- 1 Ollama
- 1.1 简介
- 1.2 下载安装
- 1.3 基本概念
- 1.3.1 模型(Model)
- 1.3.2 任务(Task)
- 1.3.3 推理(Inference)
- 1.3.4 微调(Fine-tuning)
- 1.4 Ollama命令
- 1.5 模型操作
- 1.5.1 运行模型
- 1.5.2 模型交互
- 1.6 与浏览器交互
- 1.6.1 Open WebUI
- 1.6.1.1 简介
- 1.6.1.2 安装
- 1.6.2 Page Assist
- 1.6.2.1 简介
- 1.6.2.2 安装与使用
- 1.6.1 Open WebUI
- 1.7 与Python交互
- 1.7.1 安装SDK
- 1.7.2 使用SDK交互
- 1.7.2.1 简单使用
- 1.7.2.2 常用 API 方法
- 1.7.3 使用Http方式交互
- 1.7.3.1 使用Ollama http
- 1.7.3.2 使用其他http请求
1 Ollama
1.1 简介
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计,支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
Ollama 的特点在于它不仅仅提供了现成的模型和工具集,还提供了方便的界面和 API,使得从文本生成、对话系统到语义分析等任务都能快速实现。
与其他 NLP 框架不同,Ollama 旨在简化用户的工作流程,Ollama 支持多种硬件加速选项,包括纯 CPU 推理和各类底层计算架构(如 Apple Silicon),能够更好地利用不同类型的硬件资源。
核心功能与特点:
- 多种预训练语言模型支持:
Ollama提供了多种开箱即用的预训练模型,包括常见的 GPT、BERT 等大型语言模型。 - 易于集成和使用:
Ollama提供了命令行工具(CLI)和Python SDK,简化了与其他项目和服务的集成。无需担心复杂的依赖或配置,可以快速将 Ollama 集成到现有的应用中。 - 本地部署与离线使用:不同于一些基于云的 NLP 服务,
Ollama允许开发者在本地计算环境中运行模型。 - 支持模型微调与自定义:用户不仅可以使用
Ollama提供的预训练模型,还可以在此基础上进行模型微调。
1.2 下载安装
Ollama 官方下载地址:https://ollama.com/download
下载后,打开命令提示符或 PowerShell,输入以下命令验证安装是否成功:ollama --version
更改安装路径(可选)
如果需要将 Ollama 安装到非默认路径,可以在安装时通过命令行指定路径,例如:
OllamaSetup.exe /DIR="d:\some\location"
这样可以将 Ollama 安装到指定的目录
或者使用 scoop 安装也可以 (点击此处了解scoop用法)
1.3 基本概念
1.3.1 模型(Model)
在 Ollama 中,模型是核心组成部分。它们是经过预训练的机器学习模型,能够执行不同的任务,例如文本生成、文本摘要、情感分析、对话生成等。
Ollama 支持多种流行的预训练模型,常见的模型有:
deepseek-v3:深度求索提供的大型语言模型,专门用于文本生成任务。LLama2:Meta 提供的大型语言模型,专门用于文本生成任务。GPT:OpenAI的 GPT 系列模型,适用于广泛的对话生成、文本推理等任务。BERT:用于句子理解和问答系统的预训练模型。其他自定义模型:用户可以上传自己的自定义模型,并利用 Ollama 进行推理。
Ollama 支持的模型可以访问:https://ollama.com/library
模型的主要功能:
- 推理(
Inference):根据用户输入生成输出结果。 - 微调(
Fine-tuning):用户可以在已有模型的基础上使用自己的数据进行训练,从而定制化模型以适应特定的任务或领域。
1.3.2 任务(Task)
Ollama 支持多种 NLP 任务。每个任务对应模型的不同应用场景,主要包括但不限于以下几种:
- 对话生成(
Chat Generation):通过与用户交互生成自然的对话回复。 - 文本生成(
Text Generation):根据给定的提示生成自然语言文本,例如写文章、生成故事等 - 情感分析(
Sentiment Analysis):分析给定文本的情感倾向(如正面、负面、中立) - 文本摘要(
Text Summarization):将长文本压缩为简洁的摘要。 - 翻译(
Translation):将文本从一种语言翻译成另一种语言。
1.3.3 推理(Inference)
推理是指在已训练的模型上进行输入处理,生成输出的过程。
Ollama 提供了易于使用的命令行工具或 API,可以快速向模型提供输入并获取结果。
推理是 Ollama 的主要功能之一,也是与模型交互的核心。
推理过程:
输入:用户向模型提供文本输入,可以是一个问题、提示或者对话内容。模型处理:模型通过内置的神经网络根据输入生成适当的输出。输出:模型返回生成的文本内容,可能是回复、生成的文章、翻译文本等。
1.3.4 微调(Fine-tuning)
微调是指在一个已预训练的模型上,基于特定的领域数据进行进一步的训练,以便使模型在特定任务或领域上表现得更好。
Ollama 支持微调功能,用户可以使用自己的数据集对预训练模型进行微调,来定制模型的输出。
微调过程:
准备数据集:用户准备特定领域的数据集,数据格式通常为文本文件或 JSON 格式。加载预训练模型:选择一个适合微调的预训练模型,例如 LLama2 或 GPT 模型。训练:使用用户的特定数据集对模型进行训练,使其能够更好地适应目标任务。保存和部署:训练完成后,微调过的模型可以保存并部署,供以后使用。
1.4 Ollama命令
Ollama 提供了多种命令行工具(CLI)与本地运行的模型进行交互。
基本格式:ollama <command> [args]
用 ollama --help 查看包含有哪些命令
使用方法:
ollama [flags]:使用标志(flags)运行ollama
可用标志(Flags):-h, --help:显示ollama的帮助信息-v, --version:显示版本信息
ollama [command]:运行ollama的某个具体命令
可用命令如下:serve:启动ollama服务
REST端点(默认 http://localhost:11434/api):/api/generate:文本生成/api/chat:对话流式接口/api/pull:远程拉取/api/tags:本地模型列表
create:根据一个Modelfile创建一个模型show:显示某个模型的详细信息,查看模型的元数据、参数或Modelfilerun:运行一个模型,如果不存在则自动拉取--num-predict <number>:限制输出 token 数--temperature <float>:控制随机性--top-k <int>:采样范围--top-p <float>:核采样--seed <int>:固定随机性--format json:输出 JSON--keepalive <seconds>:会话保持时间
stop:停止一个正在运行的模型pull:从一个模型仓库(registry)拉取一个模型,但不运行push:将一个模型推送到一个模型仓库list:列出本地所有已下载的模型ps:列出所有正在运行的模型及显存占用cp:复制一个模型,将现有模型复制为新名称rm:移除本地模型释放空间help:获取关于任何命令的帮助信息
当输入 ollama run 进入聊天界面后,不再是在操作命令行,而是在和 AI 对话。这时可以使用以 / 开头的快捷指令来控制对话:
/bye或/exit:退出聊天界面,返回命令行/clear:清空当前的上下文记忆(开启一段新的对话)。/show info:查看当前模型的详细参数信息/set parameter seed 123:设置随机种子(高级玩法,用于复现结果)/help:在聊天中查看所有可用的快捷键
构建模型时使用 Modelfile 指令:
FROM <model>:基础模型SYSTEM "xxx":设定系统提示PARAMETER key=value:设定默认参数TEMPLATE "xxx":自定义 Chat 模板LICENSE "xxx":设置 LicenseADAPTER <file> / WEIGHTS <file>:加载 LoRA 或额外权重
1.5 模型操作
1.5.1 运行模型
Ollama 运行模型使用 ollama run 命令。
比如:ollama run llama3.2,执行以上命令如果没有该模型会去下载 llama3.2 模型
通过 Python SDK 使用模型
如果想将 Ollama 与 Python 代码集成,可以使用 Ollama 的 Python SDK 来加载和运行模型。
安装 Ollama 的 Python SDK,打开终端,执行:pip install ollama
使用 Python 代码来加载和与模型交互。
import ollama
response = ollama.generate(model="llama3.2", # 模型名称prompt="你是谁。" # 提示文本
)
print(response)流式响应
from ollama import chat
stream = chat(model="llama3.2",messages=[{"role": "user", "content": "为什么天空是蓝色的?"}],stream=True
)
for chunk in stream:print(chunk["message"]["content"], end="", flush=True)
1.5.2 模型交互
- 命令行交互:
通过命令行直接与模型进行交互是最简单的方式
使用ollama run命令启动模型并进入交互模式:ollama run <model-name>
启动后,您可以直接输入问题或指令,模型会实时生成响应。
在交互模式下,输入/bye或按下Ctrl+d退出 - 单次命令交互:
如果只需要模型生成一次响应,可以直接在命令行中传递输入。
通过管道将输入传递给模型:
echo "你是谁?" | ollama run deepseek-coder
直接在命令行中传递输入:ollama run deepseek-coder "Python 的 hello world 代码?" - 多轮对话
Ollama支持多轮对话,模型可以记住上下文 - 文件输入
可以将文件内容作为输入传递给模型
ollama run deepseek-coder < input.txt - 自定义提示词
通过Modelfile定义自定义提示词或系统指令,使模型在交互中遵循特定规则。
创建自定义模型
编写一个Modelfile:FROM deepseek-coder SYSTEM "你是一个编程助手,专门帮助用户编写代码。"
然后创建自定义模型:ollama create test-coder -f ./Modelfile
运行自定义模型:ollama run test-coder - 交互日志
Ollama会记录交互日志,方便调试和分析:ollama logs
1.6 与浏览器交互
1.6.1 Open WebUI
1.6.1.1 简介
Open WebUI 用户友好的 AI 界面(支持 Ollama、OpenAI API 等)。
Open WebUI 支持多种语言模型运行器(如 Ollama 和 OpenAI 兼容 API),并内置了用于检索增强生成(RAG)的推理引擎,使其成为强大的 AI 部署解决方案。
Open WebUI 可自定义 OpenAI API URL,连接 LMStudio、GroqCloud、Mistral、OpenRouter 等。
官方文档:https://docs.openwebui.com
1.6.1.2 安装
使用 Docker 安装
如果 Ollama 已安装在电脑上,使用以下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
使用 Nvidia GPU 支持运行 Open WebUI:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
装完成后,通过访问 http://localhost:3000 使用 Open WebUI。
Open WebUI 可以通过 Python 的包安装程序 pip 进行安装,在开始安装之前,请确保使用的是 Python 3.11,以避免可能出现的兼容性问题。
打开终端,运行以下命令以安装 Open WebUI:pip install open-webui
安装完成后,通过以下命令启动 Open WebUI:open-webui serve
启动后,Open WebUI 服务器将运行在 http://localhost:8080
1.6.2 Page Assist
1.6.2.1 简介
Page Assist 是一款开源的浏览器扩展程序,主要为本地 AI 模型提供直观的交互界面,让用户可以在任何网页上与本地 AI 模型进行对话和交互。
Page AssistGithub 源代码:https://github.com/n4ze3m/page-assist
基本功能:
- 侧边栏交互:用户可以在任何网页上打开侧边栏,与本地 AI 模型进行对话,获取与网页内容相关的智能辅助。
- 网页 UI:提供类似 ChatGPT 的网页界面,用户可以在此界面中与 AI 模型进行更全面的对话。
- 网页内容对话:用户可以直接与网页内容进行对话,获取相关信息的解释或分析。
多浏览器支持:支持 Chrome、Brave、Edge 和 Firefox 等主流浏览器。 - 快捷键操作:通过快捷键可以快速打开侧边栏和网页 UI,方便用户使用。
- 支持多种本地 AI 提供商:目前支持 Ollama 和 Chrome AI (Gemini Nano) 等本地 AI 提供商。
- 文档解析:支持与 PDF、CSV 等多格式文档进行聊天交流。
- 离线模型适配:适用于离线环境,用户可以在本地运行 AI 模型。
- 隐私保护:所有交互都在本地完成,不会收集用户个人数据,数据存储在浏览器的本地存储中。
- 开发模式:支持开发者模式,便于进行扩展的开发和测试。
1.6.2.2 安装与使用
直接从 Chrome Web Store 或 Firefox Add-ons 商店下载安装,也可以通过手动安装的方式进行,访问 https://chromewebstore.google.com/search/,搜索 Page Assist
打开后就可以看到 Ollama 正在运行的提示,如果还没启动则需要启动 Ollama
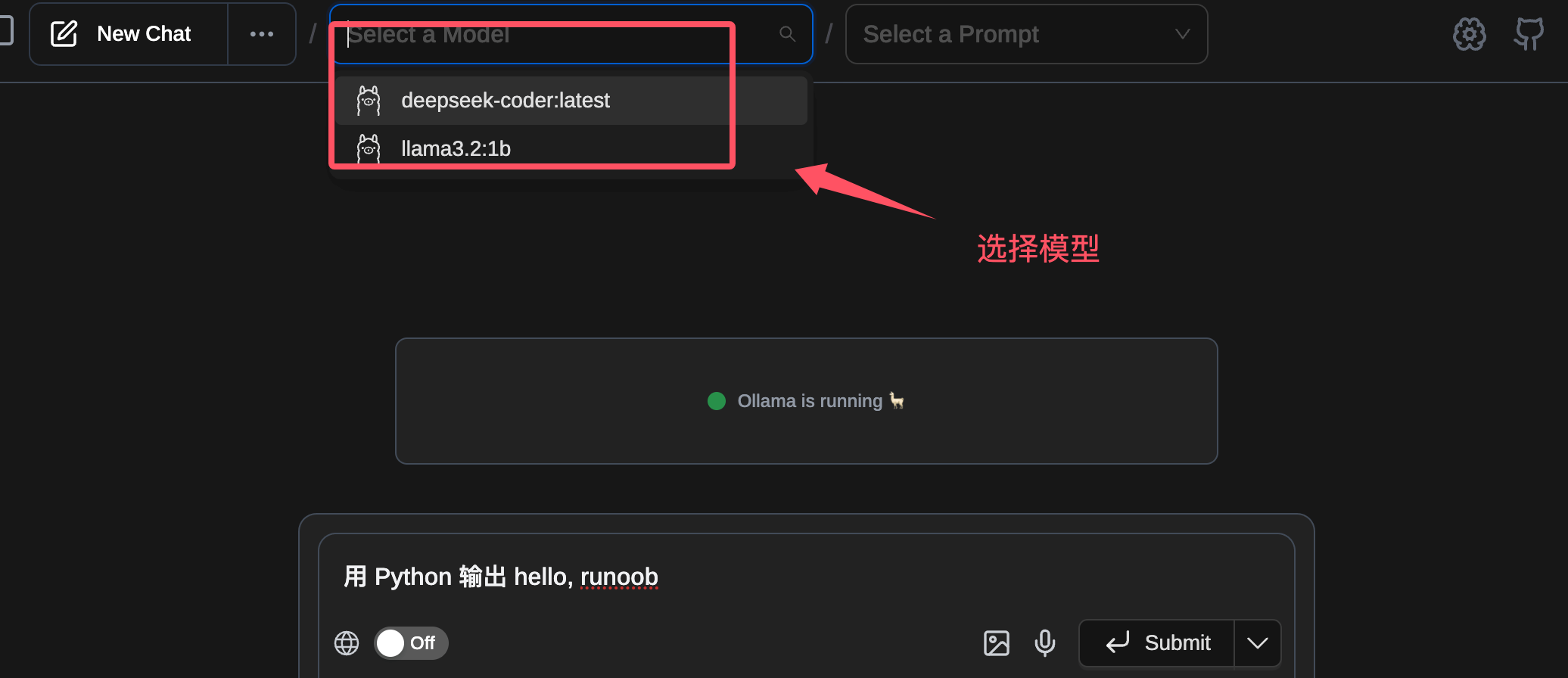
接下来我们可以选择指定的模型,然后输入提示词:
1.7 与Python交互
1.7.1 安装SDK
安装 Ollama 的 Python SDK。
pip install ollama
确保环境中已安装了 Python 3.x,并且网络环境能够访问 Ollama 本地服务
在使用 Python SDK 之前,确保 Ollama 本地服务已经启动。
使用命令行工具来启动它:ollama serve
如果已经用run启动了为什么还要用server?
因为
ollama run只能打开一个交互式命令行会话;它本身不会监听任何端口,也就无法被Python程序调用。
因此想让Ollama对外提供 API(HTTP 或官方 SDK),都必须先执行ollama serve
这条命令会在后台启动本地服务,默认监听localhost:11434,然后才能用 Python 通过 HTTP 或 ollama-python 与之通信 。
1.7.2 使用SDK交互
1.7.2.1 简单使用
通过 Python SDK,向指定的模型发送请求,生成文本或对话:
from ollama import chat
from ollama import ChatResponseresponse: ChatResponse = chat(model='deepseek-coder', messages=[{'role': 'user','content': '你是谁?',},
])
# 打印响应内容
print(response['message']['content'])# 或者直接访问响应对象的字段
#print(response.message.content)
1.7.2.2 常用 API 方法
Ollama Python SDK 提供了一些常用的 API 方法,用于操作和管理模型。
chat方法
与模型进行对话生成,发送用户消息并获取模型响应:
ollama.chat(model='llama3.2', messages=[{'role': 'user', 'content': 'Why is the sky blue?'}])generate方法
用于文本生成任务。与 chat 方法类似,但是它只需要一个 prompt 参数:ollama.generate(model='llama3.2', prompt='Why is the sky blue?')list方法
列出所有可用的模型:ollama.list()show方法
显示指定模型的详细信息:ollama.show('llama3.2')create方法
从现有模型创建新的模型:
ollama.create(model='example', from_='llama3.2', system="You are Mario from Super Mario Bros.")copy方法
复制模型到另一个位置:ollama.copy('llama3.2', 'user/llama3.2')delete方法
删除指定模型:ollama.delete('llama3.2')pull方法
从远程仓库拉取模型:ollama.pull('llama3.2')push方法
将本地模型推送到远程仓库:ollama.push('user/llama3.2')embed方法
生成文本嵌入:
ollama.embed(model='llama3.2', input='The sky is blue because of rayleigh scattering')ps方法
查看正在运行的模型列表:ollama.ps()
1.7.3 使用Http方式交互
1.7.3.1 使用Ollama http
Ollama 的端口兼容 OpenAI 格式,也提供原生 REST 端点
from ollama import Clientclient = Client(host='http://localhost:11434',headers={'x-some-header': 'some-value'}
)response = client.chat(model='deepseek-coder', messages=[{'role': 'user','content': '你是谁?',},
])
print(response['message']['content'])
异步执行请求,可以使用 AsyncClient 类,适用于需要并发的场景。
import asyncio
from ollama import AsyncClientasync def chat():message = {'role': 'user', 'content': '你是谁?'}response = await AsyncClient().chat(model='deepseek-coder', messages=[message])print(response['message']['content'])asyncio.run(chat())
异步客户端支持与传统的同步请求一样的功能,唯一的区别是请求是异步执行的,可以提高性能,尤其是在高并发场景下。
1.7.3.2 使用其他http请求
import requests, json
url = 'http://localhost:11434/api/chat'
payload = {"model": "deepseek-coder","messages": [{"role": "user", "content": "写个快速排序"}],"stream": False
}
resp = requests.post(url, json=payload)
print(resp.json()['message']['content'])