昇腾流水线优化技术详解
1. pipeline多级流水
Pipeline多级流水的核心思想是将训练步骤拆分为多个连续的阶段(Stage),通过异步调度,使不同批次的处理过程在流水线上重叠执行。这种流水线并行机制有效掩盖了阶段间的通信与计算耗时,从而显著提升了训练吞吐量与硬件利用率。
如下图所示,一个训练步骤依次经过 Stage 1、2、3。当流水线稳定运行时,在某一时刻(如红色箭头标识):Batch 0 正执行其 Stage 3,与此同时,Batch 1 正执行其 Stage 2,而 Batch 2 正执行其 Stage 1。这三个不同批次的阶段在同一时间点并行运行,后一批次的前期阶段被前一批次的后期阶段所“掩盖”,从而实现系统吞吐量的提升。

因为NPU和GPU硬件差异较大,所以两者在多级流水的底层实现逻辑上会有所差异。接下来将对NPU和GPU侧任务。
2. Rec SDK多级流水
本系统采用参数服务器(Parameter Server)架构,结合NPU多流并行技术,实现大规模稀疏特征的高效训练。通过计算与通信重叠、动态换入换出等优化策略,显著提升训练吞吐量。NPU中对于单个batch数据的处理流程如下:

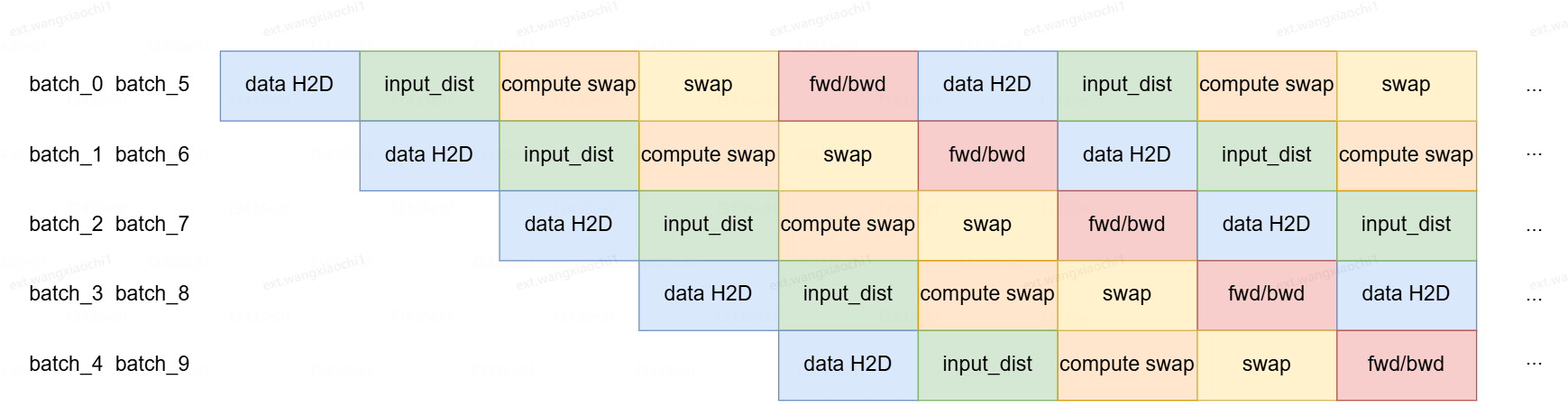
从图中可以看到单个bath数据的数据训练流程可被切分成五个细粒度的阶段,代码对应如下:
NPU侧的多流通过Torchrec实现了EmbCacheTrainPipelineSparseDist,因涉及cpu和npu的交互,分为了5个stage。如下图所示为10个step之间,不同batch的流水线并行时不同stage之间的交互情况。
-
data H2D:dataloader返回batch拷贝到NPU,使用memcpy stream实现异步;
-
input_dist:data分桶并执行all2all,使用data_dist stream实现异步;
-
compute swap: 依据当前batch和已经在NPU上的key计算需要换入换出的key,使用线程池实现异步;
-
swap:涉及换入换出多个操作,npu emb gather/cpu emb update/cpu emb lookup/npu emb update;
-
fwd/bwd:包含emb查询,dense的前反向更新,emb的反向更新,使用default stream实现异步;
当前该方案已在gitcode上开源,代码实现可参考gitcode.com:
用户端接口调用
from torchrec_embcache.distributed.train_pipeline import EmbcacheTrainPipelineSparseDistmodel =
optimizer =
dataloader_iter = EmbCacheTrainPipelineSparseDist(model, optimizer, cpu_device=cpu_device, npu_device="npu:0")while True:try:pipeline.progress(dataloader_iter)except StopIteration:break
内部实现:
调用fill_pipeline,在真正的持续输出开始之前,需要先将前几个 batch 推进到各个 stage 中,形成“满载”状态。
fill_pipeline 方法:流水线初始化填充
首先,检查流水线是否已满(4个批次),避免重复填充
def fill_pipeline(self, dataloader_iter: Iterator[In]) -> None:# pipeline is already filledif len(self.batches) >= 4:return
batch_0的阶段性处理
初始化流水线模块,设置前向传播管道
self._init_pipelined_modules(self.batches[0], self.contexts[0], EmbCachePipelinedForward)
等待分布式所有阶段的稀疏数据同步完成,并将结果填充到训练管道上下文中。执行后输入分布处理,通过do_post_input_dist过程等待AlltoAll完成,并进行分桶去重的操作。
self.wait_sparse_data_dist(self.contexts[0])
self.do_post_input_dist(self.contexts[0])
同步等待目前批次batch_0的数据就绪, 预先确定嵌入层的交换策略。
with record_function("## wait_for_batch ##"):_wait_for_batch(cast(In, self.batches[0]), self._data_dist_stream)
开始并等待交换信息计算(确定哪些嵌入需要换入换出)
self.start_compute_swap_info(self.contexts[0]) # 分布式训练中管理嵌入层的缓存交换策略
self.wait_and_get_swap_info(self.contexts[0]) # 等待并处理缓存交换信息
在host侧通过异步操作执行嵌入查找,执行异步操作从缓存中恢复需要的嵌入向量。
self.host_embedding_lookup_async(self.contexts[0]) #
self.do_restore_async(self.contexts[0])
记录可以执行换出操作的事件,异步执行换出操作,将NPU上不需要的嵌入向量和优化器状态换出到CPU内存。
self.contexts[0].event_can_swapout.record(self._default_stream)
self.swap_out(self.contexts[0])
swap_out是异步操作。与此同时,为了最大化硬件利用率和实现计算重叠,流水线立即转入Batch 1的预处理阶段。Batch 1将执行数据分布、后处理等操作,并开始异步计算交换信息,从而与Batch 0的换出操作形成时间上的重叠,构建出高效的流水线执行梯度。
batch_1的阶段性处理
在batch 0执行换出操作的同时,启动batch 1的预处理以实现计算重叠,形成流水线梯度。
# batch i+1
if not self.enqueue_batch(dataloader_iter):return
self.start_sparse_data_dist(self.batches[1], self.contexts[1])
_fuse_input_dist_splits(self.contexts[1])
self.wait_sparse_data_dist(self.contexts[1])
self.do_post_input_dist(self.contexts[1])
with record_function("## wait_for_batch##"):_wait_for_batch(cast(In, self.batches[1]), self._data_dist_stream)
self.start_compute_swap_info(self.contexts[1])
start_compute_swap_info是异步启动操作,不阻塞当前流。由于计算交换信息需要时间,此时可以并行处理Batch 2的数据分布,避免等待Batch 1的计算完成,充分利用计算资源
batch_2和batch_3的阶段性处理
每个后续批次比前一个少执行一些阶段,构建阶梯式流水线;batch_2完成数据准备之后,立即启动batch_3的数据操作,仅对batch_3启动数据分布。
# batch i+2
if not self.enqueue_batch(dataloader_iter):return
self.start_sparse_data_dist(self.batches[2], self.contexts[2])
_fuse_input_dist_splits(self.contexts[2])
self.wait_sparse_data_dist(self.contexts[2])
self.do_post_input_dist(self.contexts[2])
with record_function("## wait_for_batch##"):_wait_for_batch(cast(In, self.batches[2]), self._data_dist_stream)# batch i+3, 仅启动数据分布,提前隐藏I/O延迟
if not self.enqueue_batch(dataloader_iter):return
self.start_sparse_data_dist(self.batches[3], self.contexts[3])
_fuse_input_dist_splits(self.contexts[3])
start_sparse_data_dist是异步操作,由于数据分布需要较长时间,提前启动可以隐藏延迟。
并行Batch的预加载机制
预加载更多批次,只执行最基本的数据分布,确保流水线永不"饿死",减少后续等待时间。
# 额外预取多个batch
for i in range(self.local_unique_parallel_batch_num):if not self.enqueue_batch(dataloader_iter):returnself.start_sparse_data_dist(self.batches[4 + i], self.contexts[4 + i])
progress 方法:流水线推进执行
首先进行流水线初始化准备,步数统计,模型检查,填充流水线,设置上下文,梯度清零
self._global_steps += 1
if not self._model_attached:self.attach(self._model)self.fill_pipeline(dataloader_iter)
self._set_module_context(self.contexts[0])
if self._model.training:with record_function("## zero_grad ##"):self._optimizer.zero_grad()
流水线末端数据同步
确保流水线末端的batch_3数据准备就绪
# wait batch_ip2
if len(self.batches) >= 4:self.wait_sparse_data_dist(self.contexts[3])with record_function("## wait_for_batch ##"):_wait_for_batch(cast(In, self.batches[3]), self._data_dist_stream)if len(self.batches) >= 5:_fuse_input_dist_splits(self.contexts[4])
加载新batch数据并管理流水线深度
加载新batch数据,如果流水线过长则开始新的数据分布
self.enqueue_batch(dataloader_iter) # 加载新的批次
if len(self.batches) >= 5 + self.local_unique_parallel_batch_num:self.start_sparse_data_dist( # 防止流水线过长self.batches[4 + self.local_unique_parallel_batch_num],self.contexts[4 + self.local_unique_parallel_batch_num], )
对batch_0数据进行嵌入缓存管理
对fill_pipeline中的batch_0的数据同步换出操作,异步更新主机端嵌入,执行换入操作
# 更新 host 侧的 Embedding 和 优化器参数
self.contexts[0].event_gather_swapouted.synchronize()
self.host_embedding_update_async(self.contexts[0])# 等待 swapin tensor 并 swapin
self.swapin_tensors_to_npu(self.contexts[0])
self.wait_and_swapin(self.contexts[0])
核心计算:前向传播
batch_0的全部数据处理操作已经完成,对目前host侧的embeddding数据执行模型前向传播,计算损失和输出
# forward
with record_function("## forward ##"):losses, output = self._model_fwd(self.batches[0])
流水线协调与预计算
协调批次间依赖,定期淘汰不常用特征,预计算后续批次信息
# 等待 i+1 swap 参数计算完成
if len(self.batches) >= 2:self.wait_and_get_swap_info(self.contexts[1])# 处理淘汰信息
if (self._evict_step_interval and (self._global_steps + 1) % self._evict_step_interval == 0 ):with record_function("## feature_evict ##"):self._start_feature_evict()# 后续batch的swap计算,计算 i+2 batch 的 swap pairs 和 key2offset
if len(self.batches) >= 3:self.start_compute_swap_info(self.contexts[2])
batch_1数据预处理
在当前批次计算时,异步预处理下一个批次。保险起见,i+1轮的swapout等i轮的swapin做完之后做
# batches[i+1] 在host侧预查
if len(self.batches) >= 2:self.contexts[1].event_can_swapout.record(self._default_stream)self.host_embedding_lookup_async(self.contexts[1])self.do_restore_async(self.contexts[1])if self._model.training:# backwardwith record_function("## backward ##"):torch.sum(losses, dim=0).backward()# updatewith record_function("## optimizer ##"):self._optimizer.step()
流水线清理和推进
完成远端批次处理,执行换出操作,等待主机更新,出队当前批次
if len(self.batches) >= 4:self.do_post_input_dist(self.contexts[3])# swapout
if len(self.batches) >= 2:self.swap_out(self.contexts[1])self.wait_host_update(self.contexts[0])
self.dequeue_batch()
return output, losses
这个设计确保了在大规模嵌入表训练场景下,系统能够保持高吞吐量和低延迟。
3. GPU侧多级流水
GPU侧采用自定义的StagedTrainPipeline,通过CUDA_Stream实现异步机制。当前stage负责提交任务,下个stage开始前需要wait上一个stage的结果。图中的prefecth就是换入(emb的H2D)或换出操作(emb的D2H)。图中data H2D、input_dist操作与NPU侧含义一致。

-
batch_1的prefecth会prefecth当前batch所有的embedding到HBM;
-
batch_0的bwd(update)结束后,需要将batch_0的所有embedding刷回到MEM,同时需要把 batch_0和batch_1交集的embedding进行更新,这是因为batch_1训练的数据需要从batch_0中获取最新取值;
-
batch_0的bwd(update)中(求交&更新)的执行需要等batch_1的prefecth完成后开始;
-
batch_2的prefect启动需要依赖batch_0的所有embedding刷回HBM;
外部接口调用:
import torchmodel = ...
optimizer = ...
dataloader_iter = ...
pipeline_stages = [PipelineStage(name="data H2D",runnable=partial(model.stage1, device=self.device),),PipelineStage(name="input_dist",runnable=model.stage2,),PipelineStage(name="prefetch",runnable=model.stage3,),
]
emb = GpuPpipeEmbedding(dataloader_iter
)
def foward():sync & swicth # 流水对齐,等待backward完成之后再去做下一个batch的换入换出data_h2d # n+3input_dist # n+2prefetch(dump and load) # n+1return batch
model = BuildMode(emb)
engine = unrec_engine(model)
while True: # 模型训练try:optimizer.zero_grad()logits = model()loss = Loss(logits)loss.backward()optimizer.step()emb.save() # embedding保存torch.save() # dense层保存except StopIteration:break
内部实现:
初始化阶段
在真正的持续输出开始之前,需要先将前几个 batch 推进到各个 stage 中,形成“满载”状态。
def _fill_pipeline(self, dataloader_iter: Iterator[In]) -> None:for batch_offset in range(self.num_stages):stages_to_run = self.num_stages - batch_offsetfor stage_idx in range(stages_to_run):self._run_stage(batch_offset=batch_offset,stage_idx=stage_idx,dataloader_iter=dataloader_iter,fill=True,)self._initialized = True
循环执行模块
每调用一次 progress() 输出一个完成 batch,该方法构成了训练 loop 的核心接口:
def progress(self,dataloader_iter: Iterator[In],) -> Optional[StageOut]:if not self._initialized:self._fill_pipeline(dataloader_iter)output = self._advance()if output is None:raise StopIterationself._num_steps += 1for stage_idx in range(self.num_stages):stage_output_idx = self.num_stages - 1 - stage_idxself._run_stage(batch_offset=stage_output_idx,stage_idx=stage_idx,dataloader_iter=dataloader_iter,)return output
流水线stage执行模块
根据输入stage的值,执行单个 stage 的逻辑。
def _run_stage(self,batch_offset: int,stage_idx: int,dataloader_iter: Iterator[In],fill: bool = False,) -> StageOutputWithEvent:stage = self._pipeline_stages[stage_idx]with record_function(f"## Pipeline Stage {stage_idx} : {stage.name} for batch {batch_offset + self._num_steps} ##"):if stage_idx == 0:batch_to_wait = self._next_batch(dataloader_iter)else:batch_to_wait = self._stage_outputs[batch_offset]assert batch_to_wait is not Nonenew_result = self._run_with_event(runnable=stage.runnable,inputs=batch_to_wait,)self._stage_outputs[batch_offset] = new_resultif fill and (fill_callback := stage.fill_callback) is not None:if self._debug_mode:logger.info(f"Finished callback for {stage.name}")fill_callback()return new_result