今天带来的是一个基于Wan2.1 i2v 模型的 ComfyUI 工作流,它能够将静态图像转化为动态视频。在实际演示中,用户可以利用上传图片、编写正反向提示词并结合 VAE、CLIP Vision 等节点生成具有自然过渡效果的视频,最终还行直接合成并保存完整视频文件。
整个流程紧密结合了图像输入、提示词引导与视频生成环节,使得工作流不仅适合实验性探索,也具备在内容创作与应用场景中落地的可能性。
文章目录
- 工作流介绍
- 核心模型
- Node节点
- 工作流程
- 大模型应用
- CLIP Text Encode (Positive Prompt) 文本语义驱动的核心描述节点
- CLIP Text Encode (Negative Prompt) 质量控制与去噪语义节点
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
该工作流以图像到视频生成(Image2Video)为核心目标,构建了完整的模型加载、提示词控制、视频生成与保存的链路。核心模型的加载保证了对大规模视觉与文本特征的捕捉能力,节点之间的有序衔接让流程更具扩展性与灵活性。整体上,这个工作流既能满足视觉生成的实验需求,也为动画、短视频创作等领域提供了参考案例。
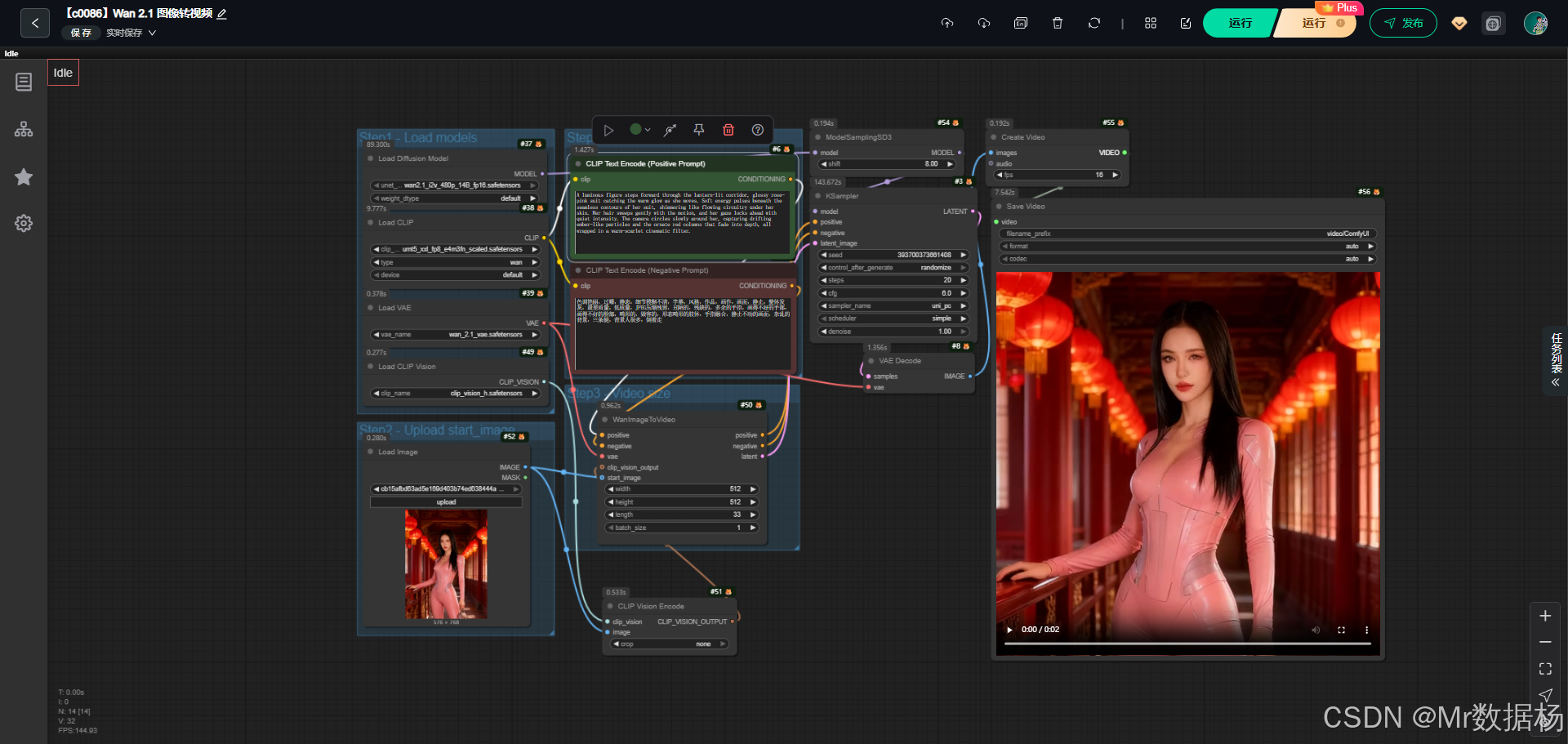
核心模型
在核心模型部分,工作流加载了 UNet 主干模型、CLIP 文本编码器、VAE 解码器与 CLIP Vision 模型。这些模型共同作用,使输入的图像与文本提示词能够有效融合,并通过潜空间解码生成连续的视频帧。UNet 负责图像到潜变量的生成,CLIP 模型负责对文本提示词进行语义引导,VAE 用于潜空间的解码重建,而 CLIP Vision 模型则在图像输入与条件控制中起到关键作用。
| 模型名称 | 说明 |
|---|---|
| wan2.1_i2v_480p_14B_fp16.safetensors | UNet 主干模型,支撑图像到视频的生成过程 |
| umt5_xxl_fp8_e4m3fn_scaled.safetensors | CLIP 文本编码器,用于正反向提示词的语义引导 |
| wan_2.1_vae.safetensors | VAE 模型,负责潜空间的解码还原 |
| clip_vision_h.safetensors | CLIP Vision 模型,用于图像输入的特征提取和条件控制 |
Node节点
工作流的节点设计覆盖了从信息加载、提示词处理到视频生成与保存的全链路。图像加载节点提供了起始输入,CLIPTextEncode 分别对正向与负向提示词进行处理,WanImageToVideo 节点将图像与提示词信息融合为潜变量序列,随后依据采样器与 VAE 解码生成视频帧,再交由 CreateVideo 与 SaveVideo 节点进行最终合成与保存。整体节点间的衔接清晰合理,保证了数据流的高效传递与输出。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载 UNet 模型,为视频生成提供基础网络结构 |
| CLIPLoader | 加载 CLIP 模型,支撑文本提示词的编码处理 |
| VAELoader | 加载 VAE 模型,用于潜空间与图像间的转化 |
| CLIPVisionLoader | 加载 CLIP Vision 模型,提取图像视觉特征 |
| LoadImage | 上传初始输入图像 |
| CLIP Text Encode (Positive/Negative Prompt) | 对正反向提示词进行编码 |
| WanImageToVideo | 将图像输入与提示词结合生成潜变量序列 |
| KSampler | 通过采样器对潜变量进行迭代优化 |
| VAEDecode | 将潜变量解码为可视图像 |
| CreateVideo | 将生成的图像序列合成为视频 |
| SaveVideo | 保存最终生成的视频文件 |
工作流程
该工作流的设计以图像到视频的生成链路为核心,分为模型加载、图像输入、提示词引导、潜空间采样与解码、视频合成与保存几个阶段。每个阶段的节点都有明确分工,模型加载阶段负责将 UNet、CLIP、VAE 等必要组件引入环境,图像输入阶段提供静态图像作为初始素材,提示词引导阶段通过正反向文本条件控制生成效果,潜空间采样与解码阶段保证了图像序列的连续性与质量,最终由视频合成与保存节点将输出组织为完整的视频文件。整体流程条理清晰,既体现了 ComfyUI 模块化拼接的优势,也保证了从输入到输出的完整闭环。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 引入 UNet、CLIP、VAE 与 CLIP Vision 模型,确保后续生成所需的基础能力 | UNETLoader, CLIPLoader, VAELoader, CLIPVisionLoader |
| 2 | 图像输入 | 上传起始图像作为生成的视觉素材来源 | LoadImage |
| 3 | 提示词引导 | 使用 CLIP 文本编码器对正向与负向提示词进行语义编码,为生成提供约束 | CLIP Text Encode (Positive/Negative Prompt) |
| 4 | 视频潜空间生成 | 将图像输入、提示词与 VAE 结合,生成潜变量序列,形成视频的潜在结构 | WanImageToVideo |
| 5 | 采样与优化 | 对潜变量进行迭代优化,确保视频帧的稳定性与细节表现 | KSampler |
| 6 | 解码与还原 | 通过 VAE 解码将潜变量还原为图像序列 | VAEDecode |
| 7 | 视频合成 | 将图像序列合成为视频,拥护帧率设置与音频接入 | CreateVideo |
| 8 | 视频保存 | 将合成的视频文件保存至本地指定路径 | SaveVideo |
大模型应用
CLIP Text Encode (Positive Prompt) 文本语义驱动的核心描述节点
该节点负责将用户输入的正向 Prompt 转换为模型可理解的语义嵌入,用来指导整个 Wan2.1 图生视频流程中的动作生成、视觉基调和角色风格。Prompt 在这里起决定性作用,用户写法越明确,生成视频的动作表现、镜头氛围和画面风格就越稳定。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIP Text Encode (Positive Prompt) | a cute anime girl with massive fennec ears and a big fluffy tail wearing a maid outfit turning around | 将正向 Prompt 编码为语义向量,用于控制角色外观、动作倾向及整体视觉风格,是图生视频生成的核心语义输入。 |
CLIP Text Encode (Negative Prompt) 质量控制与去噪语义节点
该节点编码负向 Prompt,用于限制模型产生不良内容或错误风格。负向 Prompt 的强度会直接影响生成视频的干净程度,例如减少畸形、过曝、模糊、附加手指等问题。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIP Text Encode (Negative Prompt) | 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走 | 将负向 Prompt 转成抑制向量,减少画面噪点、结构错误和异常细节,让视频运动自然、画面干净。 |
使用方法
整个工作流通过输入起始图片与文本 Prompt,实现从静态图向短视频的自动生成。你上传角色起始图后,CLIP 会根据正向 Prompt 生成动作语义,而负向 Prompt 则用于保证风格统一和质量稳定。平台随后利用 WanImageToVideo 将图像转成初始动态潜变量,再交由采样器执行多步推理,生成连续的视频帧。最后由 CreateVideo 与 SaveVideo 自动合成最终视频文件。只要替换起始图或修改 Prompt,工作流就会自动触发新的视频生成,无需额外处理。
| 注意点 | 说明 |
|---|---|
| Prompt 尽量明确 | 模糊描述会导致镜头风格摇摆或动作表现不稳定 |
| 负向 Prompt 建议完整 | 可明显降低畸形、乱影、卡帧、噪点和过曝情况 |
| 起始图要清晰 | 图像越干净,角色重建越准确 |
| 视频尺寸需按需求调整 | WanImageToVideo 的宽高参数会影响视频清晰度和构图 |
| 采样步数决定质量 | 步数越高画面越稳定,但生成时间变长 |
| 若画面偏移可调整 Prompt | 多加入动作、姿态、视觉倾向词,可提升一致性 |
应用场景
该工作流在图像生成与多媒体创作中具有广泛的应用价值。凭借结合图像输入与文本提示词,允许完成静态图像的动态化表现,适合于动画创作、短视频生成、角色动态演示等领域。在社交媒体与数字内容行业中,这样的工作流能够快速将二维素材转化为具有吸引力的动态内容,满足创作者对低门槛视频生成的需求。同时,该流程还能够结合特定音频,实现图像与声音的多模态融合,进一步拓展在广告、虚拟角色展示与教育可视化等场景的使用潜力。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 动画创作 | 将静态图像转化为动态角色视频 | 插画师、动画工作室 | 二次元角色、场景画面 | 生成具备动态效果的短视频片段 |
| 短视频制作 | 在社交平台快速生成视觉内容 | 内容创作者、自媒体用户 | 卡通形象、表情演绎 | 给予个性化、快速的视频生成方案 |
| 虚拟角色展示 | 让角色图像呈现自然动作与转场 | 游戏开发者、虚拟偶像团队 | 游戏角色、虚拟人物 | 实现角色动态演示和舞台化展示 |
| 教育与科普 | 将静态素材转化为动态教学演示 | 教育工作者、科普视频制作者 | 实验原理图、教学插画 | 增强教学内容的直观性与互动感 |
| 多模态创作 | 图像与音频结合生成动态内容 | 音视频创作者、广告团队 | 图像素材配合音频旁白 | 输出具有完整视听效果的视频成品 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
ComfyUI启用教程、构建指导、资源下载
更多内容桌面应用研发和学习文档请查阅:
AIGC应用平台Tauri+Django环境开发,支持局域网使用
AIGC设备平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git计划介绍和使用