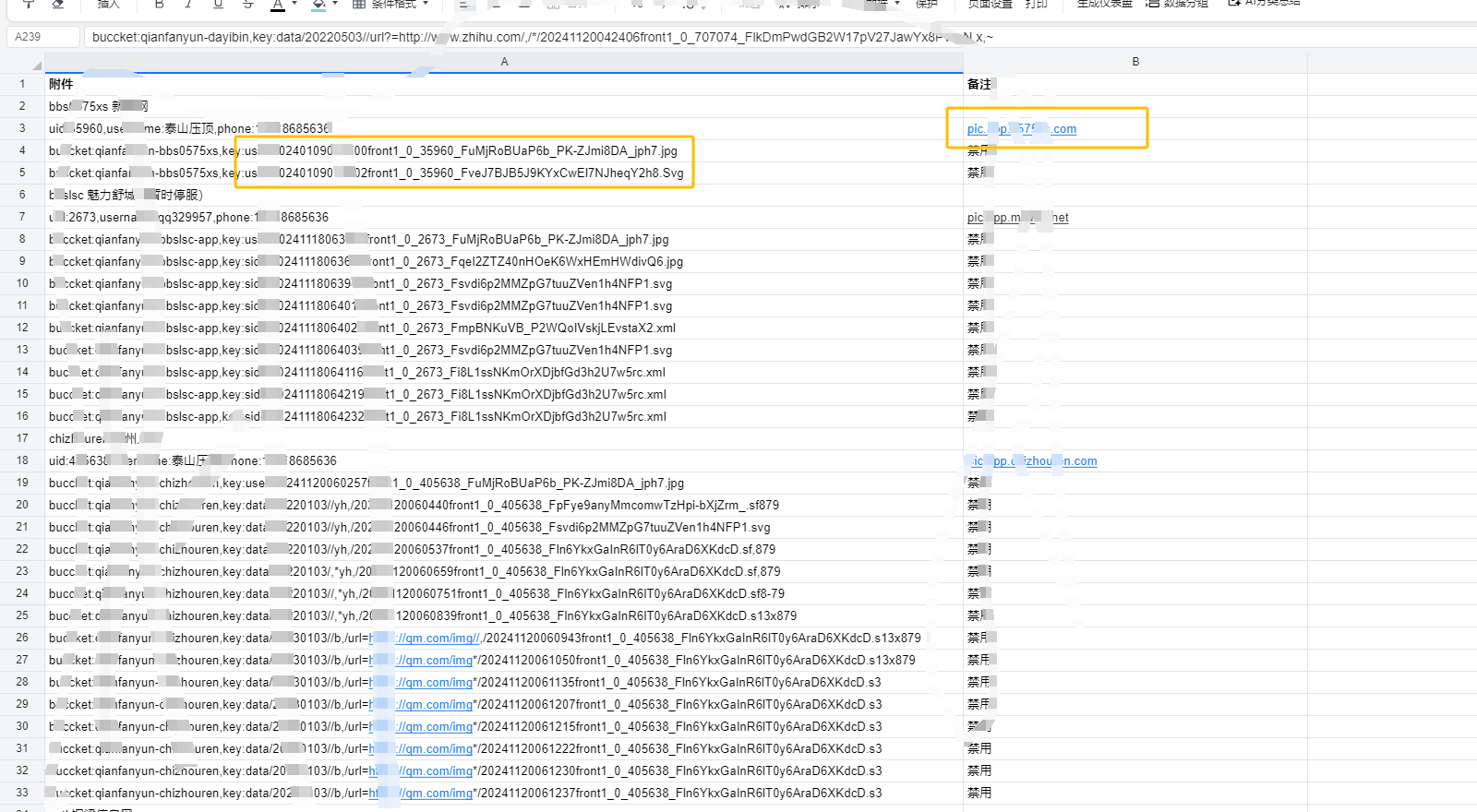
用以下csv表格(如图)用备注列的域名,去拼接url,用request来请求
功能叠加版
我的思路:附件列可以做成字典
第一步用csv操作得到{host:domain}的字典
import csv
import pandas as pd
import traceback
tes1= 'C:/Users/Administrator/Desktop/1212.csv''''这一步用csv处理文件'''
def csv_hostname(csvname):'''通过csv处理得到{hostname:domain}的字典'''hostname_list= []domain_list =[]with open(csvname,'r',encoding='utf8') as f: reader = csv.reader(f)next(reader)for row in reader :for i in row:if " " in i :hostname = i.split()[0]elif i.startswith('pic') :domain_list.append(i)hostname_list.append(hostname)f.close()mes_dict = {hostname_list[i]: domain_list[i] for i in range(len(domain_list))}return mes_dict
使用pandas处理附件列,得到一个新的Series列,加到原来的pandas中(因为太多行了,不好调试,所以加了抛错机制,准备在写一般装饰器的)
try...except...捕获报错
import csv
import pandas as pd
import tracebackpds = pd.read_csv(tes1)def pretreat(cells):try:if ',' in cells and 'uid' not in cells:res_s = cells.split(',')res = []for i in res_s:if ':' not in i and '/' not in i:continueelif ':' not in i and'/' in i :num = res_s.index(i)i = 'key' + str(num) + ':' + ires.append(i)res1 = [i.split(':',1) for i in res]pretreatment = dict(res1)return pretreatmentexcept Exception as e:# 打印详细错误信息print(cells)print(f"错误发生在索引: {pds.index[pds['附件']==cells]}")print(f"错误类型: {type(e).__name__}")print(f"错误信息: {e}")print("完整错误追踪:")traceback.print_exc()print("-" * 50)test=pds['附件'].dropna().apply(pretreat)
pds['pretreatement'] =test
装饰器版
import csv
import pandas as pd
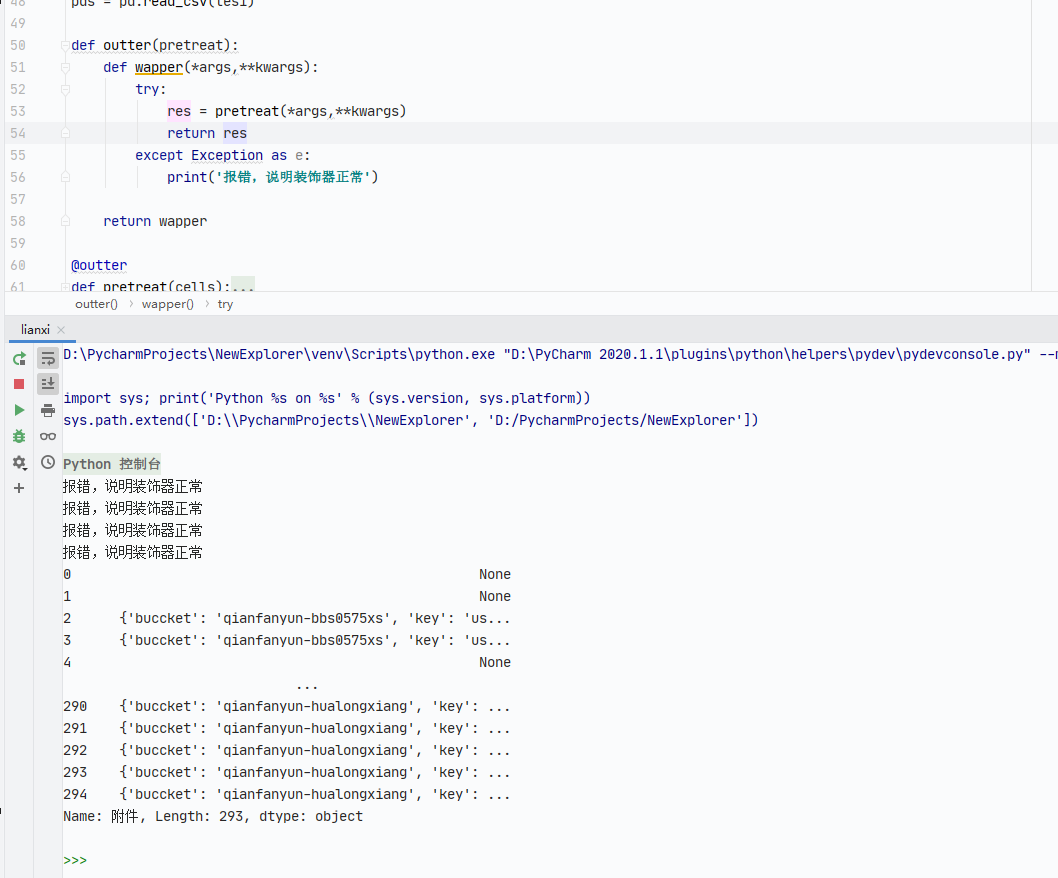
import tracebackpds = pd.read_csv(tes1)def outter(pretreat):def wapper(*args,**kwargs):try:res = pretreat(*args,**kwargs)return resexcept Exception as e:print('报错,说明装饰器正常')return wapper@outter
def pretreat(cells):if ',' in cells and 'uid' not in cells:res_s = cells.split(',')res = []for i in res_s:if ':' not in i and '/' not in i:continueelif ':' not in i and'/' in i :num = res_s.index(i)i = 'key' + str(num) + ':' + ires.append(i)res1 = [i.split(':') for i in res]pretreatment = dict(res1)return pretreatment#### 测试装饰器
test = pds['附件'].dropna().apply(pretreat)
print(test)
保存,因为不想每次都执行函数
pds.to_csv('std.csv',columns=['附件','url_d'])
类的完整版
import csv
import pandas as pd
import traceback
import requests
import timeclass Analysis:def __init__(self,csvname):self.csvname = csvnameself.host_d=self.csv_hostname()def csv_hostname(self):'''通过csv处理得到{hostname:domain}的字典'''hostname_list = []domain_list = []with open(self.csvname, 'r', encoding='utf8') as f: ### name =tes1reader = csv.reader(f)next(reader)for row in reader:for i in row:if " " in i:hostname = i.split()[0]elif i.startswith('pic') or i == 'a01.dqin.cn':domain_list.append(i)hostname_list.append(hostname)f.close()mes_dict = {hostname_list[i]: domain_list[i] for i in range(len(domain_list))}return mes_dictdef host_url(self,cells):'''结合pandas使用'''if ',' in cells and 'uid' not in cells:res_s = cells.split(',')res = []for i in res_s:if ':' not in i and '/' not in i:continueelif ':' not in i and '/' in i:num = res_s.index(i)i = 'key' + str(num) + ':' + ires.append(i)res1 = [i.split(':', 1) for i in res]predict = dict(res1)keys = predict['buccket'].split('-')[1]domain = self.host_d.get(keys)values = [predict[key] for key in predict if key != 'buccket']'''接着改逻辑,因为request 我需要一个人refer,所以{domain:[url,url2]}'''urls = []for i in values:if i.startswith('/'):url = domain + ielse:url = domain + '/' + iurls.append(url)url_d = {domain:urls}return url_ddef url_req(self,cells):domain = list(cells.keys())[0]for url in cells:urls = 'https://' + urlheader = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36','Referer': domain,'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'}try:response = requests.get(urls, headers=header, timeout=10)print(f"状态码: {response.status_code}")except Exception as e:print(urls)print('---------------')print(f"错误: {e}")print('\n')time.sleep(3)
总结
知识点
-
pandas - apply函数:对pandas中整个列操作
eg:pd_test['test'] =pd_test['附件'].dropna().apply(test.host_url) -
pandas - dropna函数:直接去除nan数据

-
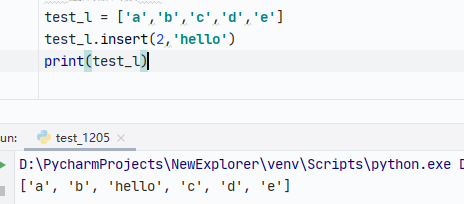
list - insert函数:在某个位置插入数据
-
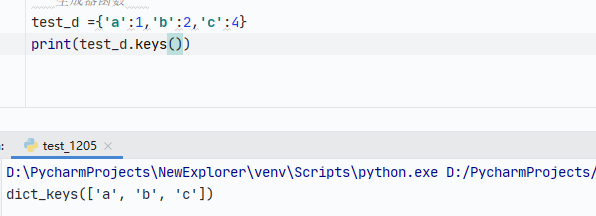
dict - keys函数:获取字典的key,要想取的话,要先转换成列表
总结
split函数和strip函数
无数次的分不清split和strip
-
str.strip([chars]):指定要去除的字符串
-
str.split(sep=None, maxsplit=):将字符串按照指定的分隔符分割成多个子字符串,并返回一个列表(maxsplit:最大分割次数,默认-1表示全部分割)
还有学了一些列表推导式,字典推导式
装饰器
类的self用法
在类的初始化定义中,也可以直接调用下面的方法函数的返回值

1、csv_hostname()函数的返回值,我需要再后续调用,所以我直接写入初始化代码中,即后续代码可以直接调用host_d
2、后续代码要想直接调用host_d,必须要前面加self.,否则会变成__init__函数的局部变量
3、self.host_d=self.csv_hostname():csv_host前加.self的原因是:csv_host是实例方法,需要前加.self;否则会在__init__找csv_host方法,找不到报错
我的处理逻辑是:有上一步函数的结果返回值,才能进行下一步的函数执行;以为用类不行,没想到正好,解决了我不想每次处理,都要从上到下,全部执行一遍,就像上面的host_d这个值,之前每次都要执行,现在实例化执行一次之后,就保存了,可以随时访问