基础知识
注释
(1) # 基本注释 ctrl+/ 快捷键
(2)多行注释
"""
多行注释 一般写在程序开头上方
"""
(3)TODO注释
用于提醒后续完善代码
注释方法
# TODO: 描述需要完成的工作补充责任人或时间:要是有明确的负责人,或者希望为任务设定一个时间限制
注释方法
# TODO(alice): 在用户登录时添加密码加密功能(截止日期:2025/07/15)记录待解决的问题:对于临时采用的解决方案,或者已知存在的问题
注释方法
# TODO: 此处使用了硬编码的数据库连接,后续需要改为配置文件读取
大项目中会对TODO扫描,不能有残留
(4)其他注释
FIXME:表示代码存在问题,需要进行修复。
HACK:意味着采用了临时的解决方案。
XXX:用于标记危险或者有风险的代码。
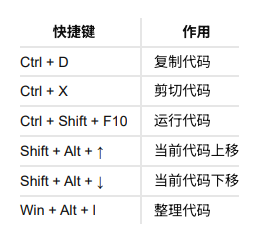
快捷键
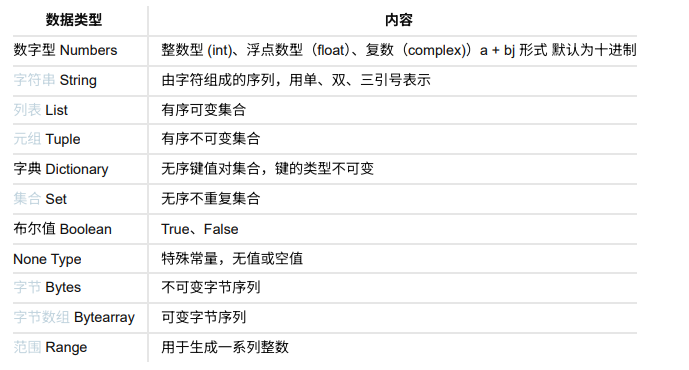
数据类型
数据类型转换
“万物”------都可转换-----→字符串
字符串(必须为数字)------才可以-----→数字
#数据转换方法:目标格式(被转换变量)
int(x)
float(x)
str(x)
变量定义
x = 1
a,b,c =1, 2, 3
# 注意:变量无类型,变量存储的数据有类型
变量作用域
(1)内置作用域:预定义变量
(2)全局作用域:所编写整个程序----全局变量(注意:若想要将函数内变量声明为全局变量,则使用 global 关键字)
(3)局部作用域:某函数内部(注意:局部作用域内可引用全局变量,但不可修改)----局部变量(函数内变量)
global 声明使用、改全局变量
nonlocal 声明使用、改外层函数的局部变量
x = 100 # 全局变量def outer():x = 10 # 外层函数的局部变量def inner_global():global x # 声明使用全局变量 xx = 200 # 修改全局变量def inner_nonlocal():nonlocal x # 声明使用外层的局部变量 xx = 20 # 修改外层局部变量inner_global()print("After inner_global:", x) # 输出 10,外层变量未被修改inner_nonlocal()print("After inner_nonlocal:", x) # 输出 20,外层变量被修改outer()
print("Global x:", x) # 输出 200,全局变量被修改
函数内变量优先用局部变量,global声明只是修改全局变量,并不会影响函数内用的变量值
变量名规范
标识符规范(变量、类、方法名)
(1)内容限定:英文、中文(不推荐)、数字(不能放在首位)、下划线
(2)简洁明了:见名知意
(3)大小写敏感:变量名中字母小写
(4)非法字符:不用关键字
(5)常量:建议全部大写字母
运算符
# 算术运算符
+ 、- 、* 、/ 、//(取整向下)、%(取余)、**(指数)# 赋值运算符
=# 复合运算符
+= 、-= 、*= 、/= 、%= 、**= 、//=# 比较运算符
== 、!= 、> 、< 、>= 、<= 、 is(用来检查对象的标示符是否一致,也就是比较两个对象在内存中的地址是否一样) 符合则返回True# 逻辑运算符
and 、or 、not# 成员运算符
in(在指定对象中返回True,否则False) 、not in(在指定对象中返回False,否则返回True)# 位运算符
&(按位与:有0为0)、|(按位或:有1为1)、^(按位异或:同0异1)、~(按位取反:0为1,1为0)、<<(左移n位则2^n)、>>(右移n位则除2^n)
优先级
()小括号 > x[i]索引 > x.attribute属性访问 > **乘方 > ~按位取反 > 一元正负号 > 乘除 > 加减 > 位移 > 按位与 > 异或 > 或 > 比较 > is > in > 非 > 与
内置常量
逻辑假:False, None, 0, "", {}, (), []
其余均为逻辑真
输出语句
语法:print(字面量)
默认输出末尾添加换行符
在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法
常见的字面量类型: 整数, 浮点数, 字符串
字面量拼接语法:
print(" " + " ")
例子:print("我是" + name + "住在" + address)
end特殊用法:
# 使print()输出内容不换行
print("Hello", end='')
# 使print()输出内容末尾处理
print("Hello", end='(空格)')
print("Hello", end=',')制表符 \t
换行符 \n
输入语句
n = input("内容")
类型查看
语法 : id(object)
主要特点:
- 返回值:返回一个整数,这个整数在对象的生命周期内是唯一且恒定的
- 唯一性:在同一时刻,不同的对象不会有相同的 id
- 内存地址关联:在 CPython 解释器中,这个 id 通常对应着对象在内存中的地址
注意: 对于不可变对象(如整数、字符串),Python 可能会有缓存机制,导致不同变量引用相同值时具有相同 id 当对象被销毁后,其 id 可能会被重新分配给新的对象 id() 函数通常用于检查两个变量是否指向同一个对象(即是否为同一引用)
type用于查看数据类型,也存在返回值
# 查看变量内存储的数据类型
print(type())
# 使用变量存储type()语句结果
string_type = type(" ")
isinstance用于检查一个对象是否是指定类(或元组中列出的多个类之一)的实例 返回值是布尔值 True 或 False,表示对象是否是指定类的实例
# 语法
isinstance(object, classinfo)
参数:
object:要检查的对象
classinfo:可以是一个类,或者多个类组成的元组注意:与 type() 函数不同,isinstance() 会考虑继承关系,即如果一个对象是某个类的子类的实例,它也会返
回 True。
随机
import random # 导入随机数模块# 生成含a和b的范围内随机整数
num = random.randint(a, b)# 生成一个0到1之间的随机浮点数
num = random.random()# 生成一个在a到b之间的随机浮点数
num = random.uniform(start, end)# 生成含start不含end范围内的随机整数
num = random.randrange(start, end)# 从序列seq中随机选择一个元素
num = random.choice(seq)# 随机打乱序列x中的元素
num = random.shuffle(x)# 从m中随机获取t个元素,不重复
num = random.sample(m, t)
范围 range()
语法: range(num_1, num_2, step)
解释: num_1为起始值(包含,默认为0),num_2为终止值(不包含,必须指定),step为步长(默认为1)
字符串
引号
'写单行'"写单行""""
写好几段
"""'111"里外层符号不能一样,外双里就必须双"111'
在python3中, 字符串是使用的Unicode. 支持多语言, 包括中文, 类型是str。也可以认为是utf-8 (utf-8是基于unicode编码的一种节约字节的编码,为了节省大小, 就出现了utf-8, 使用1到4个字节进行存储,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4个字节)。参考文章: https://www.zhihu.com/question/23374078/answer/69732605
在python中, 常用到的编码和解码的方法是:编码, encode ;解码: decode
格式化
占位符 % 语法: python message = "%d%s"%(num, string)
多个变量占位,变量用括号括起来,并依次填入
%m,nd %m,nf
m:控制宽度,要求是数字,宽度小于数字自身时不生效
n:控制小数点精度,要求是数字,小数四舍五入%s 转化为字符串
%d 或 %i 转化为整数
%f 转化为浮点型
格式化字符串字面值 f-strings 方法 f 或 F (python 3.6++)
语法: f"内容{变量}" 不限类型和精度,括号内可以表达式求值
# 浮点数控制精度 {value:.nf} n表示保留的小数位数 注意此处详细作用为:固定小数位数四舍五入
pi = 3.1415926
print(f"π 约等于 {pi:.2f}") # 保留2位小数,输出:π 约等于 3.14
print(f"π 约等于 {pi:.4f}") # 保留4位小数,输出:π 约等于 3.1416# {value:.n} 注意此处详细作用为:限制总位数(可能改变整数部
分)
print(f"总位数4: {num:.4}") # 输出:123.5
print(f"总位数2: {num:.2}") # 输出:1.2e+02(科学计数法)# 百分比精度控制 {value:.n%} 自动将数值乘以100并添加百分号
score = 0.875 print(f"得分率: {score:.1%}") # 输出:得分率: 87.5%# 科学计数法精度控制 {value:.ne} n表示有效数字位数
large_num = 123456789
print(f"科学计数法: {large_num:.2e}") # 输出:科学计数法: 1.23e+08# 字符串截断精度 {value:.n}注意此处n后没有f n表示截断字符串至第n个字符
text = "Hello, World!"
print(f"简短文本: {text:.5}") # 输出:简短文本: Hello# 组合格式化 结合宽度、对齐和精度控制
num = 3.14159
print(f"|{num:>10.3f}|") # 右对齐,总宽度10,保留3位小数
# 输出:| 3.142|# 数字补位
number = 7
padded = f"{number:04d}" # 输出:"0007"
注意:对整数使用 .f 会报错,整数无需精度
重点: value:.nf 带 f :专门用于浮点数,控制小数部分的位数
重点: value:.n 不带 f :对浮点数,控制总位数(可能影响整数部分);对字符串,截断字符串长度
format() 方法
基本语法:"{str}, {str1}".format(str, str1)
索引指定参数:print("{1} {0}".format("World", "Hello")) # 输出:Hello World
关键字指定参数: print("{name} {age}岁".format(name="Bob", age=25)) # 输出:Bob 25岁
访问对象的属性或方法:
class Person:def __init__(self, name, age):self.name = nameself.age = age
p = Person("Charlie", 35)
print("{p.name} 今年 {p.age} 岁。".format(p=p)) # 输出:Charlie 今年 35 岁。
精度控制
# 浮点数精度
pi = 3.14159
print("{0:.2f}".format(pi)) # 输出:3.14(保留2位小数)
# 字符串截断
text = "Hello"
print("{0:.3}".format(text)) # 输出:Hel(截断至3个字符)
对齐与宽度
# 右对齐,宽度10
print("{:>10}".format("Apple")) # 输出: Apple
# 左对齐,宽度10
print("{:<10}".format("Apple")) # 输出:Apple
# 居中对齐,宽度10
print("{:^10}".format("Apple")) # 输出: Apple
填充字符
# 用*填充,右对齐
print("{:*>10}".format("Apple")) # 输出:*****Apple
# 用0填充,数字补零
print("{:0>5d}".format(42)) # 输出:00042
数值格式化
# 千位分隔符
num = 1234567
print("{:,}".format(num)) # 输出:1,234,567
# 百分比
percent = 0.75
print("{:.1%}".format(percent)) # 输出:75.0%
# 科学计数法
large = 123456789
print("{:.2e}".format(large)) # 输出:1.23e+08
混合使用
data = {"name": "David", "age": 40, "score": 92.5}
print("{name}的分数是{score:.1f},排名{rank:02d}".format( name=data["name"],
score=data["score"], rank=3 ))
# 输出:David的分数是92.5,排名03
字符串函数
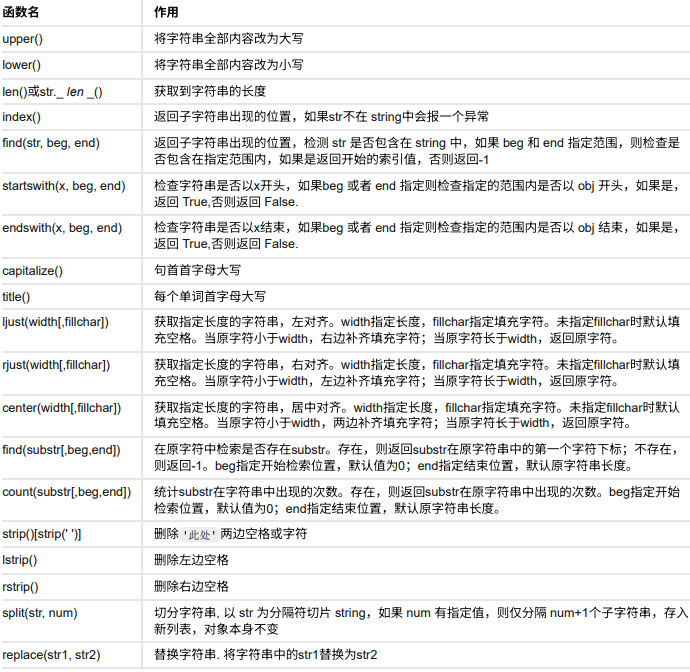

拆分 split(sep, num) : num 指定拆分次数( "a,b,c".split(",",1), 输出 ["a","b,c"] )。
替换 replace(old, new, count) : count 指定替换次数。
3. 拼接 join(seq) :仅支持字符串序列,效率远高于 + ( "|".join(["a","b"]), 输 出"a|b" )
语句结构
顺序、选择、循环
顺序结构
程序会按照代码编写的先后顺序,依次执行每一条语句,直到程序结束
选择结构 if
if(条件表达式_1):语句_1
elif(条件表达式_2):语句_2
else: # 此处条件默认,不得添加条件语句_3
其判断结果均为布尔型,不要忘记判断条件后的冒号,归属语句代码前4格空格或Tab缩进
循环结构
while循环
while 条件(布尔类型、比较类型):循环体(满足条件时运行)
for循环(序列类型,遍历循环)
for循环采用轮询机制,对内容逐个处理,无法定义循环条件
for 变量 in 可迭代对象:循环体
循环中断
continue语句
for i in range(1, 100):循环语句 # 中断本次循环continue # 直接下次循环
break语句
for i in range(1, 100):语句break # 中断此循环,跳出该循环执行后面的语句
第一周题目
-
Python 中 int(3.9) 的结果是
3。 -
嵌套函数中修改外层局部变量的关键字是
nonlocal,修改全局变量的关键字是global。 -
执行 print(-5 // 2) 的结果是
-3,执行 print(-5 % 2) 的结果是1。 -
用 join() 拼接列表 ["Python","速成","课"] 为 Python|速成|课 的代码是
"|".join(["Python","速成","课"])。 -
一行多变量赋值 a,b = 1 报错的原因是
前后参数输入数量不对应; input() 接收的用户输入默认是string类型。 -
阅读以下代码,回答问题:
x = 100
def outer():x = 10def inner():x = 200inner()
outer()
print(x)
题目:由该代码可知,定义了整型 x ,并初始化赋值了 100 ,内层函数修改了 x=200 ,但是 又被外层函数调用,又得到了 x=10 ,所以当 outer() 被调用后,输出的结果为10。 请说出你的看法:
outer() 被调用后输出结果还是100。因为在函数中定义的变量作用域只在函数内部,outer()inner()函数调用并不影响全局变量x=100,且print语句不在函数内,因此调用到的x是全局变量x=100
sep_line = "="*5 + "Python" + "="*5
print(sep_line)
题目:由该代码可知,对字符串 "=" 进行了前后5次重复,并进行了拼接,输出的结果是 =Python= 请说出你的看法:
输出结果为=====Python=====,+和*可拼接字符串或列表
lst = [10, 20, 30]
a, b = lst
print(a, b)
题目:由该代码可知,解包赋值会依次取列表的前两个元素赋值给 a 和 b,输出结果是 10 20。 请说出你的看法:
错误,该段代码会报错,在解包赋值时需要用*接收剩余变量数,若变量数与数据输匹配不上会报错
a = b = [1, 2, 3]
b.append(4)
a.append(6)
c = a + b
print(c)
题目:由该代码可知,链式赋值会分别给 a、b 赋值为列表 [1,2,3],修改 b 后仅影响 b, 修改 a 后仅影响 a ,然后拼接 a , b 得到 c ,输出结果是 [1,2,3,6,1,2,3,4]。 请说出你的看法:
使用 append() 函数添加列表时,是添加列表的引用地址而不是添加列表内容,当被添加的列表发生变化时,添加后的列表也会同步发生变化,所以应该输出[1, 2, 3, 4, 6, 1, 2, 3, 4, 6]
生活需求
小明和小红共享一份购物清单 shop_list (清单内数字为商品价格, 0 代表已下架商品), 清单初始内容为 [25, 0, 18, 32, 0, 15] 。两人分别在各自手机上查看这份清单(小明手机端清单名为 my_list ,小红手机端清单名为 your_list ),因清单为共享状态会同步。
请完成以下操作,并用代码实现:
1.数据清理:用 while 循环遍历清单,移除所有值为 0 的下架商品,遍历过程中必须使 用 continue 控制逻辑;
- 数据解构:从清理后的清单中提取前 2 个商品价格(分别赋值给 price1、price2 ),剩 余商品价格用 *other_prices 接收;
- 内存验证:验证小明和小红手机上的清单是否为同一份(通过内存地址判断);
- 总价计算:用 while 循环计算清理后清单中所有商品的总价(禁止使用 sum() 内置函 数);
- 优惠计算:基于总价计算优惠价(总价整除 2,使用 // 运算符);
- 结果输出:按指定格式打印所有关键结果(清单内容、内存验证结果、价格解构结果、总 价、优惠价)。
前提假设:
清理后的清单长度不少于 2,可正常提取前 2 个价格;
所有操作基于共享清单完成,最终以清理后的清单作为结账依据。
请写出你的代码:
shop_list = my_list = your_list =[25, 0, 18, 32, 0, 15]
shop_li = []i = 0
sum = 0
while i<len(shop_list):if shop_list[i]==0:i += 1continueshop_li.append(shop_list[i])print(shop_list[i])sum += shop_list[i]i+=1print("清洗后列表:",shop_li)
price1,price2,*other_prices = shop_li
print("前两个商品价格为",price1,price2)
print("总价为:",sum)
print("折后为",sum//2)
if id(my_list) == id(your_list):print("同一份")
else:print("不同一份")