GPU基础概念举例
// 假设我们要处理一个 1024x1024 的浮点数组
__global__ void myKernel(float* data) { // 1. 计算当前线程的唯一全局索引 int idx = blockIdx.x * blockDim.x + threadIdx.x; int idy = blockIdx.y * blockDim.y + threadIdx.y;// 2. 检查是否在有效数据范围内 if (idx < 1024 && idy < 1024) { // 3. 每个线程处理一个数据点 int global_index = idy * 1024 + idx; data[global_index] = data[global_index] * 2.0f; // 例如,进行乘2操作 } }int main() { // ... 分配设备内存等准备工作 ...// 定义执行配置:网格和线程块的维度 dim3 threadsPerBlock(16, 16); // 每个块有 16x16=256 个线程 dim3 numBlocks((1024 + 15) / 16, (1024 + 15) / 16); // 计算所需的网格大小// 启动内核函数! myKernel<<<numBlocks, threadsPerBlock>>>(device_data); }
一个生动的比喻:图片处理“工厂”
想象你有一张 1024x1024像素 的图片,需要把每个像素调亮一些(乘以2.0)。如果用传统CPU方式,就像一个工人挨个处理104万多个像素,非常慢。
GPU的思路是:同时雇佣104万多个“微型工人”(线程),每个工人只处理一个像素,一瞬间完成。
但104万人不能乱哄哄地工作,需要严格组织。这就是你代码中网格(Grid)、线程块(Block)、线程(Thread) 三层结构的作用。
解剖代码:三层组织如何运转
第1步:工厂车间规划(main函数中的设置)
dim3 threadsPerBlock(16, 16); // 每个“小组”有16行×16列=256个工人
dim3 numBlocks((1024+15)/16, (1024+15)/16); // 需要多少这样的“小组”
threadsPerBlock(16, 16):这是最基本的工作小组(线程块)。每个小组有256个工人(线程),他们可以很方便地互相传递工具(共享内存)。
numBlocks:计算需要多少个这样的小组。(1024+15)/16 = 65,因为1024像素需要65个小组才能完全覆盖(64个小组处理1024像素,多1组处理剩下的)。
所以最终工厂有:65个小组 × 65个小组 = 4225个小组,每个小组有256个工人,总共 108万多个工人(线程)准备就绪。
第2步:给每个工人分配唯一“工位号”(内核函数中的索引计算)
当所有工人同时开始工作时,每个工人都需要知道:“我该处理哪个像素?”
int idx = blockIdx.x * blockDim.x + threadIdx.x; // 我的水平坐标
int idy = blockIdx.y * blockDim.y + threadIdx.y; // 我的垂直坐标
这是理解GPU并行的最关键公式:
blockIdx.x, blockIdx.y:我所在小组在工厂里的位置(第几列小组、第几行小组)。
blockDim.x, blockDim.y:每个小组的规模(这里是16×16)。
threadIdx.x, threadIdx.y:我在小组内部的位置(小组内的第几列、第几行工人)。
计算示例:假设一个工人位于第3列小组、小组内第2列。
小组坐标:blockIdx.x = 3
小组规模:blockDim.x = 16
组内位置:threadIdx.x = 2
全局水平坐标:idx = 3 * 16 + 2 = 50(这个工人负责第50列的像素)
第3步:工人开始工作(处理数据)
if (idx < 1024 && idy < 1024) { // 确保我的坐标在图片范围内
int global_index = idy * 1024 + idx; // 将二维坐标转换为一维数组下标
data[global_index] = data[global_index] * 2.0f; // 处理我的那个像素
}
if语句:因为我们的工人数(108万)比像素数(104万)多,多余的工人就“放假”不干活。
global_index:图片在内存中是连续的一维数组,这个计算找到像素在数组中的精确位置。
最后一行:这个工人(线程)唯一的工作——把自己负责的那个像素值乘以2。
核心思想:单指令多线程(SIMT)
理解这个,你就真正懂了GPU:
所有工人执行完全相同的指令(都运行myKernel函数里的代码)。
但每个工人处理的数据不同(因为idx, idy不同,所以global_index不同)。
当工人A在从内存读取数据时,工人B可能正在计算,工人C正在写入结果……数万个工人同时处于不同工作阶段,实现极致并行。
GPU编程思维转换
CPU思维(串行) GPU思维(并行)
“我要如何处理这个数组?” “数组的每个元素应该被如何处理?”
一个复杂的函数处理所有数据 一个简单的函数只处理一个数据
关注算法步骤 关注数据分解和线程组织
你的代码完美体现了这个思维:myKernel函数不是“处理整个数组的函数”,而是“单个像素的处理说明书”。GPU的威力在于把这个说明书同时交给108万个微型工人去执行。
简单来说:“网格-线程块-线程”是CUDA和HIP的编程模型术语,“调度网格-工作组-工作项”是OpenCL的术语,而“波前/线程束”则是硬件执行层面的概念。
横向对比:三套主流API的术语对应关系
概念层级 CUDA / HIP (AMD ROCm) OpenCL 对应关系与说明
最大任务单元 网格 (Grid) NDRange (调度网格) 完全对应。都代表一次内核启动所定义的所有并行工作总量。
协作/调度单元 线程块 (Thread Block) 工作组 (Work Group) 完全对应。都是一组可以紧密协作(共享内存、同步)的线程集合。是GPU硬件调度的基本单位。
基本执行单元 线程 (Thread) 工作项 (Work Item) 完全对应。都是最小的并行执行单元,每个处理一份数据。
硬件执行单元 线程束 (Warp, 32线程) 波前 (Wavefront, 64线程@AMD) 概念对应,但大小不同。这是硬件真正同时执行的线程组。一个线程块/工作组会被拆分成多个波前/线程束在计算单元上执行。
纵向深入:从编程模型到硬件执行
为了更透彻地理解,我们需要看看当你写下 myKernel<<<numBlocks, threadsPerBlock>>> 这行代码后,发生了什么:
1、编程模型(你写的代码):
你定义了一个由 numBlocks 个线程块组成的网格。
每个线程块包含 threadsPerBlock 个线程。
2、硬件调度与执行:
当线程块被分配到GPU的一个流多处理器(SM/CU) 上时,硬件会将其中的线程进一步分组为更小的固定尺寸的批次来执行。
在NVIDIA GPU上,这个分组叫线程束(Warp),固定为32个线程。
在AMD GPU上,这个分组叫波前(Wavefront),通常为64个线程(旧架构有32)。
这是硬件真正并行执行的粒度。一个波前/线程束内的所有线程在同一时钟周期内执行相同的指令(但操作的数据可以不同,即SIMD/SIMT架构)。
核心区别与如何对应理解
1、“波前/线程束”是物理现实,“线程块/工作组”是逻辑抽象:
你可以随意指定线程块的大小(如128、256、512),这是为了编程灵活性。
但硬件在执行时,会无视你设定的块大小,而是严格按照波前/线程束的固定宽度(32或64)来调度和执行线程。
理解关键:一个256线程的线程块,在NVIDIA GPU上会被硬件“看作”8个线程束(256/32),在AMD GPU上会被“看作”4个波前(256/64)来执行。
2、为什么硬件要这么做?——为了极致效率:
将线程分组执行,可以极大地简化调度器和指令发射单元的复杂度。
波前/线程束内的线程共享程序计数器,一起取指、译码、执行,实现了极高的能效比。如果其中有些线程走了不同的分支(如if/else),硬件会串行化执行所有分支,并屏蔽不活动的线程,这称为分支发散,是性能优化的重点。
一个具体例子:串联所有概念
假设你用HIP(ROCm)编写内核,设置 threadsPerBlock(256),并在AMD GPU上运行:
编程层面:你启动了一个有 N 个线程块的网格,每个块有256个线程。
硬件层面:一个线程块被加载到计算单元(CU)。硬件将这个256线程的块,划分成4个波前(256/64)。
执行层面:调度器每次调度一个波前执行。这个波前中的64个线程锁步执行相同的指令,分别处理各自的数据。4个波前可能并发执行,以隐藏内存延迟。
总结与记忆图谱
你可以这样建立认知框架:
你的代码 (HIP/CUDA): 网格(Grid) -> 线程块(Block) -> 线程(Thread)
你的代码 (OpenCL): NDRange -> 工作组(Work Group) -> 工作项(Work Item)
| | |
| | |
硬件视角: | | |
v v v
在GPU上排队 被SM/CU处理 被分组为 **波前/Warp**
(32/64线程的 **物理执行单元**)
进一步理解:
“调度一个波前执行”和“多个波前并发执行”并不矛盾,它们描述的是不同维度的概念。用一个更深入的比喻和详细流程来拆解
核心比喻:从“单一厨房”到“餐厅后厨”
把GPU的一个计算单元想象成一个餐厅后厨:
一个波前:就像是一张包含了64道相同菜品的订单。例如,“用同样的方法炒64盘青椒肉丝”。厨师(SIMD单元)必须一次性处理这整张订单。
调度器:是后厨的调度员。他的基本工作单位就是“一张订单”(一个波前)。他每次调度,就是拿起一张订单,交给一个可用的厨师团队去处理。
并发执行:后厨里不止有一个厨师团队。理想情况下,有多个厨师团队(多个SIMD单元) 可以同时工作,各自处理不同的订单。同时,即使一个团队在等待食材(内存延迟),其他团队也可以继续炒菜(计算)。
AMD GPU计算单元(CU)的详细架构与调度流程
让我们结合AMD GPU的硬件架构图(下图),来具体看看一个波前是如何被调度和执行的:
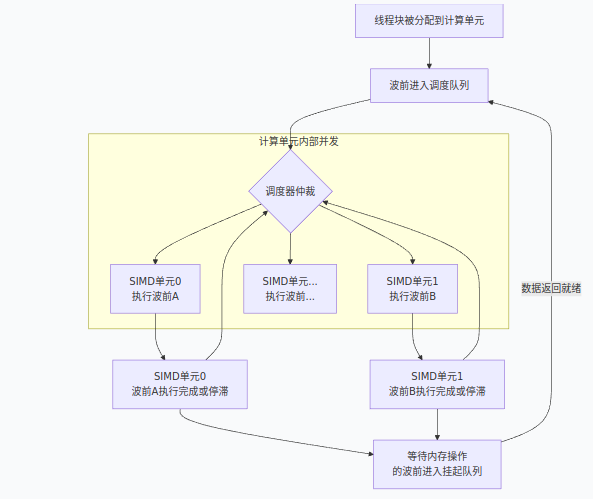
1、计算单元的资源池:一个计算单元有固定的硬件资源,如多个SIMD单元(通常是4个)、寄存器堆、本地数据共享(LDS,即共享内存)和调度队列。当一个线程块(例如256个线程)被分配到一个计算单元时,它的线程和所需的资源(寄存器、LDS)就被划拨给了这个单元。
2、波前的形成与就绪:这个256线程的块,在硬件层面被立即且静态地划分成4个波前(256/64)。每个波前作为一个独立的调度单元,进入计算单元的调度队列,等待被派发执行。
3、调度器的仲裁与派发:计算单元内的调度器在每个时钟周期都会检查队列中的波前。它的派发决策基于两个核心原则:
SIMD单元可用性:是否有空的SIMD单元(“空闲的厨师团队”)来接收并执行一个波前。
波前就绪状态:波前的所有操作数(数据)是否已就绪。例如,如果波前正在等待从全局内存读取的数据,它就会处于“未就绪”状态,不会被派发。
调度器会从就绪的波前中挑选,派发到空闲的SIMD单元上。
4、SIMD单元的锁步执行:这才是 “调度一个波前执行” 的真实场景。一个SIMD单元接收一个波前后,会让这个波前的64个线程严格锁步:在同一时钟周期,所有线程执行完全相同的指令,但操作的是各自不同的数据(例如,64个线程同时做一次乘法,但各自乘自己寄存器里的数)。
5、并发的真谛:由于一个计算单元内通常有4个SIMD单元,因此在理想情况下,调度器可以同时向4个SIMD单元各派发一个波前。这就实现了 “4个波前并发执行” 。这就是硬件层面的指令级并行(ILP)和线程级并行(TLP)。
6、隐藏延迟的关键:当某个正在执行的波前遇到高延迟操作(比如访问全局内存,可能需要几百个时钟周期)时,SIMD单元不会傻等。调度器会立即将该波前挂起,腾出SIMD单元,然后从队列中派发另一个就绪的波前来执行。通过这种方式,让计算单元始终处于忙碌状态,从而“隐藏”了内存访问的巨大延迟。
总结一下:
可以把波前看作是GPU硬件调度和执行的“原子单位”。调度器以波前为单位进行派发,而硬件设计(多SIMD单元)允许多个波前真正在物理上并发执行,
并通过在众多波前之间快速切换来完美隐藏延迟。这正是GPU能达到惊人吞吐量的核心秘密之一。
进一步的理解:线程块大小、波前与SIMD单元的真实关系
我们可以将线程块看作一个可以自由裁切的“工作包”,而硬件有固定的“处理格子”。下图展示了不同大小的线程块如何被硬件处理:
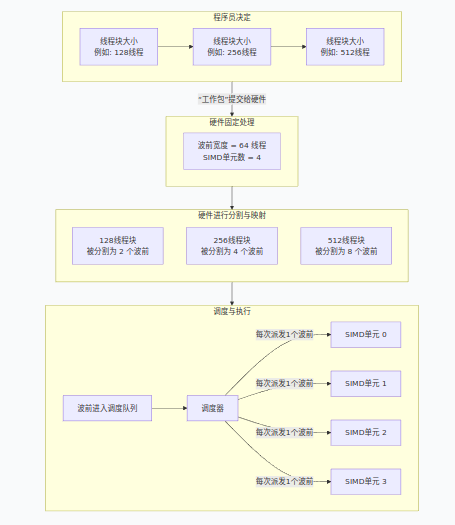
上图展示了流程,下面我们结合这个流程,重点解释几个核心关系:
1、线程块大小由程序员自由决定:你可以启动一个只有 64个线程 的块(被分成1个波前),或 128个线程 的块(2个波前),
或 512个线程 的块(8个波前)。常见的尺寸如64、128、256、512等,主要是出于性能经验和对齐的考虑,而非硬件强制。
2、SIMD单元数量决定并发执行的“车道”数,而非“乘客”总数:有4个SIMD单元,意味着最多可以有4个波前在同一时钟周期内分别在这4条“车道”上并发执行。
但这绝不意味着一个计算单元CU上只能有4个波前。如上图所示,一个256线程的块会生成4个波前,一个512线程的块会生成8个波前,它们都会进入同一个CU的调度队列。
3、资源限制是真正的约束:一个CU能容纳多少波前,不取决于SIMD单元数量,而取决于更稀缺的硬件资源:
寄存器堆:每个线程都需要一定数量的寄存器。如果线程块太大,每个线程占用寄存器过多,会导致CU能同时驻留的波前数量减少,甚至无法启动该大小的线程块。
本地数据共享(LDS/共享内存):每个线程块可以申请一部分LDS。LDS总量是固定的,过大的线程块请求会限制并发线程块的数量。
波前调度槽位:每个CU有用于管理波前状态的硬件存储,其数量决定了能同时驻留(包括正在执行和等待的)波前的最大理论值(例如,AMD CDNA2架构的CU可达40个波前)。
为什么我们说“4个波前可能并发执行”?
这里的“并发执行”是指在同一个时钟周期内,有多个波前在物理上同时处于执行状态。这正是由多个SIMD单元实现的。
但调度器会在极短的时间片内(几个时钟周期)在几十个驻留波前之间快速切换,让它们轮流使用这4个SIMD单元,
从而在宏观上实现远超4个波前的并行度,并完美隐藏内存延迟。
最佳实践建议:
从256开始:这是一个经验证的、在大多数情况下表现良好的默认值。
进行性能剖析:使用ROCm的rocprof或rocTracer等工具,查看内核实际运行的“平均活跃波前数”。
如果这个数值很低(例如远小于硬件支持的最大值),说明延迟隐藏不足,可以尝试增大线程块尺寸或增加每个网格的线程块总数。
考虑算法需求:如果你的算法需要线程块内大量通信(如归约、扫描),更大的块(如512)可能更高效。
检查资源限制:确保你的线程块大小不会导致内核因寄存器或LDS不足而无法启动。