CSDN叶庭云:https://yetingyun.blog.csdn.net/
文章目录
- 一、前言
- 二、DeepSeek-V3.1 模型文件结构
一、前言
在当前 AI 技术讨论中频繁提及“大语言模型(Large Language Model,LLM)开源”,但它到底 “开” 出来什么?一个开源 LLM 究竟包含哪些核心组成部分?本文将介绍 DeepSeek-V3.1 模型记录由哪些部分组成,有助于理解大语言模型开源的具体内容和运行流程。
下图展示了知名大模型厂商DeepSeek公司在 Hugging Face 平台的主页,Hugging Face 实为当前全球最大的开源机器学习模型社区。Hugging Face 对于 AI 模型领域而言,可类比为面向人工智能领域的 GitHub。
我们以 DeepSeek-V3.1 的模型仓库作为观察示例,网址为:https://huggingface.co/deepseek-ai/DeepSeek-V3.1
Model Card 页面展示了模型的基本信息,具体内容如下:

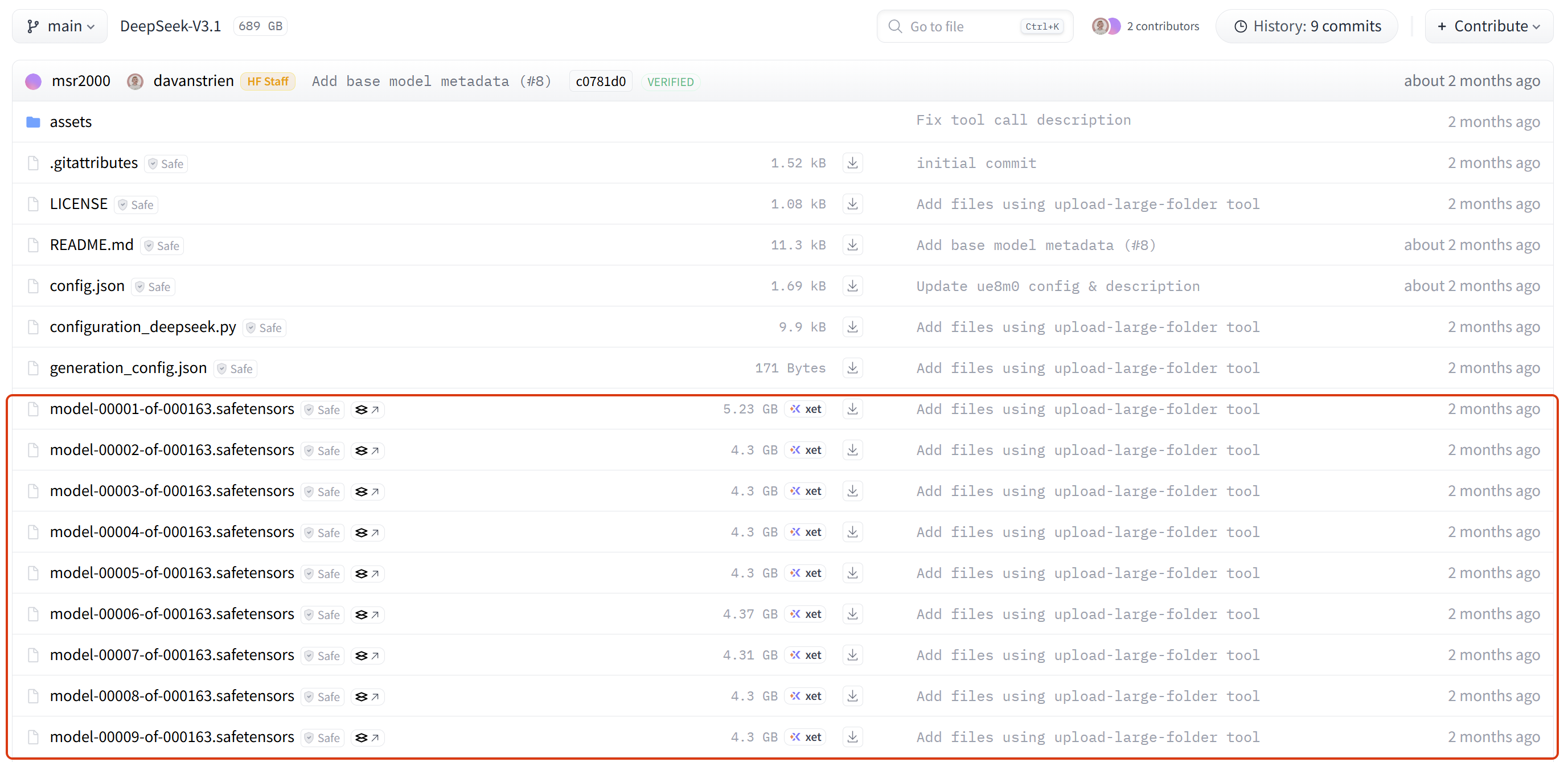
注意,真正的核心内容在Files and versions 选项卡里:https://huggingface.co/deepseek-ai/DeepSeek-V3.1/tree/main
二、DeepSeek-V3.1 模型文件结构
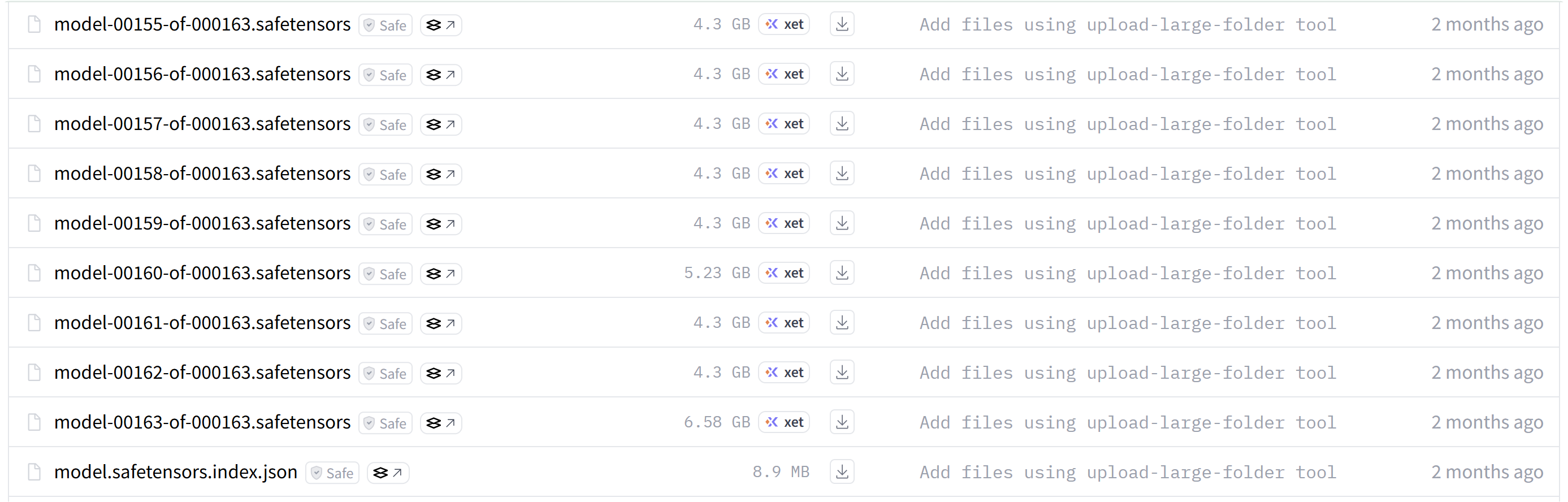
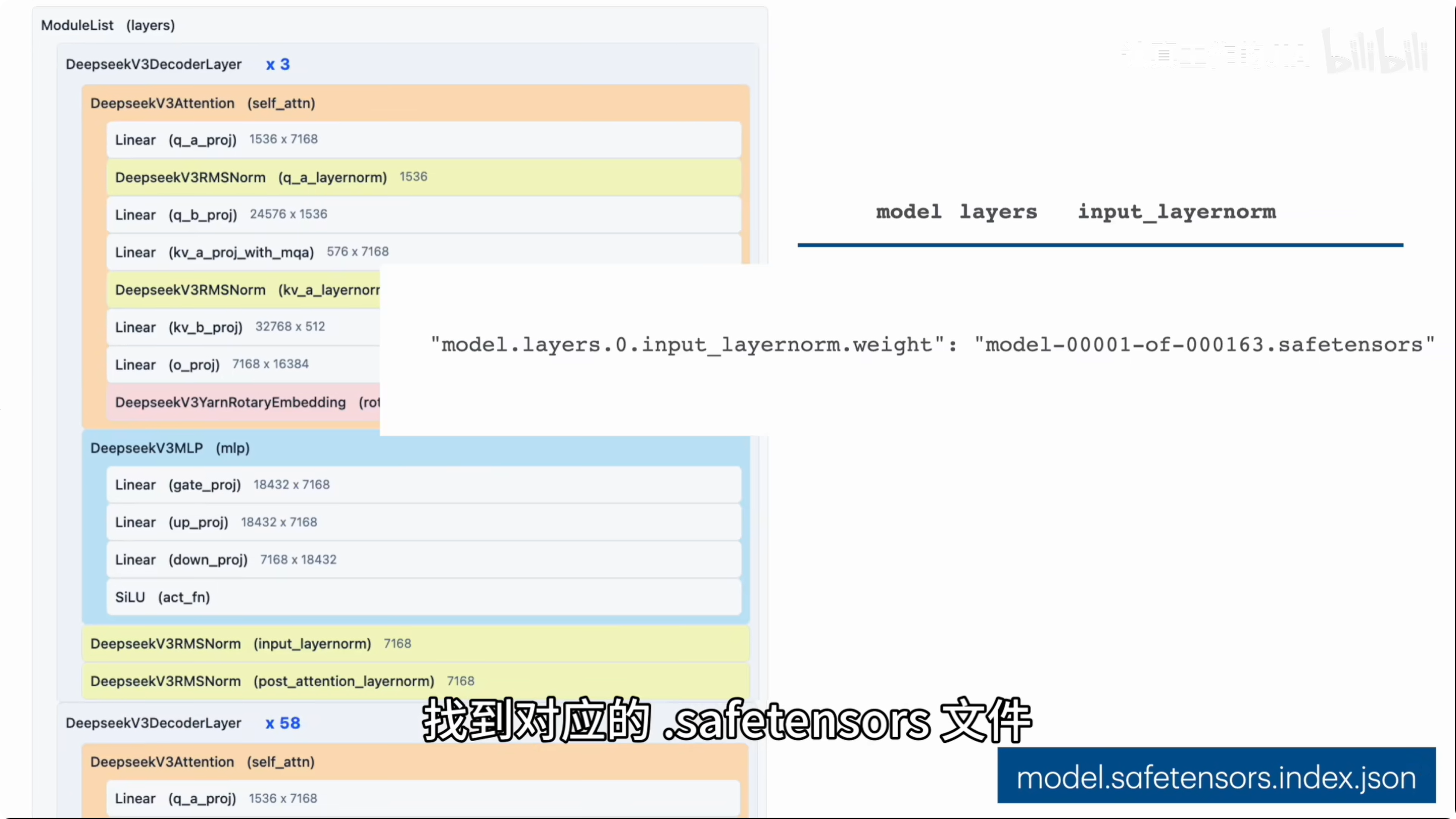
.safetensors 格式的模型权重文件数量最多且体积最大,因其包含模型中所有层的参数。为便于并行加载,模型权重通常被切分为许多 .safetensors 档案。在实际部署过程中,model.safetensors.index.json 索引文件负责记录模型层与对应权重文件之间的映射关系,从而确定各权重在具体文件中的存储位置。
config.json 定义了模型的结构参数,相当于该大语言模型的 “身份证”,其内容包括 model_type、architectures、hidden_size、num_hidden_layers、vocab_size 等参数,以及 DeepSeek-V3.1 中所使用的混合专家(Mixture-of-Experts,MoE)配置。

config.json 文件以 JSON 格式存储模型参数,而这些参数由 configuration_deepseek.py 代码负责解析并转化为模型配置对象。因此,这两个文件构成了配置文件解析与模型配置初始化的核心组件。
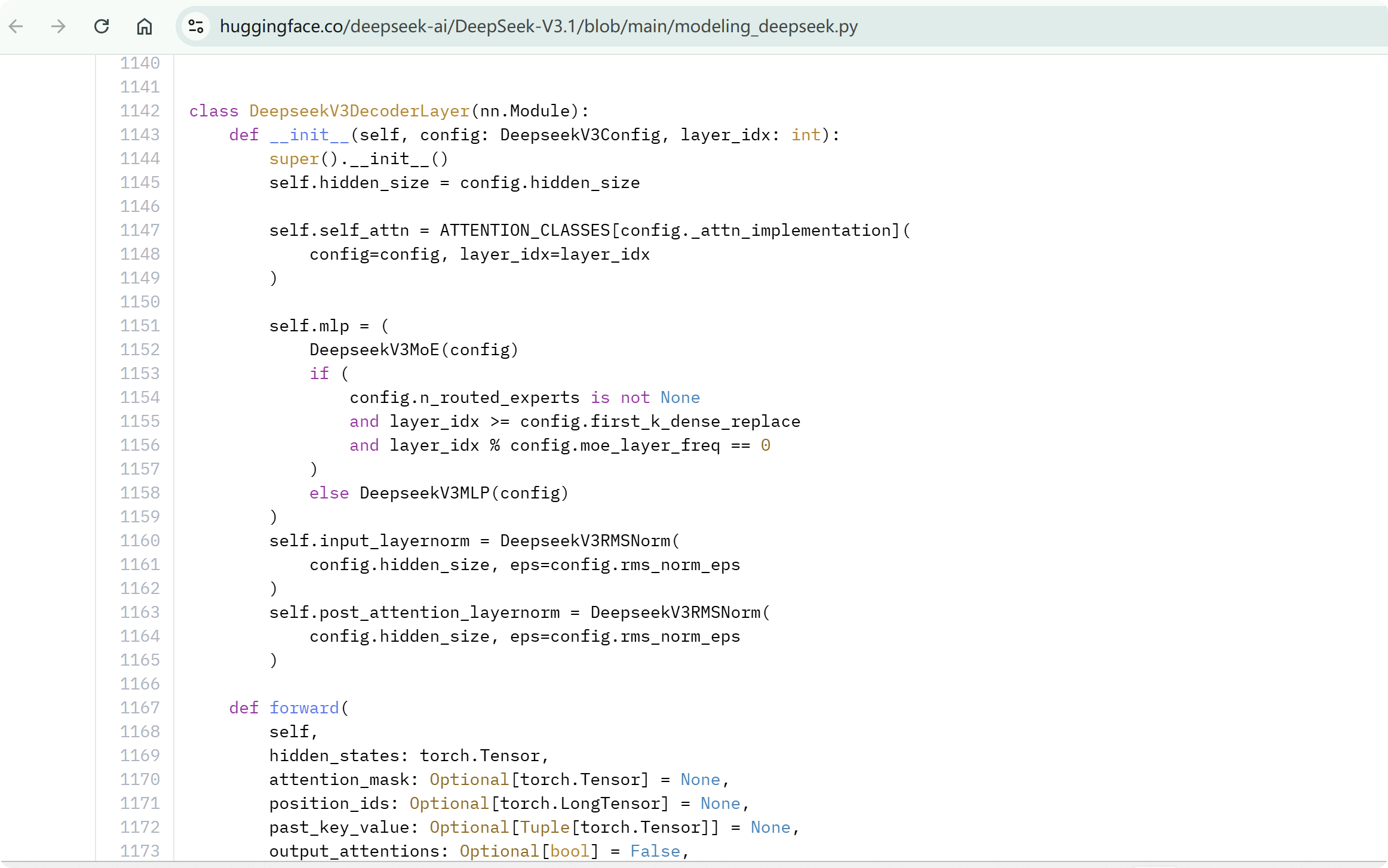
modeling_deepseek.py 则负责实现模型架构与具体计算逻辑。
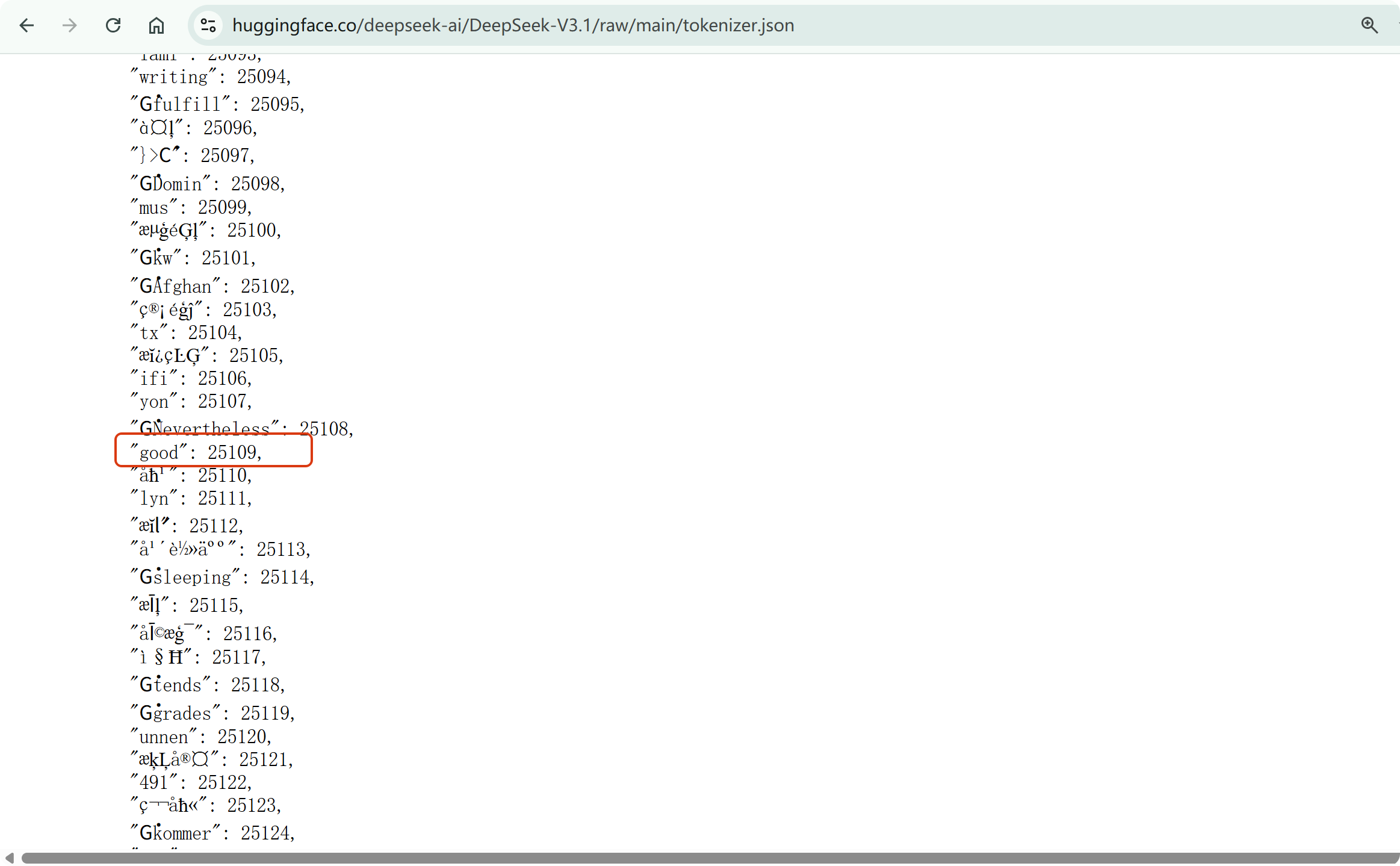
此外,诸如 DeepSeek 这类大语言模型并不直接处理原始文本,而是依赖分词器将输入文本转换为模型可处理的数字表示,其中 tokenizer.json 包含了分词规则映射与词汇表数据。例如,在词表中查询词汇 “good”,可获取其对应的 Token ID 为 25109。
tokenizer_config.json 用于配置文本处理方式、特殊 token、model_max_length 和 chat_template 等参数。总体而言,分词器的主要功能是将输入文本转换为模型可处理的 Token ID 序列;在解码过程中,则将模型输出的 Token ID 序列重新转换为自然语言文本。
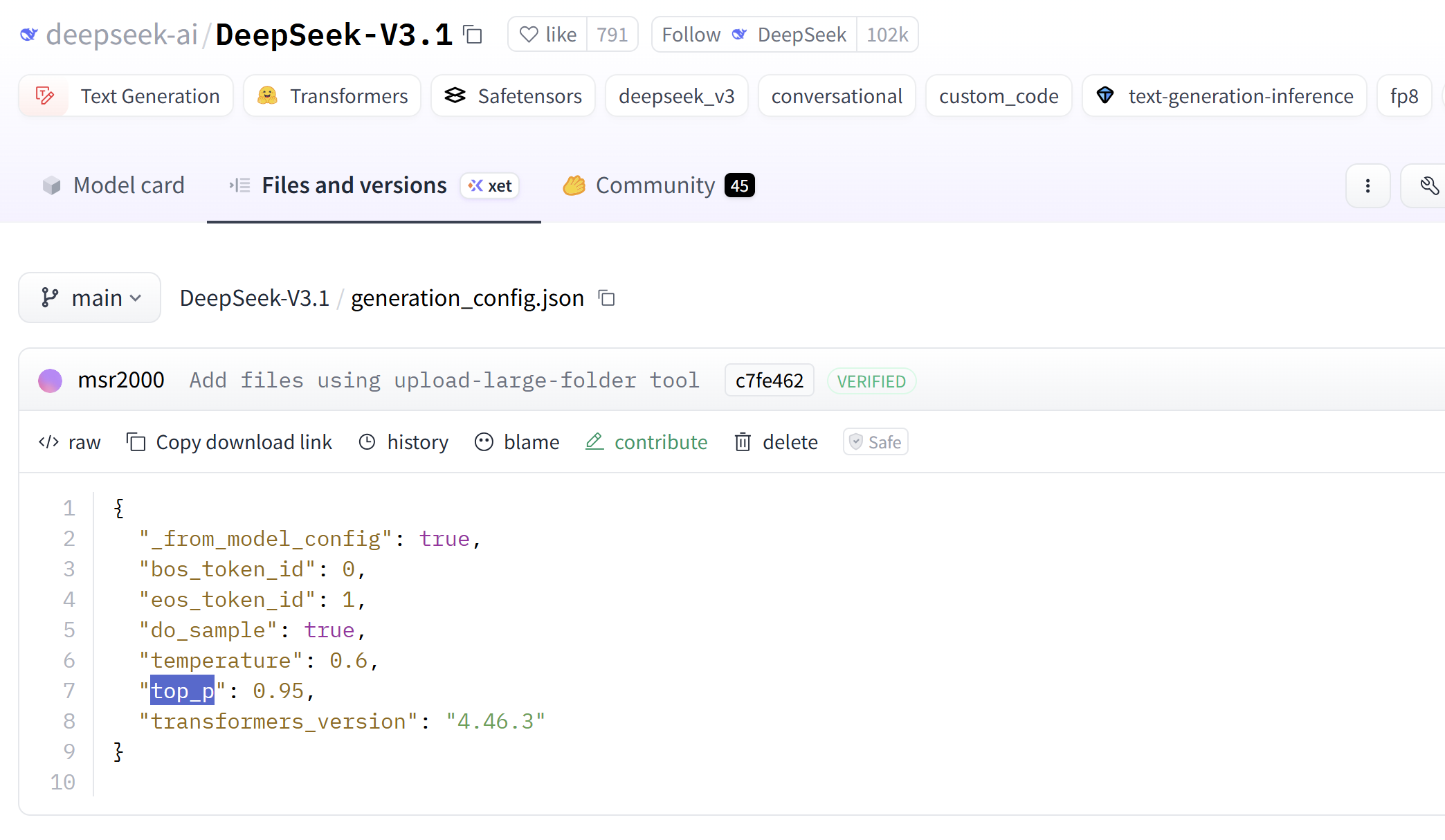
generation_config.json 用于配置使用 transformers 库加载并推理 DeepSeek-V3.1 模型时的生成策略相关参数,例如 do_sample、temperature 和 top_p 等。
其他:
assets/- 辅助资源目录
.gitattributes- Git 属性部署
LICENSE- 特定开源许可证,DeepSeek-V3.1 实际用的 MIT License
README.md- 模型说明文档
️ 有关链接:
DeepSeek-V3.1 Files and versions
DeepSeek - 探索未至之境
DeepSeek-V3 Technical Report