实用指南:即插即用系列 | TGRS 2025 GST-Net:基于“相对运动模式”与“全局时空融合”的红外小目标检测
论文名称:A Global Spatial–Temporal Detection Framework for Infrared Small Targets in Complex Ground Scenes
论文原文 (Paper):https://ieeexplore.ieee.org/abstract/document/11098927
官方代码 (Code):https://github.com/elvintanhust/GST-Det
GitHub 仓库链接:https://github.com/AITricks/AITricks
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
- 1. 核心思想
- 2. 背景与动机
- 3. 主导贡献点
- 4. 途径细节
- 5. 即插即用模块的作用
1. 核心思想
本文针对复杂地面背景下红外小目标检测中目标被淹没且运动信息提取不足的挑战,提出了一种全新的全局时空检测框架。该框架涵盖两个核心组件:相对运动模式提取(RMPE)模块,借助归一化光流的累积来增强目标与背景的相对运动差异;以及全局时空特征融合网络(GST-Net),凭借双流编码器分别处理空间(图像)和时间(运动图)信息。GST-Net 利用时空特征融合模块(STFFM)进行浅层互补,并利用全局时空依赖提取模块(GSTDEM)进行深层语义交互,从而显著提升了对复杂背景下弱小目标的检测性能。
2. 背景与动机
文本角度总结:
红外小目标检测(尤其是无人机检测)常面临目标极小(低SCR)、背景复杂(如地面纹理干扰)的难题。虽然多帧方法利用了运动信息,但现有方法存在两个主要局限:- 运动信息提取不足:现有方式多关注像素绝对位移,忽略了目标相对于背景的运动模式,且未充分利用历史帧的累积信息来增强对比度。
- 时空信息融合不充分:现有网络要么缺乏不同层级的特征交互,要么仅将时间信息作为辅助,未能实现空间与时间信息的深度互补和相互过滤,导致虚警率高或检测率低。
本文旨在通过显式提取相对运动模式并构建多层级(浅层局部+深层全局)的时空融合机制来解决上述问题。
动机图解分析:
- 图 1 (Fig. 1): 运动图对比
- 图 (a)展示了原始红外图像,目标(红圈内)极难辨识。
- 图 (b)是光流图(OFM),虽然反映了运动,但背景噪声依然存在。
- 图 © & (d)是其他途径的运动图,哪怕有所增强,但背景杂波仍较多。
- 图 (e)是本文提出的RMM(相对运动图)。可以看到,通过 RMPE 模块的均值相减和历史累积,背景被极大抑制(变黑),而目标区域(亮点)被显著增强。这直观展示了 RMPE 模块在提取纯净运动特征方面的优势。
- 图 7 (Fig. 7): ROC 曲线对比
- 该图展示了不同方法在测试集上的 ROC 曲线。本文方法(GST-Net,黑色实线)在 IDSAT 和 UAVD 信息集上均包络了其他对比办法(如 DNA-Net, MTU-Net 等),表明在相同的虚警率下,本文方法能获得更高的检测率。这证明了 GST-Net 在综合利用时空信息方面的有效性。
- 图 1 (Fig. 1): 运动图对比
3. 主要贡献点
[贡献点 1]:提出了全局时空检测框架
设计了一个包含RMPE(相对运动模式提取) 和 GST-Net(全局时空特征融合网络)的完整框架。该框架不仅显式地提取了目标的相对运动模式,还通过双流网络实现了空间与时间信息的深度融合。[贡献点 2]:设计了时空特征融合模块(STFFM)
在特征编码阶段引入 STFFM,通过空间和通道注意力机制,促进了浅层空间特征和时间特征的交互。这种设计允许两个模态在早期阶段进行互补和噪声过滤,防止了关键目标信息的过早丢失。[贡献点 3]:设计了全局时空依赖提取模块(GSTDEM)
在深层特征交互阶段引入 GSTDEM,利用多头自注意力机制(Multi-Head Self-Attention)捕捉时空域的长距离依赖关系。这使得网络能够在全局范围内关联目标与背景,从而更准确地在高层语义特征中区分目标、背景和噪声。
4. 手段细节
整体网络架构(对应 Fig. 2 & Fig. 4):
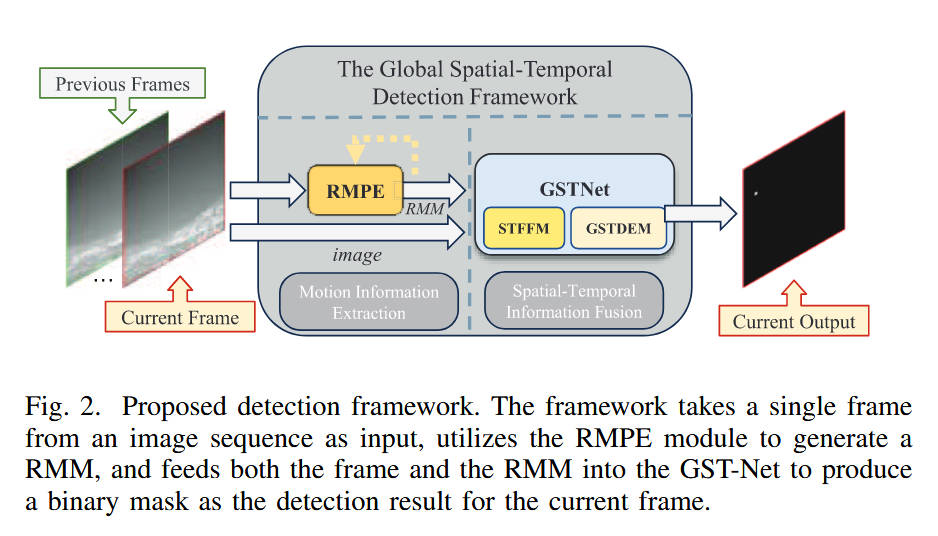
输入流:框架接收当前帧图像i m g imgimg和历史帧序列。
RMPE 模块:首先利用历史帧计算当前帧的相对运动图 (RMM)。RMM 和原始图像i m g imgimg分别作为两个独立分支的输入进入 GST-Net。
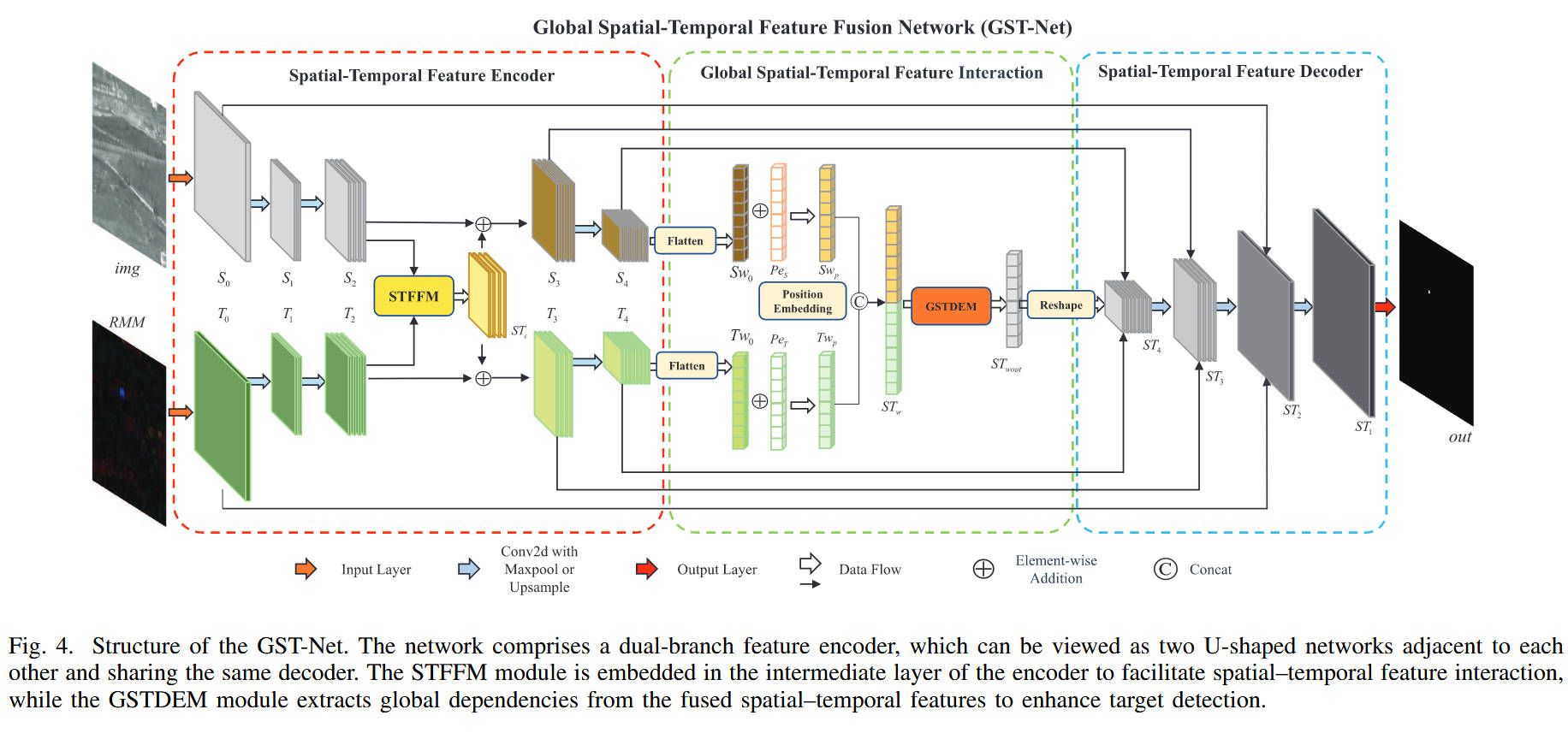
GST-Net 结构:
- 双流编码器:包含一个空间分支(处理i m g imgimg)和一个时间分支(处理R M M RMMRMM)。两个分支结构对称,均包含卷积和池化层。
- STFFM 嵌入:在编码器的中间层(如S 2 , T 2 S_2, T_2S2,T2),嵌入 STFFM 模块,将融合后的特征反哺回两个分支,实现浅层交互。
- 全局交互:编码器输出的深层特征S 4 , T 4 S_4, T_4S4,T4被展平并加上位置编码,送入GSTDEM进行全局注意力计算。
- 解码器:GSTDEM 输出的特征经过重塑和上采样,结合跳跃连接(Skip Connection)恢复分辨率,最终输出检测掩码。
核心创新模块详解:
模块 A:相对运动模式提取 (RMPE) 模块(对应 Fig. 3)
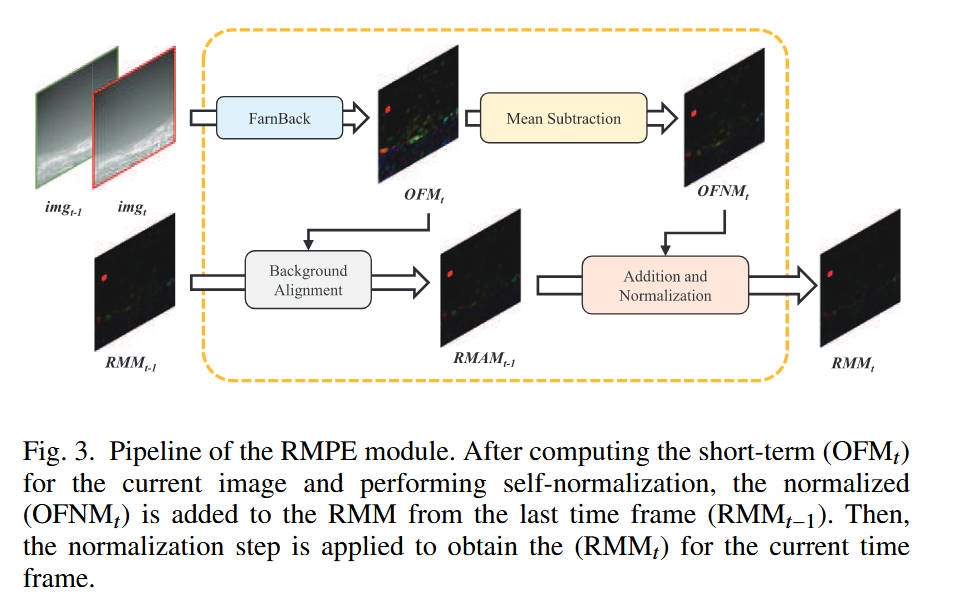
- 内部结构:包含光流计算、均值相减、历史对齐与累积。
- 数据流:
- 光流计算:计算当前帧与前一帧的光流O F M t OFM_tOFMt。
- 均值相减:计算 O F M t OFM_tOFMt 的均值并从 O F M t OFM_tOFMt中减去,得到归一化光流O F N M t OFNM_tOFNMt。这一步消除了背景的全局运动(如相机运动),突出了目标的相对运动。
- 历史累积:将上一时刻的累积运动图R M M t − 1 RMM_{t-1}RMMt−1根据光流对齐到当前时刻,之后与O F N M t OFNM_tOFNMt 相加。
- 归一化:对累积结果进行 Top-K 归一化,得到当前的R M M t RMM_tRMMt。
- 设计目的:凭借累积历史信息增强弱小目标的信号强度,通过相对运动计算抑制背景杂波。
模块 B:时空特征融合模块 (STFFM)(对应 Fig. 5)
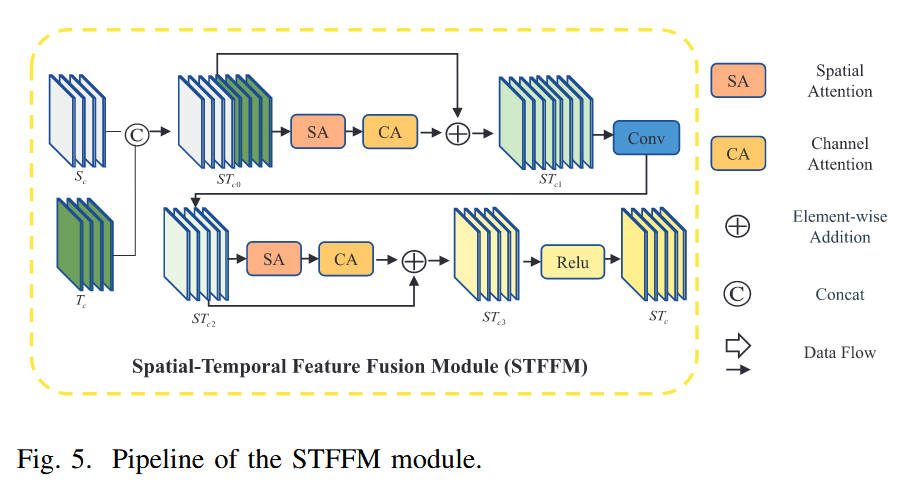
- 内部结构:基于注意力机制的融合块。
- 数据流:
- 输入空间特征S i S_iSi 和时间特征 T i T_iTi进行拼接(Concat)。
- 依次通过 空间注意力 (SA) 和 通道注意力 (CA) 模块。
- 输出的融合特征S T c i ST_{ci}STci分别与原始输入S i S_iSi 和 T i T_iTi相加,更新两个分支的特征。
- 设计理念:在特征提取的早期阶段引入跨模态交互,利用时间信息(哪里在动)引导空间特征(哪里有外观),反之亦然。
模块 C:全局时空依赖提取模块 (GSTDEM)(对应 Fig. 6)
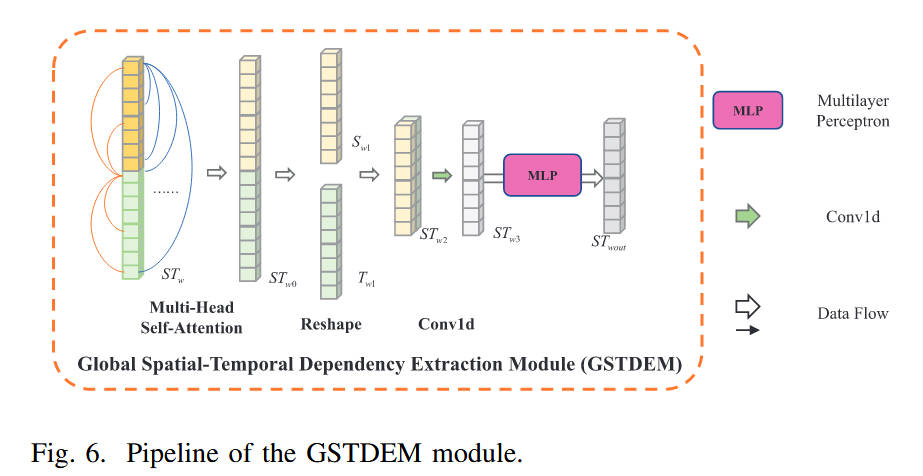
- 内部结构:基于 Transformer 的自注意力块。
- 数据流:
- 将空间和时间分支的深层特征图展平为序列,并加入特制的时空位置编码。
- 输入 多头自注意力 (Multi-Head Self-Attention)模块,计算全局关联矩阵。
- 经过前馈网络(FFN/MLP)和残差连接,输出全局增强的特征序列。
- 最后重塑回 3D 特征图供解码器运用。
- 设计理念:在语义层面上建立长距离的时空依赖,帮助网络在全局范围内区分真实目标和类似目标的干扰物(如闪烁的背景纹理)。
理念与机制总结:
- “相对运动”与“历史累积”:论文认为目标的绝对运动往往被背景运动掩盖,只有相对运动才是显著的。且单帧运动信号微弱,必须依据时间积分(累积)来增强信噪比。
- “双流交互”与“全局关联”:论文强调空间和时间信息是平等的。STFFM 实现了“局部互补”,GSTDEM 建立了“全局辨析”。此种分层级的融合策略确保了细节不丢失,语义更准确。
图解总结:
- Fig. 3清晰展示了 RMPE 如何通过循环累积(Feedback Loop)将微弱的瞬时运动信号逐渐增强为显著的目标热点。
- Fig. 4展示了 GST-Net 的宏观架构,其中红色虚线框内的双流编码器通过中间的黄色 STFFM 块连接,直观体现了“浅层交互”的设计;中间的橙色 GSTDEM 块则体现了“深层融合”的设计。
5. 即插即用模块的作用
本文提出的模块具有很强的通用性,可应用于多种视频分析任务:
RMPE 模块 (Relative Motion Pattern Extraction)
- 适用场景:任何涉及微小运动目标检测、运动背景下的前景提取或视频异常检测的任务。
- 具体应用:
- 视频监控:作为预处理模块,增强监控视频中远距离行人和车辆的运动特征,特别是针对云台摄像机(背景在动)的场景。
- 无人机防撞:用于敏捷提取视野中其他飞行物的相对运动轨迹,辅助避障。
- 红外/可见光小目标检测:直接作为现有单帧检测网络(如 YOLO)的输入增强模块(输入 Image + RMM),显著提升对运动目标的召回率。
STFFM 模块 (Spatial-Temporal Feature Fusion Module)
- 适用场景:双流网络(Two-Stream Networks)、多模态融合(如 RGB-Thermal, RGB-Depth)。
- 具体应用:
- 行为识别:在 RGB 流和 Optical Flow 流的 CNN 骨干网络中间插入 STFFM,促进外观和运动特征的早期融合。
- RGB-T 目标检测:用于融合可见光和热成像特征,利用 STFFM 的注意力机制让两种模态互为补充,提升全天候检测性能。
GSTDEM 模块 (Global Spatial-Temporal Dependency Extraction Module)
- 适用场景:需要长距离时空建模的任务,如视频目标分割、视频显著性检测。
- 具体应用:
- 视频语义分割:作为解码器前的瓶颈层(Neck),利用其全局自注意力机制捕捉视频序列中的长时依赖,解决遮挡或目标暂时消失的问题。
- 时序动作定位:用于在长视频特征序列中提取关键帧之间的全局关联,提升动作边界定位的准确性。
到此,所有的内容就基础讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦。
获取更多高质量论文及完整源码关注【AI即插即用】