目录
- 一、项目概述
- 二、数据采集前期准备
- 1. 明确数据需求与核心指标
- 2. 权威数据源调研与验证
- 3. 采集技术方案选型
- 4. 开发环境搭建与配置
- 三、核心采集模块实现
- 1. 结构化数据采集
- 2. 图片数据采集
- 3. 非结构化数据采集
- 四、数据清洗与格式标准化
- 1. 出生人口数据清洗
- 2. 政策文件数据清洗
- 3. 图片文件数据清洗
- 4. 合并数据
- 五、成果展示
- 六、总结收获
一、项目概述
为推进本组 “基于多源政策文本与人口数据的福州市出生人口趋势预测系统” 研发,我负责数据采集模块工作,需自动化获取、清洗与整合相关政策文本及人口数据,为后续建模预测提供高质量数据支撑,助力系统顺利落地。
二、数据采集前期准备
在正式开展数据采集工作前,为确保采集流程高效、数据质量可控,我完成了多维度的前期筹备工作,核心围绕“数据需求梳理、数据源调研验证、技术方案选型、环境搭建配置”四大环节展开,具体如下:
1. 明确数据需求与核心指标
结合“福州市出生人口趋势预测”的核心目标,我打算采集三类关键数据:
- 结构化人口数据:核心指标为历年出生人数、出生率、城镇化率等,用于构建人口趋势基础数据集;
- 图片类经济数据:核心指标为历年GDP数据,作为影响出生人口的关键经济变量补充;
- 非结构化政策文本:核心围绕生育补贴、生育登记、人口自然增长等相关政策,用于分析政策对出生人口的调控作用。
2. 权威数据源调研与验证
为保障数据真实性和可靠性,重点调研政府官方渠道,完成数据源筛选与可用性验证:
- 福州市统计局官网(https://www.fuzhou.gov.cn/zgfzzt/tjnj/ ):确认该网站发布历年统计年鉴,其中“03-03”章节包含完整的出生人口结构化数据,部分经济数据(如GDP)以可视化图片形式呈现,支持浏览器直接访问和资源下载;
- 福建省发展和改革委员会官网(https://fgw.fujian.gov.cn/ ):核实网站提供站内搜索功能,可通过“生育政策”等关键词检索相关政策文件,且政策详情页结构规范,便于解析提取文本内容;
3. 采集技术方案选型
根据不同数据类型的存储形式和获取难度,针对性制定采集技术方案:
- 结构化数据(Excel):采用Python requests库模拟浏览器请求,结合urllib.parse处理URL拼接,实现统计年鉴Excel文件的批量下载;
- 图片数据(GDP图表):通过requests库下载网页中的图片资源,后续搭配Tesseract OCR技术实现图片中数值的提取,同时准备备用数据兜底方案,应对OCR识别失败场景;
- 非结构化政策文本:采用“POST请求调用搜索接口+BeautifulSoup解析HTML”的组合方案,先批量获取政策详情页URL,再逐页提取标题、发布时间、正文等信息,结合关键词筛选有效内容。
4. 开发环境搭建与配置
完成Python开发环境的搭建与依赖库安装,保障采集代码可正常运行:
- 基础环境:配置Python 3.8+版本,创建独立虚拟环境避免依赖冲突;
- 核心库安装:安装requests(网络请求)、BeautifulSoup4(HTML解析)、pandas(数据处理)、Pillow(图片处理)、pytesseract(OCR识别)等依赖库,命令如下:
pip install requests beautifulsoup4 pandas pillow pytesseract - 辅助配置:下载 Tesseract OCR 工具并配置系统环境变量,确保 pytesseract 可正常调用;准备停用词库文件,用于后续政策文本的关键词筛选清洗;创建 “福建计生政策文件”“福州统计年鉴 3-3 数据” 等输出文件夹,提前规划数据存储结构。
- 环境变量配置:找到 Tesseract OCR 安装目录(默认
C:\Program Files\Tesseract-OCR),将其添加至系统 PATH 变量,重启命令行后通过tesseract --version验证配置有效性; - 停用词库准备:整理中文通用停用词及政务文本专用停用词(如“为了”“根据”“特此通知”等),保存为
stopwords.txt文件,便于后续过滤政策文本中的无效词汇; - 文件夹规划:按数据类型分类创建存储目录,结构化数据、图片数据、政策文本分别存放,避免后续数据混乱,同时为清洗后的最终数据集预留独立文件夹,保障数据流转清晰。
- 环境变量配置:找到 Tesseract OCR 安装目录(默认
三、核心采集模块实现
1. 结构化数据采集
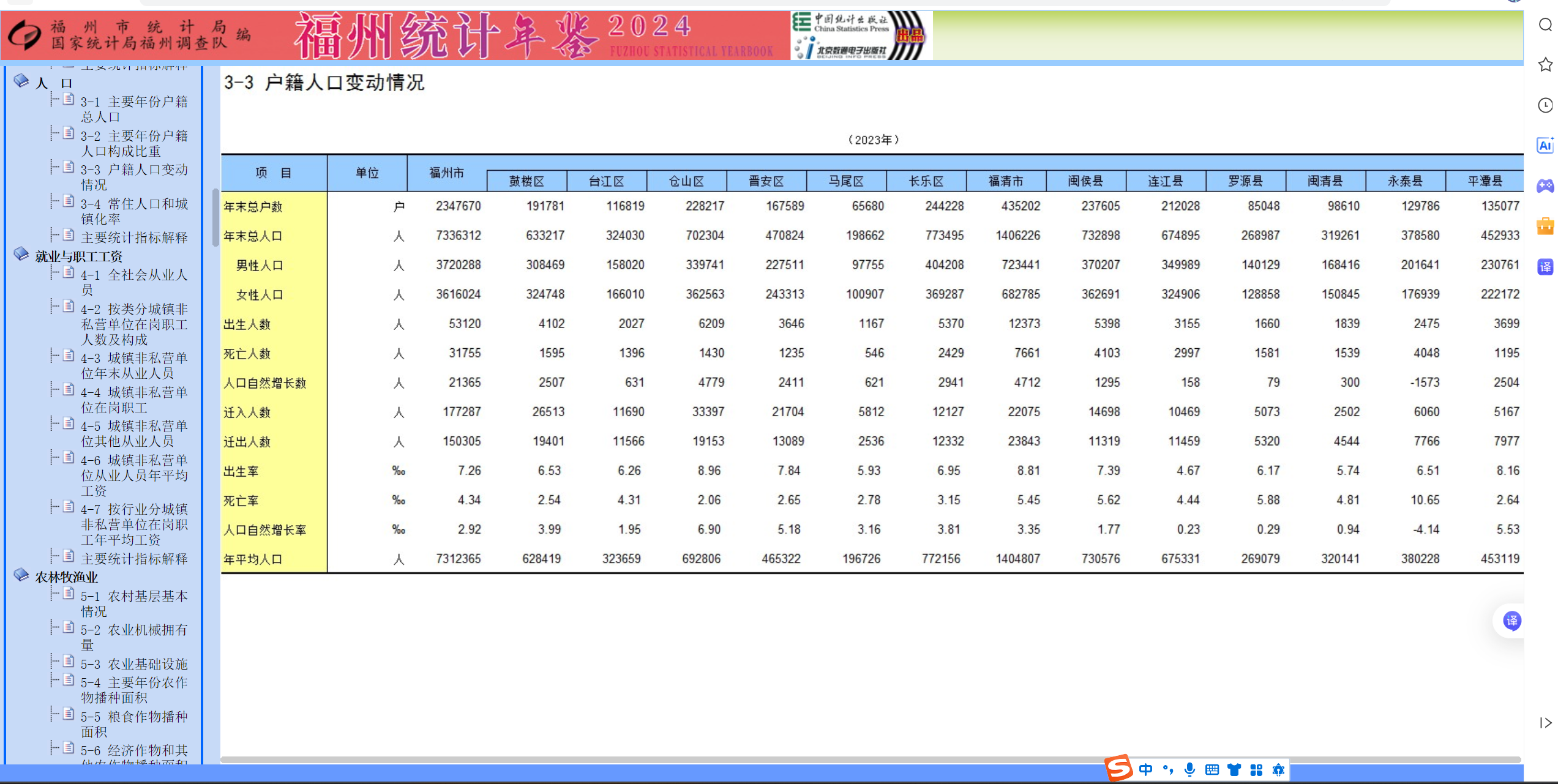
对于人口数据,为了保证数据的真实性与可靠性,我决定从官方网站福州市统计局(https://www.fuzhou.gov.cn/zgfzzt/tjnj/ )进行爬取。该网站对每年各地市的出生人口都做了统计,数据形式为结构化数据,可直接下载Excel表。

代码说明
自动化批量下载福州市统计年鉴中 2016-2024 年的 “03-03” 章节 Excel 数据(对应人口出生相关统计表格)等文件,并按年份规整保存到指定文件夹。具体实现中,通过遍历年份构造下载链接,设置请求超时与重试机制,避免网络波动导致的下载失败,同时对下载文件进行重命名(如“2016年3-3数据.xls”),提升文件可读性。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5/%E5%87%BA%E7%94%9F%E4%BA%BA%E5%8F%A3%E7%88%AC%E5%8F%96.py
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5/%E4%B8%BB%E8%A6%81%E5%B9%B4%E4%BB%BD%E6%88%B7%E7%B1%8D%E6%80%BB%E4%BA%BA%E5%8F%A3%E5%92%8C%E5%9F%8E%E9%95%87%E5%8C%96%E7%8E%87%E7%88%AC%E5%8F%96.py
2. 图片数据采集
对于GDP数据,依旧从官方网站福州市统计局(https://www.fuzhou.gov.cn/zgfzzt/tjnj/ )进行爬取,发现网页中GDP数据是以可视化柱状图的图片形式存在,无法直接获取结构化数值,因此先完成图片资源的批量下载。

代码说明
模拟浏览器正常访问,通过解析统计年鉴网页的HTML结构,定位GDP图片对应的<img>标签,提取图片src属性并拼接为完整下载链接,使用requests库下载图片文件并保存到“福州GDP图片数据”文件夹,命名格式为“福州GDP走势图_年份.jpg”,确保图片与年份一一对应,为后续OCR识别做好准备。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5/GDP%E5%9B%BE%E7%89%87%E7%88%AC%E5%8F%96.py
3. 非结构化数据采集
对于政策文件,我爬取了福建省发展和改革委员会官方网站(https://fgw.fujian.gov.cn/ )。该网站提供了站内高级搜索接口,支持按关键词、栏目、时间等条件筛选,可通过接口批量获取相关政策文件,无需逐页手动浏览。
代码说明
通过 POST 请求调用网站站内搜索接口,以 “生育政策” 为核心关键词,搭配“出生人口”“生育补贴”“人口自然增长”等辅助关键词,设置爬取页数与每页条数,批量获取多页政策文件的详情页 URL。随后遍历所有URL,使用BeautifulSoup解析详情页HTML,提取政策标题、发布单位、发布时间、正文内容等信息,通过关键词二次筛选过滤无关文件,最终将符合条件的政策文本以TXT格式保存到“福建计生政策文件”文件夹,形成结构化本地文本数据集。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5/%E6%94%BF%E7%AD%96%E6%96%87%E6%9C%AC%E7%88%AC%E5%8F%96.py
四、数据清洗与格式标准化
1. 出生人口数据清洗
对于爬取到的出生人口数据和城镇化率,使用“出生人口处理.py”文件进行数据清洗。原始Excel数据存在部分格式不统一、区县名称不一致、空值缺失等问题,需要进行标准化处理。
代码说明
针对存放于 “福州统计年鉴 3-3 数据” 文件夹中的 2015-2023 年的 Excel 文件,通过pandas库读取文件数据,先筛选出“福州市”及下辖鼓楼区、台江区、仓山区、福清市等目标区县的记录;再统一区县名称格式,修正错别字与简称差异;随后提取“出生人数”“出生率”等核心指标,填充合理空值,剔除无效异常数据;最后按年份与区域进行汇总,统一调整年份口径,生成 2015-2023 年福州各区域出生人数汇总表,保存为标准化Excel文件。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5/%E5%87%BA%E7%94%9F%E4%BA%BA%E5%8F%A3%E5%A4%84%E7%90%86.py
2. 政策文件数据清洗
对于爬取到的政策文件,使用“政策处理.py”文件进行数据清洗。原始政策文本存在格式混乱、冗余信息过多、编码不一致等问题,需进行结构化整理与关键词分析。
代码说明
通过Python批量读取“福建计生政策文件”文件夹中的TXT文件,先进行编码统一(转为UTF-8)与格式清洗,去除网页残留的HTML标签、多余空格与换行符;再利用停用词库过滤无效词汇,通过jieba分词进行文本分词处理;随后提取政策中的核心关键词,统计关键词出现频次,分析政策聚焦方向;最后将政策标题、发布时间、核心内容、关键词、政策类型等信息结构化汇总,生成标准化 Excel 分析报告,便于后续政策影响分析。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5/%E6%94%BF%E7%AD%96%E6%96%87%E6%9C%AC%E5%88%86%E6%9E%90%E7%BB%93%E6%9E%9C.py
3. 图片文件数据清洗
对于爬取到的图片文件,使用“OCR识别图片.py”文件进行数据清洗。GDP图片中的数值需要从可视化图像转为结构化数字,需通过OCR识别与数据校验实现。
代码说明
通过Pillow库对GDP图片进行预处理,先转为灰度图减少色彩干扰,再进行二值化处理提升文字与背景的对比度,保存预处理后的图片用于调试;随后调用Tesseract OCR工具识别图片文字,通过正则表达式匹配“年份+GDP数值+亿元”的格式,提取原始数据;再对提取的数据进行类型转换与合理性校验,过滤超出合理范围的异常值;最终生成标准化的 Excel 格式 GDP 数据集,若OCR识别失败则输出预设兜底数据,保障数据完整性。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5/OCR%E8%AF%86%E5%88%AB%E5%9B%BE%E7%89%87.py
4. 合并数据
代码说明
整合、清洗、补全福州市及下辖县级单位的多维度人口与经济数据,最终生成标准化的完整数据集
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/综合实践/15-23完整数据.py
五、成果展示
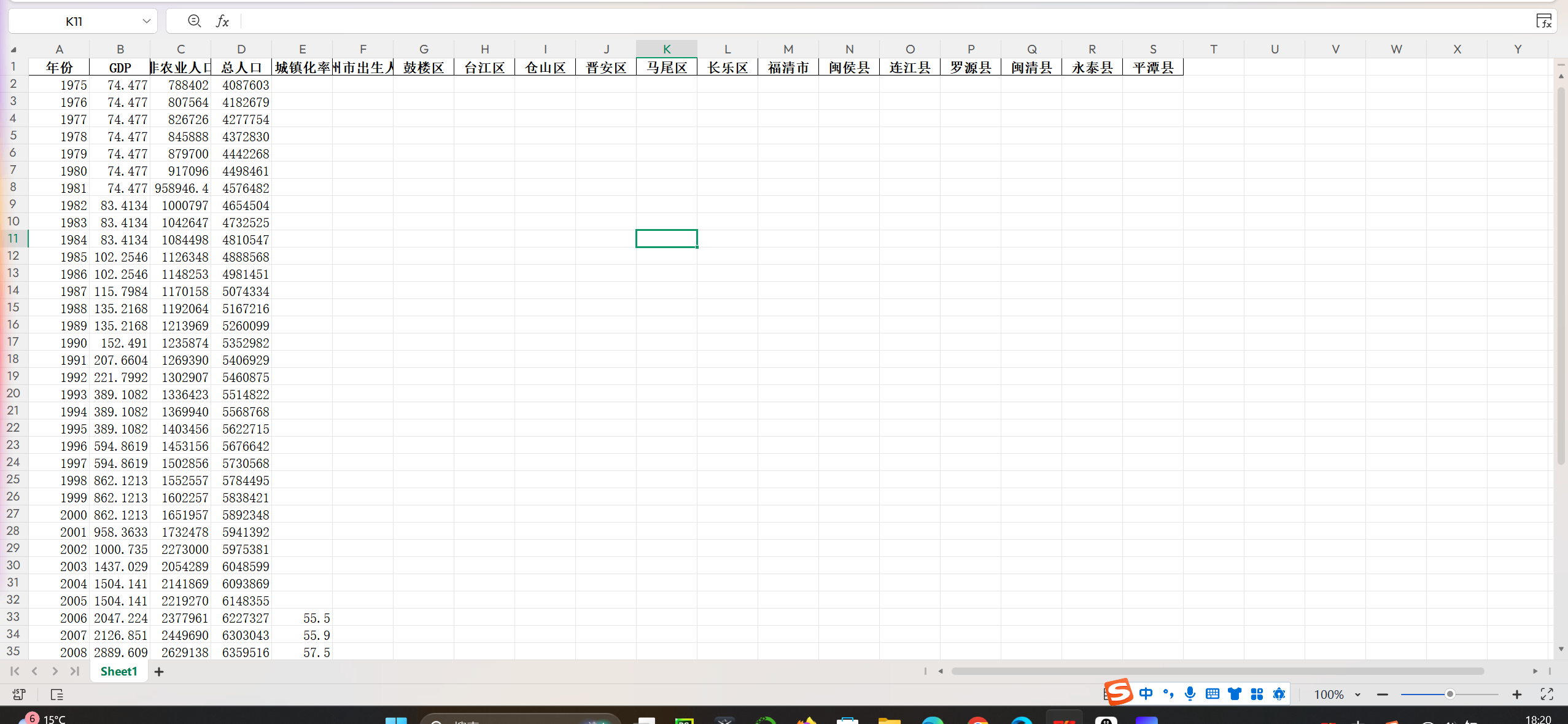
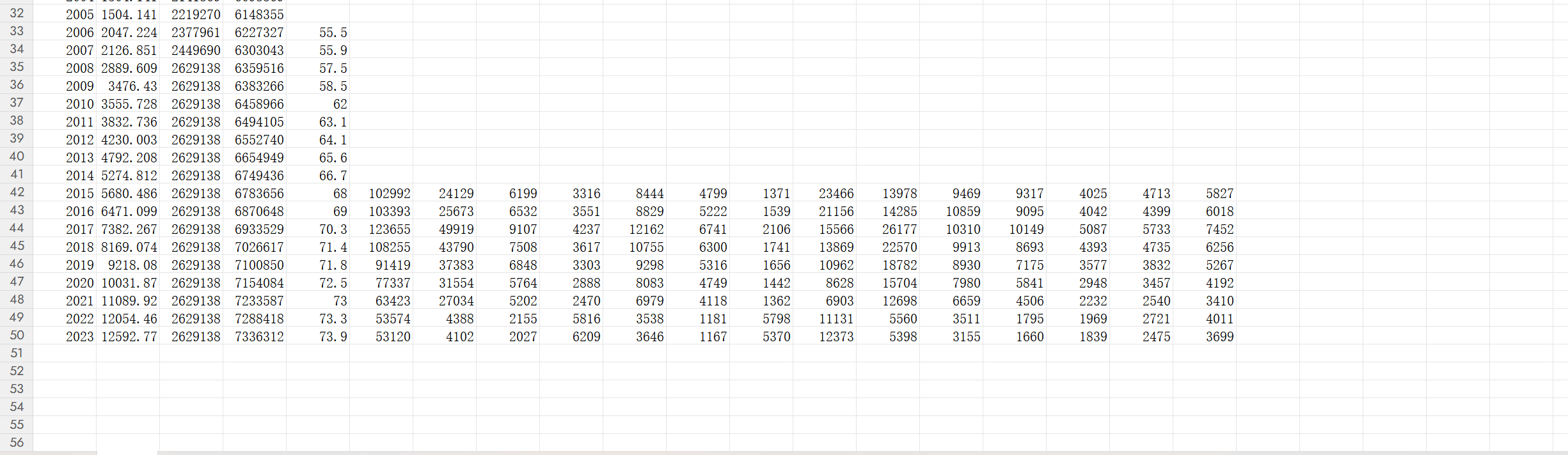
清洗后的人口等数据
经过标准化清洗后的人口数据,实现了年份、区域、指标的统一规整,数据格式清晰、无无效冗余信息,可直接用于后续建模分析。
政策文件
整理后的政策文件按类别存放,文本格式规范,配套结构化Excel分析报告,清晰呈现政策核心信息与关键词分布,为政策影响研究提供有力支撑。
GDP数据成果
通过OCR识别与清洗后的GDP数据,实现了从图片到结构化Excel的转化,数据与官方统计口径一致,时间序列完整,可用于经济与人口趋势的关联分析。
六、总结收获
本次数据采集工作,我掌握了多源数据(结构化、图片、非结构化)自动化爬取与清洗的方法,熟练运用requests、BeautifulSoup、pandas及OCR技术处理不同类型数据的痛点问题。同时深刻认识到权威数据源与标准化流程的重要性,从前期需求梳理到后期数据规整的全流程实践,提升了我的数据处理与项目实操能力,为后续福州市出生人口趋势预测建模筑牢了坚实的数据基础。
总代码文件:https://gitee.com/lin-weijie123/2025_crawl_project/tree/master/%E7%BB%BC%E5%90%88%E5%AE%9E%E8%B7%B5