过去这些年语言模型的效率优化基本围绕着两条主线展开:参数规模和注意力机制的复杂度。但有个更根本的问题一直被忽视,那就是自回归生成本身的代价。这种逐token生成的模式让模型具备了强大的通用性,同时也带来了难以回避的计算开销。
现在有一种思路值得关注:不去替换现有的优化手段,而是在上层加一个潜在空间的映射层,直接削减前向传播的次数。
每次让GPT-5写封邮件模型都得一个token一个token地往外蹦字。每个token意味着一次完整的前向计算,要把数十亿参数全过一遍。生成1000个token的回复那就是1000次前向传播,整个神经网络要走1000遍,计算资源和延迟就这样一点点累积起来。自回归架构就是这么设计的现在这个机制正变成AI系统效率的最大瓶颈。
找到比token更高层次的表示形式,对降低延迟、提升吞吐量都有直接作用。换句话说,用更少的资源干同样的活儿。
token本身已经是词汇表规模和表达能力之间比较精妙的平衡了,想在这个基础上再优化并不简单。
词汇表示的粒度选择
主流语言模型的词汇表通常在3万到25万个token之间。每个token对应一个学习出来的嵌入向量,存在查找表里,和transformer的层一起训练。模型就是靠拼接这些子词片段来还原文本。
看看其他方案就知道为什么这个设计能胜出了。
如果往上走用完整的词或短语来表示,词汇表会膨胀到无法控制。 词级分词得为每种语言的每个词形都建条目,短语级更不用说,光是两个词的组合就能把查找表撑爆。
往下走又会碰到另一个极端,字符级模型处理英文ASCII只要95个条目左右,内存占用看起来很好。 但问题是要把所有语言知识塞进这么小的嵌入空间(这事儿本身就够呛),更要命的是生成变成了逐字符进行。本来就贵的自回归循环直接翻4到5倍。
子词token正好卡在中间这个位置。语义信息足够丰富,词汇表又不会大到装不下。transformer普及这么多年,分词方式基本没变过,原因就在这儿。
得换个角度,不是去替换token,而是在token之上再搭一层。
Continuous Autoregressive Language Models(CALM)做的就是这个思路。整个框架包含好几个模块,这篇文章先聚焦基础部分:把token序列压缩成密集向量的自编码器。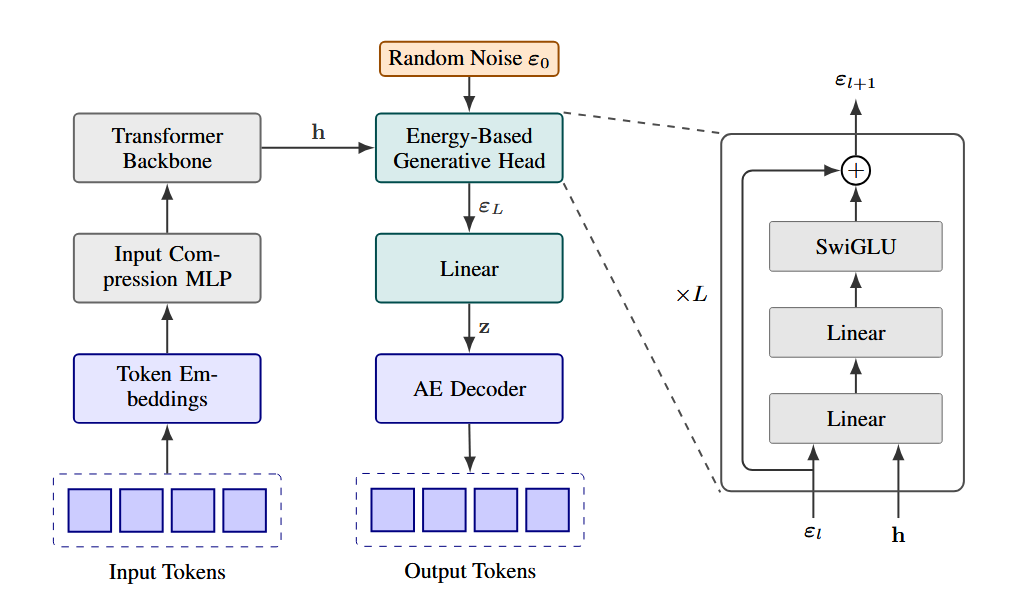
自编码器的作用
在讲CALM架构之前,得先理解自编码器为什么重要,最直观的例子是图像生成。
https://avoid.overfit.cn/post/0c9c3766205f44e5bc74fcf9328468ec