此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第四课第三周的课后习题和代码实践部分。
1.理论习题
【中英】【吴恩达课后测验】Course 4 -卷积神经网络 - 第三周测验
习题都较为简单,就不再多说了,还是把重点放在下面的演示部分。
2.代码实践
YOLO车辆识别实战
同样先摆上这位博主的链接,在这周的编程作业中,这位博主手动构建了YOLO网络及其各个组件,非常详细,但同样因为 Keras 如今已经被 TF 的集成,如果要进行相应实践,需要调整相应的导库代码和一些方法的调用。
我们仍然使用较成熟的框架来演示一下 YOLO 算法,只是这次我们既不用 PyTorch ,也不用TF。
我们这次要使用的库叫做 ultralytics,是 YOLO 官方团队维护的 Python 包。
无论是使用 YOLO 进行学术实验,还是竞赛打榜,ultralytics 都被广泛使用,如果说 PyTorch 和 TF 提供的是造模型的积木,那么 ultralytics 就是针对 YOLO 算法的专精机器。
你可以直接通过 pip 安装这个包:
pip install ultralytics
ultralytics 毕竟是一个首次使用的全新库,因此,本篇我会使用一个极小的 demo 数据集,主要演示一下 ultralytics 的使用流程。
2.1 demo 数据集:COCO8
在目标检测领域,COCO(Common Objects in Context) 是目前使用最广泛、影响力最大的标准数据集之一。
它以复杂真实场景为特点,强调多目标共存、小目标比例高以及目标与背景强耦合,长期以来被作为目标检测算法的重要评测基准。
标准的 COCO 数据集规模庞大,仅 2017 版本就包含超过 11 万张训练图像,覆盖 80 个常见物体类别,完整下载、预处理与训练成本都较高。因此,尽管 COCO 非常适合用于严肃的算法研究与性能对比,但对于初学者上手门槛偏高。

为了解决这一问题,Ultralytics 官方提供了一个用于演示和教学的极简数据集 —— COCO8。
COCO8 本质上是从 COCO 数据集中抽取出的一个最小化子集,在保持 COCO 数据格式与标注规范完全一致的前提下,将数据规模压缩到了极低的水平。目前的 COCO8 仅包含 8 张图像,通常划分为 训练集 4 张、验证集 4 张,并覆盖 COCO 中的若干典型目标类别。
这种设计使得 COCO8 具备两个非常突出的特点:
一方面,它可以在数秒内完成下载,并在极短时间内跑完一次完整的训练流程;另一方面,它又完整保留了真实 COCO 数据集在目录结构、标注格式与训练接口上的一致性。
因此,COCO8 的核心用途并不是训练一个性能良好的检测模型,而是用于:快速验证 ultralytics 的安装与环境配置是否正确、流程是否正常并演示 YOLO 的训练、验证与推理的完整闭环。
需要特别说明的是,由于数据规模极小,COCO8 上得到的指标也不具备统计意义,也不反映模型的实际检测能力。它的价值更多体现在“流程验证”和“使用示例”层面。
2.2 使用 ultralytics 实现 YOLO 算法
先来看这样一段代码:
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
results = model.train( data="coco8.yaml", epochs=50, imgsz=640, batch=16, name="coco8_train", device="cpu"
)
metrics = model.val(device="cpu")
print("mAP50-95:", metrics.box.map)
print("mAP50:", metrics.box.map50)
要说明的是:这就是在 ultralytics 上实现 YOLO 算法的完整代码,包括创建模型、输入数据、模型传播、指标评估甚至包括可视化图表。
是的,这便是 ultralytics 的显著特点,它的封装度极高。
这代表我们使用起来可以较容易地跑通代码,但同时也意味着隐藏了大量细节,想要熟练应用,就要慢慢拆解。
现在,我们就来详细看看这段代码的运行细节:
(1) 模型定义
首先,定义模型:
model = YOLO("yolo11n.pt") # 这里传入的是预训练权重文件名,.pt文件是 PyTorch 的权重格式。
YOLO 是 ultralytics 提供的统一模型接口类,它可以根据传入的参数,加载不同版本的 YOLO 模型(如 YOLOv8、YOLO11 等),它封装了模型的所有关键逻辑。
要说明的是,YOLO 模型权重文件通常遵循如下命名规则:
在 ultralytics 最新版本中,YOLO 模型权重文件通常遵循如下命名规则:
yolo[版本号][模型大小].pt
版本号表示 YOLO 的算法版本或 ultralytics 发布的迭代版本。
模型大小 表示模型的参数量与计算复杂度,也是速度和精度的折中指标:
n= nano → 极小模型,参数少,推理快,适合演示和入门s= small → 小型模型,参数稍多,精度和速度平衡m= medium → 中等模型,精度更高,训练和推理开销也增大l= large → 大模型,高精度,训练和推理成本高x= extra large → 超大模型,精度最高,但训练成本最大
同时,你会发现,只要我们传入 .pt 结尾的权重文件作为参数,那就代表我们使用的是预训练模型。
而如果你希望从头训练自己的模型,就要改变传入参数:
# 从头创建模型,不加载预训练权重
model = YOLO("yolov8n.yaml") # 只指定网络结构 YAML,不是 .pt 文件
(2) 训练方法
了解完模型定义后,现在就来看看传入方法
results = model.train(...)
这一行是整个流程的核心。调用 train() 方法后,ultralytics 会自动完成一次完整的目标检测训练流程。
从宏观上看,这一行代码内部依次完成了以下工作:
- 读取并解析
coco8.yaml数据集配置文件 - 根据配置构建训练集与验证集的数据加载器
- 加载预训练权重并初始化模型参数
- 按照指定的训练轮数执行前向传播、损失计算与反向传播
- 在训练过程中自动记录 loss、mAP 等指标,并生成可视化结果
也就是说,我们在代码中看到的只是一次函数调用,但在其背后,实际上已经包含了一个标准深度学习训练框架所需的完整流程。
下面,我们再展开看看这个方法的参数设置:
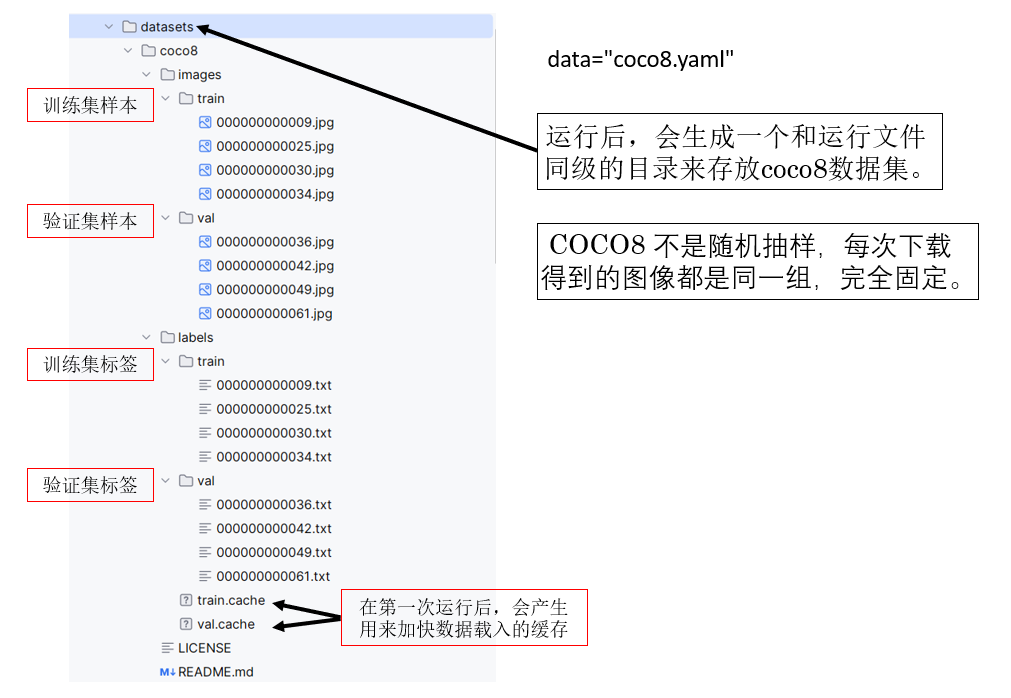
data="coco8.yaml" # Ultralytics 内置的 COCO8 配置,首次运行自动下载数据集
这一参数用于指定数据集的配置文件。
与之前在代码中手动构建 Dataset 和 DataLoader 不同,ultralytics 采用 YAML 文件(你可以理解为专用设定集) 来描述数据集的路径、类别数量以及类别名称。
通过这种方式,模型与数据集实现了解耦: 同一套训练代码可以通过更换 YAML 文件,直接应用到不同的数据集上,而无需修改模型或训练逻辑。
再来看看它的运行时的细节:
继续看下面几个参数:
epochs=50, # 训练轮次
imgsz=640, # 图像大小
batch=16, # 批次大小
name="coco8_train", # 实验名称
device="cpu" # 如果有 GPU 用 0,或 "cuda";无 GPU 用 "cpu"
这些我们都比较熟悉了,要专门说的一点是:
name="coco8_train" 指定了本次训练实验的名字,ultralytics 会根据这个名字创建一个文件夹来保存训练输出。每个实验名对应一个独立的训练结果目录,方便管理。
我们后面展示运行结果时就会再次用到它。
(3)评估方法
同样,这一方法被高度封装:
metrics = model.val(device="cpu") # 默认使用GPU,因此,如果没有GPU,要显式指定CPU。
print("mAP50-95:", metrics.box.map)
print("mAP50:", metrics.box.map50)
这是 ultralytics YOLO 提供的验证接口, 它在内部做了这些关键步骤:
- 读取并加载验证集:如果有缓存(
.cache文件),会加快数据载入。 - 模型前向传播:自动使用非极大值抑制筛选重复框。
- 计算指标:返回的
metrics对象中包含了不同类型的指标数据。
于是,我们便可以直接打印 metrics 对象中的指标。
现在,了解了框架本身后,我们来看看运行效果和其过程中的细节。
2.3 在 coco8 上运行 YOLO 算法
YOLO 的模型时至今日仍在不断地更新,我们使用的 YOLOv11 的网络结构如下:
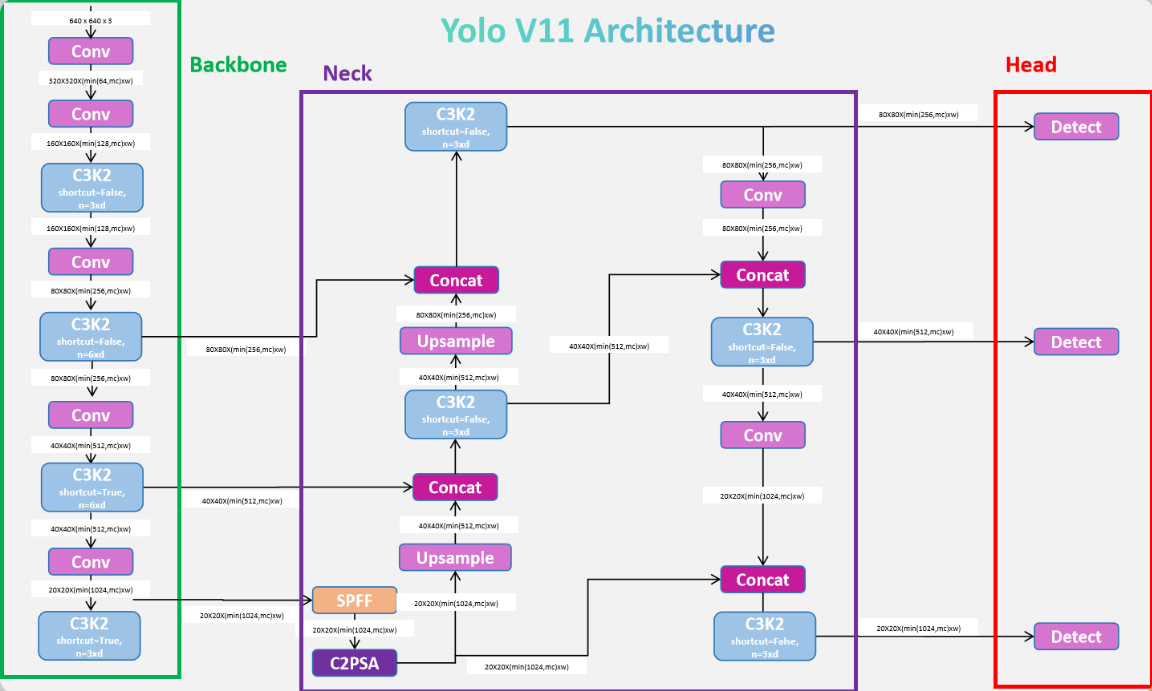
它集成了很多的先进技术,非常复杂,目前阶段,我们理解 YOLO 算法的基础原理就好。
现在,我们来看看代码的运行过程:
(1)控制台输出内容
当代码成功开始运行后,你会发现在轮次信息前,控制台就输出了很多内容。这些其实是在训练开始时的标准日志,它主要是在做训练前的准备、模型初始化、数据检查和优化器配置。
我们简单看一看:

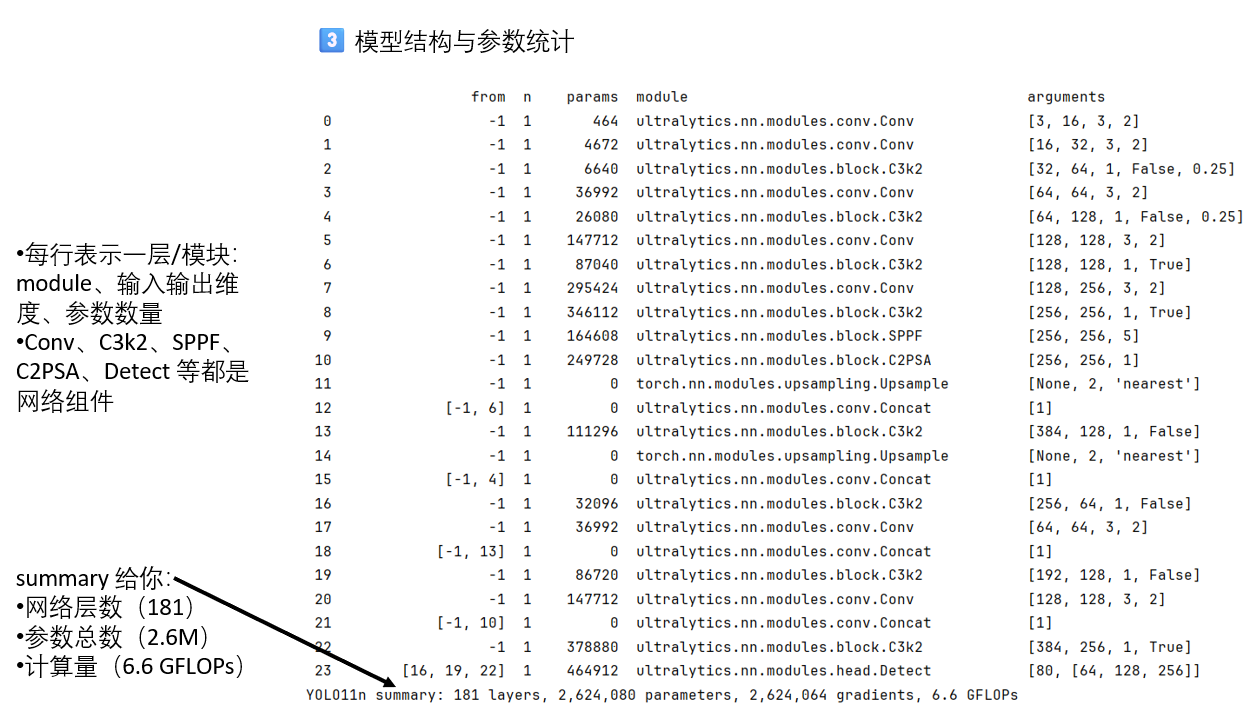

直到这里,模型才完成前期准备工作,开始正式训练。
同样,ultralytics 对训练信息的输出也十分丰富:

别急,还没完,在结束训练后,ultralytics 还会给你做一些”善后和总结“:

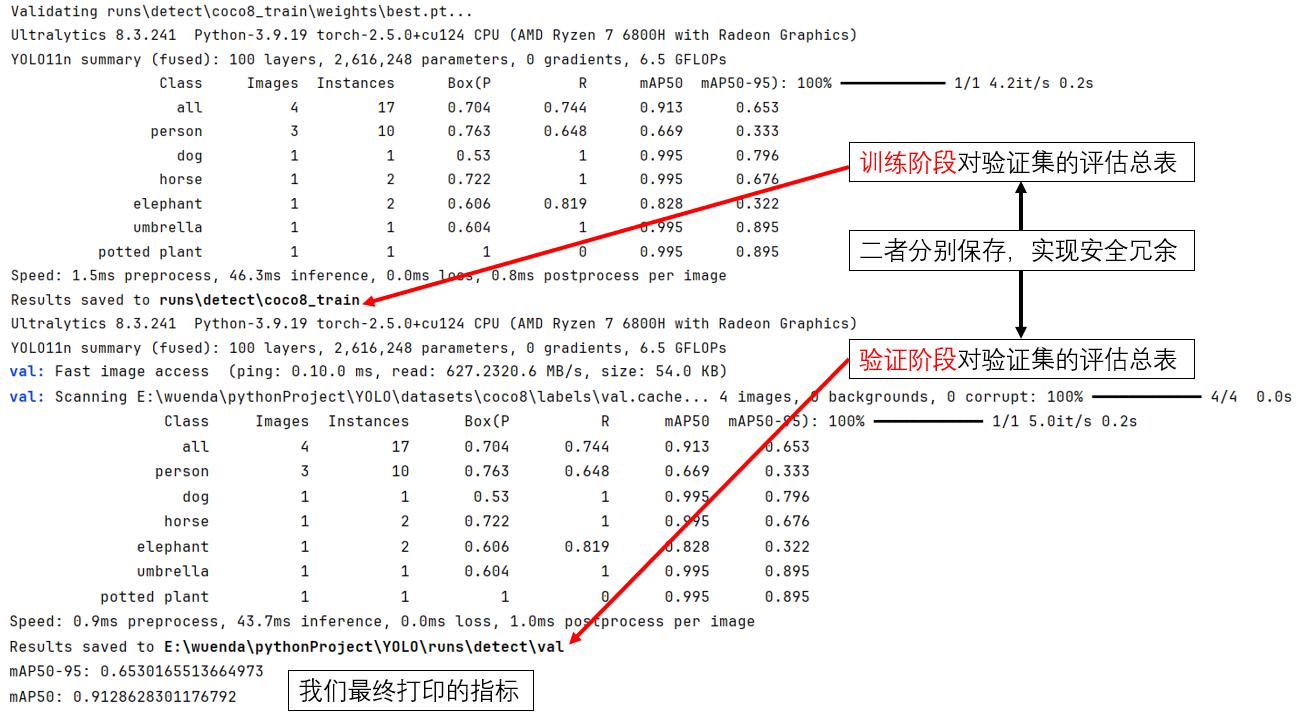
显然,这里的指标较高是预训练的成果。
这一整套下来,你会发现,不同于我们原本自己打印的输出结果,ultralytics 对训练日志的记录和管理非常完备,而且还不仅仅局限于控制台输出。
我们继续往下:
(2)日志文件夹
在完成训练后,你会发现,运行文件的同级目录中新出现了一个名为 runs 的文件夹,这就是ultralytics用来管理日志的文件夹。
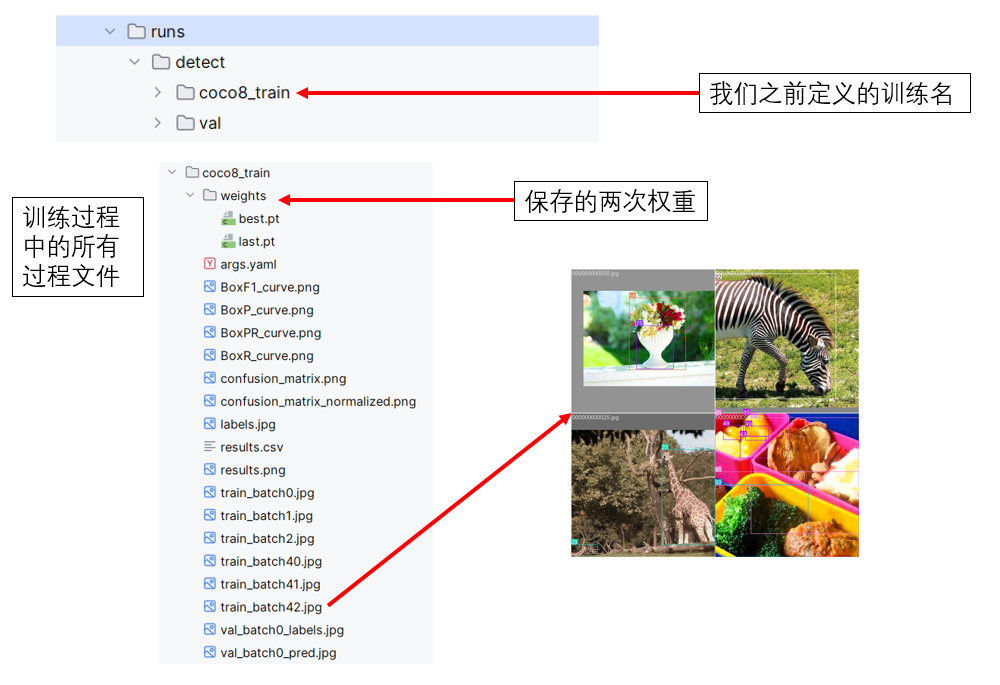
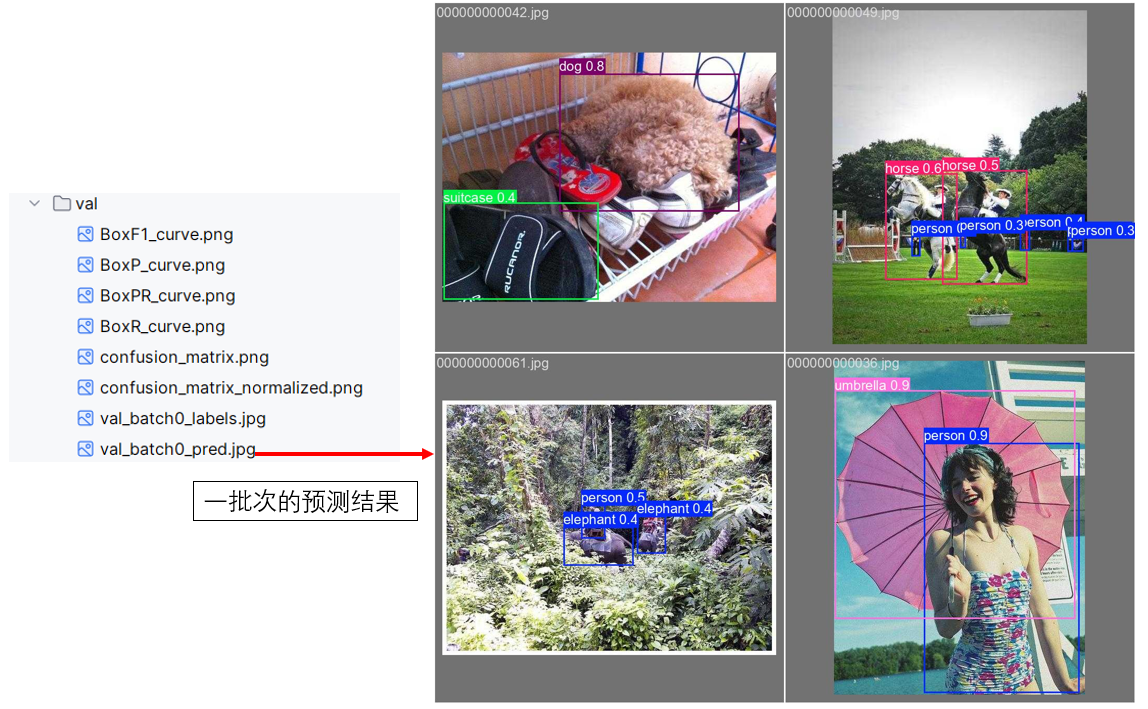
这样的管理方式也更方便我们的溯源和调试。
我们这次实践内容就到这里,实际上,与其说本篇是在演示 YOLO 算法,倒不如说是对 ultralytics 的使用介绍。主要原因是 YOLO 算法作为真正流行的算法,其使用的各项技术和原理已经可以出本书了,我们这里只将其作为计算机视觉中的一个方向来介绍一些基础内容。
实际上还有很多内容可以展开,比如在训练日志里出现的一些专业图表的含义,以及检测任务的几个评估指标,这些我们之后遇到再慢慢说。