FAISS 在实验阶段确实好用,速度快、上手容易,notebook 里跑起来很顺手。但把它搬到生产环境还是有很多问题:
首先是元数据的问题,FAISS 索引只认向量,如果想按日期或其他条件筛选还需要自己另外搞一套查找系统。
其次它本质上是个库而不是服务,让如果想对外提供接口还得自己用 Flask 或 FastAPI 包一层。
最后最麻烦的是持久化,pod 一旦挂掉索引就没了,除非提前手动存盘。
Qdrant 的出现解决了这些痛点,它更像是个真正的数据库,提供开箱即用的 API、数据重启后依然在、原生支持元数据过滤。更关键的是混合搜索(Dense + Sparse)和量化这些高级功能都是内置的。
MS MARCO Passages 数据集
数据集地址:
MS MARCO 官方页面:https://microsoft.github.io/msmarco/
这次用的是 MS MARCO Passage Ranking 数据集,信息检索领域的标准测试集。
数据是从网页抓取的约880万条短文本段落,选它的原因很简单:段落短(平均50词),不用处理复杂的文本分块,可以把精力放在迁移工程本身。
实际测试时用了10万条数据的子集,这样速度会很快
嵌入模型用的是 sentence-transformers/all-MiniLM-L6-v2,输出384维的稠密向量。
SentenceTransformers 模型地址:https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
FAISS 阶段的初始配置
生成嵌入向量
加载原始数据,批量生成嵌入向量。这里关键的一步是把结果存成 .npy 文件,避免后续重复计算。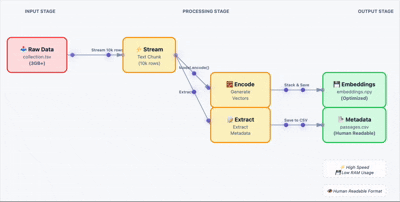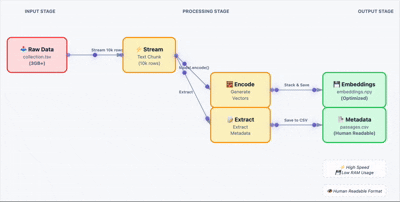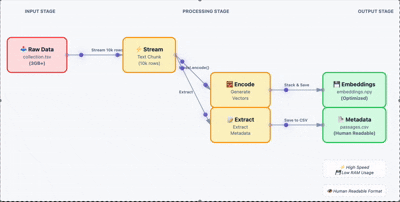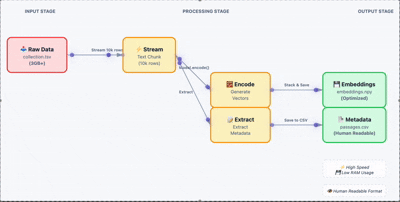
https://avoid.overfit.cn/post/ce7c45d8373741f6b8af465bb06bc398