一、爬虫的整体流程图

二、具体实现
1)身份伪装和登录
身份伪装和登录
def init_driver(self):"""初始化浏览器。首次启动需扫码登录。"""if self.driver is not None:returnprint(">>> [系统初始化] 正在启动浏览器...")chrome_options = Options()if self.headless:chrome_options.add_argument("--headless=new")chrome_options.add_argument("--disable-gpu")chrome_options.add_argument("--disable-blink-features=AutomationControlled")chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")self.driver = webdriver.Chrome(options=chrome_options)self.driver.get("https://weibo.com/login.php")input(">>> [请操作] 请扫描屏幕上的二维码登录。\n>>> 登录成功后,请在此处按【回车键】继续... ")
运行代码,访问微博首页

跳出微信登录框、自行扫码登录
登陆成功
点击回车继续爬虫
2)模拟搜索搜索关键字
"""搜索关键词并抓取内容。返回:解析后的字典数据。"""if self.driver is None: self.init_driver()print(f"\n>>> [抓取中] 关键词: {keyword}")self.driver.get(f"https://s.weibo.com/weibo?q={keyword}")
### time.sleep(random.uniform(2, 4))
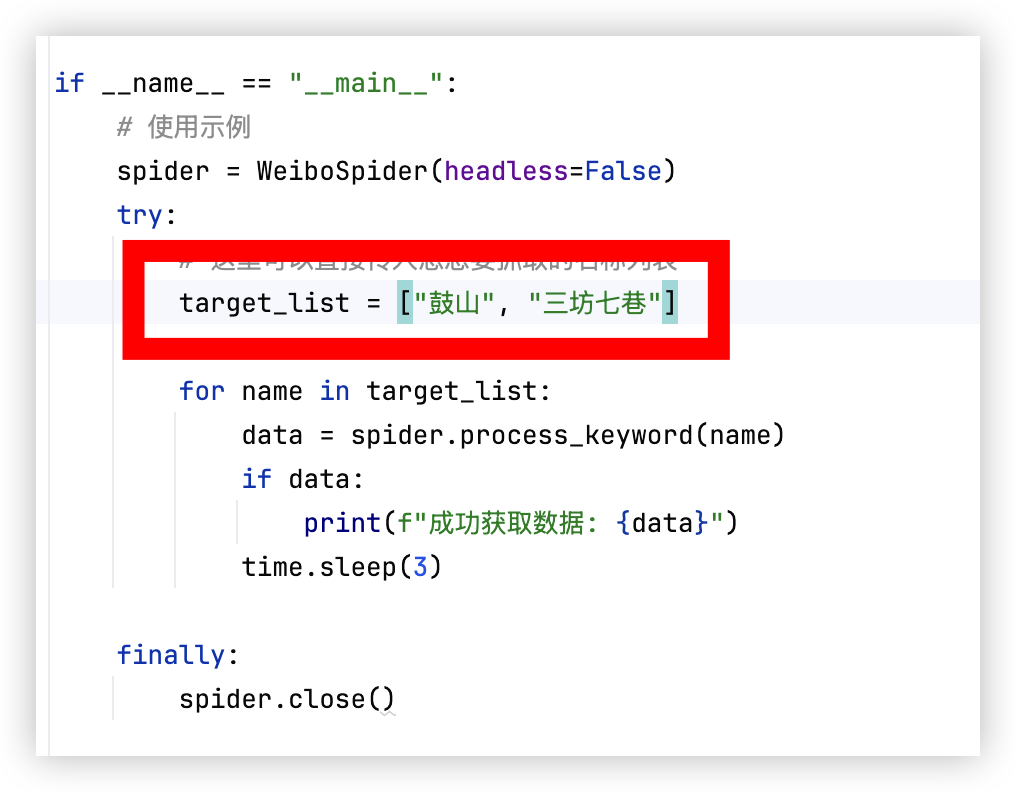
访问预设搜索词,这里我们以鼓山、三坊七巷为例
跳转到鼓山搜索界面

3)精准定位和信息提取
提取每篇文章的关键内容概要
posts = self.driver.find_elements(By.CSS_SELECTOR, 'div[action-type="feed_list_item"]')[:self.posts_per_search]if not posts: return Nonecombined_text = ""for i, post in enumerate(posts):try:# 尝试获取全文或摘要try:txt = post.find_element(By.CSS_SELECTOR, 'p[node-type="feed_list_content_full"]').textexcept:txt = post.find_element(By.CSS_SELECTOR, 'p[node-type="feed_list_content"]').textcombined_text += f" {self._clean_text(txt)}"except:continue

4)AI结构化解析
通过千问大模型将爬虫内容解析成结构化数据
def call_ai(self, prompt: str) -> str:"""调用通义千问大模型"""if not self.tongyi_api_key:raise RuntimeError("API Key 未配置,请设置环境变量 TONGYI_API_KEY")headers = {"Content-Type": "application/json", "Authorization": f"Bearer {self.tongyi_api_key}"}payload = {"model": self.tongyi_model,"input": {"messages": [{"role": "user", "content": prompt}]},"parameters": {"max_tokens": 800, "temperature": 0.0},}for attempt in range(1, self.ai_retries + 1):try:resp = requests.post(self.tongyi_api_url, headers=headers, json=payload, timeout=self.ai_timeout)resp.raise_for_status()result = resp.json()return result["output"]["text"]except Exception as e:if attempt == self.ai_retries: raisetime.sleep(2)return ""def ai_parse_structured_fields(self, raw_text: str, name_hint: str = "") -> Dict:"""使用 AI 将非结构化文本转为字典"""prompt = f"""
请从以下微博文本中提取信息,以 JSON 格式返回:
1. name: 地点名称(默认使用"{name_hint}")。
2. description: 核心特色描述(150字内)。
3. category: 从 ["自然风光", "历史古迹", "文化艺术", "主题乐园", "城市地标", "其他"] 中选一。输入内容:{raw_text}
"""try:ai_res = self.call_ai(prompt)# 提取 JSON 部分start = ai_res.find("{")end = ai_res.rfind("}")return json.loads(ai_res[start:end + 1])except Exception:# 降级处理return {"name": name_hint, "description": raw_text[:150], "category": "其他"}
结果输出:
完整代码
# -*- coding: utf-8 -*-
"""
weibo_spider_core.py
核心爬虫版:移除 CSV 存储逻辑,保留爬虫与 AI 解析接口。
返回结果为 Python 字典,方便集成到其他系统。
"""import os
import time
import random
import json
import requests
from typing import Dict, Optional, Listfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Optionsclass WeiboSpider:"""核心爬虫类。负责:初始化浏览器、模拟搜索、提取博文及评论、调用AI清洗并返回字典。"""def __init__(self,tongyi_api_url: Optional[str] = None,tongyi_api_key: Optional[str] = None,tongyi_model: Optional[str] = None,ai_timeout: int = 20,ai_retries: int = 2,headless: bool = False,posts_per_search: int = 5,):# 通义(DashScope)相关配置self.tongyi_api_url = (tongyi_api_urlor os.environ.get("TONGYI_API_URL","https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation",)).strip()self.tongyi_api_key = (tongyi_api_key or os.environ.get("TONGYI_API_KEY", "")).strip()self.tongyi_model = (tongyi_model or os.environ.get("TONGYI_MODEL", "qwen-turbo")).strip()self.ai_timeout = ai_timeoutself.ai_retries = ai_retriesself.headless = headlessself.posts_per_search = posts_per_searchself.driver = None@staticmethoddef _clean_text(text: str) -> str:"""清洗文本:去换行、去两端空白。"""if not text:return ""return text.replace("\n", " ").replace("\r", " ").strip()def init_driver(self):"""初始化浏览器。首次启动需扫码登录。"""if self.driver is not None:returnprint(">>> [系统初始化] 正在启动浏览器...")chrome_options = Options()if self.headless:chrome_options.add_argument("--headless=new")chrome_options.add_argument("--disable-gpu")chrome_options.add_argument("--disable-blink-features=AutomationControlled")chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")self.driver = webdriver.Chrome(options=chrome_options)self.driver.get("https://weibo.com/login.php")input(">>> [请操作] 请扫描屏幕上的二维码登录。\n>>> 登录成功后,请在此处按【回车键】继续... ")def close(self):"""关闭浏览器。"""if self.driver:self.driver.quit()self.driver = Noneprint(">>> 浏览器已关闭。")def call_ai(self, prompt: str) -> str:"""调用通义千问大模型"""if not self.tongyi_api_key:raise RuntimeError("API Key 未配置,请设置环境变量 TONGYI_API_KEY")headers = {"Content-Type": "application/json", "Authorization": f"Bearer {self.tongyi_api_key}"}payload = {"model": self.tongyi_model,"input": {"messages": [{"role": "user", "content": prompt}]},"parameters": {"max_tokens": 800, "temperature": 0.0},}for attempt in range(1, self.ai_retries + 1):try:resp = requests.post(self.tongyi_api_url, headers=headers, json=payload, timeout=self.ai_timeout)resp.raise_for_status()result = resp.json()return result["output"]["text"]except Exception as e:if attempt == self.ai_retries: raisetime.sleep(2)return ""def ai_parse_structured_fields(self, raw_text: str, name_hint: str = "") -> Dict:"""使用 AI 将非结构化文本转为字典"""prompt = f"""
请从以下微博文本中提取信息,以 JSON 格式返回:
1. name: 地点名称(默认使用"{name_hint}")。
2. description: 核心特色描述(150字内)。
3. category: 从 ["自然风光", "历史古迹", "文化艺术", "主题乐园", "城市地标", "其他"] 中选一。输入内容:{raw_text}
"""try:ai_res = self.call_ai(prompt)# 提取 JSON 部分start = ai_res.find("{")end = ai_res.rfind("}")return json.loads(ai_res[start:end + 1])except Exception:# 降级处理return {"name": name_hint, "description": raw_text[:150], "category": "其他"}def process_keyword(self, keyword: str) -> Optional[Dict]:"""搜索关键词并抓取内容。返回:解析后的字典数据。"""if self.driver is None: self.init_driver()print(f"\n>>> [抓取中] 关键词: {keyword}")self.driver.get(f"https://s.weibo.com/weibo?q={keyword}")time.sleep(random.uniform(2, 4))posts = self.driver.find_elements(By.CSS_SELECTOR, 'div[action-type="feed_list_item"]')[:self.posts_per_search]if not posts: return Nonecombined_text = ""for i, post in enumerate(posts):try:# 尝试获取全文或摘要try:txt = post.find_element(By.CSS_SELECTOR, 'p[node-type="feed_list_content_full"]').textexcept:txt = post.find_element(By.CSS_SELECTOR, 'p[node-type="feed_list_content"]').textcombined_text += f" {self._clean_text(txt)}"except:continueif not combined_text.strip(): return None# 调用 AI 结构化数据return self.ai_parse_structured_fields(combined_text, name_hint=keyword)if __name__ == "__main__":# 使用示例spider = WeiboSpider(headless=False)try:# 这里可以直接传入您想要抓取的名称列表target_list = ["鼓山", "三坊七巷"]for name in target_list:data = spider.process_keyword(name)if data:print(f"成功获取数据: {data}")time.sleep(3)finally:spider.close()
心得体会
本次项目中,我负责实现微博爬虫及非结构化数据结构化转化工作。通过 Selenium 解决微博动态渲染抓取难题,配置反爬策略保障访问稳定,采用 “优先全文 + 降级摘要” 策略提取博文并清洗。引入通义千问大模型,通过精准 Prompt 提取景点名称、特色、类别等字段,设计异常降级机制确保数据输出稳定。同时剥离本地存储逻辑,返回字典格式数据实现与项目系统无缝集成,为智能旅游路线规划提供了高质量数据支撑,深刻体会到技术服务业务、数据驱动智能决策的核心价值。