作为聚焦实时互动(Real-Time Engagement, RTE)的开发者社区,RTE 开发者社区始终关注人与 AI 在端侧的深度协同。随着端侧模型能力持续增强,「端-边-云」协同架构正加速演进,一个成熟、高效、跨平台的端侧 AI 开发 SDK 已成为行业刚需。
Nexa AI 正是这一趋势的引领者。
我们诚邀你参加 12 月 28 日(周日)上午 11:00~12:00 在「Voice Agent+硬件」微信群举办的 线上快闪 AMA 活动 ,特别邀请 Nexa AI CTO Zack Li 与开发者面对面交流:
-
当前端侧 SOTA 模型部署有哪些困难和解决方案?
-
2026 年哪些端侧 AI 场景最可能爆发?
-
端侧 AI 开发的核心机会在哪里?
-
初学者如何系统学习端侧 AI 开发?
-
Nexa SDK 是如何让同一个 AI 模型轻松跑在手机、电脑、汽车等各种设备上,实现「一次开发,全设备运行」?
参与方式:
添加微信 Creators2022,备注格式为:「一句话个人介绍 + 端侧 AI」。备注清晰者将优先进群。
⚡ 「微信群快闪 AMA」 是一个轻量、轻松、轻互动的开发者交流活动——在约定时间内,大家可直接在群内文字提问,嘉宾将实时答疑。一人提问,全体受益,共同激发高质量的技术碰撞。
带上你的好奇心和问题,周日见!
暴涨 7000+ GitHub Star,一部手机就能跑本地大模型,NEXA SDK 重磅更新
从端侧推理引擎的深度优化,到软硬件协同的模型定制突破,再到全场景解决方案的无缝落地 ——Nexa SDK迎来重磅更新。这一次我们进一步突破手机、PC、汽车、IoT 设备间的算力壁垒,让 “边缘AI推理” 更加触手可及!
欢迎 Star 支持我们的开源项目,每一份认可都是我们前行的动力!
代码:https://github.com/NexaAI/nexa-sdk
文档:https://docs.nexa.ai/cn/nexa-sdk-go/overview
HuggingFace:https://huggingface.co/NexaAI

Nexa SDK 端侧 AI 开发工具包,依托自研 NexaML 引擎,可跨平台深度适配 NPU、GPU、CPU,支持多模态模型 Day-0 落地,以低代码、OpenAI API 兼容特性,助力手机、汽车等设备快速实现高效本地 AI 应用
一、AI 的“最后一公里”在设备端
当下,大模型的战场仍集中在云端。云端虽能提供强大的生成与推理能力,但始终受限于三大核心痛点:
-
依赖 稳定网络 连接,离线场景完全失效;
-
数据需上传至第三方服务器,隐私泄露风险 让金融、医疗等敏感领域望而却步;
-
云端传输带来的延迟,让实时交互类场景(如车载语音、实时翻译)体验大打折扣。
随着芯片技术的爆发式发展,这一局面正在被改写。
无论是手机的 NPU(神经网络处理单元)、PC 的独立显卡,还是嵌入式设备的专用计算芯片,硬件算力的普遍提升为 AI 迁移至“端侧”奠定了基础。用户不再满足于“云端调用”的间接体验,而是渴望将 AI 直接植入日常设备,实现 “数据不出设备、响应无需等待、使用无需付费” 的终极体验。
Nexa SDK就是这样一套 “一站式端侧 AI 推理与部署工具包”,覆盖模型压缩、跨平台适配、快速部署全流程, 旨在解决端侧 AI 开发中的 兼容性、性能优化、易用性 三大核心难题。
其核心价值在于:支持 Hugging Face海量模型格式,兼容从手机到 IoT 设备的全硬件平台,让开发者通过简单命令即可完成复杂模型的端侧部署,真正实现 “一次开发,全设备运行”。
以安卓高通骁龙平台为例,下面视频展示了 Nexa SDK 其图片识别理解、语音识别的多模态能力。
Nexa SDK for Android,由 Nexa AI 与高通合作打造,专为骁龙手机简化端侧AI部署。它可调用 Hexagon NPU(AI核心)、Oryon CPU、Adreno GPU,Granite 4.0-h-350M 模型在 NPU 达 92 token/s,能效为 CPU 9倍。 支持多类模型,含 GPT-OSS-20B(200亿参数,≥16GB RAM骁龙机可端侧运行),且新模型Day-0可用。
详见高通开发者博客:
https://www.qualcomm.com/developer/blog/2025/11/nexa-ai-for-android-simple-way-to-bring-on-device-ai-to-smartphones-with-snapdragon
二、技术深潜——“异构计算”与“全格式支持”
端侧 AI 开发的核心痛点,在于设备生态的碎片化。手机的 Apple A 系列芯片与安卓骁龙芯片架构不同,PC 的 CUDA 与 Metal 平台互不兼容,IoT 设备的低算力环境更是对模型提出苛刻要求。
过去,开发者需为不同设备编写专属代码,适配成本极高,这也成为端侧 AI 普及的最大障碍。
Nexa SDK 给出的解决方案,核心在于“异构计算调度”与“全链路兼容”, NexaQuant 模型压缩技术是第一个支点。
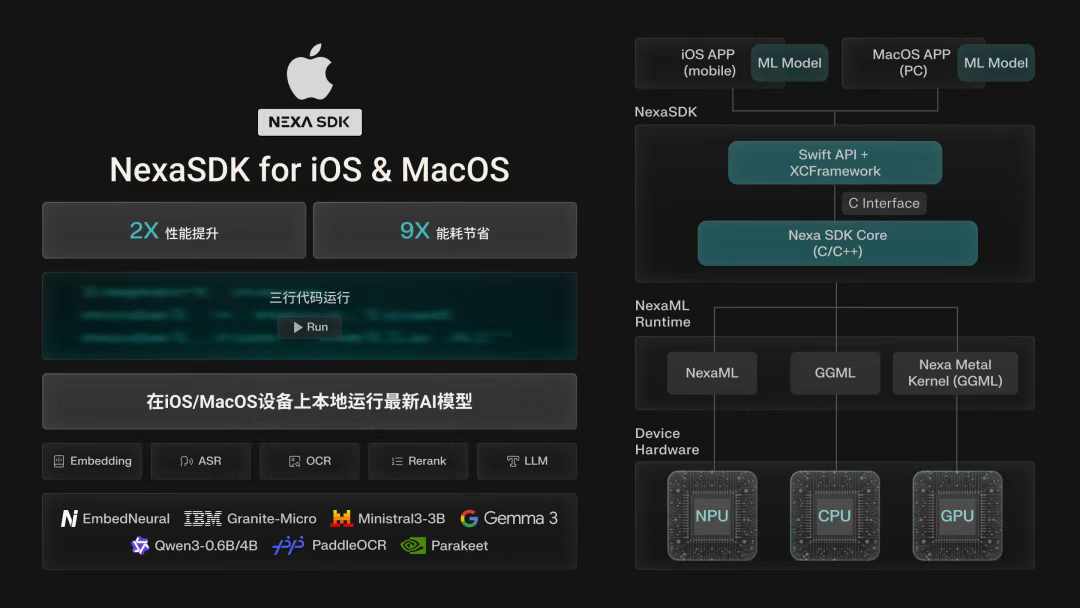
Nexa SDK for iOS & macOS,它能让 iOS 移动设备与 macOS 电脑本地运行最新 AI 模型,不仅实现 2 倍性能提升与 9 倍能耗节省,还只需三行代码即可启动运行,同时支持 Embedding、ASR、OCR 等功能,兼容 EmbeddingNeural、Gemma 3 等框架。
1. NexaQuant:压缩不缩水,让大模型“瘦身”适配端侧
模型体积与性能的平衡,是端侧部署的第一道关卡。即使是 3B 参数的小模型,原始格式也需占用数 GB 存储空间,推理时的内存消耗更是让普通设备难以承受。
NexaQuant 作为硬件感知型多模态模型压缩工具,通过创新的混合精度量化技术,实现了“3 倍速度提升、4 倍存储/能耗节省,同时保证 100%+ 精度恢复”的突破。
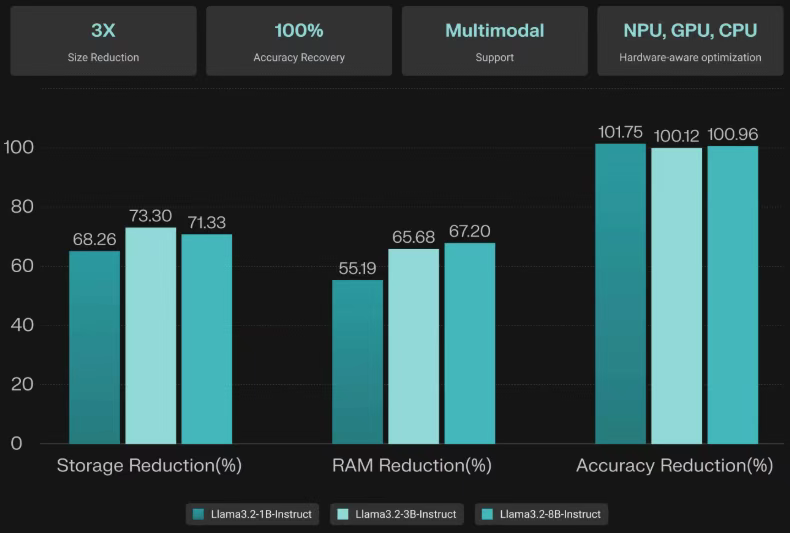
当应用于Llama 3.1/3.2模型(1B、3B和8B参数版本)时,在各项标准评估指标上均达到了原始BF16模型100%的性能。这种相较于基准的轻微性能提升在我们的测试套件中能稳定复现。该技术支持任何基于Transformer的模型,包括处理视觉和音频输入的多模态系统。虽然NexaQuant能够扩展以处理任何规模的模型,但我们针对 10B 参数以下的模型深度优化,发现这一范围是计算效率与实际部署需求之间的最佳平衡点当应用于Llama 3.1/3.2模型(1B、3B和8B参数版本)时,在各项标准评估指标上均达到了原始BF16模型100%的性能。这种相较于基准的轻微性能提升在测试套件中能稳定复现。该技术支持任何基于Transformer的模型,包括处理视觉和音频输入的多模态系统。虽然NexaQuant能够扩展以处理任何规模的模型,但针对 10B 参数以下的模型深度优化是计算效率与实际部署需求之间的最佳平衡点
NexaQuant 其核心优势在于:
-
精度无损压缩:针对 Llama 3.1/3.2 系列模型(1B、3B、8B),NexaQuant 压缩后不仅未降低性能,反而在部分基准测试中实现精度提升——如 Llama3.2-3B-Instruct 经 Nexa Q4_0 量化后,IFEVAL 基准得分从 60.82 提升至 62.77,GSM8K 数学推理得分从 63.92 提升至 64.75。
-
多模态兼容:不仅支持文本模型,还能高效压缩视觉、音频、视频、图像生成类模型。例如,Qwen-VL-2B 经压缩后存储体积从 4.42GB 缩减至 2.27GB, runtime 内存从 4.40GB 降至 2.94GB,却能在复杂文档 QA 任务中保持完美准确率。
-
全硬件适配:压缩后的模型可无缝运行于 NPU、GPU、CPU,兼容 PC、移动端、IoT、汽车、XR 等全场景设备。

借助NexaQuant,将图像生成模型的速度提升4倍,同时保持高质量的输出,从而实现更快、更安全且更注重隐私的创意体验。相较于原始模型(BF16),Nexa压缩后的FLUX.1-dev模型能够实现:原始文件大小的27.9%:23.8 GB → 6.64 GB,所需运行时内存的36%:34.66GB → 12.61 GB。与标准Q4_0量化相比的性能指标:推理速度快9.6倍
2. 异构后端支持:打破设备壁垒,算力自动调度,能耗大幅节省
Nexa SDK 最强大的能力,在于通过底层推理引擎NexaML其对全平台硬件的深度适配,真正实现“一次开发,全设备运行”:
-
跨平台无死角:覆盖手机(iOS/Android)、PC(Windows/Mac/Linux)、嵌入式设备(IoT/XR)、汽车座舱等全场景,无需针对特定系统重构代码。例如,Parakeet v3 ASR 模型通过 Nexa SDK,可同时运行于 Apple ANE(M 系列/A 系列芯片)和 Qualcomm Hexagon NPU,实现跨生态一致体验。
-
硬件智能调度: 自动识别设备算力资源(CPU/GPU/NPU),并针对性优化运行策略。
-
在支持 NPU 的设备(如 Qualcomm SA8295 汽车芯片、Apple M 系列 Mac)上,优先调用 NPU实现低功耗高性能运行,如下视频所示;
-
在无专用 AI 芯片的设备上,则通过 CPU/GPU 优化确保基础体验。
-
全格式兼容: 原生支持GGUF、MLX等主流模型格式,可直接调用 Hugging Face 等社区的海量模型。例如,Qwen3-VL 系列模型通过 Nexa SDK,无需格式转换即可在 Qualcomm NPU(NexaML 引擎)、Apple Silicon(MLX 引擎)、Intel/AMD GPU上高效运行。
-
全模态支持: 整合 LLM(文本)、VLM(多模态)、Vision(视觉)、Audio(音频)、ImageGen(图像生成)等全模态能力,开发者无需分别对接各模态接口,可一站式调用跨模态模型协同工作。
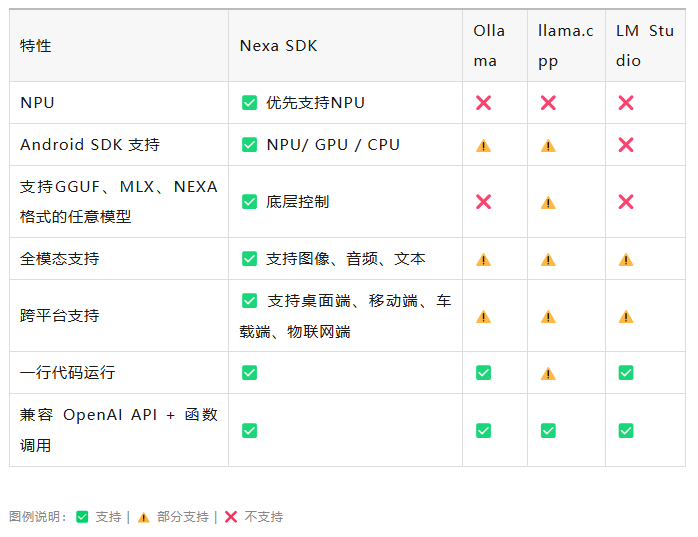
为了更直观、清晰地展示支持的设备与其他框架的比较,给出如下的特性支持表:
三、场景化体验——不仅是聊天,而是“多模态”助手
技术的最终价值,在于落地为可感知的用户体验。端侧 AI 生态,早已超越单纯的文本聊天,延伸至多模态交互、本地知识库、实时场景感知等多元场景。
3.1 移动端:口袋里的“隐私AI管家”——EmbedNeural
假如您的手机相册里存着数千张照片、截图和设计素材,无需联网,用自然语言就能瞬间找到目标——这正是Nexa SDK + EmbedNeural 带来的体验。作为全球首个专为 Apple 和 Qualcomm NPU 设计的多模态嵌入模型,它让手机成为“永不离线的视觉搜索引擎”。
快速体验:两步完成部署
-
步骤1:按照模型卡片上的说明,下载 SDK 并激活token:sdk.nexa.ai/model/EmbedNeural
-
步骤2:参考 GitHub 示例的 README,打开 Gradio 可视化界面

核心亮点
-
毫秒级搜索:如在 5000+ 张图片中搜索“穿西装的猫”,仅需 0.03 秒即可命中结果,远超传统相册的关键词匹配效率。
-
100% 隐私保护:所有图片嵌入处理均在本地完成,数据从未上传云端,彻底杜绝隐私泄露风险。
-
超低功耗:依托 NPU 加速,持续索引和搜索的功耗仅为 CPU/GPU 方案的 1/10,支持 24 小时后台运行而不显著耗电。
-
功能预告:即将推出的视频搜索功能,可通过自然语言(如“查找所有人在笑的片段”)检索本地视频库,进一步拓展移动端 AI 应用边界。
3.2 PC 端:本地“超级大脑”——Hyperlink
对于需要处理大量敏感文档的知识工作者,如律师、金融从业者、医生,基于 Nexa SDK 构建的本地 AI 助手Hyperlink 为PC 端 AI带来了全新体验。这款应用相当于“私有化部署的 Perplexity”,让电脑成为能理解文件、生成洞察的智能伙伴。
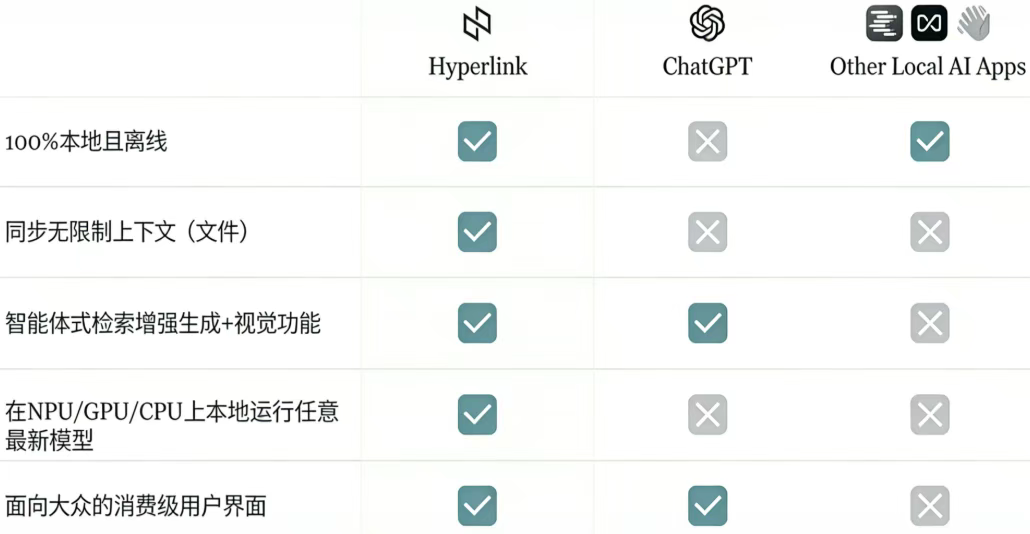
Hyperlink 支持 100% 本地离线、无限制上下文同步、多硬件本地运行最新模型等全功能;
Hyperlink 核心能力包括:
-
无限制本地知识库: 支持索引 PDF、Word、PPT、图片、md等多种格式文件,无文件数量上限(支持 10000+ 文档),超越 ChatGPT(40 个)、NotebookLM(50 个)的云端限制。
-
自然语言问答+溯源: 可回答“总结供应商合同中的合规问题”等复杂查询,生成的答案附带可点击的原文引用,确保信息准确性。
Agentic RAG 推理: 不仅能检索文档,还能跨文件关联信息、发现隐藏规律。在 75 个真实场景测试中,Hyperlink 以 4.2/5 的高分超越 ChatGPT(GPT-5)和 NotebookLM(Gemini 1.5 Pro),成为隐私敏感场景的首选。
-
全离线运行: 无需联网,所有索引、检索、生成过程均在本地完成,既保证数据安全,又避免网络波动影响体验。
下面视频是 Hyperlink 在本地 PC 上部署 gpt-oss-20B 模型,实现本地 RAG:
Hyperlink 下载体验链接:https://hyperlink.nexa.ai/
3.3 全场景多模态:从汽车到 IoT 的“感知大脑”
Nexa SDK 的场景也可以延伸到汽车和IoT领域:
-
车载场景: AutoNeural-VL-1.5B作为首个为 Qualcomm SA8295 NPU 软硬件协同设计的车载 VLM模型 ,可实现座舱内检测、车外环境感知、HMI 理解、视觉+语音交互等功能。其端到端延迟较传统方案降低 14 倍,支持 768×768 高分辨率图像输入,为驾驶安全提供实时智能支撑。
-
IoT 场景: 通过 NexaML 引擎,LFM2-1.2B 等模型可在 Qualcomm IQ-9075 等 IoT 芯片上高效运行, 实现工业场景的异常检测、现场设备的实时指导等功能,解码速度达 45 tokens/秒,满足边缘计算的低延迟需求。
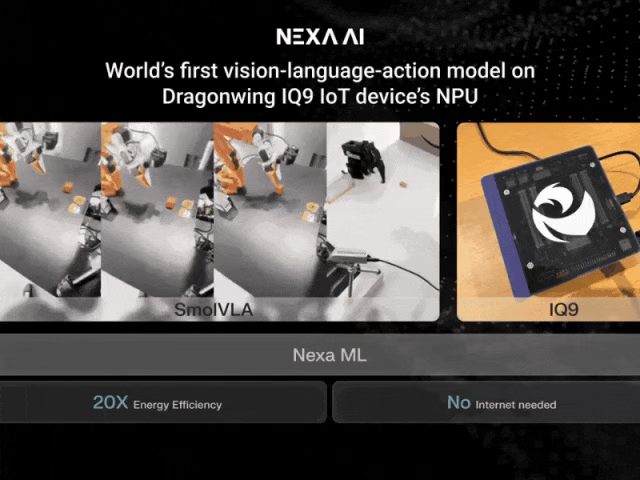
四、从开发者出发,赋能端侧AI开发
Nexa SDK 始终从开发者角度考虑,持续致力于降低端侧 AI 开发门槛。
4.1 零成本迁移:OpenAI API 兼容
开发者无需改变既有的开发习惯,只需将云端 API 请求指向本地 Nexa Server,即可实现从云端到端侧的无缝迁移。无论是聊天交互、函数调用还是多模态处理,都能沿用熟悉的接口规范,迁移成本几乎为零。
4.2 极致易用:一行命令启动模型
Nexa SDK 极大简化端侧 AI 部署的复杂流程,将繁琐的配置、优化、适配工作封装为简单命令:
-
在 Qualcomm NPU 上运行模型:nexa infer NexaAI/Qwen3-VL-4B-Instruct-GGUF
-
在 Apple Silicon 上运行模型模型:nexa infer NexaAI/qwen3vl-4B-Thinking-4bit-mlx
-
更多模型见:https://huggingface.co/NexaAI/collections
这种“开箱即用”的设计,让非专业算法工程师也能快速落地端侧 AI 应用。下面视频展示了通过 NexaCLI 实现 PC 端 38 秒极速安装运行 Qwen模型。
4.3 强大生态:覆盖主流模型与硬件伙伴
1)模型支持
深度适配通义千问系列(Qwen-VL、Qwen-Audio)、Llama 3 系列、GPT-OSS 等主流模型(4/8 bit),同时支持自定义模型的快速接入。
HuggingFace:https://huggingface.co/NexaAI
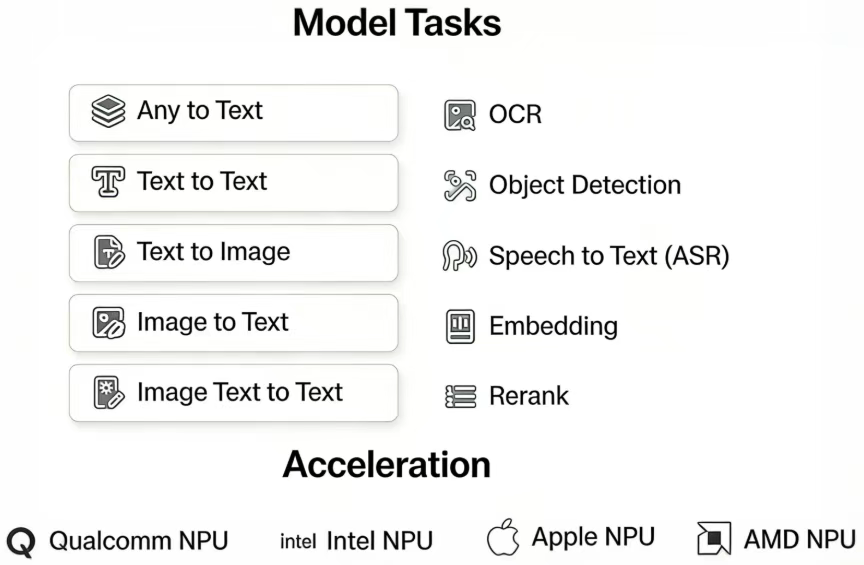
模型能力涵盖了 Any to Text、Text to Text、Text to Image、Image to Text 以及 Image Text to Text 这类不同形式间的转换类任务,也涉及 OCR、目标检测、Speech to Text(ASR)、Embedding 以及 Rerank 这些具体的功能型任务,模型能力涵盖了 Any to Text、Text to Text、Text to Image、Image to Text 以及 Image Text to Text 这类不同形式间的转换类任务,也涉及 OCR、目标检测、Speech to Text(ASR)、Embedding 以及 Rerank 这些具体的功能型任务,覆盖了从形式转换到特定场景处理的不同需求,这些都可以在 Model Hub 上找到。
2)硬件合作与 Qualcomm、Apple、AMD、Intel、NVIDIA 等 芯片厂商深度合作,针对特定硬件优化运行效率。 例如,Hyperlink 借助 Qualcomm Hexagon NPU 的 80 TOPS 算力,实现隐私与性能的兼顾;在 AMD Ryzen AI 平台上,模型解码速度达 51.78 tok/s。
-
Model Hub:https://sdk.nexa.ai/model
3)社区支持
GitHub 仓库(NexaAI/nexa-sdk)提供完整的示例代码、文档和社区支持,开发者可快速获取技术帮助,同时参与生态共建。
-
Nexa SDK Demos:
https://github.com/NexaAI/nexa-sdk/tree/main/demos
-
Nexa Android SDK Demo App:
https://docs.nexa.ai/cn/nexa-sdk-android/overview
写在最后:端侧 AI 的未来已来
随着云端大模型的参数竞赛进入“高投入,低收益”阶段,或许未来的AI将是“贴近用户”的AI——贴近用户的设备、贴近用户的场景、贴近用户对隐私和体验的核心需求。
随着模型压缩技术的持续进步和硬件算力的不断提升,未来的 AI 应用将像手机 APP 一样普及——无需联网、无需付费、随取随用。我们希望通过Nexa SDK,能够让更多开发者参与到这场变革中来。
如果您也想体验端侧 AI 的魅力,不妨前往我们的 GitHub 仓库为 Nexa SDK (https://github.com/NexaAI/nexa-sdk/)点亮 Star,或下载示例代码,用一行命令启动属于你的本地 AI 模型。
我们在GitHub上还发布了有奖征集活动,使用Nexa SDK的优秀应用开发者可以获得1500美元的优质应用奖励,更有 5000美金特别奖励 等待你来领取哦!

端侧 AI 的未来,等待你亲手开启!
如果您有兴趣,欢迎扫码加入我们国内的社群👇


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么
