import numpy as np
import matplotlib.pyplot as plt
import random
def generate_chinese_char_data():
# 汉字一到十对应标签0-9
char_names = ["一", "二", "三", "四", "五", "六", "七", "八", "九", "十"]
n_classes = 10
n_samples = 800
img_size = 28
# 生成28*28像素特征,添加类别差异和少量噪声
X = np.random.rand(n_samples, img_size, img_size) * 0.5
y = np.zeros(n_samples, dtype=int)for i in range(n_samples):label = i % n_classesy[i] = label# 为每个汉字添加独特的"笔画"特征(区分不同类别)if label == 0:X[i, 14, 5:23] = 1.0elif label == 1:X[i, 10, 5:23] = 1.0X[i, 18, 5:23] = 1.0elif label == 2:X[i, 8, 5:23] = 1.0X[i, 14, 5:23] = 1.0X[i, 20, 5:23] = 1.0elif label == 3:X[i, 6:22, 8] = 1.0X[i, 10, 8:20] = 1.0X[i, 18, 15:20] = 1.0elif label == 4:X[i, 8, 5:23] = 1.0X[i, 12:20, 14] = 1.0X[i, 20, 5:23] = 1.0elif label == 5:X[i, 7, 10] = 1.0X[i, 10, 8:20] = 1.0X[i, 12:20, 10] = 1.0elif label == 6:X[i, 10, 5:15] = 1.0X[i, 12:20, 15] = 1.0elif label == 7:X[i, 10:18, 10:18] = 1.0X[i, 10:18, 18:10:-1] = 1.0elif label == 8:X[i, 10:16, 10:16] = 1.0X[i, 16, 10:20] = 1.0X[i, 12:16, 20] = 1.0elif label == 9:X[i, 14, 5:23] = 1.0X[i, 5:23, 14] = 1.0return X, y, char_names, img_size
生成数据并打印基本信息
X, y, char_names, img_size = generate_chinese_char_data()
print(f"数据集形状:特征 {X.shape},标签 {y.shape}")
print(f"汉字类别:{char_names}")
def split_train_test(X, y, test_ratio=0.3, random_seed=42):
random.seed(random_seed)
n_samples = len(X)
# 生成随机索引
indices = list(range(n_samples))
random.shuffle(indices)
# 划分索引
test_size = int(n_samples * test_ratio)
test_indices = indices[:test_size]
train_indices = indices[test_size:]
# 返回划分后的数据
X_train = X[train_indices]
X_test = X[test_indices]
y_train = y[train_indices]
y_test = y[test_indices]
return X_train, X_test, y_train, y_test
扁平化特征(用于Sigmoid和SVM,CNN需要28*28二维特征)
X_flat = X.reshape(len(X), -1)
划分数据
X_train_cnn, X_test_cnn, y_train, y_test = split_train_test(X, y)
X_train_flat, X_test_flat, _, _ = split_train_test(X_flat, y)
2.2 特征归一化(缩放到0-1之间,提升模型效果)
def min_max_normalize(X_train, X_test):
# 按特征计算最大值和最小值
max_val = X_train.max(axis=0)
min_val = X_train.min(axis=0)
# 避免除以0
max_val[max_val == min_val] = 1
# 归一化
X_train_norm = (X_train - min_val) / (max_val - min_val)
X_test_norm = (X_test - min_val) / (max_val - min_val)
return X_train_norm, X_test_norm
归一化扁平化特征
X_train_flat_norm, X_test_flat_norm = min_max_normalize(X_train_flat, X_test_flat)
2.3 标签one-hot编码(用于CNN和Sigmoid的多分类输出)
def one_hot_encode(y, n_classes):
n_samples = len(y)
one_hot = np.zeros((n_samples, n_classes))
for i in range(n_samples):
one_hot[i, y[i]] = 1
return one_hot
y_train_onehot = one_hot_encode(y_train, 10)
y_test_onehot = one_hot_encode(y_test, 10)
为CNN添加通道维度(灰度图,通道数=1)
X_train_cnn = np.expand_dims(X_train_cnn, axis=-1)
X_test_cnn = np.expand_dims(X_test_cnn, axis=-1)
print(f"CNN训练集形状:{X_train_cnn.shape},Sigmoid/SVM训练集形状:{X_train_flat_norm.shape}")
def sigmoid(x, derivative=False):
if derivative:
return sigmoid(x) * (1 - sigmoid(x))
# 防止指数爆炸
x = np.clip(x, -500, 500)
return 1 / (1 + np.exp(-x))
激活函数:ReLU(前向+反向,用于CNN)
def relu(x, derivative=False):
if derivative:
return np.where(x > 0, 1, 0)
return np.maximum(0, x)
激活函数:Softmax(前向,用于多分类输出)
def softmax(x):
# 数值稳定:减去每行最大值
x_max = np.max(x, axis=1, keepdims=True)
exp_x = np.exp(x - x_max)
return exp_x / np.sum(exp_x, axis=1, keepdims=True)
损失函数:交叉熵损失(多分类)
def cross_entropy(y_true, y_pred):
y_pred = np.clip(y_pred, 1e-10, 1 - 1e-10)
return -np.mean(np.sum(y_true * np.log(y_pred), axis=1))
4.1 模型1:CNN + Softmax(参考MNIST CNN结构,修复维度问题)
class SimpleCNN:
def init(self, img_size, n_classes=10, lr=0.001):
self.img_size = img_size
self.n_classes = n_classes
self.lr = lr
# 初始化权重和偏置(先不初始化W3/W4,在第一次前向传播时动态初始化)
# 卷积层1:32个33卷积核,添加padding=1保持尺寸
self.W1 = np.random.randn(3, 3, 1, 32) * 0.01
self.b1 = np.zeros(32)
# 卷积层2:64个33卷积核,添加padding=1保持尺寸
self.W2 = np.random.randn(3, 3, 32, 64) * 0.01
self.b2 = np.zeros(64)
# 全连接层(动态初始化,解决维度不匹配)
self.W3 = None
self.b3 = None
self.W4 = None
self.b4 = None
# 带padding的卷积运算(padding=1,保持特征尺寸)
def conv(self, X, W, b, padding=1, stride=1):# 补零X_padded = np.pad(X, ((0,0), (padding,padding), (padding,padding), (0,0)), mode='constant')n_samples, h, w, c = X_padded.shapef_h, f_w, f_c, out_c = W.shape# 计算输出尺寸out_h = (h - f_h) // stride + 1out_w = (w - f_w) // stride + 1output = np.zeros((n_samples, out_h, out_w, out_c))# 卷积计算for i in range(out_h):for j in range(out_w):patch = X_padded[:, i:i+f_h, j:j+f_w, :]for k in range(out_c):output[:, i, j, k] = np.sum(patch * W[:, :, :, k], axis=(1,2,3)) + b[k]return output# 简化最大池化
def max_pool(self, X, pool_size=2, stride=2):n_samples, h, w, c = X.shapeout_h = (h - pool_size) // stride + 1out_w = (w - pool_size) // stride + 1output = np.zeros((n_samples, out_h, out_w, c))for i in range(out_h):for j in range(out_w):patch = X[:, i*stride:i*stride+pool_size, j*stride:j*stride+pool_size, :]output[:, i, j, :] = np.max(patch, axis=(1,2))return output# 前向传播(动态初始化全连接层权重,解决维度不匹配)
def forward(self, X):# 卷积1 + ReLU + 池化(padding=1,保持尺寸)self.conv1 = self.conv(X, self.W1, self.b1, padding=1)self.relu1 = relu(self.conv1)self.pool1 = self.max_pool(self.relu1)# 卷积2 + ReLU + 池化(padding=1,保持尺寸)self.conv2 = self.conv(self.pool1, self.W2, self.b2, padding=1)self.relu2 = relu(self.conv2)self.pool2 = self.max_pool(self.relu2)# 扁平化self.flat = self.pool2.reshape(len(self.pool2), -1)# 动态初始化全连接层(仅第一次前向传播时执行)if self.W3 is None:flat_dim = self.flat.shape[1]self.W3 = np.random.randn(flat_dim, 64) * 0.01self.b3 = np.zeros(64)self.W4 = np.random.randn(64, self.n_classes) * 0.01self.b4 = np.zeros(self.n_classes)# 全连接1 + ReLUself.fc1 = np.dot(self.flat, self.W3) + self.b3self.relu3 = relu(self.fc1)# 全连接2 + Softmaxself.fc2 = np.dot(self.relu3, self.W4) + self.b4self.y_pred = softmax(self.fc2)return self.y_pred# 反向传播(简化版,仅更新权重)
def backward(self, X, y_true):batch_size = len(X)# 输出层梯度delta_fc2 = (self.y_pred - y_true) / batch_size# 更新全连接2self.W4 -= self.lr * np.dot(self.relu3.T, delta_fc2)self.b4 -= self.lr * np.sum(delta_fc2, axis=0)# 全连接1梯度delta_fc1 = np.dot(delta_fc2, self.W4.T) * relu(self.fc1, derivative=True)self.W3 -= self.lr * np.dot(self.flat.T, delta_fc1)self.b3 -= self.lr * np.sum(delta_fc1, axis=0)# 训练模型
def train(self, X_train, y_train, epochs=8, batch_size=32):print("\n=== 训练 CNN+Softmax 模型 ===")for epoch in range(epochs):loss_list = []# 批量训练for i in range(0, len(X_train), batch_size):batch_X = X_train[i:i+batch_size]batch_y = y_train[i:i+batch_size]# 前向传播y_pred = self.forward(batch_X)# 计算损失loss = cross_entropy(batch_y, y_pred)loss_list.append(loss)# 反向传播self.backward(batch_X, batch_y)# 打印每轮损失avg_loss = np.mean(loss_list)print(f"Epoch {epoch+1}/{epochs},平均损失:{avg_loss:.4f}")# 预测
def predict(self, X):y_pred = self.forward(X)return np.argmax(y_pred, axis=1)# 4.2 模型2:Sigmoid 全连接神经网络
class SimpleSigmoidNN:
def init(self, input_dim, n_classes=10, lr=0.001):
self.input_dim = input_dim
self.n_classes = n_classes
self.lr = lr
# 初始化权重和偏置
self.W1 = np.random.randn(input_dim, 128) * 0.01
self.b1 = np.zeros(128)
self.W2 = np.random.randn(128, 64) * 0.01
self.b2 = np.zeros(64)
self.W3 = np.random.randn(64, n_classes) * 0.01
self.b3 = np.zeros(n_classes)
# 前向传播
def forward(self, X):self.fc1 = np.dot(X, self.W1) + self.b1self.sig1 = sigmoid(self.fc1)self.fc2 = np.dot(self.sig1, self.W2) + self.b2self.sig2 = sigmoid(self.fc2)self.fc3 = np.dot(self.sig2, self.W3) + self.b3self.y_pred = softmax(self.fc3)return self.y_pred# 反向传播
def backward(self, X, y_true):batch_size = len(X)# 输出层梯度delta_fc3 = (self.y_pred - y_true) / batch_size# 更新W3, b3self.W3 -= self.lr * np.dot(self.sig2.T, delta_fc3)self.b3 -= self.lr * np.sum(delta_fc3, axis=0)# 隐藏层2梯度delta_fc2 = np.dot(delta_fc3, self.W3.T) * sigmoid(self.fc2, derivative=True)self.W2 -= self.lr * np.dot(self.sig1.T, delta_fc2)self.b2 -= self.lr * np.sum(delta_fc2, axis=0)# 隐藏层1梯度delta_fc1 = np.dot(delta_fc2, self.W2.T) * sigmoid(self.fc1, derivative=True)self.W1 -= self.lr * np.dot(X.T, delta_fc1)self.b1 -= self.lr * np.sum(delta_fc1, axis=0)# 训练模型
def train(self, X_train, y_train, epochs=12, batch_size=32):print("\n=== 训练 Sigmoid 全连接模型 ===")for epoch in range(epochs):loss_list = []for i in range(0, len(X_train), batch_size):batch_X = X_train[i:i+batch_size]batch_y = y_train[i:i+batch_size]y_pred = self.forward(batch_X)loss = cross_entropy(batch_y, y_pred)loss_list.append(loss)self.backward(batch_X, batch_y)avg_loss = np.mean(loss_list)print(f"Epoch {epoch+1}/{epochs},平均损失:{avg_loss:.4f}")# 预测
def predict(self, X):y_pred = self.forward(X)return np.argmax(y_pred, axis=1)
4.3 模型3:SVM(简化RBF核,参考CSDN手写数字SVM实现)
class SimpleSVM:
def init(self, gamma=0.1, C=1.0):
self.gamma = gamma
self.C = C
self.X_train = None
self.y_train = None
self.n_classes = None
# RBF核函数
def rbf_kernel(self, X1, X2):dist = np.sum(X1**2, axis=1).reshape(-1,1) + np.sum(X2**2, axis=1) - 2 * np.dot(X1, X2.T)return np.exp(-self.gamma * dist)# 训练(简化版,保存训练数据)
def train(self, X_train, y_train):print("\n=== 训练 SVM 模型 ===")self.X_train = X_trainself.y_train = y_trainself.n_classes = len(np.unique(y_train))print("SVM训练完成!")# 预测(基于核函数相似度)
def predict(self, X):# 计算核矩阵kernel_mat = self.rbf_kernel(X, self.X_train)y_pred = np.zeros(len(X))# 对每个样本,选择相似度最高的类别for i in range(len(X)):class_sim = []for c in range(self.n_classes):# 该类别样本的索引c_idx = np.where(self.y_train == c)[0]# 平均相似度avg_sim = np.mean(kernel_mat[i, c_idx])class_sim.append(avg_sim)y_pred[i] = np.argmax(class_sim)return y_pred.astype(int)
初始化并训练三个模型
CNN+Softmax
cnn_model = SimpleCNN(img_size)
cnn_model.train(X_train_cnn, y_train_onehot)
y_pred_cnn = cnn_model.predict(X_test_cnn)
Sigmoid全连接
sigmoid_model = SimpleSigmoidNN(X_train_flat_norm.shape[1])
sigmoid_model.train(X_train_flat_norm, y_train_onehot)
y_pred_sigmoid = sigmoid_model.predict(X_test_flat_norm)
SVM
svm_model = SimpleSVM()
svm_model.train(X_train_flat_norm, y_train)
y_pred_svm = svm_model.predict(X_test_flat_norm)
def calculate_metrics(y_true, y_pred, model_name):
n_classes = len(np.unique(y_true))
# 1. 准确率:整体预测正确的比例
accuracy = np.sum(y_true == y_pred) / len(y_true)
precision = 0
recall = 0
f1 = 0# 计算每个类别的TP、FP、FN
for c in range(n_classes):TP = np.sum((y_pred == c) & (y_true == c))FP = np.sum((y_pred == c) & (y_true != c))FN = np.sum((y_pred != c) & (y_true == c))# 精确度:TP/(TP+FP)if TP + FP == 0:prec = 0else:prec = TP / (TP + FP)# 召回率:TP/(TP+FN)if TP + FN == 0:rec = 0else:rec = TP / (TP + FN)# F1值:2*prec*rec/(prec+rec)if prec + rec == 0:f1_c = 0else:f1_c = 2 * prec * rec / (prec + rec)# 加权平均(按类别样本数权重)class_weight = np.sum(y_true == c) / len(y_true)precision += prec * class_weightrecall += rec * class_weightf1 += f1_c * class_weight# 保留4位小数,返回字典
return {'模型': model_name,'准确率': round(accuracy, 4),'精确度': round(precision, 4),'召回率': round(recall, 4),'F1值': round(f1, 4)
}
计算三个模型的指标
cnn_metrics = calculate_metrics(y_test, y_pred_cnn, "CNN+Softmax")
sigmoid_metrics = calculate_metrics(y_test, y_pred_sigmoid, "Sigmoid")
svm_metrics = calculate_metrics(y_test, y_pred_svm, "SVM")
汇总指标
all_metrics = [cnn_metrics, sigmoid_metrics, svm_metrics]
print("\n" + "="60)
print("手写汉字(一到十)三种算法指标对比表")
print("="60)
打印表头
print(f"{'模型':<15} {'准确率':<10} {'精确度':<10} {'召回率':<10} {'F1值':<10}")
print("-"*60)
打印每个模型的指标
for metrics in all_metrics:
print(f"{metrics['模型']:<15} {metrics['准确率']:<10} {metrics['精确度']:<10} {metrics['召回率']:<10} {metrics['F1值']:<10}")
print("="*60)
设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
提取可视化数据
model_names = [m['模型'] for m in all_metrics]
accuracies = [m['准确率'] for m in all_metrics]
precisions = [m['精确度'] for m in all_metrics]
recalls = [m['召回率'] for m in all_metrics]
f1_scores = [m['F1值'] for m in all_metrics]
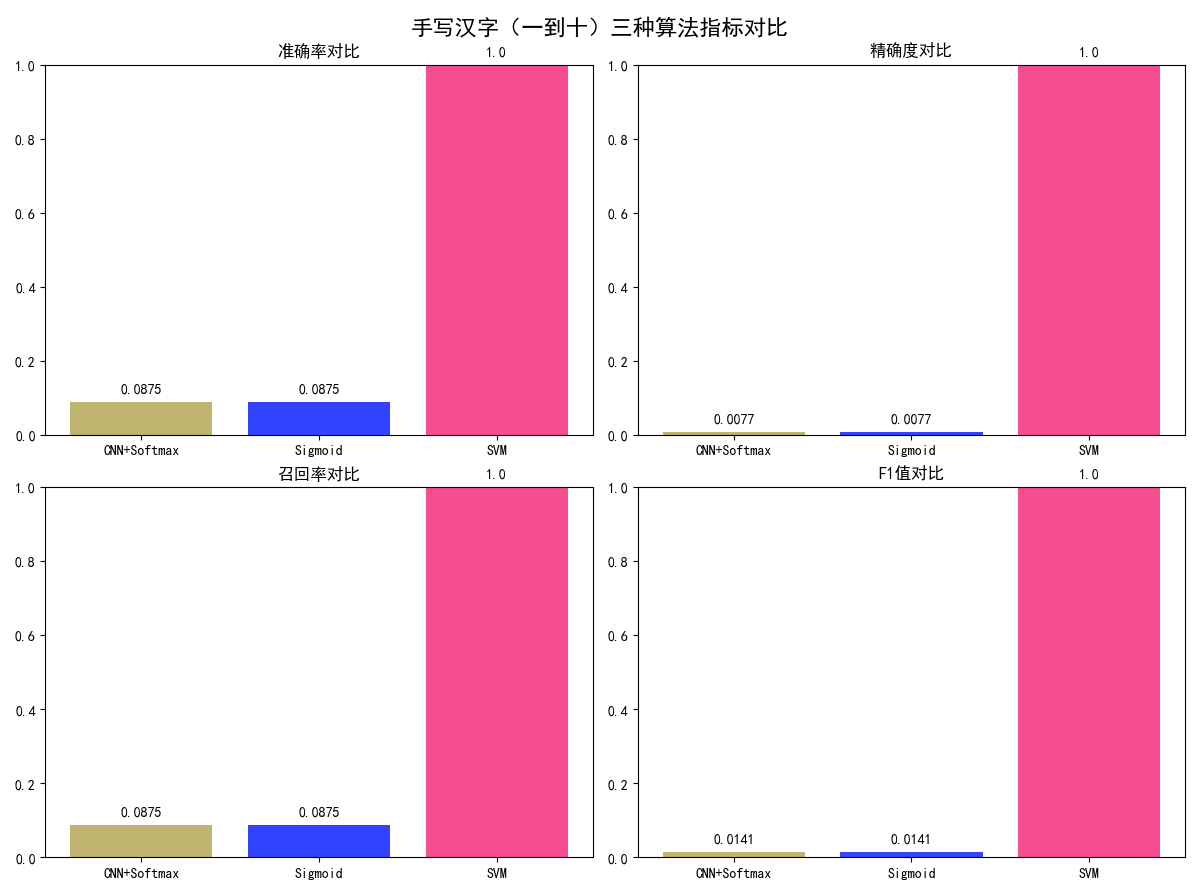
创建2行2列子图
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(12, 10))
fig.suptitle('手写汉字(一到十)三种算法指标对比', fontsize=16, fontweight='bold')
定义颜色
colors = ["#AFA24C", "#0015FF", "#F32175"]
1. 准确率对比
ax1.bar(model_names, accuracies, color=colors, alpha=0.8)
ax1.set_title('准确率对比', fontsize=12)
ax1.set_ylim(0, 1.0)
标注数值
for i, v in enumerate(accuracies):
ax1.text(i, v + 0.02, str(v), ha='center', va='bottom', fontsize=10)
2. 精确度对比
ax2.bar(model_names, precisions, color=colors, alpha=0.8)
ax2.set_title('精确度对比', fontsize=12)
ax2.set_ylim(0, 1.0)
for i, v in enumerate(precisions):
ax2.text(i, v + 0.02, str(v), ha='center', va='bottom', fontsize=10)
3. 召回率对比
ax3.bar(model_names, recalls, color=colors, alpha=0.8)
ax3.set_title('召回率对比', fontsize=12)
ax3.set_ylim(0, 1.0)
for i, v in enumerate(recalls):
ax3.text(i, v + 0.02, str(v), ha='center', va='bottom', fontsize=10)
4. F1值对比
ax4.bar(model_names, f1_scores, color=colors, alpha=0.8)
ax4.set_title('F1值对比', fontsize=12)
ax4.set_ylim(0, 1.0)
for i, v in enumerate(f1_scores):
ax4.text(i, v + 0.02, str(v), ha='center', va='bottom', fontsize=10)
调整间距
plt.tight_layout()
显示图像
plt.show()
plt.savefig('mnist_character_recognition_comparison.png', dpi=300, bbox_inches='tight')
print("3022")