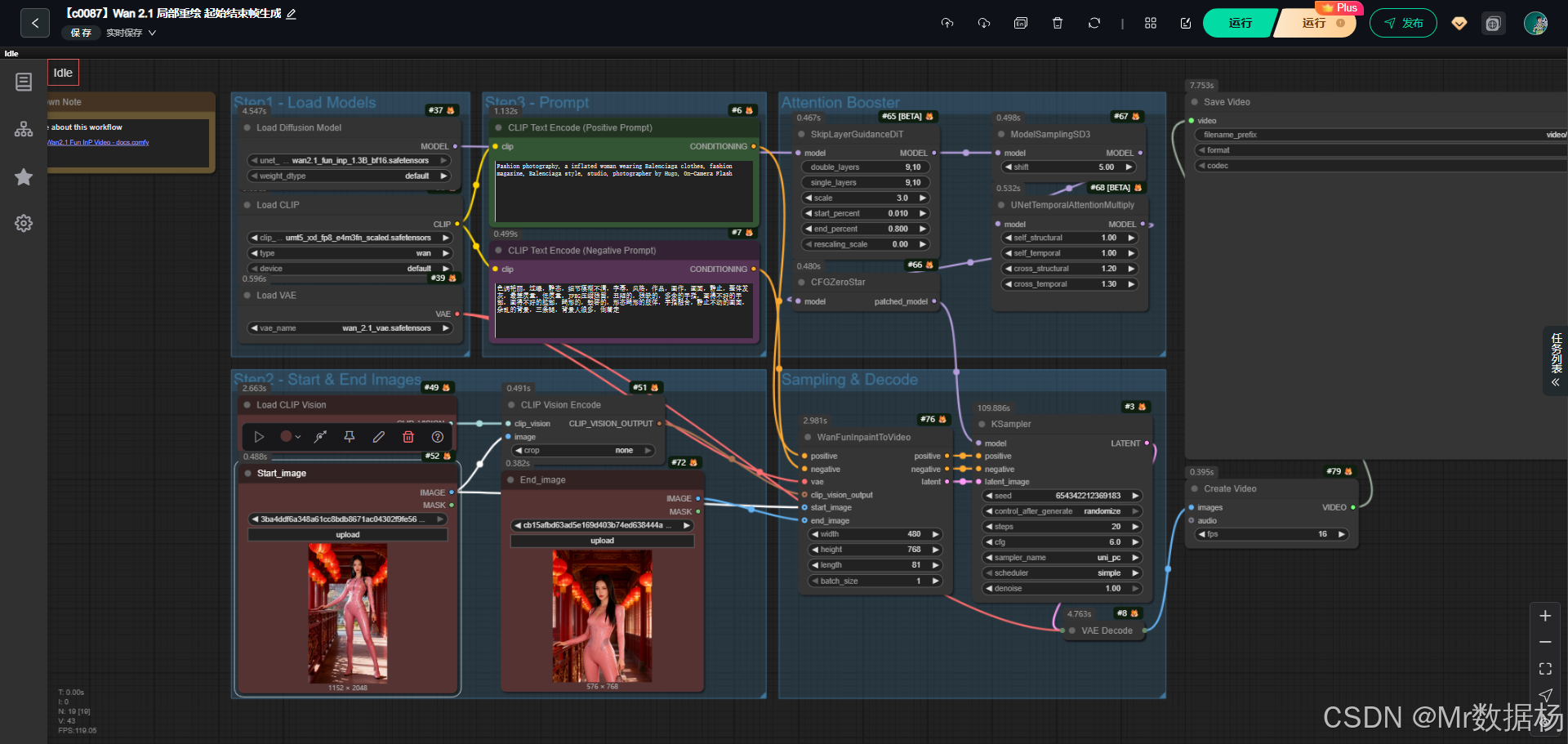
今天演示的案例是一个基于ComfyUI Wan2.1 Fun Inpaint to Video 工作流的完整演示。该工作流通过加载扩散模型、文本与图像编码器以及视频合成节点,将输入的起始图像和结束图像在条件提示的引导下转换为连贯的视频片段。
整体链路清晰地体现了模型加载、提示词处理、采样与解码、以及视频拼接保存的全流程,能够直观展示 AI 在视觉生成领域的综合应用。
文章目录
- 工作流介绍
- 核心模型
- Node节点
- 工作流程
- 大模型应用
- CLIPTextEncode(Positive Prompt) 文本语义驱动的影像生成核心
- CLIPTextEncode(Negative Prompt) 语义排除与画面净化
- CLIPVisionEncode 图像语义特征提取
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
该工作流的逻辑架构围绕核心模型、关键节点和视频生成模块展开。核心模型负责潜变量生成与解码,文本和视觉编码器给出正向与反向的语义控制,采样器则实现从潜在空间到最终图像的转化,终于通过视频拼接与保存节点将生成的多帧内容导出为完整视频文件。此种设计模式保证了用户在处理图像到视频的转换任务时,可以灵活调整提示与控制参数,达到定制化的视觉输出。
核心模型
在这一工作流中,核心模型由扩散模型、VAE 以及文本与视觉编码器共同组成。UNet 扩散模型承担潜变量的生成与推理任务,VAE 负责潜在空间与像素图像之间的解码转换,CLIP 编码器则通过正负提示词的约束提供语义导向。整体模型组合的目标是确保视频在保持一致风格与清晰细节的同时,能够准确响应提示语与输入图像的条件约束。
| 模型名称 | 说明 |
|---|---|
| wan2.1_fun_inp_1.3B_bf16.safetensors | 扩散模型,用于潜变量生成与图像生成核心推理 |
| wan_2.1_vae.safetensors | VAE 模型,负责潜变量与像素空间的互相转换 |
| umt5_xxl_fp8_e4m3fn_scaled.safetensors | 文本编码器,处理提示词信息并转化为条件输入 |
| clip_vision_h.safetensors | 视觉编码器,分析输入图像特征并提供条件约束 |
Node节点
节点的组合实现了从数据输入、模型推理到视频输出的完整链路。CLIPTextEncode 节点负责处理正负提示词并生成语义条件,WanFunInpaintToVideo 节点整合起始图像与结束图像并生成潜变量流,KSampler 通过采样器在潜空间内进行推理并传递结果,VAEDecode 将潜变量解码为可视图像,CreateVideo 和 SaveVideo 则把图像序列整合并输出最终视频文件。这些节点之间的衔接不仅保证了数据流的顺畅传递,也让用户可以在每一个环节上进行个性化控制。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载核心扩散模型,提供推理基础 |
| VAELoader | 加载并管理 VAE 模型,负责潜变量与图像互转 |
| CLIPLoader | 提供文本编码器加载作用 |
| CLIPVisionLoader | 加载视觉编码器,用于图像条件输入 |
| CLIPTextEncode (Positive / Negative) | 对提示词进行正负向语义编码 |
| WanFunInpaintToVideo | 融合文本提示与起止图像,生成潜变量序列 |
| KSampler | 在潜变量空间内执行采样推理 |
| VAEDecode | 将潜变量解码为高清图像帧 |
| CreateVideo | 将多帧图像拼接成视频 |
| SaveVideo | 输出最终视频文件 |
工作流程
该工作流的执行环节以模型加载、图像输入、文本提示、潜变量采样、视频生成和最终保存为核心脉络。通过将 UNet、VAE 与 CLIP 模块联合起来,实现了从输入图像到动态视频的无缝衔接。在结构上,工作流利用正负提示词编码提升了生成内容的准确性,同时借助注意力机制模块与采样策略来控制画面细节与动态效果。视频生成环节结合了起始图像与目标图像的过渡处理,从而形成完整的视频片段输出。整体设计保证了处理链路的可视化和可追踪性,适合教学与创作两方面的使用。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 加载 UNet、VAE、CLIP 文本与视觉模型,作为生成的底层框架 | UNETLoader, VAELoader, CLIPLoader, CLIPVisionLoader |
| 2 | 图像输入 | 导入起始与目标图像,为视频过渡提供素材 | LoadImage(Start), LoadImage(End) |
| 3 | 提示处理 | 编码正向和负向提示词,提供生成条件 | CLIP Text Encode (Positive/Negative) |
| 4 | 注意力控制 | 使用多层注意力与 CFGZeroStar 进行生成引导 | SkipLayerGuidanceDiT, UNetTemporalAttentionMultiply, CFGZeroStar |
| 5 | 采样生成 | 基于条件和模型进行潜变量采样 | KSampler |
| 6 | 解码输出 | 将潜变量还原为图像帧 | VAEDecode |
| 7 | 视频生成 | 将连续帧合成为视频,可结合音频输出 | CreateVideo |
| 8 | 结果保存 | 将最终视频保存至指定目录 | SaveVideo |
大模型应用
CLIPTextEncode(Positive Prompt) 文本语义驱动的影像生成核心
这个节点承担着将用户输入的正向 Prompt 转成深度语义向量的任务。它决定生成视频中人物外观、服装风格、摄影氛围、灯光语言等视觉内容。Prompt 写得越清晰,生成的影像越能贴合创作意图。它在本工作流中不仅决定静态画面特征,也直接影响 Wan2.1 Fun Inpaint To Video 的动作过渡与镜头统一性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Positive Prompt) | Fashion photography, a inflated man wearing Balenciaga clothes, fashion magazine, Balenciaga style, studio, photographer by Hugo, On-Camera Flash | 将正向 Prompt 编码为深度语义向量,控制角色造型、时尚风格、灯光氛围与整体画面基调,对后续视频生成具有主导作用。 |
CLIPTextEncode(Negative Prompt) 语义排除与画面净化
该节点将负向 Prompt 转成条件向量,用来过滤不希望出现的杂质画面,例如画质缺陷、多余肢体、过曝、背景杂乱等。它让最终的生成结果更干净、更一致,也能协助 WanFunInpaintToVideo 在帧间运动过渡中保持稳定性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Negative Prompt) | 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走 | 指定要排除的元素,将其编码为负向语义,抑制模型生成错误内容,使视频成片更自然、更干净。 |
CLIPVisionEncode 图像语义特征提取
CLIPVisionEncode 将起始图与结束图的视觉特征编码为视觉语义向量,供 WanFunInpaintToVideo 参考,以实现画面风格一致的“起点到终点”视频过渡。Prompt 指挥方向,而视觉编码则提供实际画面参考,两者共同决定最终视频的风格稳定性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPVisionEncode | none | 提取输入图像(起始图与结束图)的视觉语义特征,为视频流的连续性、风格一致性与结构保持提供参考信息。 |
使用方法
整个工作流基于 Wan2.1 Fun Inpaint To Video,将“起始图”与“结束图”进行语义连贯的视觉过渡,自动生成一段镜头稳定、风格统一的时尚短视频。用户只需提供两张图:开始图与结束图,再加上一段正向 Prompt 用于定义时尚风格和视觉氛围,负向 Prompt 则用于避免画面缺陷。用户替换素材后即可自动生成新的视频,无需手动调整模型结构。
| 注意点 | 说明 |
|---|---|
| 正向 Prompt 要明确 | 有助于控制视频整体风格、人物外观与摄影氛围 |
| 负向 Prompt 不宜忽略 | 过滤错误肢体、画质缺陷和杂乱背景 |
| 起始图与结束图需结构相近 | 结构差异太大会影响视频稳定性 |
| CLIP Vision 图像清晰度重要 | 提高风格一致性和动作过渡自然度 |
| CFGZeroStar、SkipLayerGuidance 会影响视频质量 | 建议使用默认数值,避免破坏模型稳定性 |
| 分辨率与帧数受显存限制 | 分辨率越大,生成时间越长 |
| 音频为可选项 | 仅在需要带声成片时输入音频 |
应用场景
该工作流在多个领域具有实际落地的应用价值。对于数字艺术创作者而言,可以利用它完成从概念设计到动态演示的完整流程,快速产出高质量视觉作品。在影视与广告行业,利用图像过渡生成视频的能力,可以建立风格化转场与动态演绎,从而提升作品的视觉冲击力。教育和科研场景中,该工作流能以清晰的节点链路展示深度生成模型的原理,帮助学习者直观理解 AI 图像与视频生成机制。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 数字艺术创作 | 制作时尚摄影与创意视觉作品 | 插画师、艺术家 | 从图像到视频的动态转换 | 敏捷生成高质量创意成品 |
| 影视与广告 | 构建风格化的视频转场与动态片段 | 视频导演、广告设计师 | 起始与目标画面之间的流畅过渡 | 提升作品表现力与观赏性 |
| 教学与科研 | 展示 AI 视频生成原理与结构 | 教师、研究人员 | 可视化的节点链路与生成结果 | 帮助理解深度生成模型的机制 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境创建,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC软件平台Tauri+Django内容生产介绍和使用
AIGC器具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和采用