 CCTV)将视频内容通过专线,预先部署到 CDN 的缓存节点。
- 用户访问重定向:用户请求时,通过 “域名解析重定向”,引导至 “离用户最近、服务质量最好” 的缓存节点,由缓存节点提供流化服务(内容加速)。
-
CDN 缓存节点部署策略(两种)
| 策略名称 | 部署位置 | 优势 | 劣势 | 代表案例 |
|---|---|---|---|---|
| In-to-Deep(深入群众) | local ISP 内部(靠近用户) | 跳数少、带宽大、服务质量高 | 节点数量多(数千个)、维护成本高 | 阿卡米 |
| Bring Home(关键少数) | 高层 ISP / 数据中心关键节点 | 节点数量少、维护成本低 | 到用户跳数稍多 | 中小型 CDN 运营商 |
- CDN 的实际应用实例
实例 1:CCTV 春晚(高并发场景)
-
问题:春晚点播量惊人,若全从 CCTV 源服务器请求,源服务器并发扛不住,且用户到源服务器跳数多(卡顿)。
-
解决方案:CCTV 购买 “中国蓝讯” CDN 服务,将春晚视频通过专线部署到蓝讯全国缓存节点,用户由缓存节点服务 —— 跳数少、无卡顿,体验好。
实例 2:网飞(Netflix)
- 网飞模式:

- 轻资产运营:认证服务器自维护(保障账号安全),视频制作、网页服务租用亚马逊云(降低成本);
- 内容分发:制作完的视频发布到 CDN 运营商(Level 3、阿卡米)的缓存节点;
- 用户流程:账号认证→浏览云网页→点视频链接→域名解析重定向到近的缓存节点→缓存节点提供 DASH 服务。
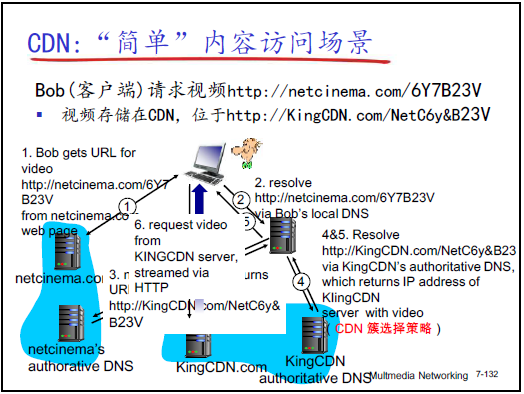
2.7.5CDN 的关键技术:域名解析重定向
-
核心逻辑:通过域名解析,透明引导用户到近的缓存节点,用户无感知(不知道是源服务器还是缓存节点服务)。
-
详细流程(以 “用户 Bob 访问 Net Cinema 视频” 为例):
- Bob 点视频链接(含域名),浏览器向 “local DNS” 请求解析该域名;
- local DNS 找到 “Net Cinema(ICP)的权威 DNS”,询问 IP;
- ICP 权威 DNS 不返回 IP,而是重定向:“请解析 CDN 运营商(King CDN)的域名”;
- local DNS 向 “King CDN 的权威 DNS” 请求解析;
- CDN 权威 DNS 根据 “Bob 的位置”“节点负载”,返回 “离 Bob 最近的缓存节点 IP”;
- Bob 向该缓存节点请求 DASH 服务(下 Manifest→选块→播放)。
- 透明性:web 端、客户端无需任何修改,仅需在 ICP 权威 DNS(配置重定向)、CDN 权威 DNS(维护节点 IP 与距离)做配置。
2.7.6CDN 的特点与挑战
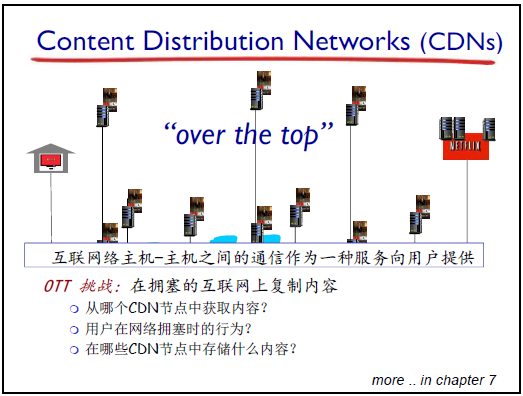
-
CDN 的 OTT 特点(Over the Top)
- 含义:在应用层、网络边缘(缓存节点是主机)提供服务,不依赖网络核心设备,靠主机间配合实现加速(互联网 “Everything over IP” 架构的体现)。
-
CDN 的三大挑战(研究生高级网络内容)
-
挑战 1:缓存节点选择 —— 多节点有同一内容时,选哪个节点(需测距离、带宽);
-
挑战 2:节点切换 —— 当前缓存节点网络堵塞时,如何切换到其他节点;
-
挑战 3:内容部署策略 ——ICP 的内容部署到哪些节点(需权衡成本:一次性投入、维护成本;地理位置:避免沙漠等交通不便处),需用数学、优化、运筹知识解决。
-
2.8 TCP 套接字编程
2.8.1TCP 套接字核心概念(对应课件图 3-137)
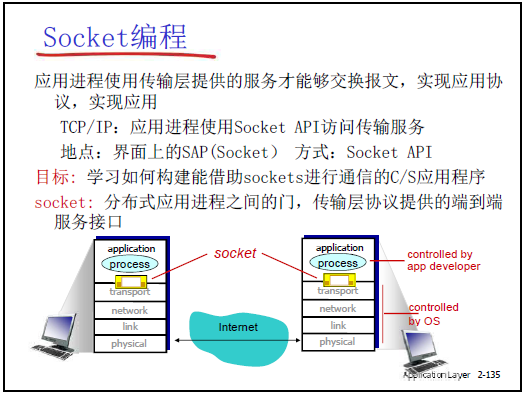

(1)套接字的本质与作用
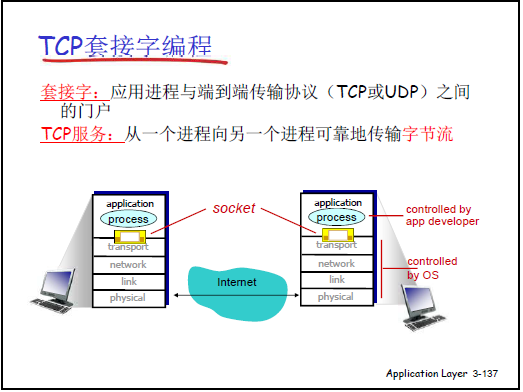
- 门户定位:套接字(Socket)是应用进程与传输层(TCP)之间的 “门户”—— 应用进程通过套接字发送 / 接收报文,无需关注传输层以下(IP、链路层等)的具体传输细节,仅需调用 Socket API 即可完成逻辑通信。
- 类比理解:类似操作系统打开文件返回的 “文件句柄”,对套接字的读写操作,本质是对 “应用进程间 TCP 连接” 的操作。
- TCP 服务特性:TCP 提供可靠的字节流服务(数据不丢失、不重复、不失序),但不保证报文界限(应用层需自行维护报文分隔,如 HTTP 的 CRLF.CRLF 标识报文结束),且是面向连接的服务(通信前需建立连接)。
(2)TCP 套接字的标识
- 4 元组定义:TCP 套接字是 “(源 IP、源 TCP 端口、目标 IP、目标 TCP 端口)”4 元组的本地意义整数标识,唯一指定两个应用进程之间的 “会话关系”。
- 例:客户端(IP:2.2.2.2,端口:777)与服务器(IP:1.1.1.1,端口:80)通信时,服务器的 TCP 套接字整数代表 “1.1.1.1:80 ↔ 2.2.2.2:777” 的连接,客户端的套接字代表反向关系。
- 优势:应用进程无需在每次发送报文时重复指定 4 元组,仅通过该整数标识即可完成通信,简化编程与管理。
2.8.2C/S 模式下 TCP 套接字交互流程(对应课件图 3-138、3-140)
TCP 套接字编程基于 “客户 - 服务器(C/S)模式”,服务器必须先启动(否则客户端无连接对象),流程分为 “服务器端步骤” 和 “客户端步骤”,核心是 “欢迎套接字” 与 “连接套接字” 的分工。
(1)服务器端流程(核心:欢迎套接字 + 连接套接字)
| 步骤 | 操作(Socket API) | 作用与细节 | 对应课件图 |
|---|---|---|---|
| 1 | 创建欢迎套接字 | welcomeSocket = socket(PF_INET, SOCK_STREAM, 0)- 参数SOCK_STREAM指定为 TCP 套接字- 操作系统返回一个整数作为套接字标识(初始无实际意义) |
3-138、3-140 |
| 2 | 绑定本地 IP 与端口 | bind(welcomeSocket, &sad, sizeof(sad))- sad是sockaddr_in结构体(存储本地 IP 和端口)- 端口需用htons()转换为网络字节序(解决大端 / 小端差异)- 服务器端口需固定(如 HTTP 的 80 端口),确保客户端可找到 |
3-138、3-141 |
| 3 | 监听连接请求 | listen(welcomeSocket, 10)- 第二个参数 “10” 是等待队列长度(最多缓存 10 个未处理的连接请求)- 此时欢迎套接字进入 “监听状态”,准备接收客户端连接 |
3-140、3-146 |
| 4 | 接受连接(阻塞) | connectionSocket = accept(welcomeSocket, &cad, &alen)- 阻塞等待:若无客户端连接,函数不返回,程序停滞- 接收到连接后,返回新的连接套接字(connectionSocket)- cad是sockaddr_in结构体,存储客户端的 IP 和端口- 关键区别:- 欢迎套接字(welcomeSocket):仅用于接受连接,长期存在- 连接套接字(connectionSocket):仅用于与当前客户端通信,通信结束后关闭 |
3-138、3-140 |
| 5 | 读写数据 | read(connectionSocket, clientSentence, ...)``write(connectionSocket, capitalizedSentence, ...)- 通过连接套接字读取客户端发送的报文(如小写字符串)- 处理数据(如转为大写)后,通过同一套接字发送回客户端 |
3-140、3-146 |
| 6 | 关闭连接 | close(connectionSocket)- 关闭当前客户端的连接套接字- 欢迎套接字仍保持监听,等待下一个客户端连接 |
3-140 |








(2)客户端流程(核心:隐式绑定 + 主动连接)
| 步骤 | 操作(Socket API) | 作用与细节 | 对应课件图 |
|---|---|---|---|
| 1 | 创建客户端套接字 | clientSocket = socket(PF_INET, SOCK_STREAM, 0)- 与服务器端socket函数参数一致,指定 TCP 类型- 操作系统返回整数标识,初始无绑定信息 |
3-140、3-143 |
| 2 | 隐式绑定本地 IP 与端口 | 无需调用bind函数!- 操作系统自动分配空闲的本地端口(如 777)和本地 IP- 客户端端口无需固定,服务器仅需知道自身端口即可 |
3-138、3-143 |
| 3 | 发起连接(阻塞) | connect(clientSocket, &sad, sizeof(sad))- sad是sockaddr_in结构体,存储服务器的 IP 和端口- 阻塞等待:直到 TCP 三次握手完成(服务器返回确认),函数才返回- 若连接失败(如服务器未启动),返回错误值 |
3-138、3-143 |
| 4 | 读写数据 | write(clientSocket, Sentence, ...)``read(clientSocket, modifiedSentence, ...)- 向服务器发送数据(如用户输入的小写字符串)- 读取服务器返回的处理结果(如大写字符串) |
3-140、3-144 |
| 5 | 关闭套接字 | close(clientSocket)- 通信结束后,关闭客户端套接字,释放资源 |
3-140、3-144 |
2.8.3关键数据结构
TCP 套接字编程需借助两个核心结构体,用于存储 “IP + 端口” 和 “域名解析结果”,是 Socket API 的重要参数。
(1)sockaddr_in:存储 IP 与端口(端节点标识)
-
结构定义:
struct sockaddr_in {short sin_family; // 地址族:AF_INET(TCP/IP协议族)u_short sin_port; // 端口号(需用htons()转为网络字节序)struct in_addr sin_addr; // 32位IP地址(如1.1.1.1)char sin_zero[8]; // 填充字段,用于内存对齐(无实际意义) }; -
作用:
- 服务器端:
sad变量存储 “本地 IP + 固定端口”(如 1.1.1.1:80),用于bind绑定。 - 客户端:
sad变量存储 “服务器 IP + 服务器端口”(如 1.1.1.1:80),用于connect发起连接。 - 服务器端
accept时:cad变量存储 “客户端 IP + 客户端端口”(如 2.2.2.2:777),用于识别客户端。
- 服务器端:
(2)hostent:存储域名解析结果
-
结构定义:
struct hostent {char *h_name; // 主机正式域名(如"www.ustc.edu.cn")char **h_aliases; // 主机别名列表(如"ustc.cn")int h_addrtype; // 地址类型:AF_INET(IPv4)int h_length; // 地址长度:4字节(IPv4)char **h_addr_list; // IP地址列表(字符串形式,如"1.1.1.1") #define h_addr h_addr_list[0] // 简化:取第一个IP地址 }; -
作用与使用:
-
客户端需通过 “服务器域名”(如 "www.someschool.edu")获取服务器 IP,需调用
gethostbyname函数:ptrh = gethostbyname(host); // host是客户端输入的服务器域名 memcpy(&sad.sin_addr, ptrh->h_addr, ptrh->h_length); // 将解析出的IP赋值给sad.sin_addr -
若域名解析成功,
ptrh->h_addr存储服务器的 IPv4 地址;若失败,返回NULL。
-
2.8.4TCP 套接字编程实例(C 语言)
以 “客户端发送小写字符串→服务器转为大写→客户端打印结果” 为例,展示核心代码与注释。
(1)客户端代码
/* client.c:TCP客户端,需输入两个参数:服务器域名、服务器端口 */
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <string.h>void main(int argc, char *argv[])
{struct sockaddr_in sad; // 存储服务器的IP和端口int clientSocket; // 客户端套接字(整数标识)struct hostent *ptrh; // 域名解析结果指针char Sentence[128]; // 存储用户输入的小写字符串char modifiedSentence[128];// 存储服务器返回的大写字符串char *host; // 服务器域名int port; // 服务器端口// 1. 解析命令行参数(必须输入“服务器域名”和“端口”)host = argv[1]; // argv[1]:服务器域名(如"www.someschool.edu")port = atoi(argv[2]); // argv[2]:服务器端口(如80),转为整数// 2. 创建TCP客户端套接字clientSocket = socket(PF_INET, SOCK_STREAM, 0); // SOCK_STREAM=TCPif (clientSocket < 0) { perror("socket error"); return; }// 3. 初始化sockaddr_in结构体(服务器地址信息)memset((char *)&sad, 0, sizeof(sad)); // 清空结构体,避免垃圾数据sad.sin_family = AF_INET; // 协议族:TCP/IPsad.sin_port = htons((u_short)port); // 端口转为网络字节序(大端)// 4. 域名解析:将服务器域名转为IP地址ptrh = gethostbyname(host);if (ptrh == NULL) { perror("gethostbyname error"); return; }memcpy(&sad.sin_addr, ptrh->h_addr, ptrh->h_length); // 复制IP到sad// 5. 向服务器发起连接(阻塞至连接建立)if (connect(clientSocket, (struct sockaddr *)&sad, sizeof(sad)) < 0) {perror("connect error"); return;}// 6. 读取用户输入(标准输入:键盘)printf("Enter a lowercase sentence: ");gets(Sentence); // 读取用户输入的小写字符串// 7. 发送字符串到服务器write(clientSocket, Sentence, strlen(Sentence) + 1); // +1:包含字符串结束符'\0'// 8. 读取服务器返回的大写字符串read(clientSocket, modifiedSentence, sizeof(modifiedSentence));// 9. 打印结果并关闭套接字printf("FROM SERVER: %s\n", modifiedSentence);close(clientSocket);
}
(2)服务器端代码
/* server.c:TCP服务器,需输入一个参数:本地守候端口 */
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#include <ctype.h> // 用于toupper()函数(小写转大写)void main(int argc, char *argv[])
{struct sockaddr_in sad; // 存储服务器的IP和端口struct sockaddr_in cad; // 存储客户端的IP和端口int welcomeSocket; // 欢迎套接字(接受连接)int connectionSocket; // 连接套接字(与客户端通信)char clientSentence[128]; // 存储客户端发送的小写字符串char capitalizedSentence[128]; // 存储转换后的大写字符串int port; // 服务器本地守候端口socklen_t alen; // 客户端地址结构体长度// 1. 解析命令行参数(必须输入“本地端口”)port = atoi(argv[1]); // argv[1]:本地端口(如80)// 2. 创建TCP欢迎套接字welcomeSocket = socket(PF_INET, SOCK_STREAM, 0);if (welcomeSocket < 0) { perror("socket error"); return; }// 3. 初始化sockaddr_in结构体(服务器地址信息)memset((char *)&sad, 0, sizeof(sad));sad.sin_family = AF_INET; // 协议族:TCP/IPsad.sin_addr.s_addr = INADDR_ANY; // 本地IP:绑定所有可用网卡(如1.1.1.1、192.168.1.1)sad.sin_port = htons((u_short)port); // 端口转为网络字节序// 4. 绑定欢迎套接字与本地IP+端口if (bind(welcomeSocket, (struct sockaddr *)&sad, sizeof(sad)) < 0) {perror("bind error"); return;}// 5. 监听连接请求(等待队列长度10)listen(welcomeSocket, 10);alen = sizeof(cad); // 初始化客户端地址结构体长度// 6. 循环接受客户端连接(长期运行)while (1) {// 6.1 接受连接(阻塞,直到有客户端连接)connectionSocket = accept(welcomeSocket, (struct sockaddr *)&cad, &alen);if (connectionSocket < 0) { perror("accept error"); continue; }// 6.2 读取客户端发送的小写字符串read(connectionSocket, clientSentence, sizeof(clientSentence));// 6.3 小写转大写(核心业务逻辑)for (int i = 0; i < strlen(clientSentence); i++) {capitalizedSentence[i] = toupper(clientSentence[i]);}capitalizedSentence[strlen(clientSentence)] = '\0'; // 字符串结束符// 6.4 发送大写字符串给客户端write(connectionSocket, capitalizedSentence, strlen(capitalizedSentence) + 1);// 6.5 关闭当前客户端的连接套接字close(connectionSocket);}
}
2.8.5扩展:多进程处理多个客户端
(1)问题背景
上述服务器代码是 “单进程” 的:一次只能处理一个客户端(处理当前客户端时,accept阻塞,无法接受新连接)。若需同时服务多个客户端,需用多进程。
(2)实现逻辑(对应课件无图,老师讲解补充)
- 服务器
accept获取connectionSocket后,调用fork()创建子进程。 - 子进程:负责与当前客户端通信(
read/write/close(connectionSocket))。 - 父进程:立即回到
accept,继续阻塞等待新客户端连接(不处理通信)。
(3)核心代码片段
while (1)
{connectionSocket = accept(welcomeSocket, &cad, &alen); // 接受连接if (fork() == 0) // 子进程(fork返回0){ read(connectionSocket, clientSentence, ...); // 子进程处理通信write(connectionSocket, capitalizedSentence, ...);close(connectionSocket);exit(0); // 子进程通信结束,退出} else // 父进程(fork返回子进程ID){ close(connectionSocket); // 父进程无需该套接字,关闭// 父进程直接回到accept,等待新连接}
}
- 关键:父进程需关闭
connectionSocket(避免资源泄漏),子进程通信结束后退出。 - 优势:多个子进程可同时服务多个客户端,父进程仅负责 “接受连接”,提高并发能力。
2.8.6关键注意事项
- 网络字节序转换:端口号必须用
htons()转换(主机字节序→网络字节序),否则不同架构(大端 / 小端)的设备会解析错误(如客户端发送端口 777,服务器可能解析为 30592)。 - 阻塞函数:
accept()、connect()、read()均为阻塞函数 —— 无数据 / 连接时,程序停滞,需等待事件发生(如客户端连接、数据到达)。 - 套接字区分:欢迎套接字(
welcomeSocket)仅用于接受连接,不可用于通信;连接套接字(connectionSocket)仅用于单个客户端通信,通信结束必须关闭。 - 客户端隐式绑定:客户端无需
bind,操作系统自动分配空闲端口,避免端口冲突(服务器必须bind固定端口,否则客户端无法找到)。 - 域名解析失败:若
gethostbyname()返回NULL(如域名错误、网络不通),客户端需处理错误,不可继续connect。
2.9 UDP 套接字编程
2.9.1UDP 套接字核心特性

(1)与 TCP 套接字的核心区别
- 无连接 / 无握手:UDP 套接字在通信前无需建立连接(无 TCP 的三次握手),客户端创建套接字后可直接发送数据,服务器无需等待 “连接请求”。
- 绑定范围不同:UDP 套接字仅与本地端节点(2 元组:本地 IP + 本地 UDP 端口) 绑定,不与对方的 IP / 端口绑定(TCP 套接字是 4 元组:源 IP + 源端口 + 目标 IP + 目标端口)。老师强调:“UDP socket 只是本地 IP 和端口的代表,发送时必须额外指明对方的 IP 和 UDP 端口,否则不知道发给谁”。
- 无连接状态维护:UDP 套接字无 “连接状态”,每次发送数据都需明确指定目标端节点,接收数据时需通过引用参数获取发送方的端节点(以便回复)。
(2)UDP 套接字的标识
UDP 套接字在操作系统中以 “本地端节点” 为唯一标识,表格结构如下:
| SOCKET(套接字描述符) | IP(本地 IP 地址) | Port(本地 UDP 端口号) |
|---|---|---|
| 整数型标识(如 8888) | 如 1.1.1.1 | 如 80(UDP 端口,与 TCP 端口分属不同空间) |
注:老师特别说明 “UDP 端口和 TCP 端口是两个独立空间,比如 UDP 的 80 端口和 TCP 的 80 端口无关联,可同时被不同进程使用”。
2.9.2UDP 服务的本质
(1)UDP 向应用层提供的服务特性
- 不可靠传输:数据可能丢失、乱序(无 TCP 的重传、排序机制),老师举例:“IP 数据报和 UDP 数据报都叫‘数据报(datagram)’,需结合上下文区分,但二者均为无连接、不可靠,UDP 的数据报是应用层与传输层间的 PDU”。
- 无流量 / 拥塞控制:应用进程发送数据的速率由自身决定,UDP 不限制发送速率(与 TCP 的流量控制、拥塞控制不同)。
- 数据报交付:UDP 以 “数据报” 为单位传输,每个数据报独立处理,应用层发送的每个报文会封装成一个 UDP 数据报(不会拆分或合并,除非超过 MTU)。
2.9.3UDP 客户端 - 服务器(C/S)交互流程
UDP C/S 通信无连接建立过程,流程如下(以 “客户端发送小写字符串,服务器返回大写字符串” 为例,老师逐步骤讲解):
(1)服务器端流程(对应课件 Server 交互步骤)
| 步骤 | 操作(对应课件代码逻辑) | 老师补充说明 |
|---|---|---|
| 1 | 创建 UDP 套接字:serverSocket = socket(PF_INET, SOCK_DGRAM, 0) |
指定 SOCK_DGRAM 标识为 UDP 套接字,返回整数型套接字描述符 |
| 2 | 绑定本地端节点:bind(serverSocket, (struct sockaddr *)&sad, sizeof(sad)) |
sad 是 sockaddr_in 结构,存储本地 IP(如 INADDR_ANY,代表本机所有 IP)和 UDP 端口(如 80);UDP 服务器必须显式 bind,否则无法被客户端找到 |
| 3 | 循环接收客户端数据:recvfrom(serverSocket, clientSentence, sizeof(clientSentence), 0, (struct sockaddr *)&cad, &addr_len) |
- clientSentence 存储接收的字符串;- cad 是引用参数,通过它获取客户端的 sockaddr_in(IP + 端口),用于后续回复;- 若无数据,recvfrom 会阻塞,直到收到数据 |
| 4 | 处理数据:将 clientSentence 转换为大写(如 capitalizedSentence) |
此为应用层逻辑,与 UDP 协议无关,老师强调 “协议仅规范交互格式,内部数据处理由应用决定” |
| 5 | 回复客户端:sendto(serverSocket, capitalizedSentence, strlen(capitalizedSentence)+1, (struct sockaddr *)&cad, &addr_len) |
必须指定客户端的 cad(从 recvfrom 获取),否则无法定位客户端 |
| 6 | 持续循环:服务器无需关闭套接字,始终在 recvfrom 阻塞等待新请求 |
UDP 服务器无 welcome socket 与 connection socket 之分,仅一个 serverSocket 处理所有客户端请求(与 TCP 服务器不同) |
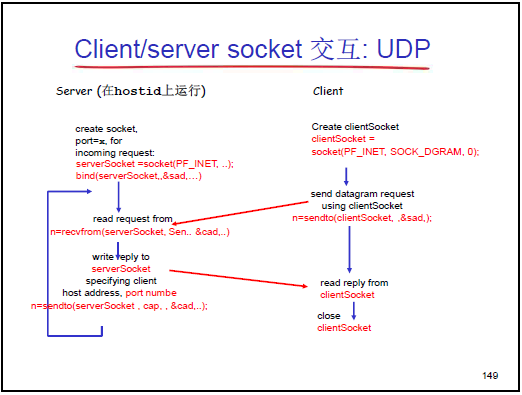



(2)客户端流程(对应课件 Client 交互步骤)
| 步骤 | 操作(对应课件代码逻辑) | 老师补充说明 |
|---|---|---|
| 1 | 创建 UDP 套接字:clientSocket = socket(PF_INET, SOCK_DGRAM, 0) |
与服务器端创建方式一致,返回客户端套接字描述符 |
| 2 | (可选)绑定本地端节点:bind(clientSocket, (struct sockaddr *)&sad, sizeof(sad)) |
客户端可隐式绑定(操作系统自动分配 IP 和端口),老师建议 “若需固定客户端端口则显式 bind,否则无需手动操作” |
| 3 | 初始化服务器端地址:sockaddr_in sad 赋值(sin_family=AF_INET、sin_port=htons(服务器端口)、sin_addr=服务器IP) |
服务器 IP 通过域名解析获取(gethostbyname(主机名) 得到 hostent 结构,再拷贝 IP 到 sin_addr) |
| 4 | 发送数据给服务器:sendto(clientSocket, Sentence, strlen(Sentence)+1, (struct sockaddr *)&sad, sizeof(sad)) |
必须指定服务器的 sad(目标端节点),否则 UDP 不知道发送目标 |
| 5 | 接收服务器回复:recvfrom(clientSocket, modifiedSentence, sizeof(modifiedSentence), 0, (struct sockaddr *)&sad, &addr_len) |
接收服务器返回的大写字符串,sad 可复用(此时存储服务器地址) |
| 6 | 关闭套接字:close(clientSocket) |
客户端通信结束后关闭套接字,释放资源 |
2.9.4UDP 编程关键数据结构(对应课件 sockaddr_in 与 hostent 结构)
(1)sockaddr_in 结构(对应课件 141 页,用于存储端节点信息
struct sockaddr_in {short sin_family; // 地址族:必须为 AF_INET(Internet 协议族)u_short sin_port; // UDP端口号:需转换为网络字节序(htons() 函数)struct in_addr sin_addr; // IP地址:存储32位IP地址(如INADDR_ANY代表本机所有IP)char sin_zero[8]; // 填充字段:用于与 sockaddr 结构对齐,需初始化为0
};
老师讲解:“sin_port 必须用 htons() 转换为网络字节序(大端序),避免主机字节序(小端序)与网络字节序不一致导致的端口错误;sin_addr 可通过 gethostbyname() 从域名获取 IP 地址”。
(2)hostent 结构(对应课件 142 页,用于域名解析)
struct hostent {char *h_name; // 主机正式名称char **h_aliases; // 主机别名列表int h_addrtype; // 地址类型:AF_INET(IPv4)int h_length; // 地址长度:IPv4为4字节char **h_addr_list; // IP地址列表(网络字节序)
#define h_addr h_addr_list[0] // 宏定义:指向第一个IP地址(常用)
};
老师说明:“调用 struct hostent *ptrh = gethostbyname(主机名) 可通过域名(如 "www.ustc.edu.cn")获取 hostent 结构,再用 memcpy(&sad.sin_addr, ptrh->h_addr, ptrh->h_length) 将 IP 地址拷贝到 sockaddr_in 的 sin_addr 字段,实现域名到 IP 的转换”。
2.9.5UDP 编程代码示例解析(对应课件 C 客户端与服务器代码)
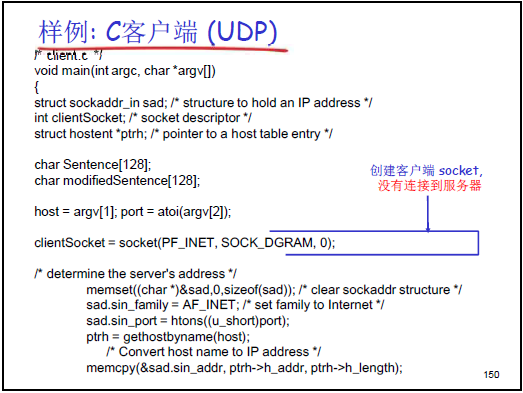
(1)C 客户端代码(对应课件 150-151 页)
void main(int argc, char *argv[]) {struct sockaddr_in sad; // 存储服务器端节点信息int clientSocket; // 客户端UDP套接字描述符struct hostent *ptrh; // 域名解析结果指针char Sentence[128]; // 存储用户输入的字符串char modifiedSentence[128];// 存储服务器返回的大写字符串int port; // 服务器UDP端口号char *host; // 服务器主机名(从参数获取)// 1. 从命令行参数获取服务器主机名和端口号host = argv[1];port = atoi(argv[2]);// 2. 创建UDP套接字clientSocket = socket(PF_INET, SOCK_DGRAM, 0);if (clientSocket < 0) { /* 错误处理(省略) */ }// 3. 初始化服务器端 sockaddr_in 结构memset((char *)&sad, 0, sizeof(sad)); // 清空结构sad.sin_family = AF_INET; // Internet 协议族sad.sin_port = htons((u_short)port); // 端口号转换为网络字节序// 4. 域名解析:将主机名转换为IP地址ptrh = gethostbyname(host);if (ptrh == NULL) { /* 错误处理(省略) */ }memcpy(&sad.sin_addr, ptrh->h_addr, ptrh->h_length); // 拷贝IP地址// 5. 从标准输入获取用户输入gets(Sentence);// 6. 发送数据到服务器int addr_len = sizeof(struct sockaddr);sendto(clientSocket, Sentence, strlen(Sentence)+1, (struct sockaddr *)&sad, addr_len);// 7. 接收服务器回复recvfrom(clientSocket, modifiedSentence, sizeof(modifiedSentence), 0, (struct sockaddr *)&sad, &addr_len);// 8. 打印结果并关闭套接字printf("FROM SERVER: %s\n", modifiedSentence);close(clientSocket);
}
老师讲解重点:
- 命令行参数
argv[1]是服务器主机名(如 "1.1.1.1"),argv[2]是服务器 UDP 端口(如 80); sendto的第 5 个参数是服务器的sockaddr_in指针,必须明确指定;recvfrom的第 6 个参数是引用参数,用于获取服务器的地址(此处可忽略,但需传入)。
(2) C 服务器代码(对应课件 152-153 页)
void main(int argc, char *argv[]) {struct sockaddr_in sad; // 存储服务器端节点信息struct sockaddr_in cad; // 存储客户端端节点信息(用于回复)int serverSocket; // 服务器UDP套接字描述符char clientSentence[128]; // 存储客户端发送的字符串char capitalizedSentence[128]; // 存储转换后的大写字符串int port; // 服务器UDP端口号(从参数获取)int addr_len = sizeof(struct sockaddr); // 端节点结构长度// 1. 从命令行参数获取服务器端口号port = atoi(argv[1]);// 2. 创建UDP套接字serverSocket = socket(PF_INET, SOCK_DGRAM, 0);if (serverSocket < 0) { /* 错误处理(省略) */ }// 3. 初始化服务器端 sockaddr_in 结构memset((char *)&sad, 0, sizeof(sad)); // 清空结构sad.sin_family = AF_INET; // Internet 协议族sad.sin_addr.s_addr = INADDR_ANY; // 绑定本机所有IP地址sad.sin_port = htons((u_short)port); // 端口号转换为网络字节序// 4. 绑定套接字与本地端节点if (bind(serverSocket, (struct sockaddr *)&sad, sizeof(sad)) < 0) {/* 错误处理(省略) */}// 5. 循环处理客户端请求while (1) {// 5.1 接收客户端数据(获取客户端地址 cad)recvfrom(serverSocket, clientSentence, sizeof(clientSentence), 0, (struct sockaddr *)&cad, &addr_len);// 5.2 处理数据:小写转大写(应用层逻辑)int i;for (i = 0; i < strlen(clientSentence); i++) {capitalizedSentence[i] = toupper(clientSentence[i]);}capitalizedSentence[i] = '\0'; // 字符串结束符// 5.3 回复客户端(使用 cad 定位客户端)sendto(serverSocket, capitalizedSentence, strlen(capitalizedSentence)+1, (struct sockaddr *)&cad, addr_len);}// 服务器通常不关闭套接字(循环永不退出)// close(serverSocket);
}
重点:
sad.sin_addr.s_addr = INADDR_ANY表示绑定本机所有 IP 地址,客户端可通过任意一个本机 IP 访问服务器;- 循环
while(1)使服务器持续运行,永不退出(除非手动终止); recvfrom的第 6 个参数&cad是关键:通过它获取客户端的地址,后续sendto才能精准回复该客户端;- 服务器无需区分不同客户端:所有客户端的请求都通过同一个
serverSocket处理,通过cad区分不同客户端。


参考资料来源:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程