一、前期调研
1.小红书爬虫——买菜分量困扰分析和关于食材预处理的看法
(1)买菜分量困扰分析
情感倾向:严重消极(88.9%消极 vs 11.1%积极)

高频词汇:“吃不完”,“一个人”,“不够”等

词云分析:“一个人”,“吃不完”,“垃圾桶”,“浪费”,“不够”等占多数

核心矛盾:分量控制与食材浪费的持续斗争
用户画像:主要为一⼈食、宿舍党、独居青年
问题集中度:食材浪费>分量控制>时间成本
(2)关于食材预处理的看法
情感倾向:消极(72.7%消极 vs 27.3%积极)

词云分析:“麻烦”“时间”“烦死”占比较多

高频词汇:"麻烦"出现8次

评论数量:分析约150条用户评论
核心问题:菜品预处理过程耗时、繁琐
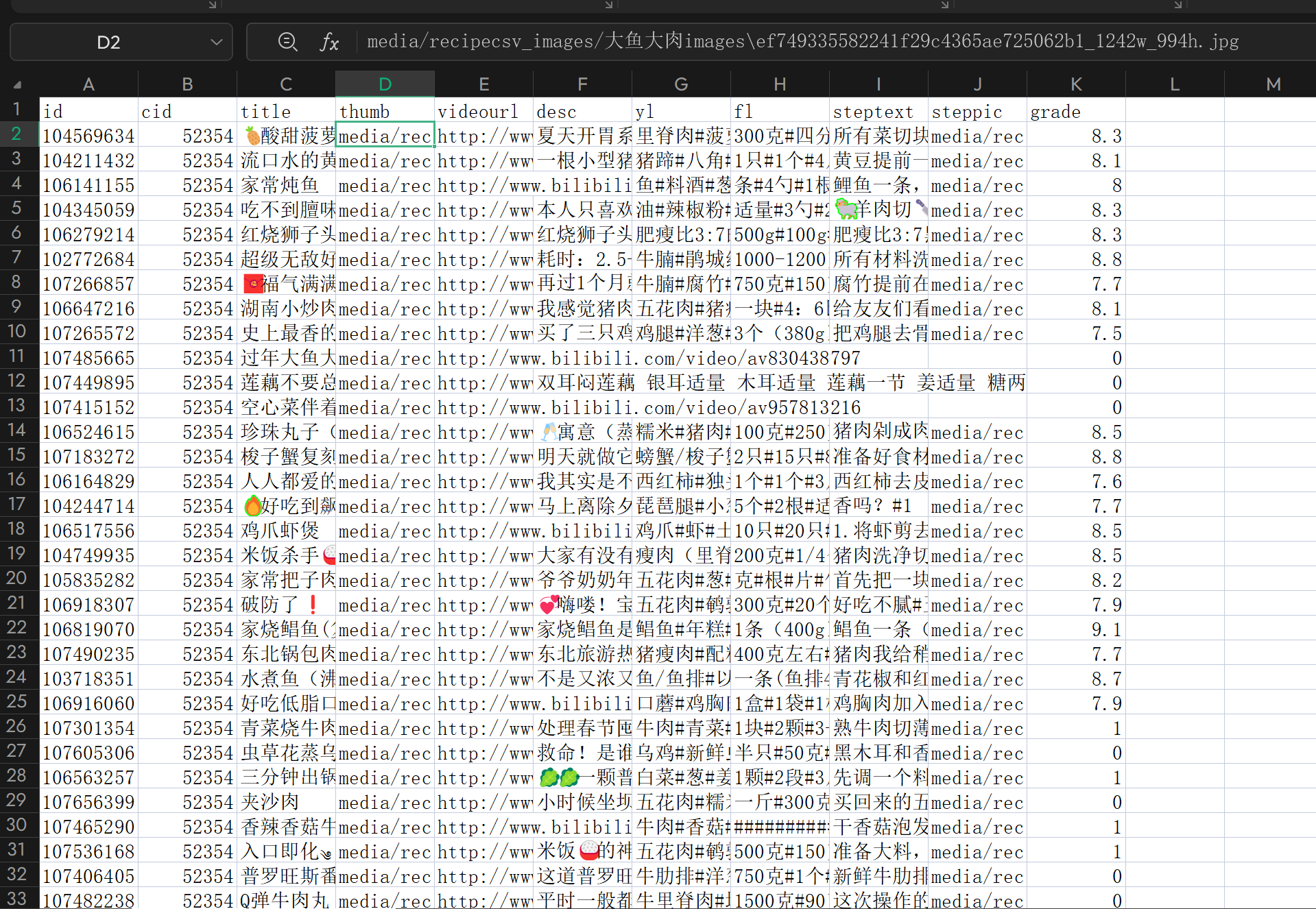
二、将爬取的食材,食谱,教程图片下载到本地,并修改url为本地路径
1.下载图片到本地

修改后表中的url路径
2.核心代码示例
点击查看代码
def main():print("开始处理CSV图片下载...")# 配置input_csv = "菜谱/大鱼大肉_updated.csv"output_csv = "菜谱/大鱼大肉_updated_local.csv"image_dir = "media/recipecsv_images/大鱼大肉images"# 检查文件是否存在if not os.path.exists(input_csv):print(f"错误: 找不到文件 {input_csv}")return# 创建图片目录os.makedirs(image_dir, exist_ok=True)# 读取CSVrows = []try:with open(input_csv, 'r', encoding='utf-8') as f:reader = csv.reader(f)rows = list(reader)except:# 尝试其他编码with open(input_csv, 'r', encoding='gbk') as f:reader = csv.reader(f)rows = list(reader)print(f"读取到 {len(rows)} 行数据")# 处理数据count = 0for i, row in enumerate(rows):if i == 0: # 跳过标题行continue# 处理第4列 (thump)if len(row) > 3:url = row[3]if url and url.startswith('http'):local_path = download(url, image_dir, f"img_{i}_thump")if local_path:row[3] = local_pathcount += 1# 处理第10列 (steppic)if len(row) > 9:url = row[9]if url and url.startswith('http'):local_path = download(url, image_dir, f"img_{i}_step")if local_path:row[9] = local_pathcount += 1# 保存结果with open(output_csv, 'w', encoding='utf-8', newline='') as f:writer = csv.writer(f)writer.writerows(rows)print(f"处理完成!")print(f"下载图片: {count} 张")print(f"图片保存到: {image_dir}")print(f"新CSV文件: {output_csv}")def download(url, save_dir, prefix):"""下载图片"""try:# 生成文件名ext = '.jpg'if '.png' in url.lower():ext = '.png'elif '.gif' in url.lower():ext = '.gif'filename = f"{prefix}_{int(time.time() * 1000)}{ext}"save_path = os.path.join(save_dir, filename)# 下载response = requests.get(url, timeout=15)response.raise_for_status()with open(save_path, 'wb') as f:f.write(response.content)return save_pathexcept Exception as e:print(f"下载失败 {url[:30]}...: {e}")return None
三、攥写综合实践报告
最后,我总结了我们项目的所有流程,攥写了综合实践报告
四、心得体会
通过本次“食鲜配・智厨”综合实践项目的完整实施,我对数据驱动产品设计与智能系统开发的整体流程有了更加直观和深入的认识。从最初的需求调研,到数据采集与分析,再到系统功能实现与最终报告撰写,每一个环节都紧密衔接、相互影响,使我真正体会到理论知识在实际项目中的应用价值。
在前期调研阶段,通过对小红书平台用户内容的爬取与情感分析,我第一次系统性地将文本挖掘技术与真实生活场景问题相结合。分析结果清晰地揭示了独居人群和一人食用户在买菜分量控制、食材浪费以及食材预处理过程中的普遍困扰,这一过程不仅验证了项目选题的现实意义,也让我深刻认识到数据背后所反映的用户真实需求。相比主观猜测,基于数据得出的结论更加客观,也更具说服力。
在数据处理与系统实现阶段,我进一步体会到了工程实践的重要性。例如,将爬取到的食材、菜谱及教程图片统一下载到本地并修改数据库中的 URL 路径,看似是一个细节问题,但实际上关系到系统的稳定性、安全性以及后续部署的可行性。在编写和调试相关代码的过程中,我对文件处理、异常处理以及数据一致性有了更清晰的理解,也提升了自己独立解决问题的能力。
在整个项目推进过程中,我逐渐意识到,一个完整的信息系统不仅仅是功能的简单堆砌,而是需要在用户体验、技术实现与实际应用场景之间取得平衡。例如,在设计“商品—菜谱”双向推荐和 AI 烹饪辅助功能时,必须同时考虑算法逻辑的合理性与普通用户的使用习惯,这让我对“以用户为中心”的设计理念有了更加深刻的体会。
总体而言,本次综合实践不仅巩固了我在数据分析、Web 开发和系统设计等方面的专业知识,也锻炼了我将复杂问题拆解并逐步落地实现的能力。同时,该项目也让我认识到自身在算法优化、系统性能和产品细节打磨等方面仍存在不足,为今后的学习与实践指明了努力方向。本次实践经历为我后续深入学习相关技术、参与更复杂的实际项目奠定了坚实基础,具有重要的学习与实践意义。