一文总结 IoTDB 在时序数据建模、双模型融合与跨源分析方面的最新进展!
一文总结 IoTDB 在时序数据建模、双模型融合与跨源分析方面的最新进展!时序数据库 IoTDB 2.0 的树模型与表模型分别有哪些特点与能力?
树/表模型如何实现平滑转换与融合查询?
在未来的联邦查询场景中,IoTDB 又将扮演怎样的角色?
如果你也好奇这些问题的答案,我们将基于 2025 时序数据库技术创新大会上,天谋科技数据库内核研发工程师、Apache IoTDB PMC Member 田原的分享,为您系统解读 IoTDB 在时序数据建模、双模型融合与跨源分析方面的最新进展。
01 时序模型关键概念及 IoTDB 双模型介绍
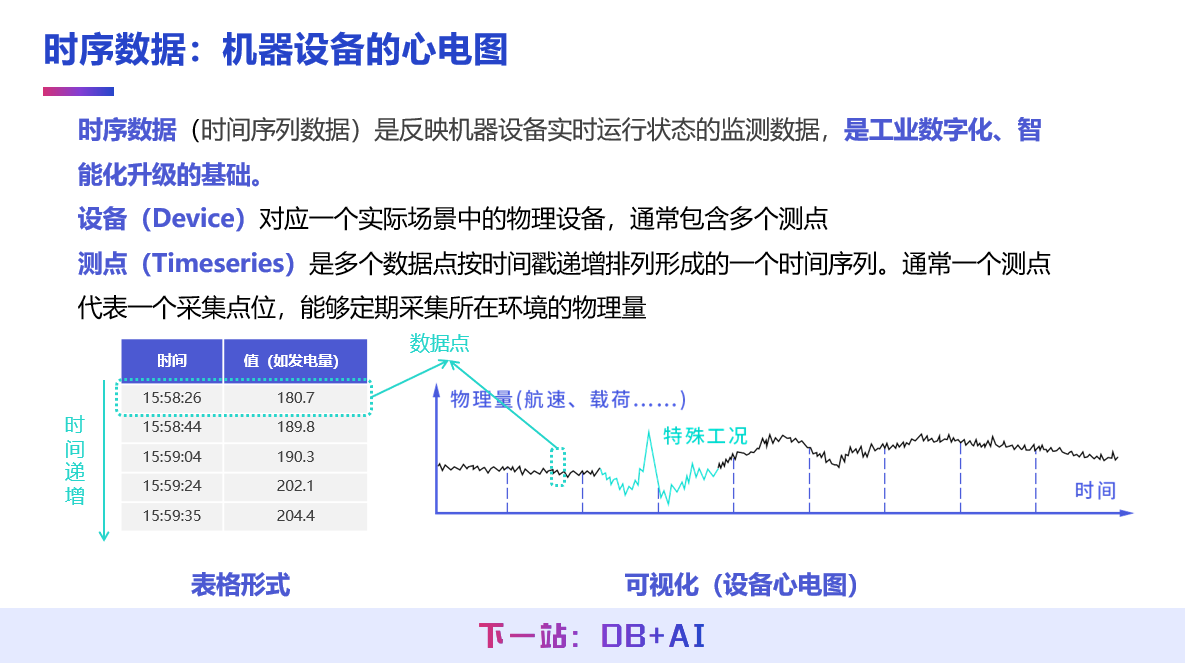
时序数据是反映机器实时运行状态的监测数据,有两个关键要素:一是设备的概念,即实际场景中的物理设备,例如每部手机都有其唯一的序列号作为设备 ID;二是测点的概念,即设备上的具体采集点位,例如手机的陀螺仪可以记录高度或倾斜角。
如果将某个采集点位的数值与对应的时间戳以二维表格形式列出,便构成了时序数据的基本结构。在可视化展示时,通常以时间轴为 x 轴、数值轴为 y 轴进行呈现,其形态类似于医院中的心电图。因此,时序数据在某种程度上可以视为设备的心电图,用以直观反映其运行状态。
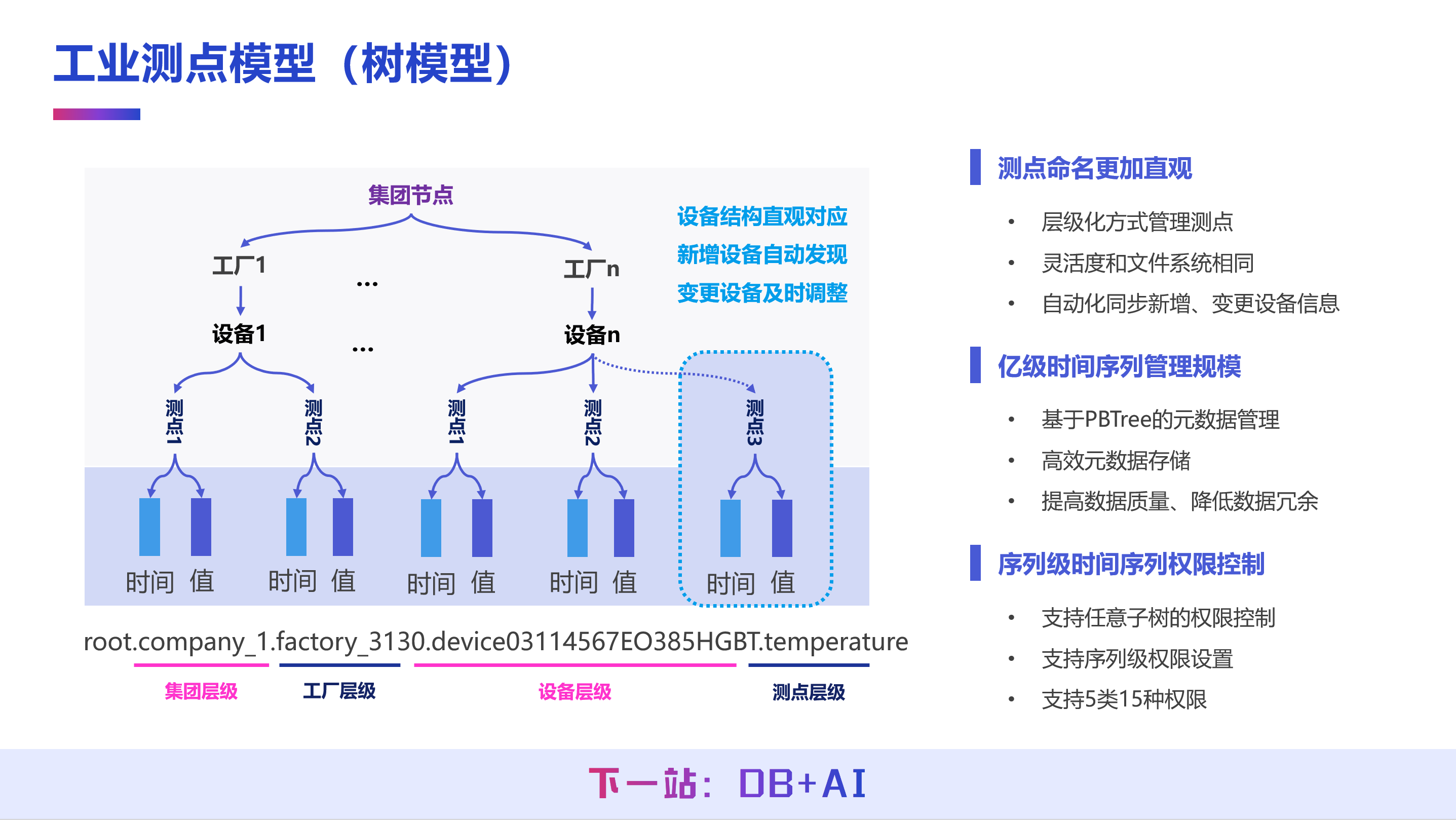
IoTDB 在设计之初就选择了贴近工业采集场景的工业测点模型,这一模型与以 PI 系统为代表,在 SCADA、DCS 等系统使用的核心数据管理范式一致。该模型的主要优势在于其直观的层级结构,上下层之间具有天然的包含关系,能够很好地映射现实世界中许多数据本身所具有的层次化组织方式,从而方便用户进行建模。
此外,为了配合这套树形模型,IoTDB 还设计了相应的简洁 SQL 语法。例如,在 1.X 版本中常用的 select from root.db 查询,正是基于树形结构设计的。这种树模型与简洁 SQL 的搭配,为用户的数据采集和使用提供了很大便利。
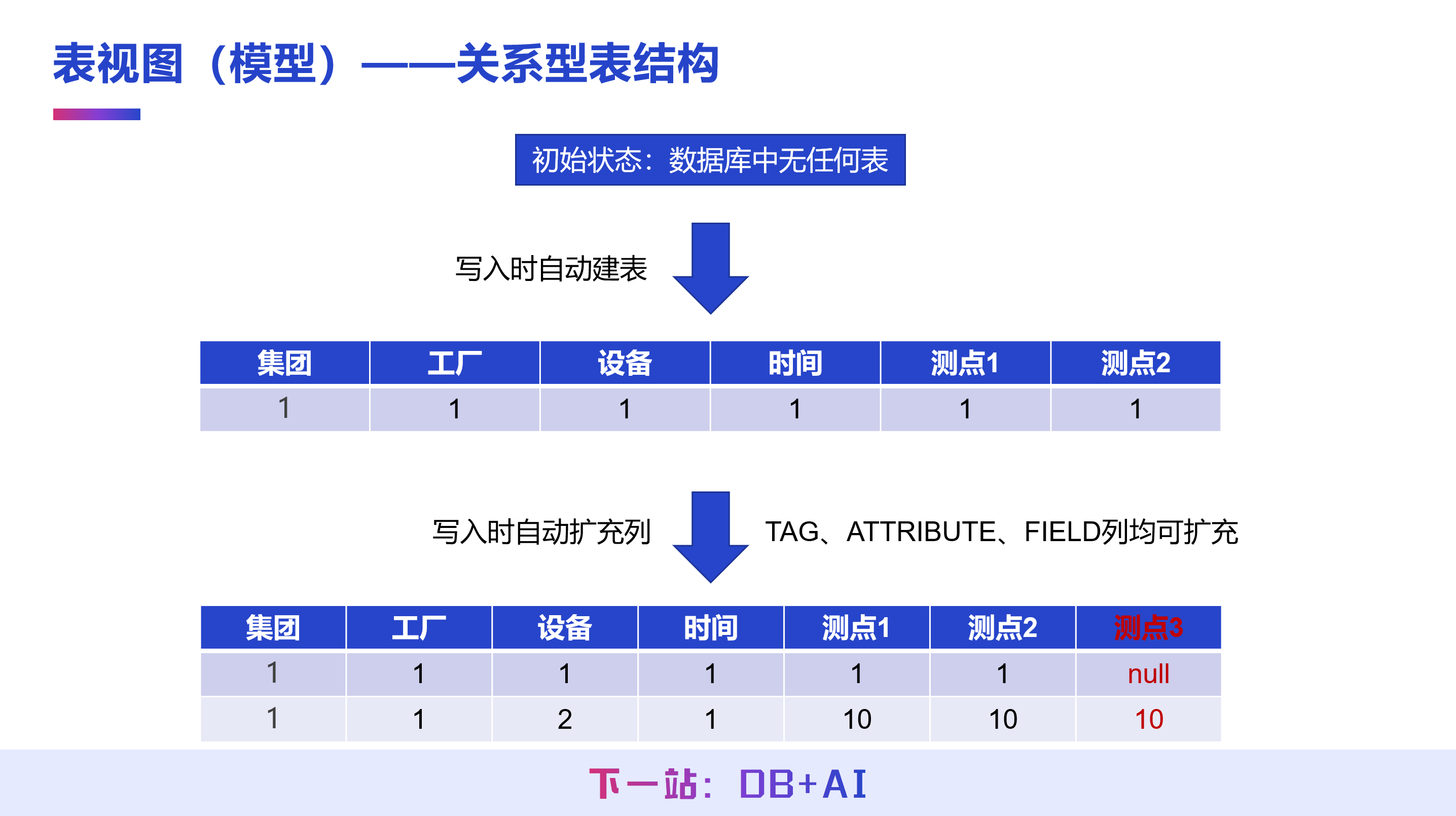
新推出的表模型与树模型的核心差异在于数据结构从树形转变为二维表形式,这使得数据模型更接近常见的关系型数据库,IT 领域用户更容易接受和理解,学习门槛也更低。
然而,与标准关系表有所不同的是,传统关系型数据库需要先创建表才能写入数据,而 IoTDB 支持在工业场景中常见的写入时自动建表需求。同样,传统关系表新增列需执行 ALTER TABLE 操作,而 IoTDB 表模型支持在写入时自动扩展列,包括 TAG、ATTRIBUTE、FIELD 等类型的列均可动态扩充。
在建模视图方面,树模型能够清晰展示“集团—工厂—设备”的层级包含关系,而在表模型中,这种关系只能依赖建模时预设的列顺序来隐含表达。如果建模时列顺序设置不当,就无法依赖列序正确表达层级包含逻辑。
IoTDB 表模型中包含几个核心概念。首先是数据库,用于管理多种类型的设备。其次是时序表,每一张时序表对应一类具有相同测点和相似采集频率的设备。在 IoTDB 表模型中,主键由所有标签(TAG)列与时间(TIME)列共同组成,作为每一行数据的唯一标识。
时序表中的列分为测点(FIELD)列、标签(TAG)列、时间(TIME)列和属性(ATTRIBUTE)列。测点列对应设备上的采集点位;标签列用于唯一定位一个设备;时间列则记录采集时的时间戳;属性列用于对设备进行补充描述,其内容不随时间变化,但也无需放入标签列。例如,一辆车的 car_id 足以唯一定位该车辆,而颜色、型号等属于附加的、相对稳定的描述信息,归为属性列,后续也可能发生变更(如车辆改色)。
在数据筛选效率方面,由于在时间列和标签列上建有稀疏索引,筛选效率较属性列更高。属性列的筛选效率则比测点列更高,因为测点列仅在文件内具有 block 级别的稀疏索引,因此其过滤条件是最严格的。

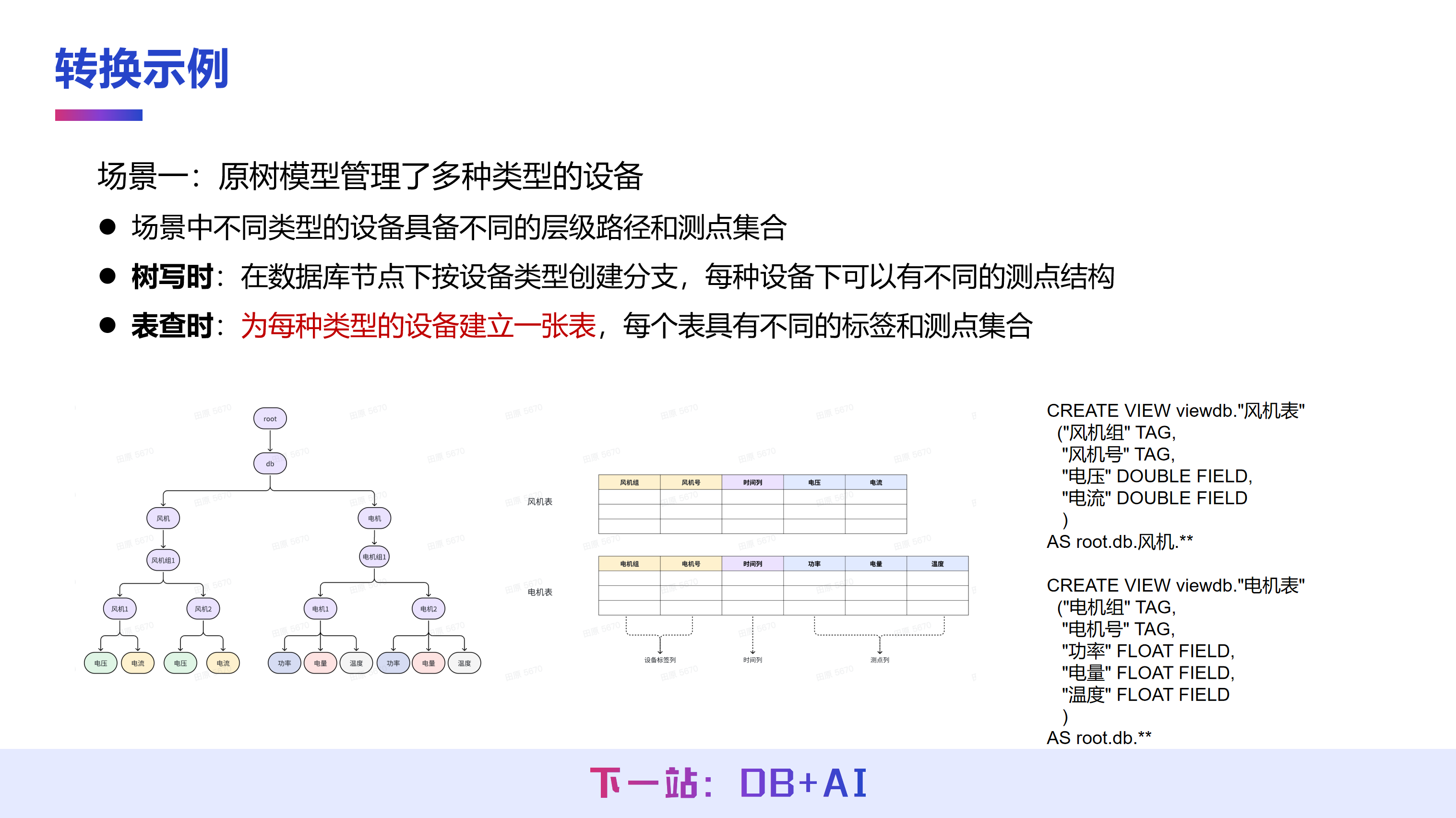
在不同建模场景下,IoTDB 的建模方式可根据实际需求灵活调整。以三种建模场景为例,第一种场景涉及多种类型设备的管理。在 IoTDB 树模型中,需要手动将不同类型的设备分配至不同前缀路径下,例如将风机设备置于某一前缀路径,电机设备置于另一前缀路径,以此实现对不同类数据的分层建模管理。
而在表模型下,只需为不同类型的设备分别创建对应的时序表,例如建立风机设备表和电机设备表即可。这种区分是必要的,因为不同类型设备采集的测点往往不同,通过分表建模能够更清晰、有效地组织和管理数据。
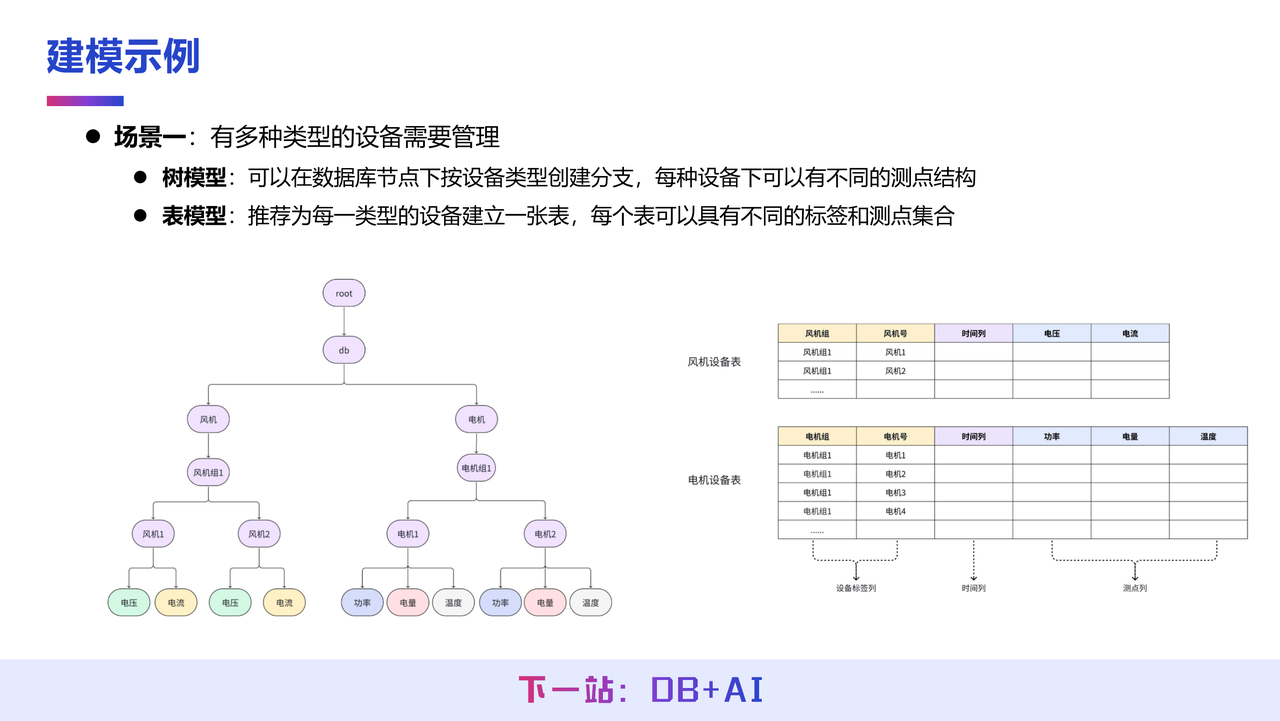
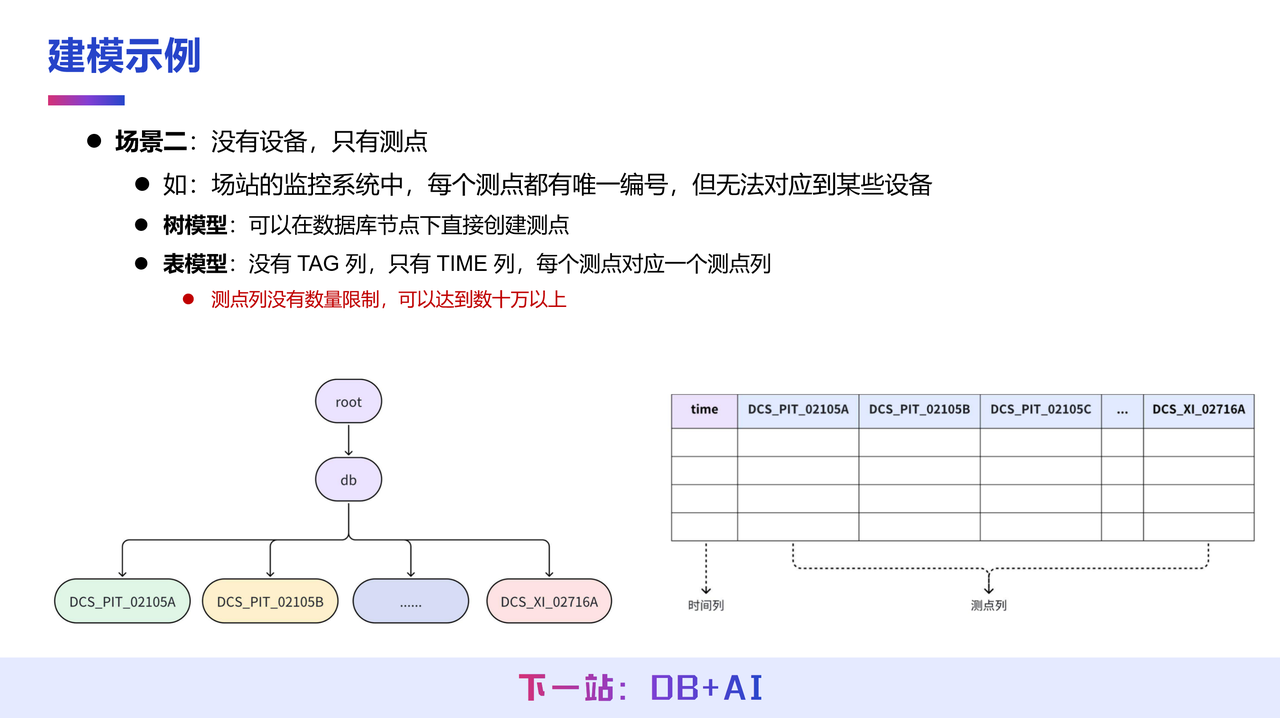
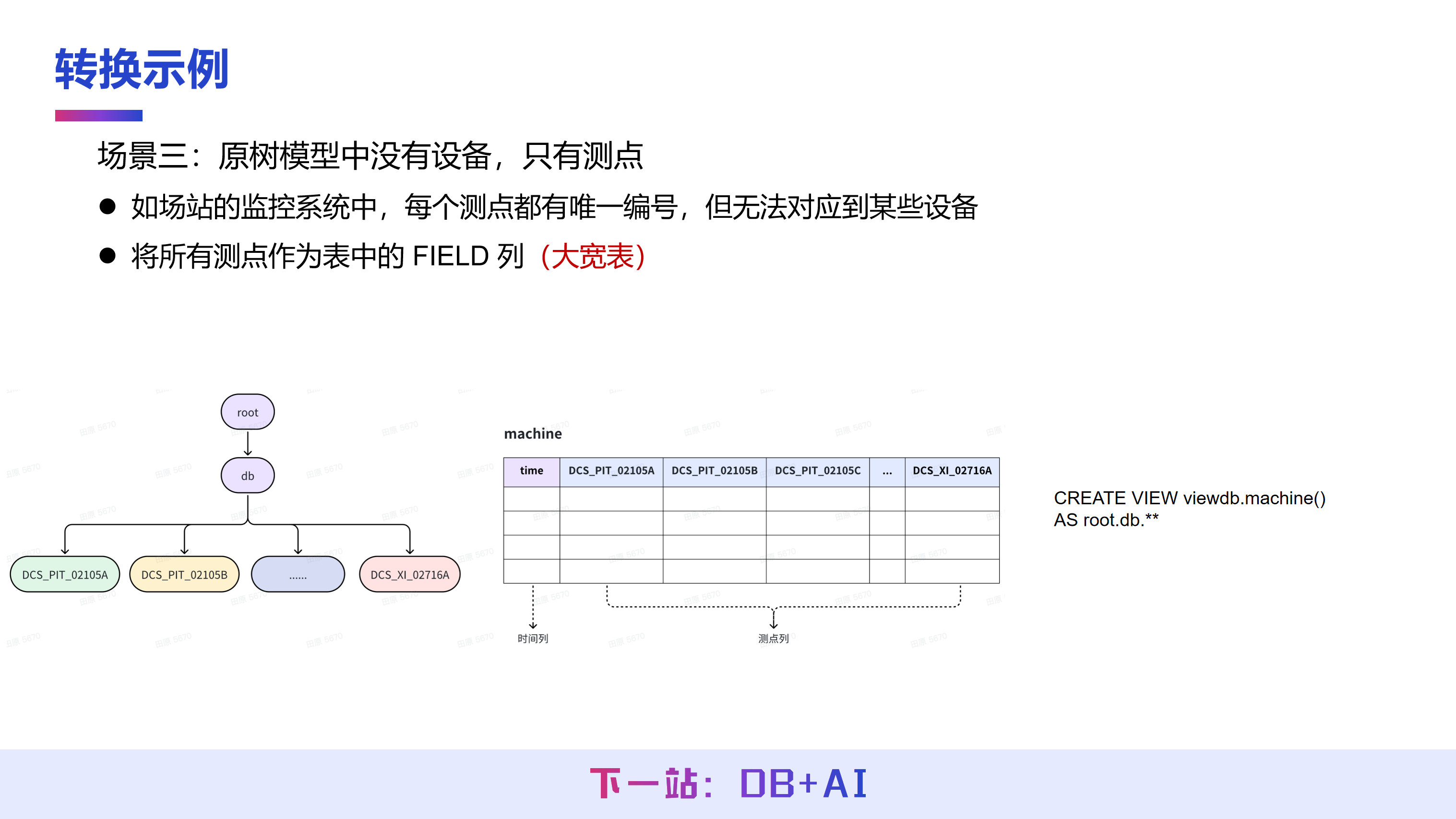
第二种建模场景不具备明确设备概念,这在电力监测或场站监控等场景中较为常见。此类场景中,数据仅通过测点 ID 进行唯一标识,而无法对应到物理意义上的具体设备。
针对该场景,在 IoTDB 树模型中,可以直接在数据库(db)层级下建立测点,无需设置设备层。表模型同样支持这种建模方式,由于设备标签(TAG)列的数量可以是 0 到多列,因此在该场景下可以完全不使用标签列,仅依靠时间(TIME)列和测点(FIELD)列即可完成数据建模。
需要特别强调的是,测点列的数量在 IoTDB 表模型中没有限制,可支持数十万甚至更多,与传统关系型数据库通常存在列数限制(如 1024 列上限)不同,这也是 IoTDB 在设计上的一个重要差异。
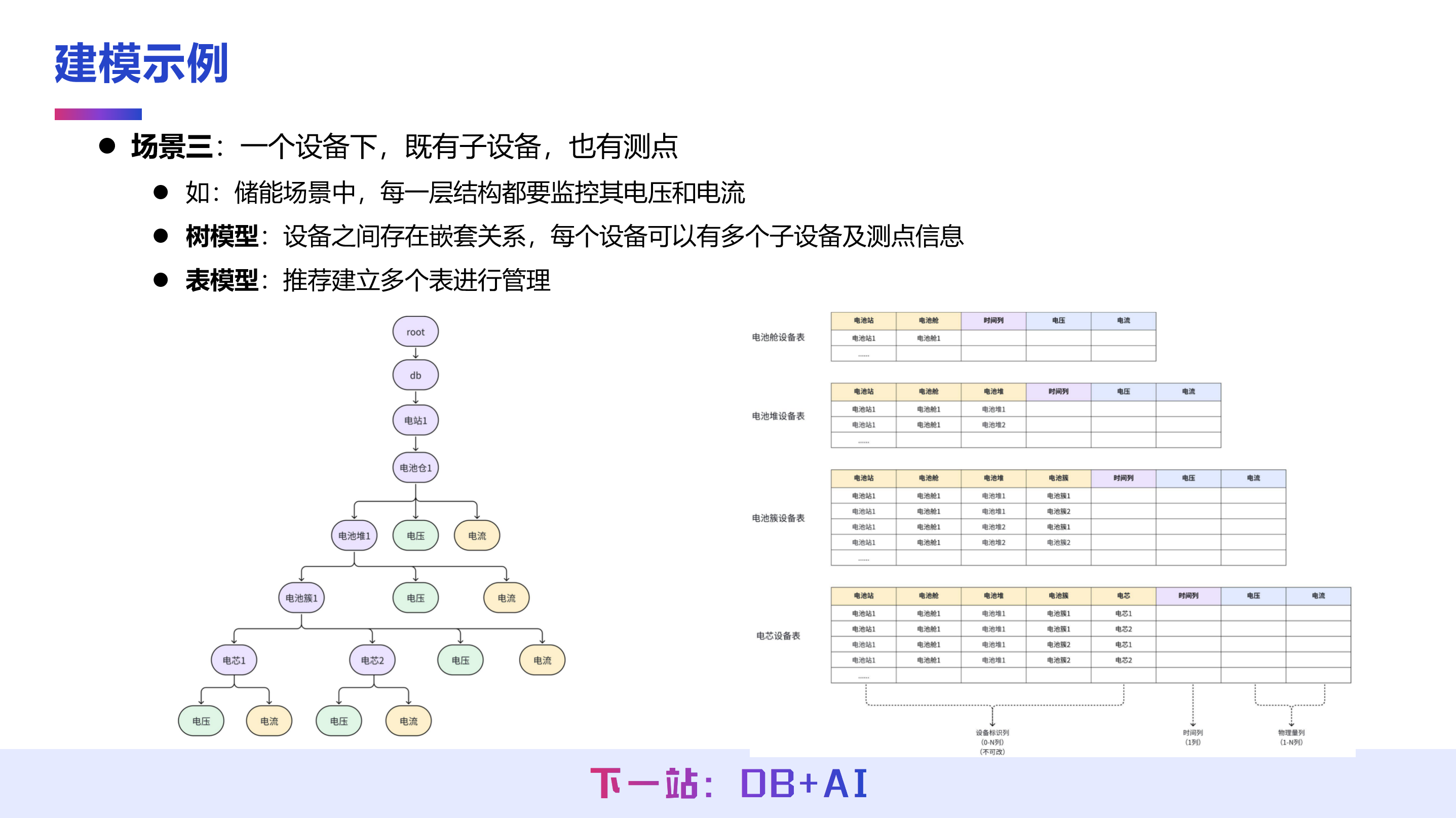
第三种建模场景为设备包含子设备与测点,如储能系统中的监控体系可能包含电站、电池仓、电池堆、电池簇、电芯等主体,每一主体都需要监控其电压、电流等参数。
在 IoTDB 树模型中,这种层级关系可以直观呈现,每一层既可以包含下级子设备,也可以拥有自身的叶子节点(即具体的采集测点,如电压、电流)。
对于表模型来说,尽管电池仓、电池堆、电池簇和电芯采集的测点可能相同,但它们属于不同类型的设备实体。因此,建议将其拆分为四张独立的时序表,通过分表实现清晰的结构化组织。
树、表两种模型各有其适用的场景,这也是为什么 IoTDB 2.0 采用了双模型并行的策略。树模型的优势在于其 SQL 语法较为简洁,因此在简单的查询场景,尤其是短查询中,目前其查询性能仍优于表模型。而表模型则提供了更丰富的高阶分析函数,并且由于兼容标准 SQL,对用户而言学习门槛相对更低,更易于上手。
在实际部署中,同一个 IoTDB 集群实例可以同时使用两种模型,两种模型可以使用不同的语法且彼此隔离,用户可以在同一套实例中根据需求选择更适合的模型进行体验与应用。

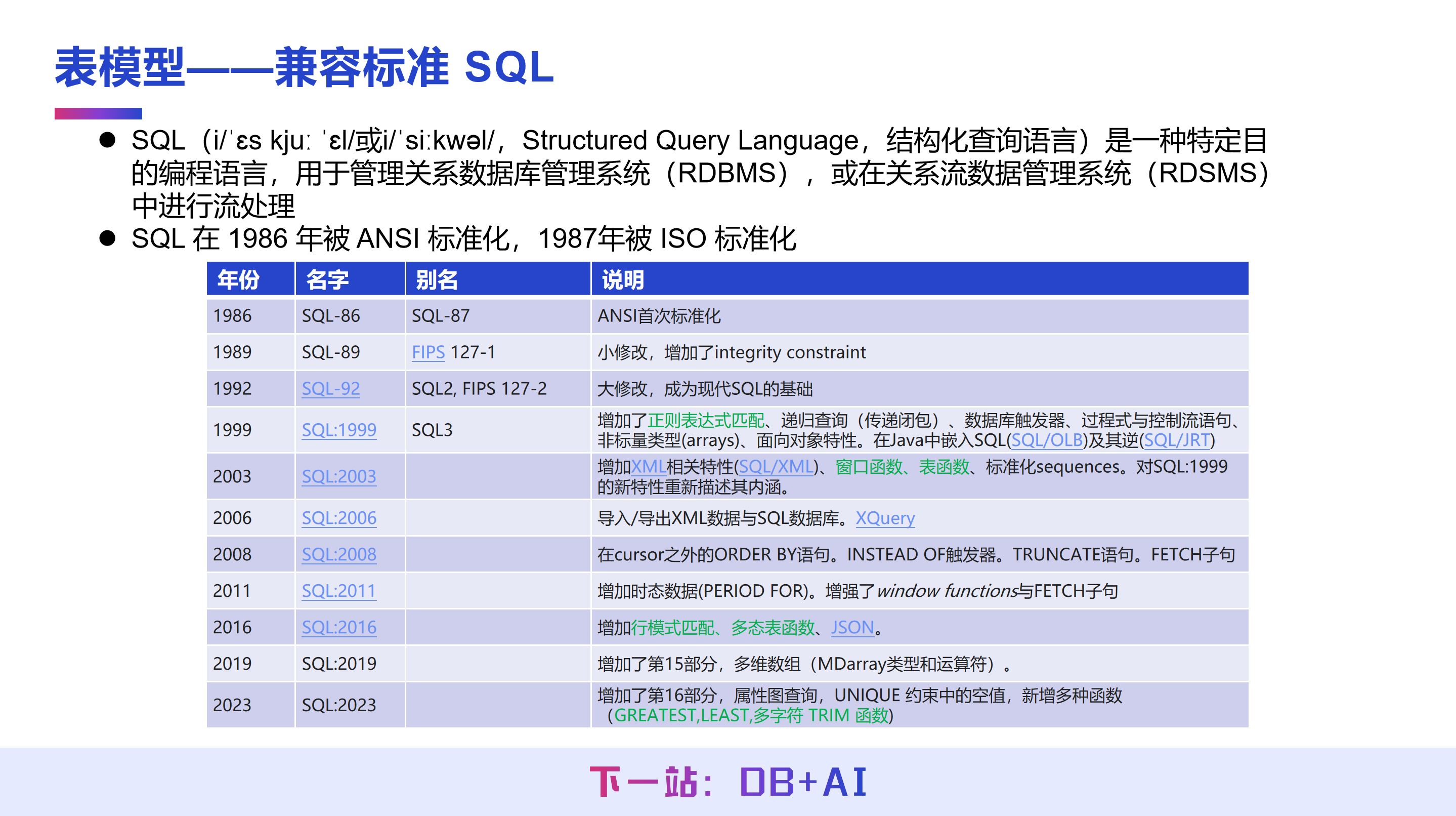
IoTDB 表模型的一个主要特点是兼容标准 SQL,因此特别补充标准 SQL 的相关概念。
标准 SQL 是一种专门用于管理关系型数据库的编程语言,于 1986 年由美国国家标准组织(ANSI)标准化,随后在 1987 年被国际标准化组织(ISO)标准化,最为广泛认知的是 1992 年发布的 SQL-92 版本。目前市面上尚无关系型数据库能够声称完整实现某一版 SQL 标准,通常仅表明“兼容标准 SQL”,即实现了标准 SQL 中的部分功能。
就 IoTDB 而言,SQL-92 中大部分与查询相关、非事务性的语法均已得到支持。同时,IoTDB 也持续跟进并支持后续标准 SQL 版本的重要功能,包括 SQL:2003 中的窗口函数和表函数、SQL:2016 中的行模式匹配及多态表函数,以及 SQL:2023 中的 GREATEST、LEAST、TRIM 等函数。目前 IoTDB 尚未支持的功能主要为 Common Table Expression(CTE)中的递归 WITH 子句,但该功能已被列入后续的迭代计划中。
02 表模型分析能力介绍
IoTDB 2.0 所支持的表模型增强了分析能力,能够实现一些在树模型中难以覆盖的分析场景。以下通过七个典型例子进行具体说明。
第一个功能是统计已录入的数据行数。在表模型中,使用 count() 可以直观地查询表中共有多少行,这完全符合标准 SQL 的语义。而在树模型中,count() 的定义则有所不同。由于树模型在设计之初就将 count() 定义为对匹配到的每个测点列分别统计非空值的数量,因此执行后会返回多列结果,每一列对应一个测点的非空计数。对比之下,表模型的 count() 结果更加直观高效。

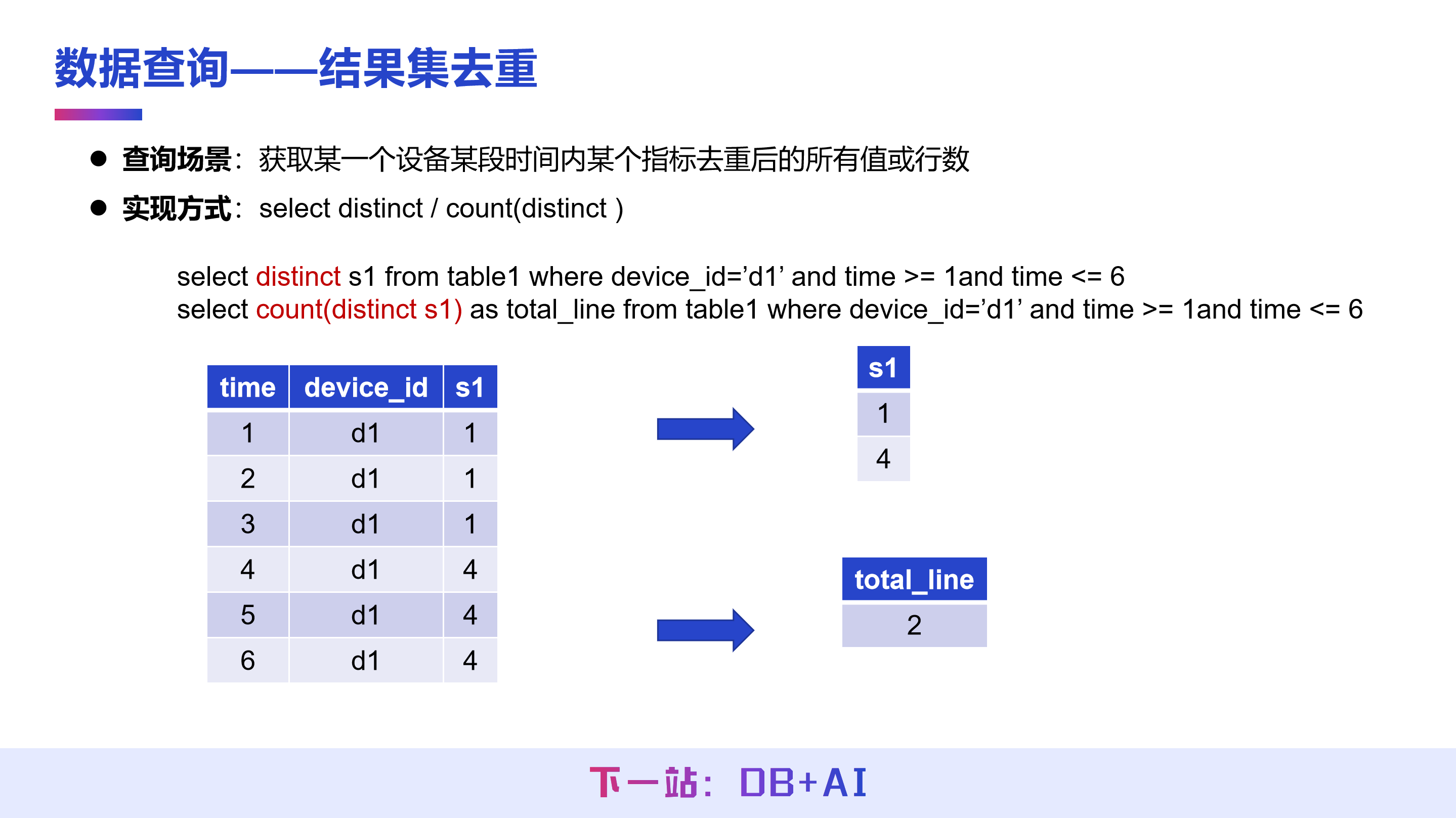
第二个功能是结果集去重。表模型中,去重功能遵循标准 SQL 定义,通过 select distinct 或 count(distinct) 来实现,用于统计特定时间段内某个指标在去重后的所有行数或值。
除了支持标准 SQL 定义的 FULL OUTER JOIN、INNER JOIN、LEFT JOIN 和 RIGHT JOIN 外,IoTDB 表模型还提供了具有时序语义特色的 ASOF JOIN。这一函数引用源于 Python 的 Pandas 库中,主要用于处理时序数据在采集时间上存在细微偏差时的对齐问题。
例如,两列时序数据可能都以一秒为周期采集,但各自采集的起始时刻存在毫秒或微秒级别的差异。若使用标准 SQL 的 JOIN 操作,通常要求时间戳严格相等才能匹配,这会导致大部分行因时间不完全一致而无法对齐。ASOF JOIN 则允许忽略微小的时间误差,按照最近的时间戳进行匹配对齐、关联成一张表,更贴合时序数据分析的实际需求。

第四个功能是子查询。树模型在设计初期主要面向 OT 领域用户,他们的应用场景较少涉及复杂的查询分析需求。因此,树模型将 FROM 子句定义为基于树形结构的前缀路径模式,查询结果无法作为另一个查询的输入直接嵌套到 FROM 中,难以实现子查询。
而在表模型中,由于采用了标准表结构和 SQL 语法,因此能够支持包括关联子查询、非关联子查询中的标量子查询等多种子查询形式,满足了更复杂的数据分析需求。

第五、六个功能是窗口函数和多态表函数,这两者都属于标准 SQL 中的函数分类。标准 SQL 函数分类主要包含标量函数、聚合函数、窗口函数、表函数、多态表函数等类型。其中,多态表函数是表函数的增强版本,因此 IoTDB 选择直接支持多态表函数。

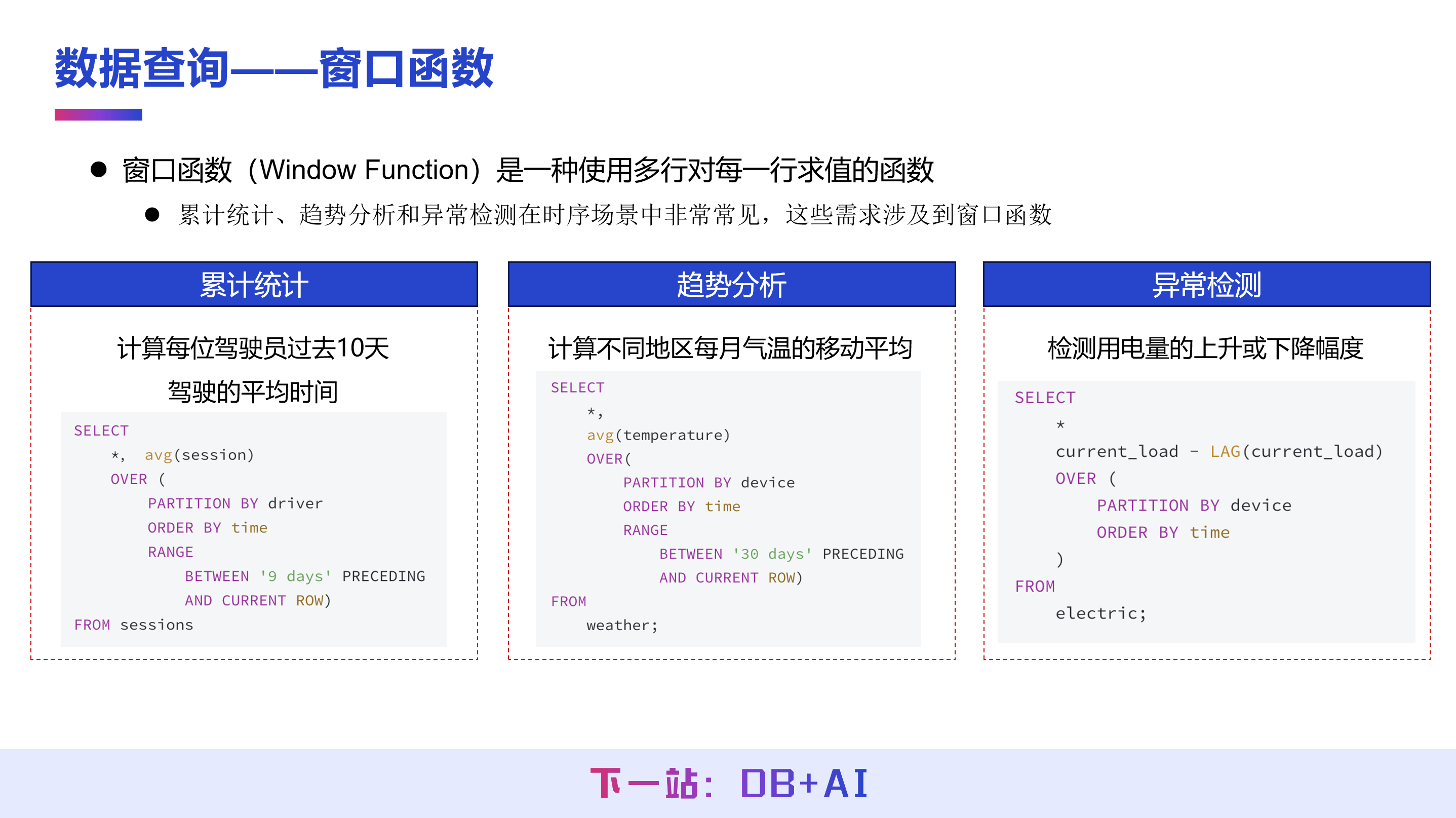
窗口函数是一种基于多行数据对当前行进行计算的函数,其结果为每一行输出一个值。在时序数据场景中,窗口函数应用十分广泛,例如计算累计平均值或移动平均值等需求,均可通过窗口函数方便地实现。
多态表函数是 SQL:2016 引入的一项里程碑式功能,它为 SQL operator 提供了一种通用的实现方式。传统 SQL 操作受限于 FROM、PROJECTION、ORDER BY、HAVING、GROUP BY 等固定算子,难以自定义业务处理逻辑并将其融入 SQL 生态。多态表函数的出现打破了这一限制,使用户能够扩展 SQL 处理逻辑。
这一特性也推动了 SQL 在更广泛场景中的应用。例如,2019 年 SIGMOD 会议上提出的“one SQL to rule them all”理念,正是基于表函数定义了一套流处理的时态语法,使流处理场景也能用标准 SQL 表达。类似地,IoTDB 引入表模型,正是为了将时序场景中的时序语义通过标准 SQL 的方式实现,原有的树模型也可视为对标准 SQL 的一种扩展,共同构建多样的时序数据处理生态。

以重叠时间分窗为例,在 IoTDB 树模型中需使用特定的自定义语法,而在表模型中,则可通过 HOP 表函数来实现。该函数命名遵循业界标准,与 Flink 等大数据组件保持一致,方便使用集成。

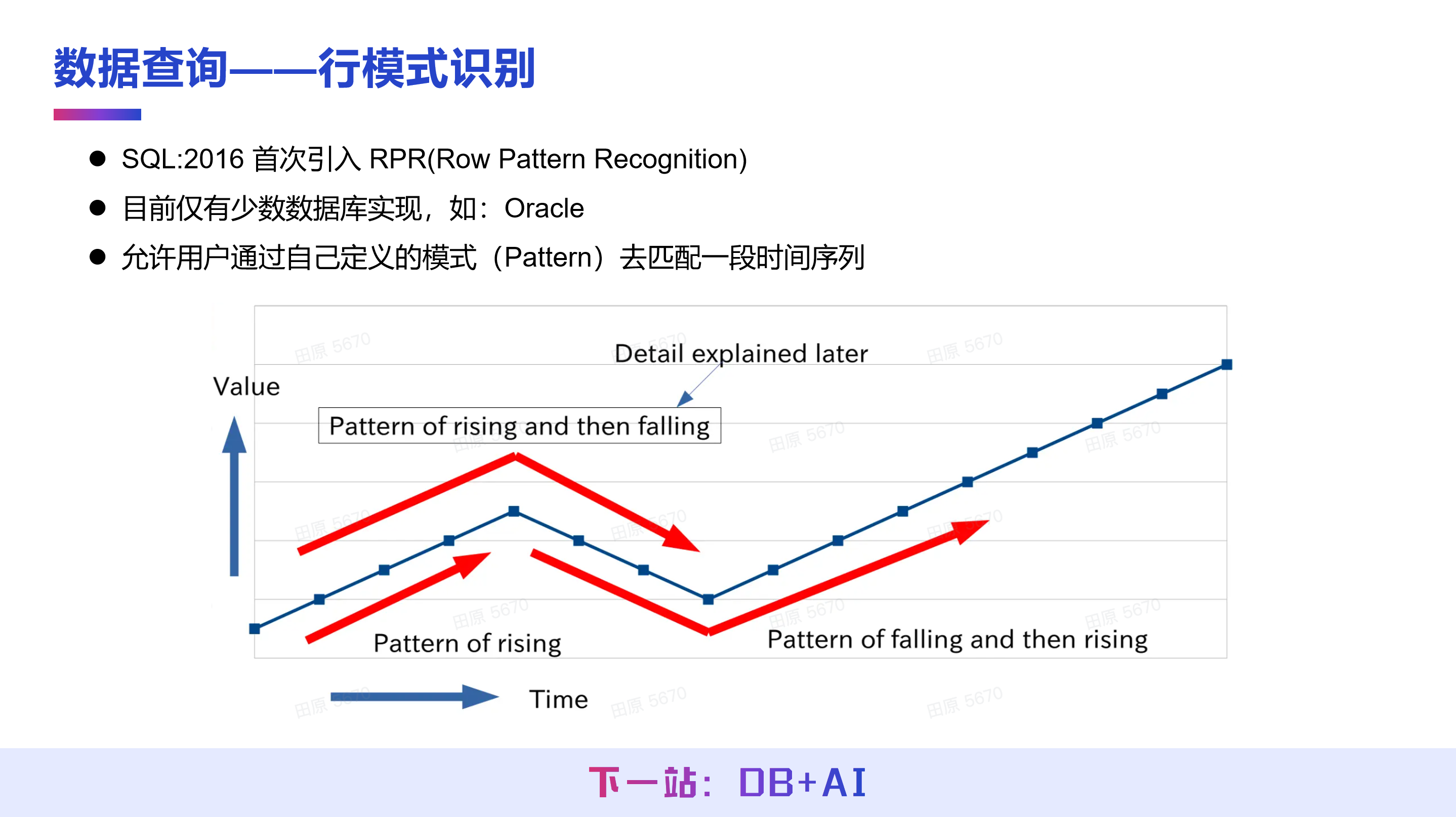
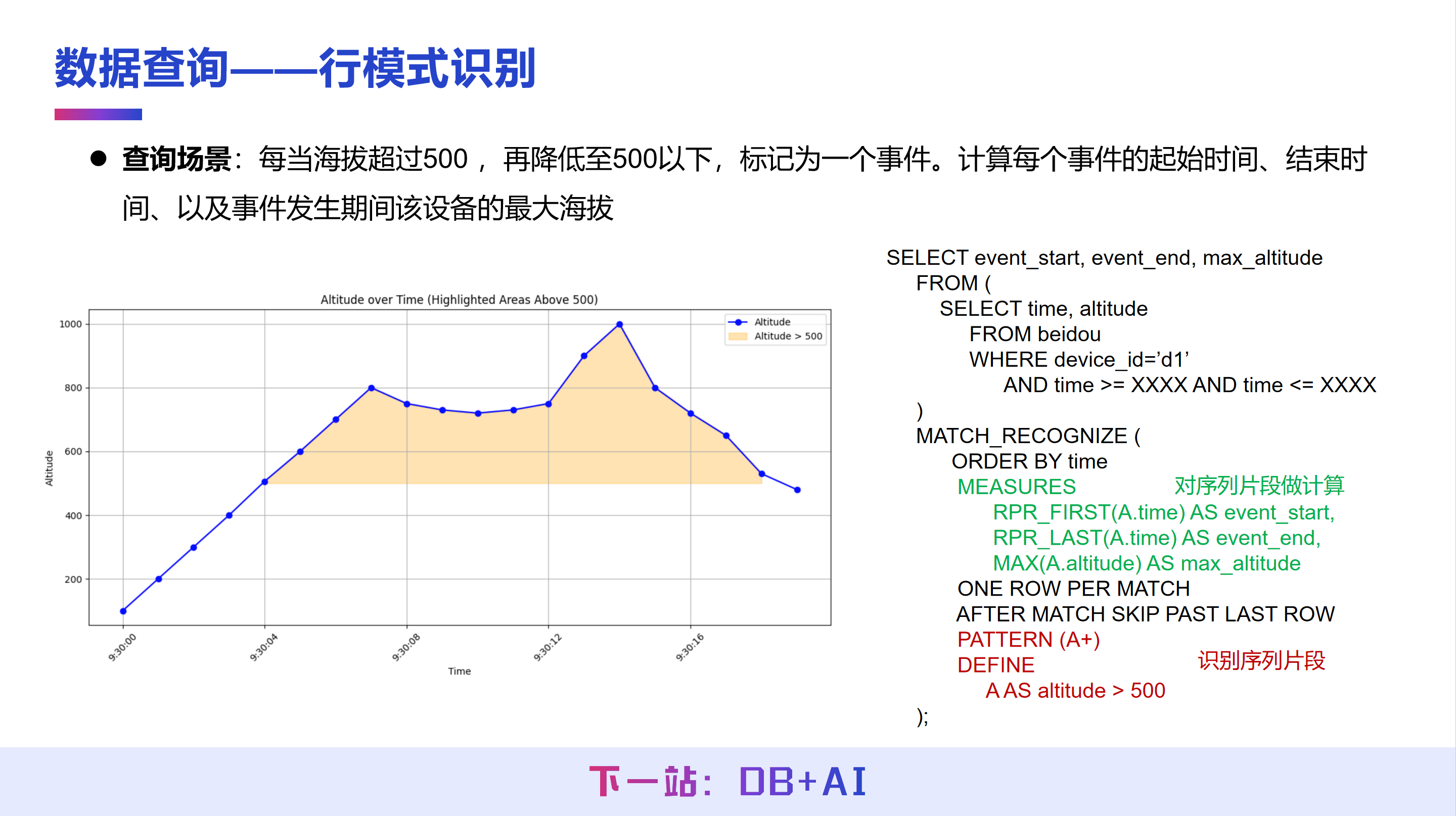
最后一个功能例子是行模式识别,该功能同样在 SQL:2016 中被引入,但目前仅有少数数据库支持实现。IoTDB 2.0 版本已实现行模式识别,使用户能够通过自定义的模式对时间序列进行匹配。
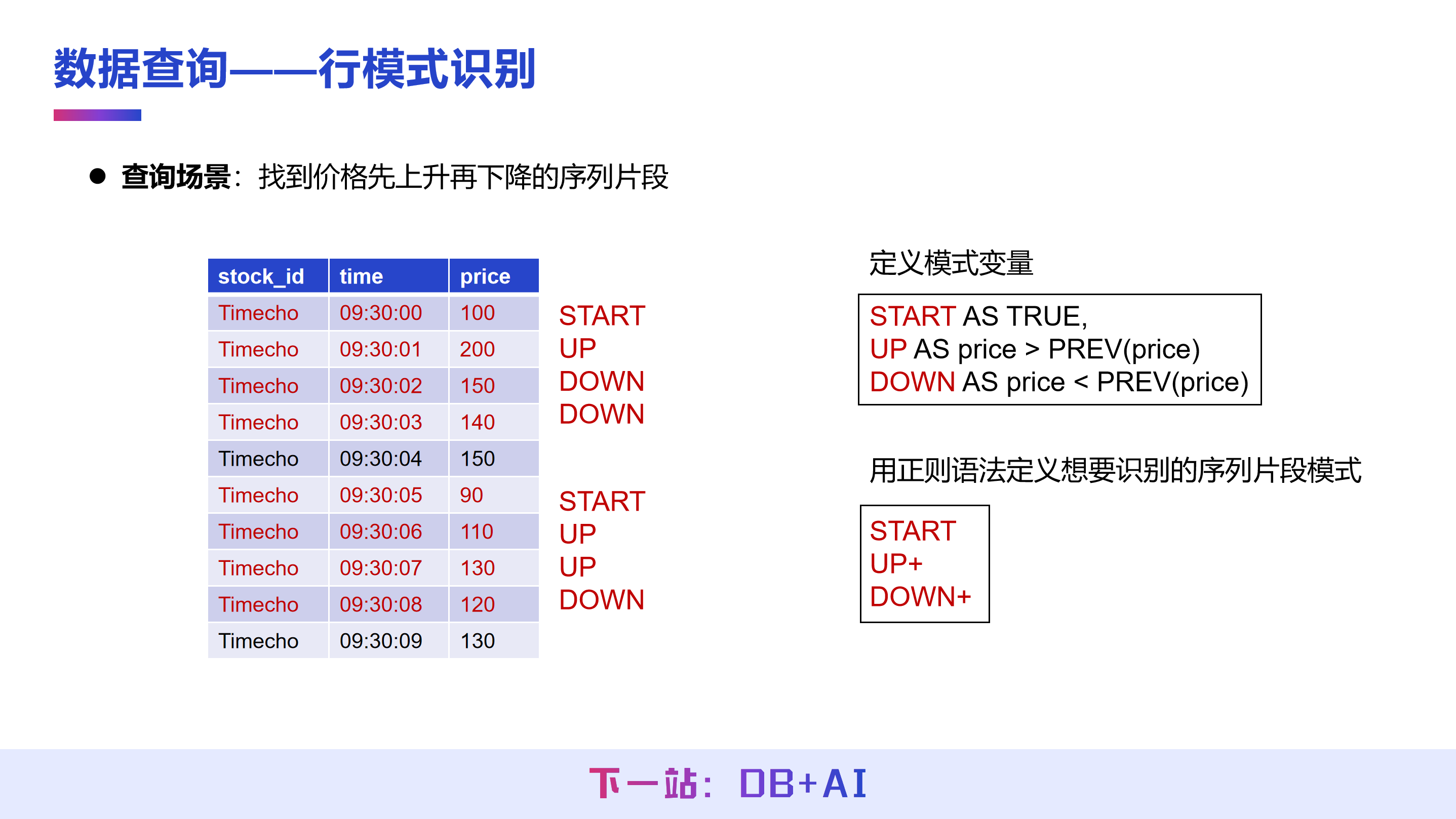
以股价分析场景为例,如果需要识别价格先上升后下降的模式,可以通过行模式识别功能实现。首先定义模式变量:设定 START AS TRUE,表示从起始点开始统计;定义 UP 为当前值大于前值,DOWN 为当前值小于前值。然后,使用类似正则语法的表达式 UP+、DOWN+ 来描述“先连续上升、再连续下降”的序列模式。
根据此模式进行匹配,即可从数据中找出符合条件的段落。例如,在示例数据中能够识别出两段满足先上升后下降条件的数据,之后可进一步对这些数据进行聚合或计算分析。
另一个使用行模式识别的案例为:需要将海拔超过 500、再降低 500 的区间标记为一个事件,并在该事件内计算最高海拔及其开始与结束时间。这不仅要求定义事件模式,还需要对匹配到的序列片段进行计算,在 IoTDB 2.0 版本中同样可以实现。
由此也可见,标准 SQL 正在逐渐贴近时序场景的需求,希望涵盖以往难以用 SQL 直接表达的时序语义与事件逻辑,从而扩展其在复杂时序数据分析中的表达能力。
03 树表双模型融合能力介绍
除了支持树模型与表模型的丰富功能,IoTDB 2.0 版本也建立了两种模型的融合机制,支持将已有的树模型建模映射为表模型视图。该机制可行的根本前提是两种模型共享统一的底层存储,即均基于 TsFile 这一物联网场景下的统一数据文件。
TsFile 存储仅识别设备和测点这两个核心概念,树模型和表模型只是用户侧不同的建模视图,因此 IoTDB 可以在两种模型的语义之间建立映射关系,从而使原有树模型的用户无需迁移数据,即可直接使用表模型提供的分析能力。
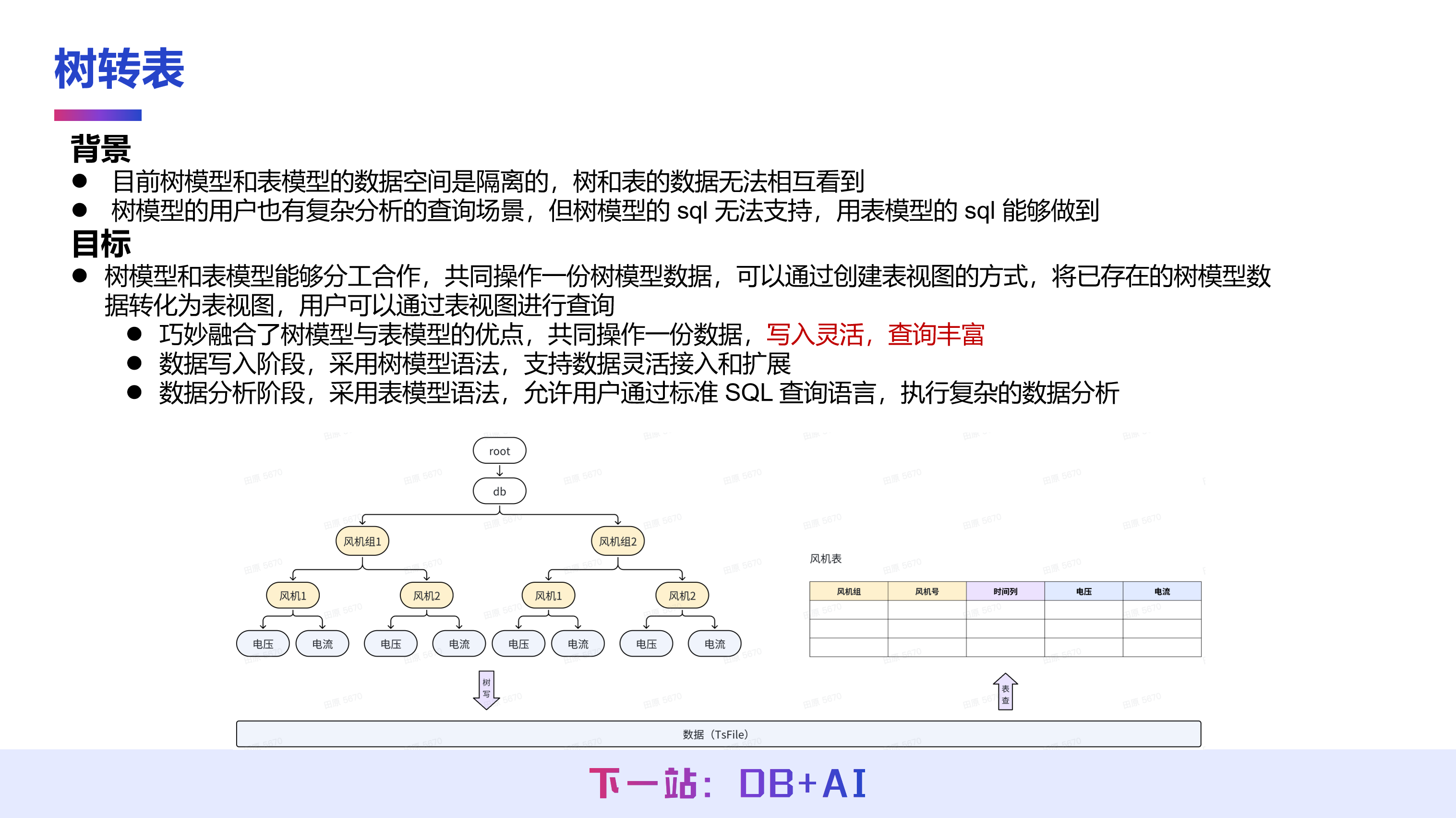
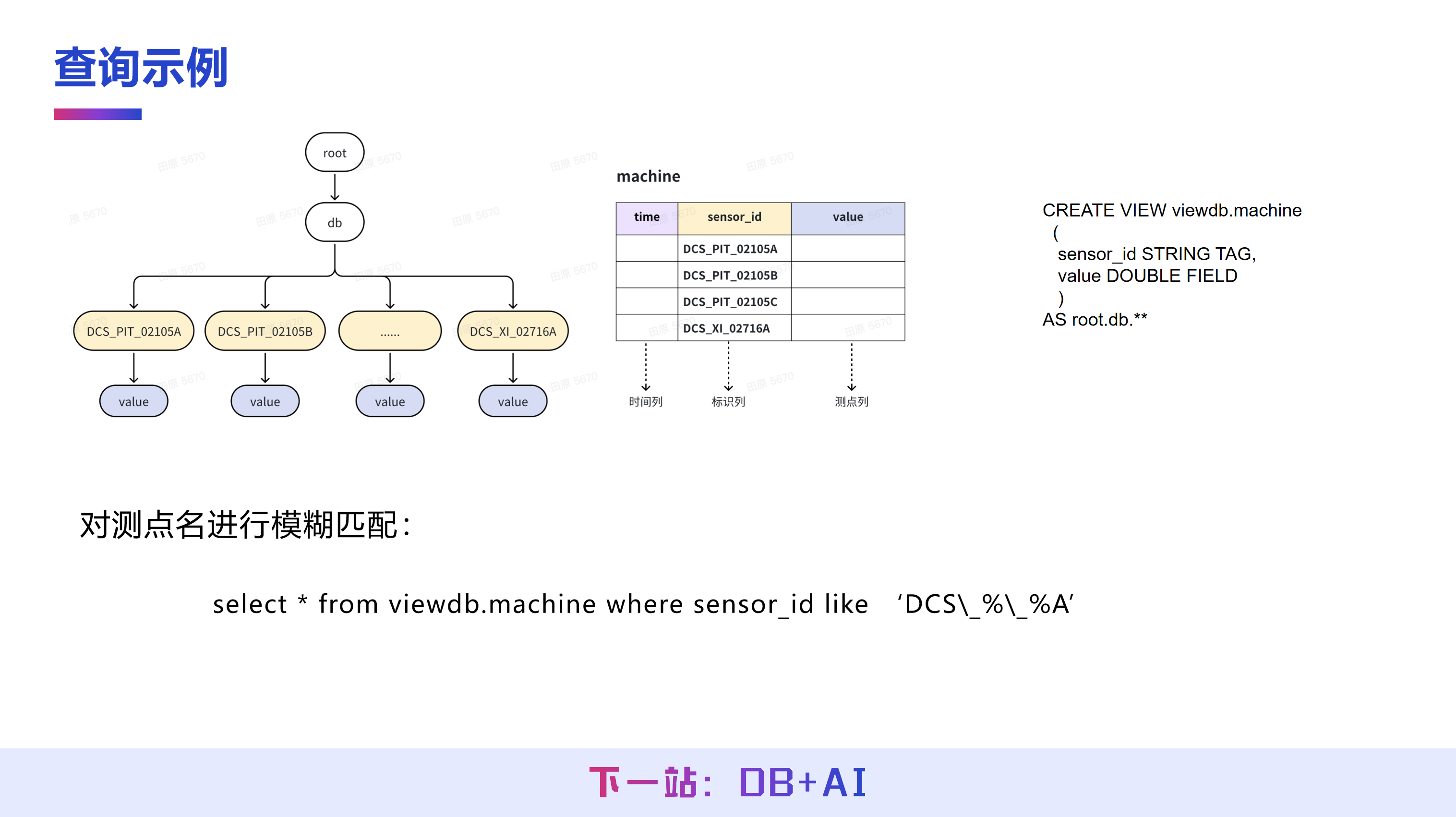
树模型转表模型的语法较为简明,其核心是通过 CREATE VIEW 语句建立逻辑视图,与关系型数据库中的标准语法一致。用户需在视图中定义树模型各层与表模型 TAG 列之间的映射关系。
在 AS 子句后,若为表模型逻辑视图,则需接一段 SQL 查询语句。而将树模型映射为表模型时,AS 后指定的则是原树结构中的一个子树前缀。例如,如果需要将“风机”这棵子树映射为一张风机表,则指定其对应前缀路径至风机层级。
对于结构更为复杂的树模型,例如设备同时包含子设备和测点,同样可以通过相应的语法将其映射为多张表。如图中右侧所示,可通过定义四个逻辑视图,分别将不同的设备层级映射为对应的时序表,从而实现从树形结构到表模型的转换。

没有设备的建模中,树模型与表模型之间依然可以进行映射。由于两者在语义上是等价的,即使数据仅通过测点 ID 进行组织,也能通过相应的视图定义实现模型间的转换。
如果用户在树模型的每个测点下添加了 value 这一层级,通过相应的映射语法,此类结构同样可以转换为包含三列(如时间列、测点列与 value 列)的窄表形式,并支持对测点名的模糊匹配,例如“查找测点路径中以 ‘DCS’ 开头、以 ‘A’ 结尾的所有测点数据”。
在树模型中,FROM 子句无法使用通配符实现特定层级的正则语法匹配,只能对特定层级进行通配匹配。而映射为表模型后,用户可直接使用 LIKE 等标准 SQL 语法对测点名进行灵活匹配,从而实现对复杂路径的查询需求。
04 融合查询展望
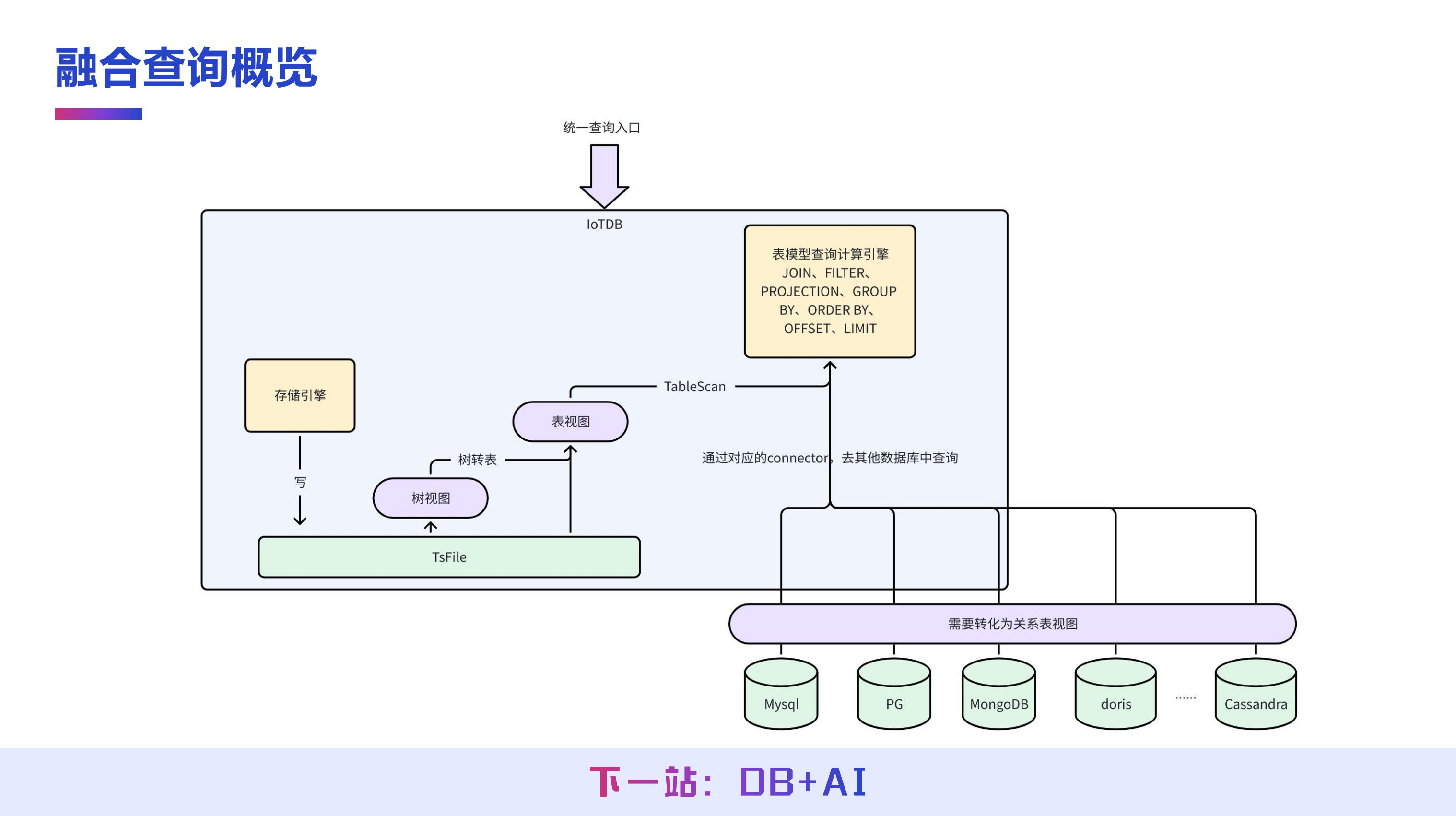
IoTDB 未来计划进一步强化联邦查询能力,旨在实现将 IoTDB 作为工业场景下的统一查询入口。
工业场景中,许多具备事务性需求的结构化数据通常存储于关系型数据库中。为支持跨源分析,IoTDB 提供了多种数据库连接器(Connector),能够将外部数据转换为关系视图。基于此,用户可在 IoTDB 中直接对外部关系数据与内部时序数据进行统一操作,如执行 JOIN、FILTER、PROJECTION、GROUP BY、ORDER BY 等计算,实现异构数据的融合分析与一站式查询。
类似的转换逻辑也应用于树/表模型的融合。树模型可视为一种异构数据源,可以通过 IoTDB 内置的类似连接器的机制,将其映射为表视图,再执行 TableScan 等操作。因此,在 IoTDB 系统内部,树与表被视作两种异构视图,二者通过连接器进行转换与集成,最终在统一的查询框架下实现对多模型数据的灵活处理。
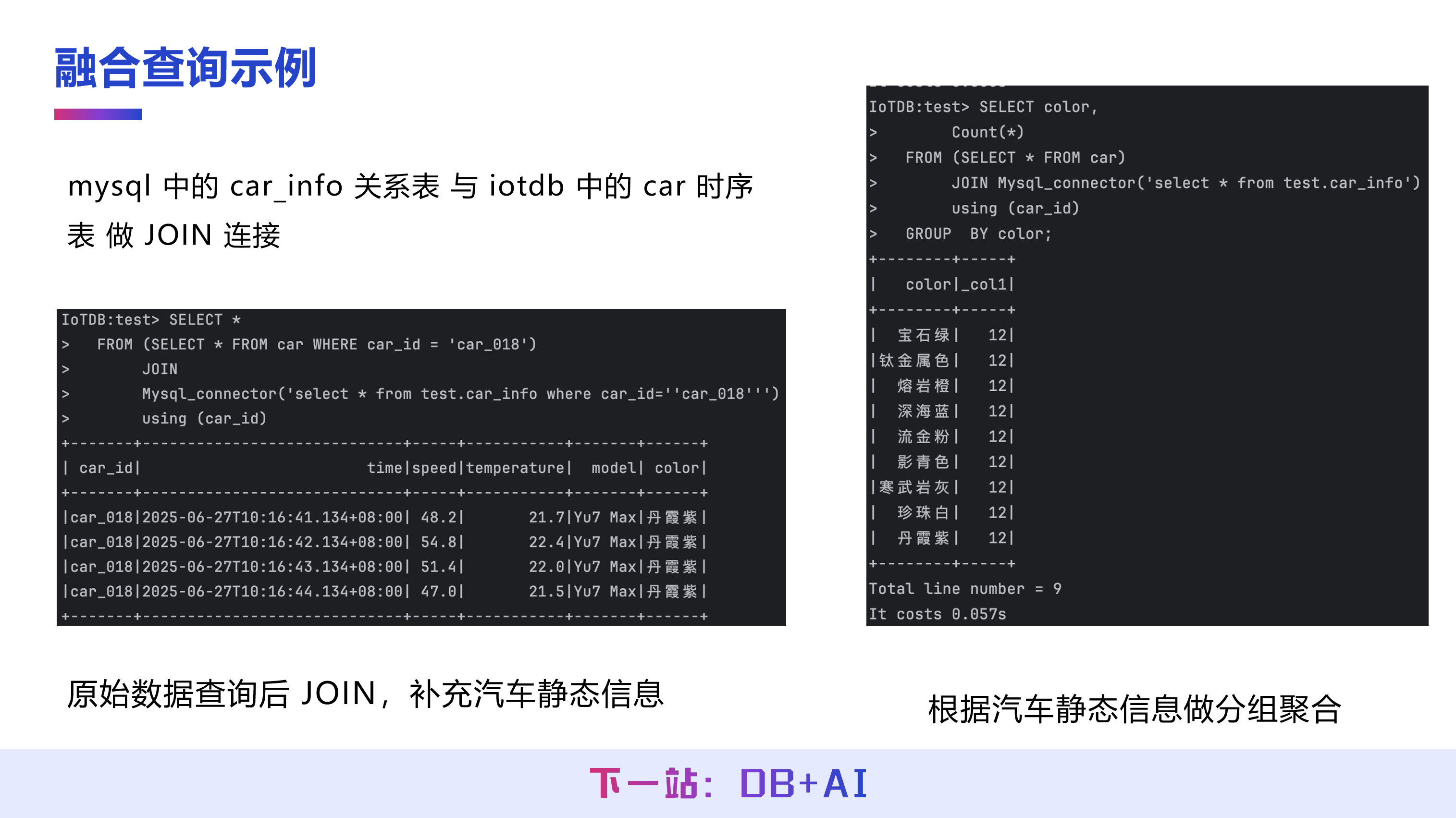
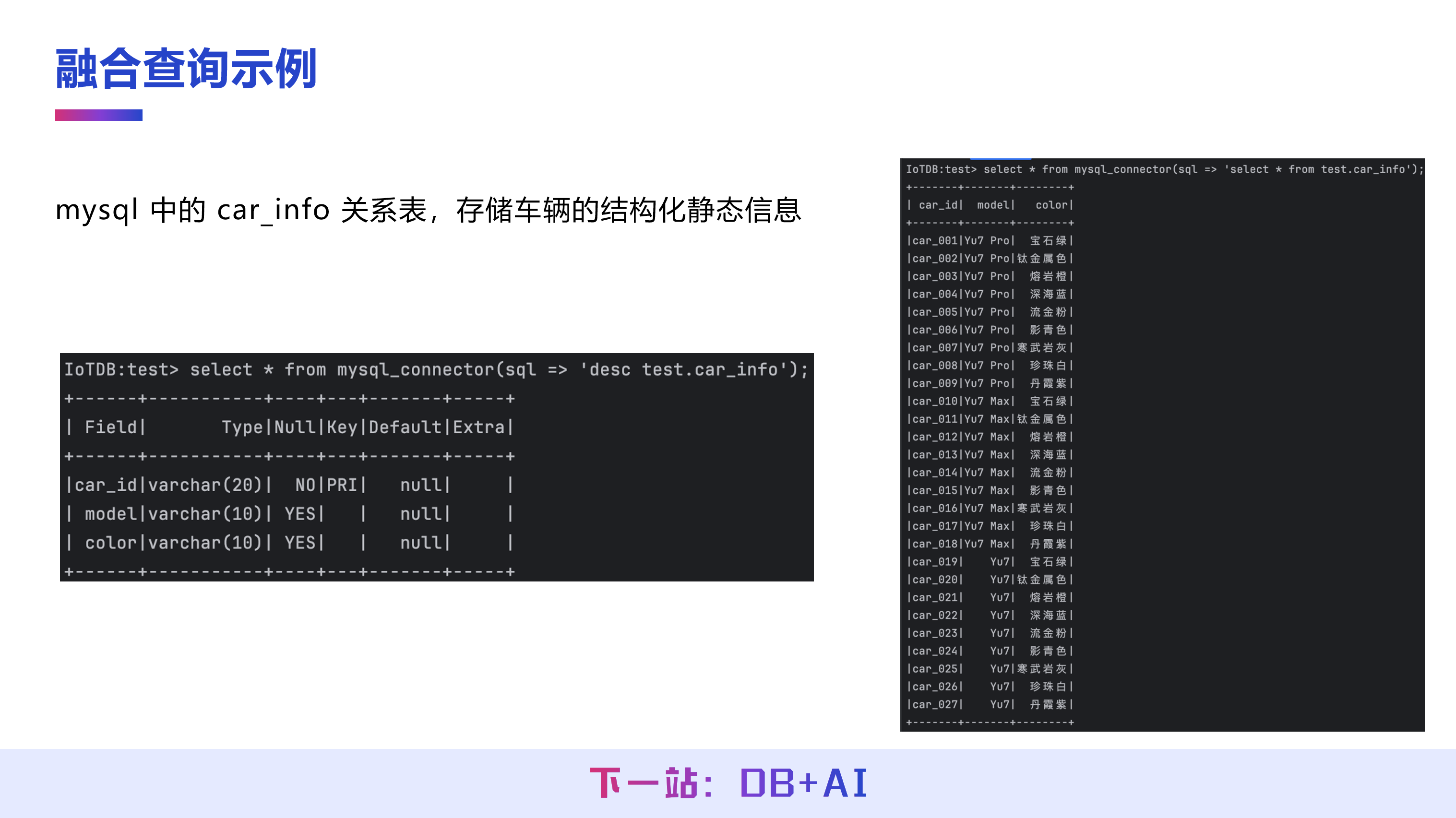
以一个具体例子说明:假设 MySQL 数据库中存储了一张名为 car_info 的关系表,记录了车型、颜色等结构化的静态信息。这些数据虽然物理上存储在 MySQL 中,但用户可以在 IoTDB client 直接编写 SQL 进行查询。通过 IoTDB 内置的 MySQL Connector,MySQL 存储的数据可以在 IoTDB 中呈现为一张可查询的表。
在这个例子中,IoTDB 通常存储的是车辆的动态时序信息,例如行驶过程中的速度、温度等实时监测数据。IoTDB 可以通过联邦查询对来自不同数据源的表进行关联与分析。例如,可以将存储在 IoTDB 的 CAR 018 的行驶时序数据与存储在 MySQL 中的车辆静态属性表通过 car_id 进行关联(JOIN),从而获得该车辆对应的车型、颜色等静态信息。进一步地,IoTDB 可以基于 JOIN 后的查询结果,按照车辆的静态属性进行分组聚合,实现诸如统计各颜色车辆销售数量的分析需求。
IoTDB 将持续深化对异构数据源的融合查询支持,致力于演进成为面向工业场景的一体化查询基座。