目录
PERTRAINING
Step 1: download and preprocess the internet 数据预处理
Step 2: tokenization 分词
Step 3: neural network training 神经网络训练
Step 4: inference 推理
POST-TRAINING
如何缓解幻觉
模型的自我认同
模型的计算能力
基于SFT model -> Reinforcement learning
RLHF (Reinforcement Learning from Human Feedback) 基于人类反馈的强化学习
Preview
KEEP TRACK OF LLMs
使用建议
课程地址:
khttps://www.youtube.com/watch?v=7xTGNNLPyMIhttps://www.youtube.com/watch?v=7xTGNNLPyMI![]() https://www.youtube.com/watch?v=7xTGNNLPyMI
https://www.youtube.com/watch?v=7xTGNNLPyMI
PERTRAINING
Step 1: download and preprocess the internet 数据预处理
HuggingFace FineWeb Datasethttps://huggingface.co/datasets/HuggingFaceFW/fineweb![]() https://huggingface.co/datasets/HuggingFaceFW/fineweb
https://huggingface.co/datasets/HuggingFaceFW/fineweb
从网上获取海量高质量文本,并经过以下处理: URL过滤(垃圾网站、营销网站等)、文本提取、 语言筛选、重复筛选、隐私信息清除,最终形成可下载内容集。
Step 2: tokenization 分词
即解决如何处理数据集,以何种形式输入到模型中:
原始文本->tokens (一维序列)
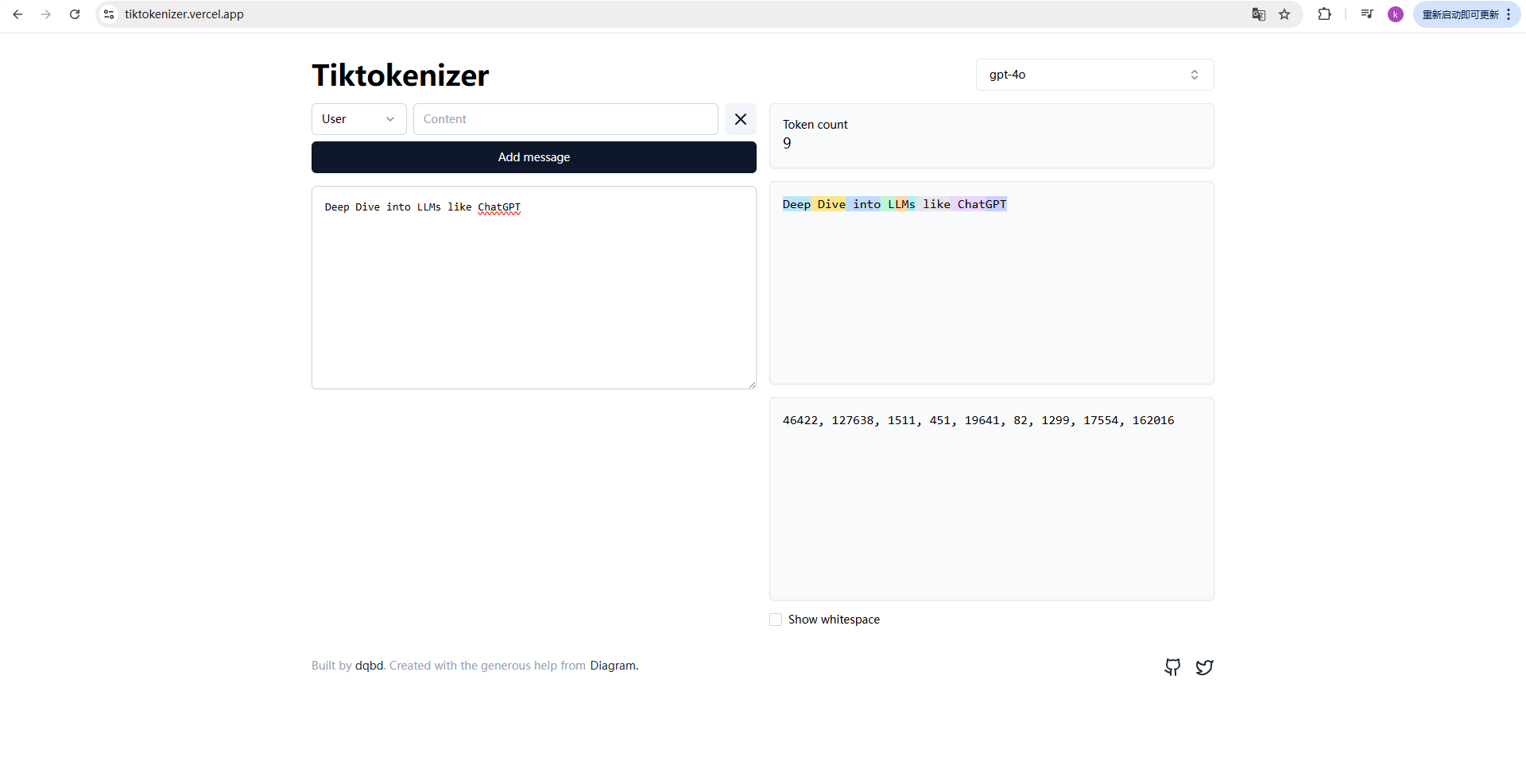
tiktokenizer 网站 可直观感受分词过程https://tiktokenizer.vercel.app/![]() https://tiktokenizer.vercel.app/
https://tiktokenizer.vercel.app/
Step 3: neural network training 神经网络训练
- 输入:可变长度的token序列
- 输出:词汇表中所有候选token的概率分布
- 训练神经网络的目的:最大化真实next token的预测概率
- 神经网络训练过程即是调整模型参数,使预测输出接近真实值的过程。
LLM Visualization![]() https://bbycroft.net/llm
https://bbycroft.net/llm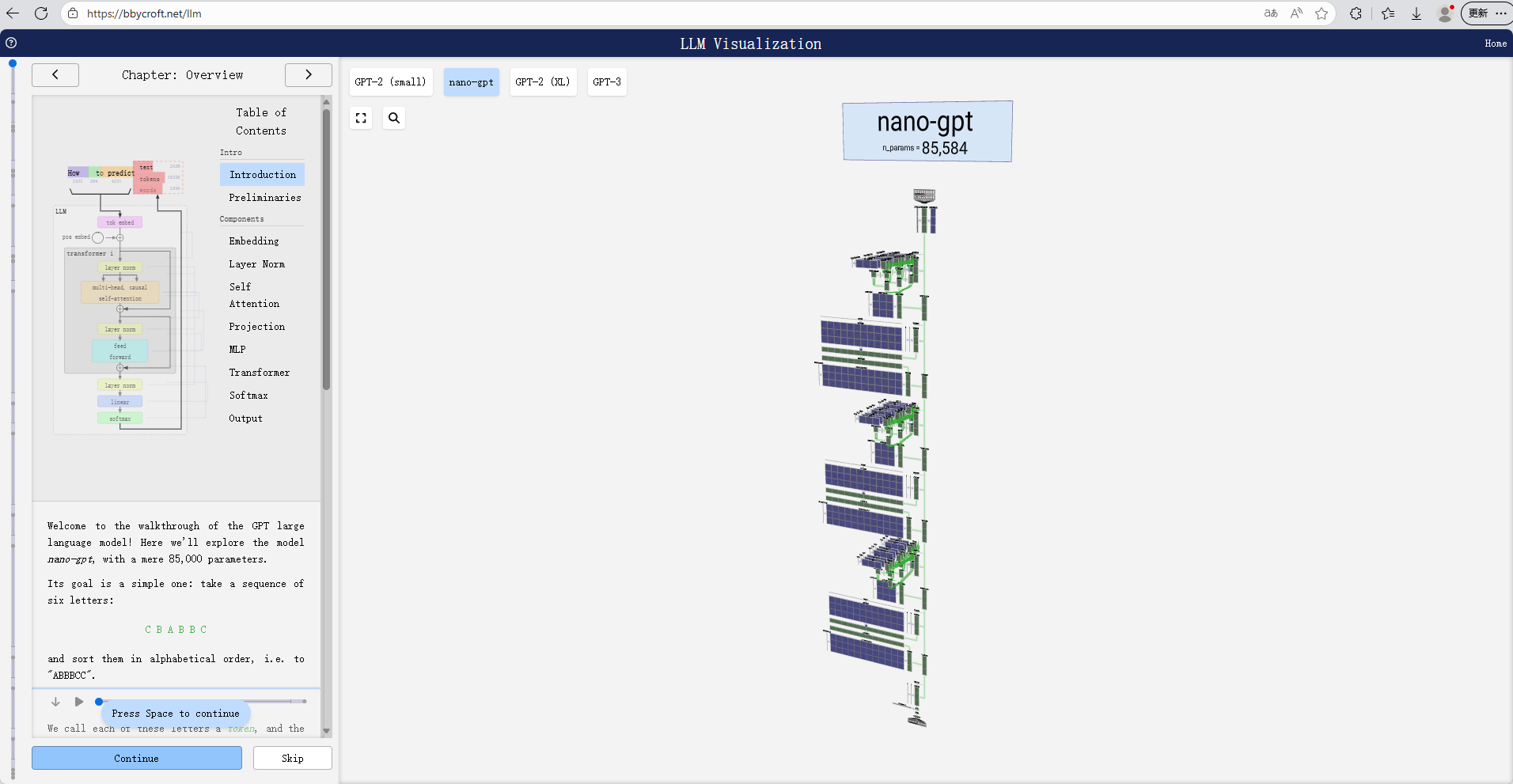
Step 4: inference 推理
- 自回归生成 (Autoregressive Generation):推理过程是一个顺序、迭代的过程。模型最初基于给定的起始上下文计算词汇表上所有候选 token 的概率分布。然后,根据某种采样策略选出下一个token ,并将其添加回输入序列,作为预测的新上下文。这一过程持续进行,直到达到最大序列长度或生成停止符。
- 参数固化:平时大家在和ChatGPT等进行实时交互,执行的是inference过程,其已由OpenAI完成预训练,模型参数处于固定状态,不会在对话过程中发生改变。
- 上下文的影响:LLM的生成质量强烈依赖上下文长度。更长的上下文长度序列能够给出更为丰富的语境信息,使模型可更为准确地预测序列中的next token。
- Base model:预训练阶段得到的Base model,本质更多是token simulator,尚不具备作为通用助手的回答能力。
Hyperbolic – The Open-Access AI Cloud![]() https://www.hyperbolic.ai/
https://www.hyperbolic.ai/
- 幻觉:即使模型在训练集中见过特定信息(如百科知识),它仍然是基于概率分布进行采样的,只是在试图做出统计学上最佳的猜测。这种基于概率的生成机制导致模型可能产生与事实不符或凭空捏造的信息,即幻觉 (Hallucination)。
- Prompt Engineering 与情境学习 (In-Context Learning, ICL):通过精心设计的提示词工程 (Prompt Engineering),特别是少样本提示 (Few-shot Prompting),许可在不改变模型参数的情况下,显著提升基础模型在特定任务上的表现,使其接近于经过微调的助手模型。少样本示例使模型能够在其输入上下文中进行情境学习,理解任务模式并更好地泛化到新的查询。
POST-TRAINING
在预训练(Pre-training)之后,模型进入监督微调 (SFT)阶段。该阶段基于相对较小的、高质量、人工筛选或标注的对话素材集进行训练,旨在将基础模型从“下一 Token 预测器”对齐为“指令遵循型助手”。
本阶段会引入新的token,如<|im_start|>、<|im_sep|>、<|im_end|>,以让模型获取新轮次的开始,知晓轮到user还是assistant。
模型在 SFT 阶段本质上是在进行模仿学习 (Imitation Learning)幻觉 (Hallucination) 产生的根本原因。就是,统计性地模仿标注者回答的风格和格式。这种基于条件概率采样的机制是其能力的来源,也
如何缓解幻觉
- 显式知识拒绝:缓解幻觉的关键手段之一是训练模型进行知识拒绝 (Knowledge Refusal)。通过在 SFT 或后续的对齐阶段引入带有知识盲区或事实性错误的问答样本,模型被训练在内部置信度较低时,显式地输出拒绝或免责声明(例如“我无法核实此信息”)。
- 检索增强生成 (RAG):利用 工具 (Tool Use) 机制,凭借生成特殊控制 Token(例如 <SEARCH_START> 查询内容 <SEARCH_END>)触发外部检索。检索到的最新或准确信息会被注入到模型的上下文窗口 (Context Window) 中。上下文窗口作为模型临时的工作记忆,使模型能够基于外部事实信息进行条件生成,这显著减少了幻觉。
- 外部知识注入:利用模型的长上下文能力,通过在用户提示中提供详尽的外部资料或参考文档,在推理时将事实信息直接注入到上下文窗口中,引导模型基于给予的证据进行回答。
模型的自我认同
- 模型自己并不知道自己的身份,它可能仅是从网络上知识获取到的,它不知不觉中扮演一个helpful assistant。
- 但也可在System meaasge进行身份设定。系统消息 (System Prompt/Message)是一种高级的上下文注入技术,用于在对话开始时设定模型的角色 (Role)、行为约束 (Constraints) 或风格 (Style)。系统消息的内容被视为最高优先级的上下文,指导模型在整个对话中的行为。
模型的计算能力
Models need tokens to think
- 基于固定的、经过训练的参数矩阵执行一系列矩阵乘法和非线性激活的数学运算。在推理时,模型为上下文窗口中的每个 Token 分配固定的计算资源,最终输出下一个 Token 的概率分布。就是LLM 的推理
- 模型在处理艰难问题时会进行逐步拆解,增加中间推理过程可提高准确率。或者要求模型use code来解决,同样属于use tool,借助特殊token触发功能并返回结果。
- 模型在处理输入时基于 Token 粒度而非字符粒度,这使得它天生不擅长精确的字符计数、字符串操作或数学运算。因此,对于精确的计数或计算任务,调用外部代码解释器是更可靠的解决方案。
基于SFT model -> Reinforcement learning
- 从SFT到RL:SFT阶段准确率受限于人类标注员所给的标注内容质量。sft model某种程度上只是将模型初始化到接近正确解决方案的区域,而强化学习通过与环境的交互,可在海量解决方案中找到使累积奖励最大化的最佳解决方案。
https://huggingface.co/playground![]() https://huggingface.co/playground可调用市面上常见模型进行inference。
https://huggingface.co/playground可调用市面上常见模型进行inference。
之前这些技术方案开源的不多,而DeepSeek-R1技术报告非常公开地讨论了LLM的强化学习、微调等技术,重新激发了公众对将强化学习应用于LLM的兴趣。报告原文可自行下载。
DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1 · GitHub![]() https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
- 认知策略的形成:RL 训练的关键成果是模型能自主发现和构建认知策略 (Cognitive Strategies)。模型不再是被动模仿,而是学习如何操作问题状态、多角度切入、试验性地尝试不同解法,并对结果进行自我检验。
- 推理模型的构建:这种利用探索和奖励驱动学习的模型被归类为推理模型 (Reasoning Model)。它们不仅模仿人类专家的最终输出,更主要的是自主发现和内化解决问题所需的推理路径 (Reasoning Trajectory)。
一些托管各类基础模型的inference provider:就是以下https://www.together.ai/![]() https://www.together.ai/
https://www.together.ai/
https://ai.google.dev/aistudio![]() https://ai.google.dev/aistudio
https://ai.google.dev/aistudio
- 基于 LLM 的评估:在没有人工标注的情况下,可以利用大模型判官 (LLM Judge) 对生成的答案进行自动化评分,用于替代部分人工反馈,指导强化学习过程。
RLHF (Reinforcement Learning from Human Feedback) 基于人类反馈的强化学习
- 奖励模型:RLHF 的核心是训练一个奖励模型 (Reward Model)。RM 是一个判别式神经网络,其训练目标是模仿人类标注者对模型多个输出(例如 A_1, A_2, A_3)的偏好排序(如 A_2 > A_1 > A_3)。
- 反馈效率:对于开放式和发散性的任务,让人类标注者对多个候选答案进行相对偏好排序 RLHF 成功的关键。就是比要求他们给出唯一“最佳”答案更简单、更具可扩展性,这也
Preview
- 多模态集成:未来的发展重点是实现多模态 (Multimodality) 的深度集成,包括文本、音频、视觉(图像和视频)等,以构建对真实世界更全面感知的模型。
- Agent 范式:任务执行将从处理单一短期任务 (Single-Step Tasks) 演进为实现自主智能体 (Autonomous Agents) 范式,专注于处理应该规划、记忆和反馈回路的复杂长程任务 (Long-Horizon Tasks)。
- 实时与在线学习:研究方向包括模型在推理(测试)时能否进行同步学习 (Synchronous Learning) 或在线适应 (Online Adaptation),利用实时的上下文和反馈进行即时微调,以提高响应的个性化和相关性。
KEEP TRACK OF LLMs
- LLM榜单
https://lmarena.ai/leaderboard![]() https://lmarena.ai/leaderboard
https://lmarena.ai/leaderboard
- AI新闻
AINews | AINews![]() https://news.smol.ai/
https://news.smol.ai/
- X / Twitter
本地部署小模型https://lmstudio.ai/![]() https://lmstudio.ai/
https://lmstudio.ai/
使用建议
始终将大型语言模型视为高效的辅助工具和灵感来源。所有由 LLM 生成的内容,都必须由用户进行严格的double check。请牢记,您对最终结果的准确性、合规性和适用性负有最终责任。