FBGEMM算子库
1. FBGEMM算子库(gitee.com)
Torchrec是Pytorch社区的官方推荐库,为支持使用torchrec训练相关模型,需要在昇腾上适配torchrec模型使用到的基础算子。由于本方案中主要涉及到的模型有DCNV2和GR模型,分别是传统推荐和生成式推荐代表模型。参考mindx-rec sdk官方开源代码,目前主要对FBGEMM库中JaggedToPaddedDense、DenseToJagged、Permute2dSparseData、AsynchronousCompleteCumsum、BackwardCodegenAdagradUnweightedExact、SplitEmbeddingCodegenForwardUnweighted、这些算子做了适配和优化,同时在此基础上,引入HstuDenseBackward、HstuDenseForward两个自定义优化算子,对GR模型进行加速处理。如若涉及到其他模型需要相关新增算子适配,可参照官方教程开发自定义算子即可。
算子库的安装
| torch版本 | 配套关系 |
|---|---|
| torch==2.6.0 | torch_npu 2.6.0 <br / fbgemm+gpu 1.1.0+cpu torchrec 1.1.0+npu |
1. 源码下载:
# 基于RecSDK开源仓进行编译安装
git clone -b develop_embcache https://gitcode.com/Ascend/RecSDK.git# 源码安装适配NPU的torchrec版本,克隆torchrec源码.patch后编译安装
git clone -b release/v1.1.0 https://gitcode.com/pytorch/torchrec.git
cd torchrec && git checkout 2c5f6ee && cd ../
bash ./RecSDK/torchrec/build_whl.sh
# 安装
cd dist
pip3 install torchrec-1.1.0+npu-*.build_whl
pip3 install -r requirements.txt
2. 编译并安装算子
# 基于开源RecSDK进行安装# 算子编译
cd RecSDK/mxrec_add_ons/build
bash build.sh# 进入打包文件夹
cd ../output
# 解压
tar -xf Ascend-mindxsdk-mxrec-add-ones-linux-x86_64.tat.gz# 进入算子目录
cd mxrec-add-ones/mxrec_ops# 安装算子
bash mxrec_opp_asynchronous_complete_cumsum.run
bash mxrec_opp_backward_codegen_adagrad_unweighted_exact.run
bash mxrec_opp_gather_for_rank1.runbash mxrec_opp_bounds_check_indices.run
bash mxrec_opp_dense_to_jagged.run
bash mxrec_opp_hstu_dense_backward.run
bash mxrec_opp_hstu_dense_forward.run
bash mxrec_opp_index_select_for_rank1_backward.run
bash mxrec_opp_jagged_to_padded_dense.run
bash mxrec_opp_permute2d_sparse_data.run
bash mxrec_opp_plit_embedding_codegen_forward_unweighted.run
算子会安装在/usr/local/Ascend/ascend-toolkit/latest/opp/vendors目录检查算子安装情况。
3. 安装算子适配层
# 进入算子适配层
cd mxrec-add-ones/torch_plugin/torch_library/2.6.0/common
bash build.sh"""
编译过程中会生成fbgemm_npu_api.so,默认存在了python 的site-package目录下
"""
1.1、JaggedToPaddedDense
该算子的主要作用是将不规则张量tensor转换为稠密张量。这是因为GR模型在QKV矩阵使用matmul时无法对jagged非对齐形式的数据进行计算。而在训练中,为了节省显存,需要将数据进行稠密存储计算,即传入jagged非对齐形式的数据。因此,在算子计算过程中,需要将jagged形式数据转换为对齐的dense形式数据用于matmul计算。参考案例如下所示:
import torchvalues = torch.tensor([1, 2, 3, 4, 5, 6]) # 所有序列的值
x_offsets = torch.tensor([0, 2, 5, 6]) # 每个序列的偏移量,shape=[B+1]
n=50 # 表示dense数组的长度
# 默认补0
result= torch.ops.fbgemm.jagged_to_padded_dense(values, [x_offsets], [n])
打印result可得到
"""
result: tensor([[1, 2, 0, ..., 0, 0, 0],[3, 4, 5, ..., 0, 0, 0],[6, 0, 0, ..., 0, 0, 0]])
"""
算子原型参考gitee.com中jagged_to_padded_dense实现。
注:该算子不涉及数据计算,仅需要做数据拷贝,需要对非对齐数据拷贝,使用DataCopyPad接口对非对齐部分直接做填充处理。
1.2、DenseToJagged
该算子与JaggedToPaddedDense互为逆向操作,其主要作用是将稠密张量转换为稀疏张量tensor。如下图展所示(输入是3 * 4 * 4的dense向量,经过算子操作后变成7*4的向量):
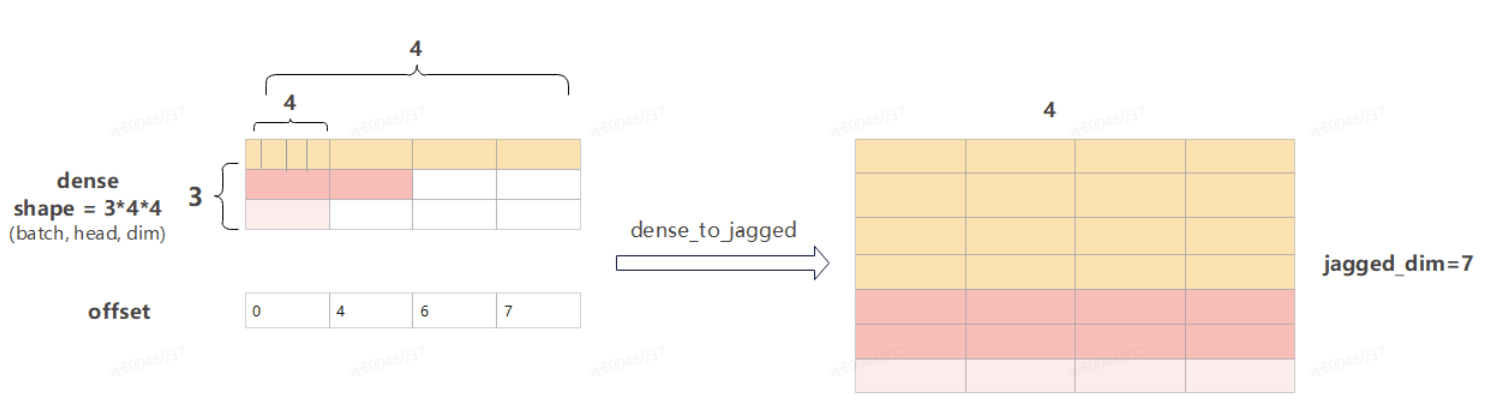
offset参数按dense的第一维轴来计算长度,可以理解为offset指定每个batch的有效数据长度。如上图,dense的shape为[3,4,4],每个batch的子shape为[4,4];offset为[0,4,6,7],每个batch有效数据长度为offset的前闭后开区间的第二维数据下标,即第一个batch的有效数据长度为[0,4),第二个batch为[4,6),第三个batch为[6,7)。算子原型参考gitee.com中实现。
import torchdense_tensor = torch.tensor([ # 定义一个已经填充好的稠密张量[1, 2, 0, 0, 0, 0, 0, 0, 0, 0], # 序列1:实际长度2[3, 4, 5, 0, 0, 0, 0, 0, 0, 0], # 序列2:实际长度3 [6, 0, 0, 0, 0, 0, 0, 0, 0, 0] # 序列3:实际长度1
])x_offsets = torch.tensor([0, 2, 5, 6]) # 每个序列的偏移量recovered_values, recovered_offsets = torch.ops.fbgemm.dense_to_jagged(dense_tensor, [x_offsets] ) # 传入偏移量列表
"""
recovered_values: tensor([1, 2, 3, 4, 5, 6])
recovered_offsets:[tensor([0, 2, 5, 6])]
"""
注:该算子不涉及数据计算,仅需要做数据拷贝,需要对非对齐数据拷贝,使用DataCopyPad接口对非对齐部分直接做填充处理。
1.3、Permute2dSparseData
在通过 Embedding Lookup 查询 Key 时,排序后的 Key 会经由 alltoall 操作分发到各个 Rank 上进行并行查询。然而,由此获取的 Embedding 向量顺序与原始输入顺序不一致,因此需要在返回前执行一次置换操作,以恢复其原始顺序。
在训练过程中,实际存储的数据格式为稀疏的 Jagged Tensor。为在 NPU 上兼容 PyTorch 中 FBGEMM 库的对应函数,我们适配了 torch.ops.fbgemm.permute_2D_sparse_data 算子。该算子的核心功能是对二维稀疏数据进行重新排列。与常见的 Transpose 算子(通常作用于稠密张量,仅依赖轴索引即可完成转换)不同,对稀疏 Tensor 进行置换需额外引入一个二维的 lengths tensor,用于明确指定每个维度上的数据长度,从而正确描述稀疏结构并完成置换。
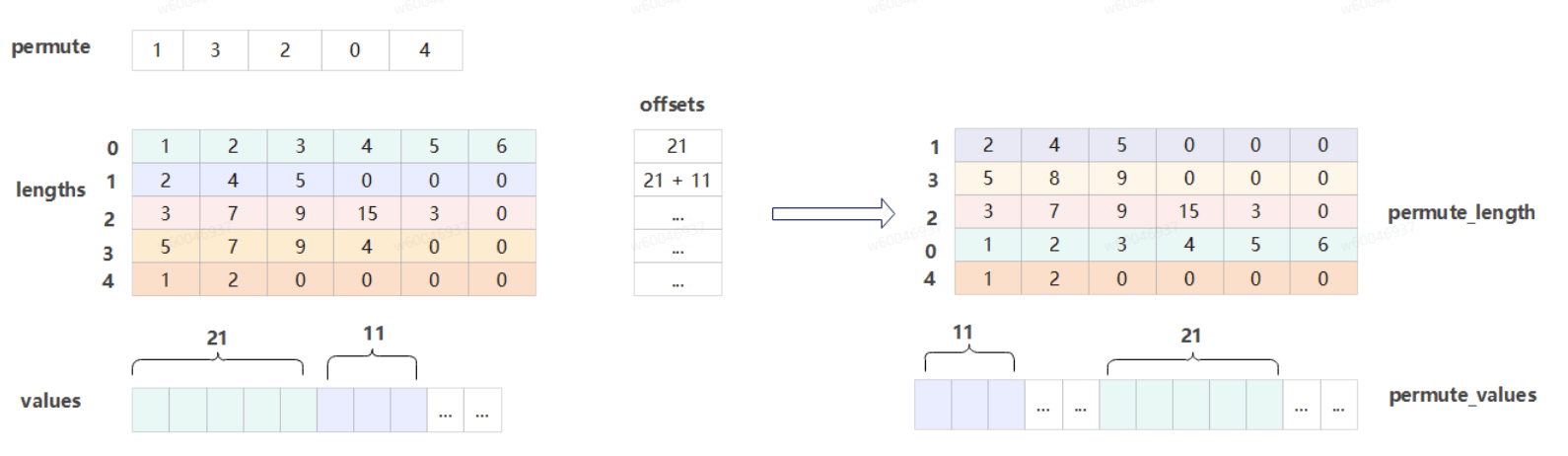
图中参数含义如下:
permute:为重排的顺序参数,重排的lengths及values均按permute中下标顺序重排。
lengths:待重排长度参数,一维长度与permute维度相等,每行数据的总和为值数据values中一块重排数据的长度。
values:待重排值参数,长度为长度参数lengths中所有数据之和。
import torchlengths = torch.tensor([2, 3, 1, 4]) # 每个样本的特征数量
indices = torch.tensor([10, 20, 30, 40, 50, 60, 70, 80, 90, 100]) # 特征索引
weights = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]) # 特征权重# 原来的第3个样本移动到第0位置
# 原来的第1个样本移动到第1位置
# 原来的第0个样本移动到第2位置
# 原来的第2个样本移动到第3位置
permute = torch.tensor([3, 1, 0, 2])permuted_lengths, permuted_indices, permuted_weights = torch.ops.fbgemm.permute_2D_sparse_data(permute, lengths, indices, weights)"""
排列后 lengths: tensor([4, 3, 2, 1])
排列后 indices: tensor([ 70, 80, 90, 100, 30, 40, 50, 10, 20, 60])
排列后 weights: tensor([ 7., 8., 9., 10., 3., 4., 5., 1., 2., 6.])
"""
算子原型参考 gitee.com中permute2d_sparse_data算子实现。
1.4、AsynchronousCompleteCumsum
AsynchronousCompleteCumsum(中文名叫异步完全累积和),该算子是一种专为分布式深度学习训练设计的高性能通信算子,算子主要功能为实现输入offsets的累加操作,将长度转换为对应的offset。参考案例如下图所示(输入x,输出y):
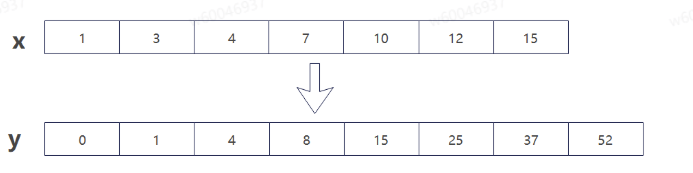
将输入参数按个累加即可。需要注意的是,结果表示的是偏移值,因此第一个数必须置为0,即表示第一个数据的偏移为0。
import torchlengths = torch.tensor([2, 3, 1, 4], dtype=torch.int32) # 每个序列的长度# 计算累积和
cumsum_result = torch.ops.fbgemm.asynchronous_complete_cumsum(lengths)print("累积和结果:", cumsum_result)
print("累积和形状:", cumsum_result.shape)"""
原始 lengths: tensor([2, 3, 1, 4], dtype=torch.int32)
累积和结果: tensor([ 0, 2, 5, 6, 10], dtype=torch.int32)
"""
1.5、HstuDenseForward
GR模型的核心创新点之一是其提出了统一的新的序列转化架构HSTU,该算子实现了HSTU模块的前向计算过程,目前支持四种mask机制,其前向计算公式如下图所示:
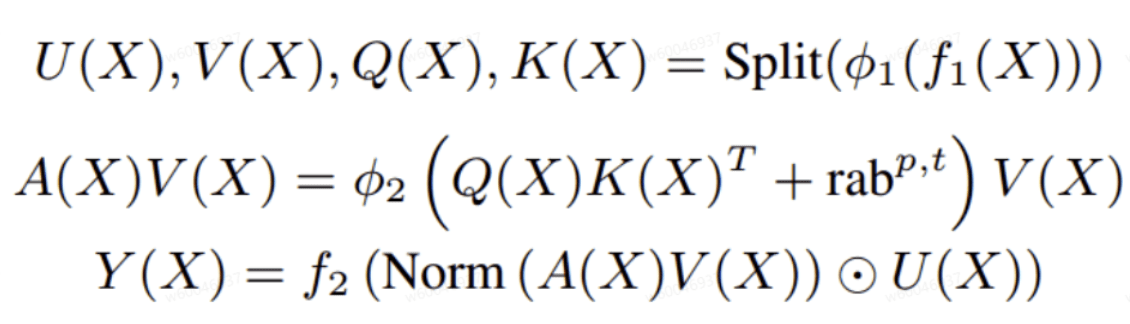
生成式推荐场景为了节省显存,将Q,K,V的[b,s,n,d]压缩存储为jagged格式[s_b, n, d]移除了s轴的padding,将s和b进行连续存储。导致了QK_MATMUL计算分核处理,基本块大小,不好设计和处理。具体计算流程如下图所示:
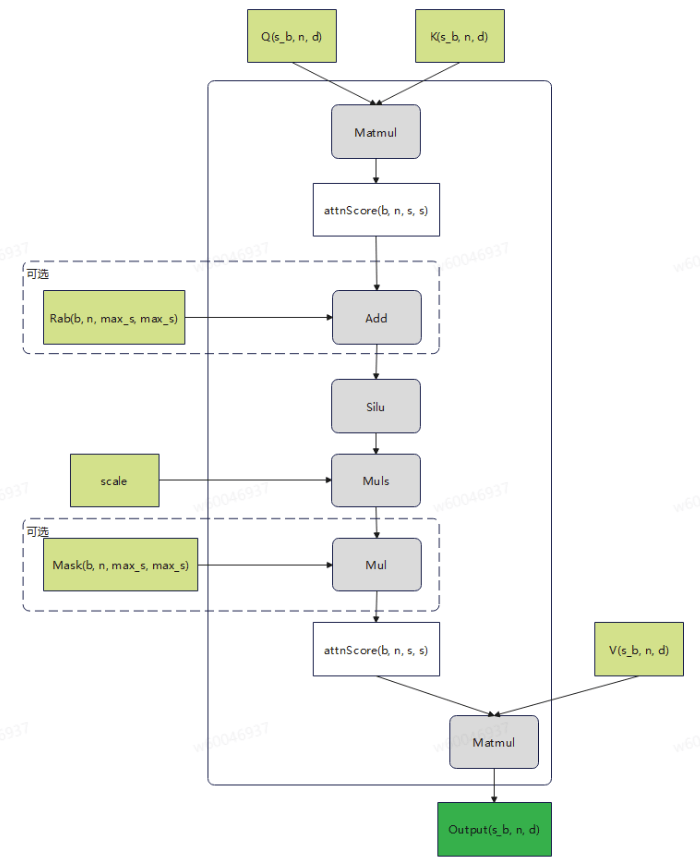
注:图中s_b表示将表征序列轴s和batch轴加起来;n表示headNum表征头的个数;d表示表征维度;max_s表示变长序列中最大序列长度。算子原型参考gitee.com中实现。
"""简单的 torch.ops.mxrec.hstu_dense 调用示例"""
import torchdef simple_hstu_dense_example():# 定义参数batch_size = 2max_seq_len = 4head_num = 2head_dim = 8data_type = torch.float32mask_type = 0 # 假设的掩码类型"""mask_type = 0:使用内置倒三角mask 不需要传递mask输入;mask_type = 1:使用内置上三角mask 不需要传递mask输入,暂不支持;mask_type = 2:不使用mask;mask_type = 3:使用用户自定义mask 此时mask输入需要用户定义并传入"""silu_scale = 1.0 # SiLU激活函数的缩放因子device_id = 0 # 假设的设备ID# 生成jagged类型的随机张量def jagged_data_gen(batch_size, max_seq_len, num_heads, attention_dim, data_type, mask_type):"""batch_size (int): 批处理大小,表示每个批次中的样本数量;max_seq_len (int): 序列的最大长度,用于生成随机序列长度的上限;num_heads (int): 注意力机制中的头数,表示多头注意力的数量;attention_dim (int): 注意力维度,表示每个注意力头的维度大小;data_type (torch.dtype): 数据类型,指定生成张量的数据类型,如torch.float32;mask_type (int): 掩码类型;"""seq_lens = np.random.randint(1, max_seq_len + 1, (batch_size))seq_offset = torch.concat((torch.zeros((1,), dtype=torch.int64), \torch.cumsum(torch.from_numpy(seq_lens), axis=0))).to(torch.int64).numpy()max_seq_len = np.max(seq_lens)total_seqs = np.sum(seq_lens)q = torch.rand(total_seqs, num_heads, attention_dim).to(torch.float32)q = q.uniform_(-1, 1)k = torch.rand(total_seqs, num_heads, attention_dim).to(torch.float32)k = k.uniform_(-1, 1)v = torch.rand(total_seqs, num_heads, attention_dim).to(torch.float32)v = v.uniform_(-1, 1)# 生成maskif mask_type == mask_tril:invalid_attn_mask = 1 - torch.triu(torch.ones(batch_size, num_heads, max_seq_len, max_seq_len), diagonal=1)else:invalid_attn_mask = torch.randint(0, 2, size=(batch_size, num_heads, max_seq_len, max_seq_len))invalid_attn_mask = invalid_attn_mask.cpu().to(torch.float32)return q, k, v, seq_offset, invalid_attn_mask, max_seq_len# 生成输入张量q, k, v, seq_offset, mask, max_seq_len = jagged_data_gen(batch_size, max_seq_len, head_num, head_dim, data_type, mask_type)# 调用 hstu_dense 操作output = torch.ops.mxrec.hstu_dense(q, k, v, mask, None, mask_type, max_seq_len, silu_scale, "jagged", seq_offset)return output# 运行示例
if __name__ == "__main__":result = simple_hstu_dense_example()
1.6、HstuDenseBackward
HSTU的Backward是Forward的逆过程,需要计算图中绿色方格的梯度Grad_V、Grad_bias、Grad_K、Grad_Q信息便于训练过程中参数的更新。在HstuDenseForward过程中,会自动注册反向操作,不需要单独调用。
算子原型参考gitee.com中实现。
1.7、SplitEmbeddingCodegenForwardUnweighted
该算子的主要功能是根据输入的indices和offset进行查表操作,如果入参poolMode不为None,将同一个offset中的indices对应的embedding进行pooling计算后输出;poolMode为None时,直接将查表结果输出到对应位置。其中poolMode主要是用来区分Torchrec中EC和EBC模式的表。
Case1:EBC模式(poolMode≠None),对indices中所有下标查表后并对表中数据求和。如下图所示:indices中的每个值都对应了一个对象,每个对象都需要查表获得返回值。offsets类似c++的数组,保存了数组的首地址。offsets和indices共同协作从devWeightsGT中取向量进行聚合(求和、平均、最大值或最小值等)。
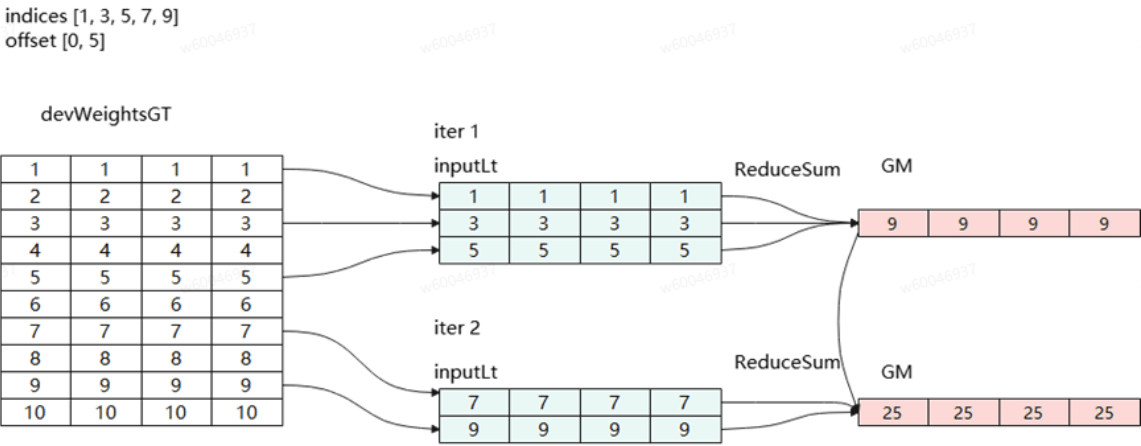
Case2:EC模式(poolMode=None),对indices中所有下标分批次查表后合表(仅查询合并,不做聚合操作)返回。
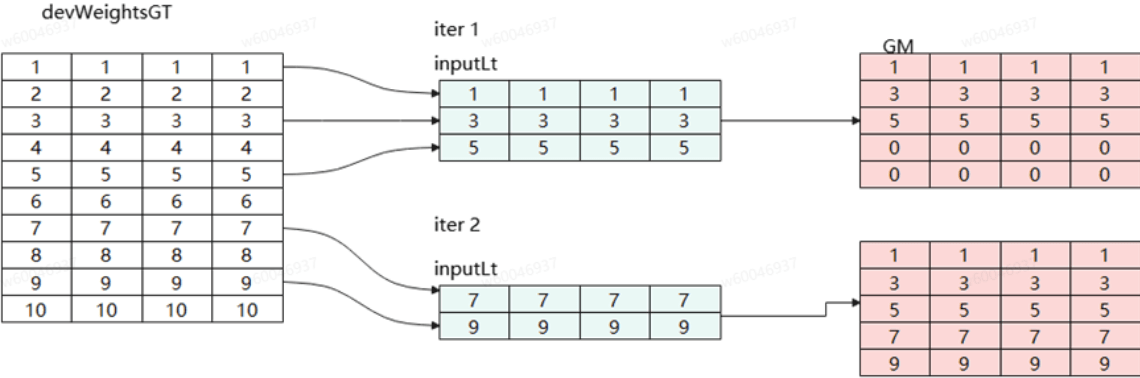
算子实现原型参考gitee.com中实现,该算子可对多张表进行合并查询,并针对不同模式可选择性对表中数据是否进行pooling操作(sum或mean等)。
1.8、BackwardCodegenAdagradUnweightedExact
该算子原型为pytorch中FBGEMM库的同名函数(torch.ops.fbgemm.split_embedding_codegen_lookup_adam_function),主要功能是对查表反向更新操作。由于正向查表算子是将返回的特征向量进行聚合(求和等),该算子是在查到的向量经过一系列运算后会产生梯度,反向传播时该算子计算原特征表各个向量对应的梯度值,并更新特征表。如下图所示(grad分成了两组,第一组对应3个元素:1、3、5;第二组对应2个元素:1、9),从图中可以看到indices 1出现两次,因此在更新grad_weights时候需要将两者叠加后更新对应位置梯度值。
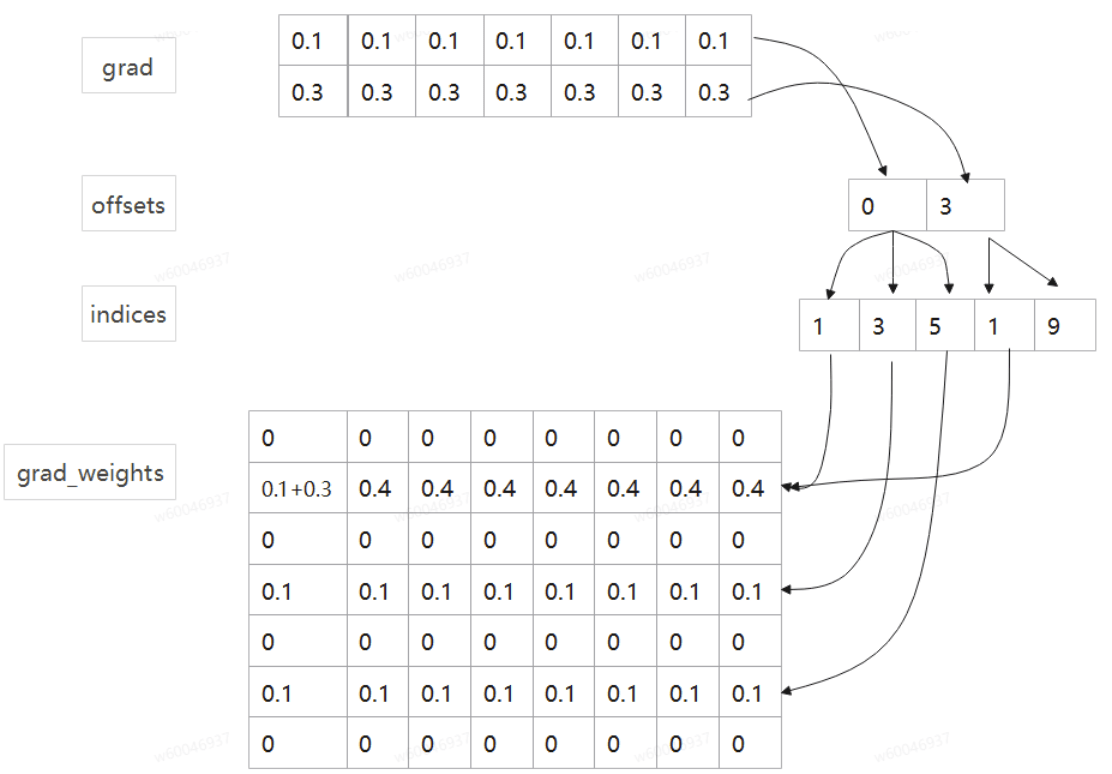
综上,整个反向过程接收到模型侧传递过来的梯度grad,根据indices(重复下标表示多个梯度需要聚合)将_grad分别更新到Embedding表中(grad_weights)。算子原型参考gitee.combackward_codegen_adagrad_unweighted_exact算子中实现。