详细介绍:Java基础篇——一文搞懂 HashMap 底层原理
2025-12-20 17:31 tlnshuju 阅读(0) 评论(0) 收藏 举报HashMap 是 Java 开发中使用频率最高、最核心的集合之一,但它的底层细节非常多:数组、链表、红黑树、哈希函数、扩容机制、并发问题…… 要真正掌握 HashMap,背后这套体系必须吃透。
本文将从 数组结构、哈希寻址、扩容原理、树化机制、并发问题 五个维度系统讲透 HashMap 的底层原理,让你从使用者进阶到理解者。
前置知识(非常重要)、什么是线程安全?
首先要明白一点,线程安全本身说的并不是线程是否安全,而是指的内存是否安全。
其实本质就是对于操作系统中的堆内存区域其实是允许共享访问的,这时候如果不加锁的限制,就容易出现错乱。
线程安全的解决思路:
1.theredLocal(每个线程有自己一个独立副本)
2.局部变量(私有化,只能自己处理)
3.final(只能读不能写)
4.加锁(互斥锁,悲观锁)——适用于线程多的情况
5.失败重试的机制(CAS,乐观锁)——适用于线程少的情况,因为线程越少,发生不安全的概率也就越少
一、HashMap 的底层结构
JDK7:数组 + 链表
JDK8:数组 + 链表 + 红黑树
HashMap 的本质是一张 "数组 + 链表/红黑树" 的混合结构:
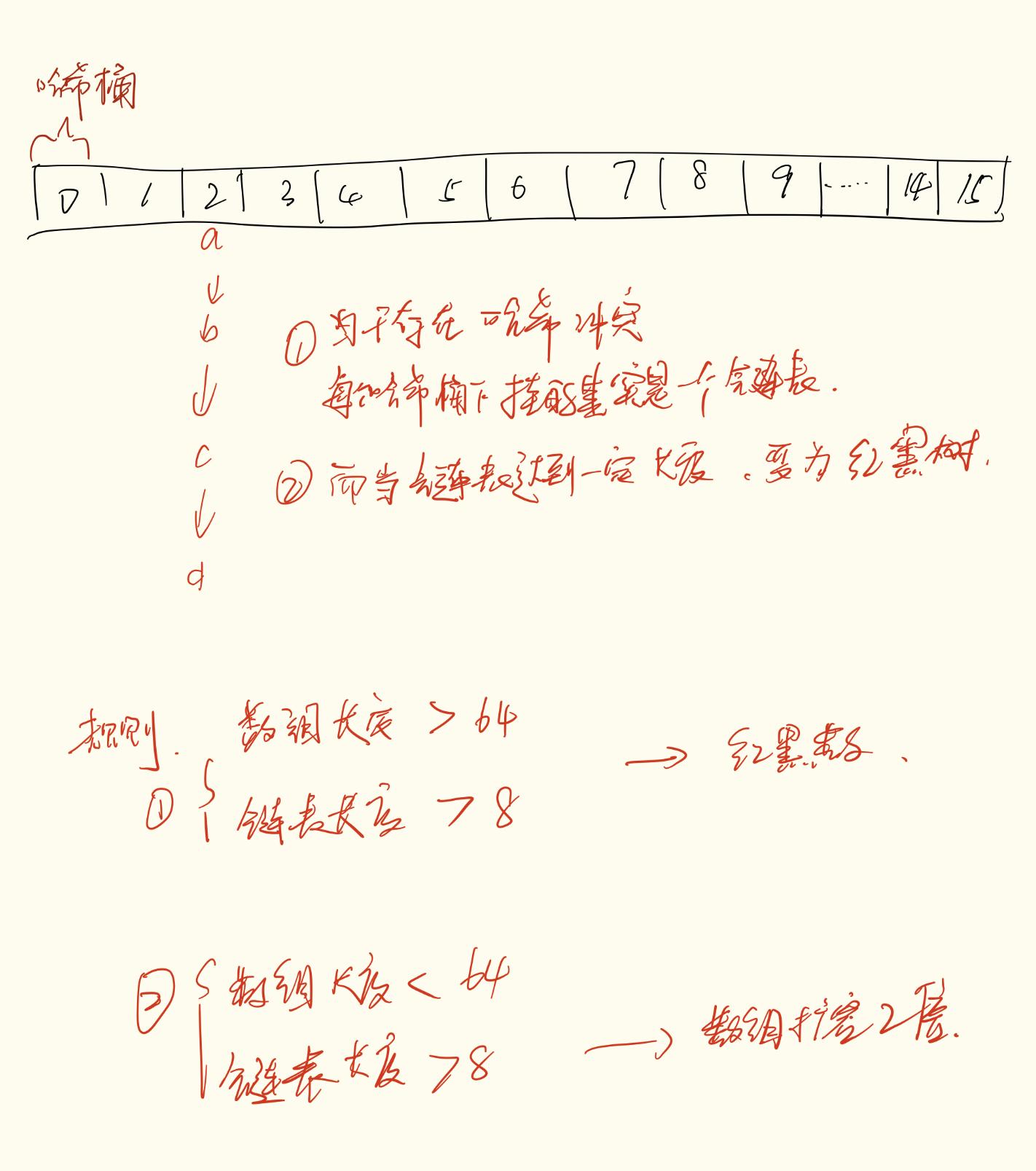
数组:真正存储数据的地方,称为 桶(bucket);
链表 / 红黑树:用于解决哈希冲突的结构。
当多个键算出的下标相同,就会进入同一个桶:
冲突不多:链表
冲突多(链表长度 ≥ 8 且数组容量 ≥ 64):红黑树
树化是 JDK8 最大的优化点之一,减少了极端情况下查询退化到 O(n) 的风险。
二、元素添加的完整流程(核心)
1. put(k, v) 大致步骤:
根据 key 的 hash 值计算数组下标:
index = (n - 1) & hash如果桶为空:直接放进去
如果桶非空:
遍历链表/红黑树
若发现 key 一致,用新 value 覆盖旧 value
若没有重复 key:放到链表尾(JDK8)
插入后判断是否需要树化
判断是否达到扩容阈值并进行扩容
为什么用 (n - 1) & hash?
这是 HashMap 最经典的优化点。
例如默认数组长度 n = 16:
n - 1 = 15(二进制:0000 1111)
任何数字与 0000 1111 按位与 (&) 后:
只保留低四位
结果一定在
0 ~ 15的范围内
也就是说,下标范围刚好落入数组范围,不会越界。
更重要的是:
这个运算在效果上 ≈
hash % n (本质上就是模一个16,16进制的余数,只是性能更高)但 位运算 & 的效率远高于 % 取余运算
因此 HashMap 使用这种技巧来提高寻址效率。
三、扩容机制(HashMap 性能关键)
1. 扩容时机
当元素数量达到:
size ≥ 容量 × 0.75就会触发扩容。
这个 0.75 就是 HashMap 的 负载因子。
2. 为什么负载因子是 0.75?
它不是拍脑袋取的,是大量实验和数学统计(泊松分布)后的最佳平衡点:
< 0.75:空间浪费严重
0.75:哈希冲突增加导致性能下降
0.75 是 HashMap 在 性能 和 空间 的最优折中点。
3. 为什么扩容为 2 倍?
简单来说就是让二进制的末尾都是1,这样就可以用&运算去替代取模,从而提升性能。
扩容后数组大小仍保持 2 的次幂:例如 16 → 32 → 64 …
因为只有当数组长度是 2 的次幂时:
(n - 1) 的二进制全部为 1例如:
n = 16(0001 0000)
n - 1 = 15(0000 1111)
此时:
(n - 1) & hash的结果取决于 hash 的低位值,能保证:
分布更均匀
冲突更低
这就是 HashMap 必须用 2 的幂长度数组的根本原因。
4. rehash的内容
触发扩容的本质其实是想把链表的长度给降下来,这时候重新分配就是rehash。
jdk7:采用重新按位与的策略分配到新的内存上。
jdk8:采用和原空间大小按位与,区分低位和高位,如果是16代表是高位,放到新的下标位置(原下标+扩容的大小),如果<16,保持原来下标位置。
举个例子:当前是12的位置,此时&16如果得到16:
高位——>新的下标(12 + 16)
低位——>原下标
四、ArrayList 与 HashMap 的容量机制对比
首先明白一点:ArrayList是采用一个懒加载策略,初始化完后不分配大小,第一次add的时候分配10的大小。
这一部分帮助你建立对集合“扩容成本”的整体认知。
ArrayList 为什么建议初始化容量?
因为 ArrayList 内部本质是 动态数组。如果不设置容量:
一直 add 时会触发扩容
扩容需要 新建更大的数组 + 拷贝旧数组数据
扩容代价很高,因此建议:
如果能预估数据量,尽量指定初始容量
ArrayList 扩容为 1.5 倍的原因
仍然是平衡:
扩太多 → 浪费内存
扩太少 → 频繁扩容导致性能下降
ArrayList 线程安全吗?
不安全,不安全正是因为对堆内存的并发修改。
多线程 add 时会出现:
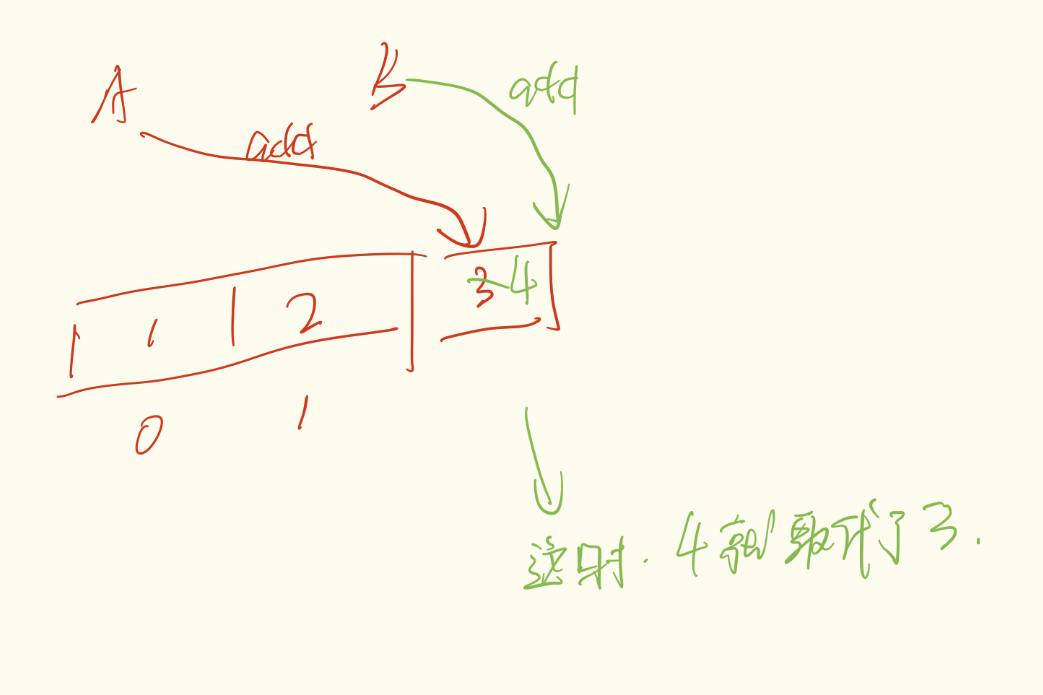
场景1:
元素覆盖(两线程同时获取到了地址0,一个add了1,一个add了2,2覆盖了1的内容)
数据丢失(两线程同时获取到了地址0,一个add了1,一个add了2,1丢失了)
参考下图:
场景2:
扩容并发表现 undefined(不可预期)
说明:
线程 A 正在 copy:
copy oldArr[0] copy oldArr[1] (copy 一半的时候)线程 B 正在 add:
oldArr[size++] = value结果导致:
- 1.首先如果数组中A有3个元素,但是copy过程中,B加入了新的,这时候最后也只有三个元素
- 2.更可怕的是:如果这时候我们拷贝了地址为2的区域,但在这时B也恰好执行oldArr[2] = newvalue,这时候很难保证扩容的数组2号地址是什么值,这是竞态条件。
元素丢失
元素重复
数组状态不一致
list 结构损坏
解决方案:
synchronized 包裹
CopyOnWriteArrayList
五、CopyOnWriteArrayList 原理(读多写少场景神器)
核心思想:写时复制
写操作:
加锁
copy 原数组 -> 新数组
在新数组上写入
指针指向新数组
读操作:
不加锁!直接读取旧数组,因此读非常快
缺点:
占内存
读到的数据不是强一致
适合场景:读多写少
六、HashMap 的线程安全问题
HashMap 本质是非线程安全的。
JDK7 问题
扩容可能产生“环形链表”,导致死循环
原因是用了头插法,本质就是:两个线程同时迁移链表导致的“指针篡改”问题
JDK8 问题
并发 put 导致数据覆盖(类似arraylist的add)
因此:
多线程不要用 HashMap!
改用 ConcurrentHashMap
七、ConcurrentHashMap(线程安全的 HashMap)
JDK 1.7:分段锁(Segment)
分成 16 段,每段一把锁
并行度最多 16
JDK 1.8:CAS + synchronized
特点:
不再使用 Segment
针对每个桶(链表/树)头节点加锁
大部分操作依赖 CAS
锁粒度更细
为什么不全部使用 CAS?
因为:
CAS 适合 短时间的、简单的操作(比如初始化桶)
synchronized 适合 复杂、耗时的操作(比如遍历链表 + 插入 + 树化)
这体现了现代并发容器的理念:
无锁优先,锁为补充
总结:HashMap 的设计哲学
复盘整个 HashMap,你会发现它有三大核心设计理念:
① 数学 + 工程优化结合
2 的次幂数组长度
(n-1)&hash 寻址
负载因子 0.75
红黑树优化极端情况
② 高效与扩展性的平衡
链表 + 数组 + 红黑树组合
位运算替代取余
两倍扩容减少复杂重分布
③ 并发编程思想
HashMap 本身不保证线程安全
ConcurrentHashMap 将“无锁 + 有锁”混合使用,取长补短
如果你认真读完本篇文章,你已经真正理解了 HashMap,而不是停留在“数组 + 链表 + 红黑树”的表层知识。