前言
本文尝试梳理一下EDM论文中的一些结论。
PF-ODE
我们先从SMLD模型出发,其加噪过程为
\[ x_{t}=x_{0}+\sigma_{t}\epsilon, ~~~ \epsilon \sim \mathcal{N}(0, I)
\]
对应的PF-ODE为
\[ dx_{t}=-\dot{\sigma}_{t}\sigma_{t}\nabla_{x_{t}}\log{p_{t}(x_{t})} \tag{1}
\]
考虑更加泛化的加噪过程
\[ x_{t} = s_{t}x_{0}+s_{t}\sigma_{t}\epsilon, ~~~ \epsilon \sim \mathcal{N}(0, I)
\]
对应的漂移系数\(f(t)\)和扩散系数\(g(t)\)为
\[ f(t) = \frac{d(lns_{t})}{dt}=\frac{\dot{s}_{t}}{s_{t}}, ~~~g^{2}(t)=\frac{d(s_{t}^{2}\sigma_{t}^{2})}{dt}-2s_{t}^{2}\sigma_{t}^{2}\frac{d(lns_{t})}{dt}=2s_{t}^{2}\dot{\sigma}_{t}\sigma_{t}\]
因此,其对应的PF-ODE为
\[dx_{t}=[\frac{\dot{s}_{t}}{s_{t}}x_{t}-s_{t}^{2}\dot{\sigma}_{t}\sigma_{t}\nabla_{x}\log{p_{t}(x_{t})}]dt \tag{2}\label{eq2}
\]
定义\(p(x, \sigma)\)为方差为\(\sigma\)的正态分布,此时有
\[p(x_{t}, s_{t}\sigma_{t})=\frac{1}{\sqrt{2\pi}s_{t}^{d}\sigma_{t}^{d}}\exp\{-\frac{(x_{t}-s_{t}x_{0})^{2}}{2s_{t}^{2}\sigma_{t}^{2}}\}=s_{t}^{-d}\frac{1}{\sqrt{2\pi}\sigma_{t}^{d}}\exp\{-\frac{(\frac{x_{t}}{s_{t}}-x_{0})^{2}}{2\sigma_{t}^{2}}\}=s_{t}^{-d}p(\frac{x_{t}}{s_{t}}, \sigma_{t})
\]
因此,
\[\nabla_{x_{t}}\log{p(x_{t})}=\nabla_{x_{t}}\log{p(\frac{x_{t}}{s_{t}}, \sigma_{t})}
\]
带入公式\eqref{eq2}可得
\[dx_{t}=[\frac{\dot{s}_{t}}{s_{t}}x_{t}-s_{t}^{2}\dot{\sigma}_{t}\sigma_{t}\nabla_{x_{t}}\log{p(\frac{x_{t}}{s_{t}}, \sigma_{t})}]dt \tag{3}\label{eq3}
\]
参数选择
由于\(\frac{dx_{t}}{dt}\)与\(s_{t}\)和\(\sigma_{t}\)有关,因此ODE轨迹的形状受到\(s_{t}\)与\(\sigma_{t}\)影响,我们想要使得ODE轨迹是一条直线,即\(\frac{dx_{t}}{dt}\)尽可能是常数,以便后续采样。
因此,我们选择\(s_{t}=1\),消除\(x_{t}\)的影响,此时
\[dx_{t} = -\dot{\sigma_{t}}\sigma_{t}\nabla_{x_{t}}\log{p(x_{t}, \sigma_{t})}dt
\]
\[\nabla_{x_{t}}\log{p(x_{t}, \sigma_{t})}=\frac{x_{0}-x_{t}}{\sigma_{t}^{2}}
\]
代入公式\eqref{eq3}可得
\[dx_{t} = \frac{x_{t}-x_{0}}{\sigma_{t}}d\sigma
\]
为了便于积分,我们进一步假设\(\sigma_{t}=t\),上式化简为
\[dx_{t}=\frac{x_{t}-x_{0}}{t}dt ~~~~~ \Rightarrow ~~~ x_{t}=x_{0}+Ct
\]
因此,对应的PF-ODE的轨迹为一条直线。
预处理与训练
在监督式训练神经网络时,输入和输出的方差最好都维持在 1 左右,避免基于单个样本的梯度幅度大幅波动。因此,我们往往不直接用神经网络作为去噪器\(D_{\theta}(x_{t}, t)\)预测\(x_{0}\),而是预测对应的噪声\(\epsilon\),记作
\[D_{\theta}(x_{t}, t)=x_{t}-tF_{\theta}(x_{t}, t)
\]
对于输入\(x_{t}=x_{0}+t\epsilon\),当时间\(t\)变化时,输入方差不稳定(与\(t\)有关);对于\(G_{\theta}\),当时间\(t\)较大时,\(F_{\theta}\)预测的误差会进一步放大,造成输出方差不稳定。因此,我们进行如下的参数化
\[D_{\theta}(x_{t}, t)=c_{skip}(t)x_{t}+c_{out}(t)F_{\theta}(c_{in}(t)x_{t}, c_{noise}(t))
\]
对应的目标函数为
\[\mathbb{E}[\lambda(t)\|D_{\theta}(x_{t}, t)-x_{0}\|_{2}^{2}]=\mathbb{E}[\lambda(t)c_{out}^{2}(t)\|F_{\theta}(c_{in}(t)x_{t}, c_{noise}(t))-\frac{1}{c_{out}(t)}(x_{0}-c_{skip}(t)x_{t})\|_{2}^{2}]
\]
为了平衡不同噪声水平下的权重,我们令\(\lambda(t)=\frac{1}{c_{out}^{2}(t)}\)。
假设数据分布\(p_{data}(x) \sim \mathcal{N}(0, \sigma_{data}^{2}I)\),则
\[x_{t} \sim \mathcal{N}(0, (\sigma^{2}+\sigma^{2}_{data})I)
\]
\[c_{in}(\sigma)x_{t} \sim \mathcal{N}(0, c^{2}_{in}(\sigma)(\sigma^{2}+\sigma^{2}_{data})I)
\]
\[\frac{1}{c_{out}(\sigma)}(x_{0}-c_{skip}(\sigma)x_{t}) \sim \mathcal{N}(0, \frac{1}{c_{out}^{2}(\sigma)}(c_{skip}^{2}(\sigma)\sigma^{2}+(1-c_{skip}(\sigma))^{2}\sigma^{2}_{data})I)
\]
根据经验值,我们假设,
\[c_{skip}(\sigma) = \frac{\sigma^{2}_{data}}{\sigma^{2}_{data}+\sigma^{2}}, ~~~~ c_{noise}(\sigma)=\frac{1}{4}ln\sigma
\]
其中\(\sigma_{data}=0.5\),因此,
\[c_{in}(\sigma)=\frac{1}{\sqrt{\sigma^{2}+\sigma^{2}_{data}}}
\]
\[c_{out}(\sigma)=\frac{\sigma_{data}\sigma}{\sqrt{\sigma^{2}+\sigma_{data}^{2}}}
\]
\[c_{skip}(\sigma) = \frac{\sigma^{2}_{data}}{\sigma^{2}_{data}+\sigma^{2}}
\]
\[c_{noise}(\sigma)=\frac{1}{4}ln\sigma
\]
\[\lambda(\sigma)=\frac{\sigma^{2}+\sigma^{2}_{data}}{\sigma^{2}\sigma^{2}_{data}}
\]
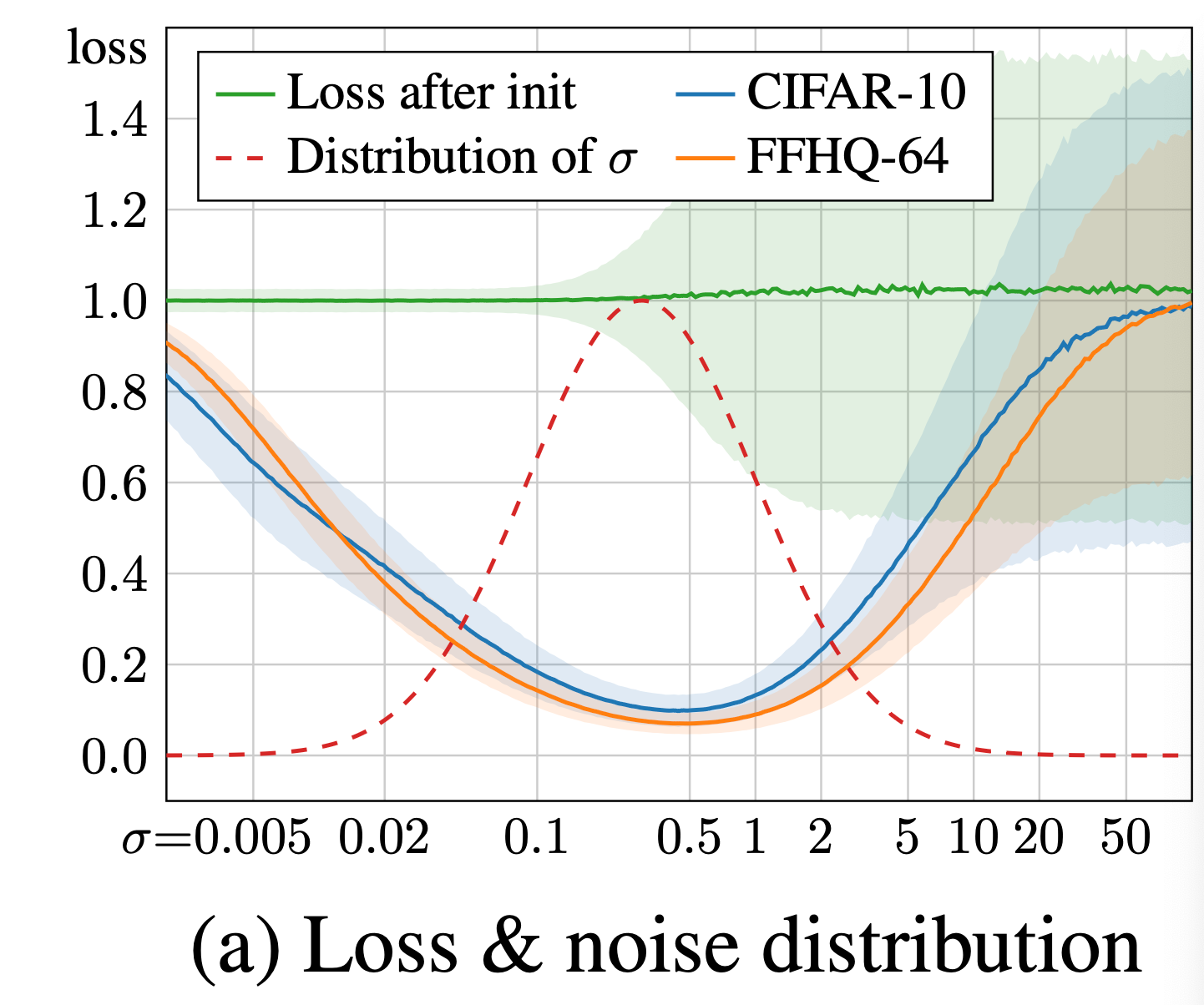
上图为训练后的模型在不同噪声水平下的loss,只有在噪声强度处于适中水平时loss出现明显降低。因此,在训练时,作者按照\(log-normal\)分布采样噪声值。
\[ln(\sigma) \sim \mathcal{N}(P_{mean}, P_{std}^{2})
\]
总结
本文主要梳理了EDM中的加噪策略是如何提出的,即尽可能使对应的PF-ODE为一条直线。并基于数值稳定性重新设计网络输入和预测目标,梳理了部分超参数的推导。