此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第四课的第二周内容,2.8到2.11的内容,同时也是本周理论部分的最后一篇。
本周为第四课的第二周内容,这一课所有内容的中心只有一个:计算机视觉。应用在深度学习里,就是专门用来进行图学习的模型和技术,是在之前全连接基础上的“特化”,也是相关专业里的一个重要研究大类。
这一整节课都存在大量需要反复理解的内容和机器学习、数学基础。 因此我会尽可能的补足基础,用比喻和实例来演示每个部分,从而帮助理解。
第二周的内容是对一些经典网络模型结构和原理的介绍,自然会涉及到相应的文献论文。因此,我也会在相应的模型下附上提出该模型的论文链接。
这周的难点部分已经过去了,最后这部分是关于如何更好地使用本周以及之前了解过的模型的方法,即几条方法论。
1. 寻找论文作者的开源项目代码
在深度学习领域,尤其是 CV 和 NLP 方向,许多论文作者都会将实验代码开源,最常见的发布平台就是 GitHub。
GitHub是目前世界上最大的代码托管,交流平台。如果你不太了解它,站内站外都有大量的关于GitHub 的新手教学,这是相关专业里几乎所有人都要用到的一个平台。
我之前在介绍图床也使用了它来存储图片。
作者的源码通常包含论文中使用的模型结构与训练流程,但在具体细节方面可能因人而异,质量差异较大,需要结合论文与代码共同理解。
显然,站在巨人的肩膀上,要比我们自己一点点造轮子要快很多,当然,后者也是必要的能力。
通过阅读作者源码,我们可以理解很多论文中一笔带过、但对性能影响巨大的工程细节和设计取舍,比如某个不起眼的参数设置。
实际操作时,一个常见流程是:
- 先在论文首页或 arXiv 页面查找是否附带 GitHub 链接;
- 如果没有,可以直接用「论文标题 + GitHub」进行搜索;
- 或查看作者个人主页、实验室主页,很多都会集中维护代码仓库。
需要注意的是,搜索结果中也可能出现第三方复现代码,这类代码在工程上可能更规范,但不一定完全等价于论文原始实验设置,使用时需要区分“作者官方实现”和“社区复现”。
以 ResNet 为例,其原论文作者及后续社区已经维护了多套高质量实现,目前常用版本也被集成进了 PyTorch / TensorFlow 官方模型库中。
这是我的搜索的结果之一,是Deep Residual Learning for Image Recognition 的第一作者何恺明和其团队对残差网络的的开源代码,你可以点击绿色的 Code 间选择不同的方式把项目下载到本身。
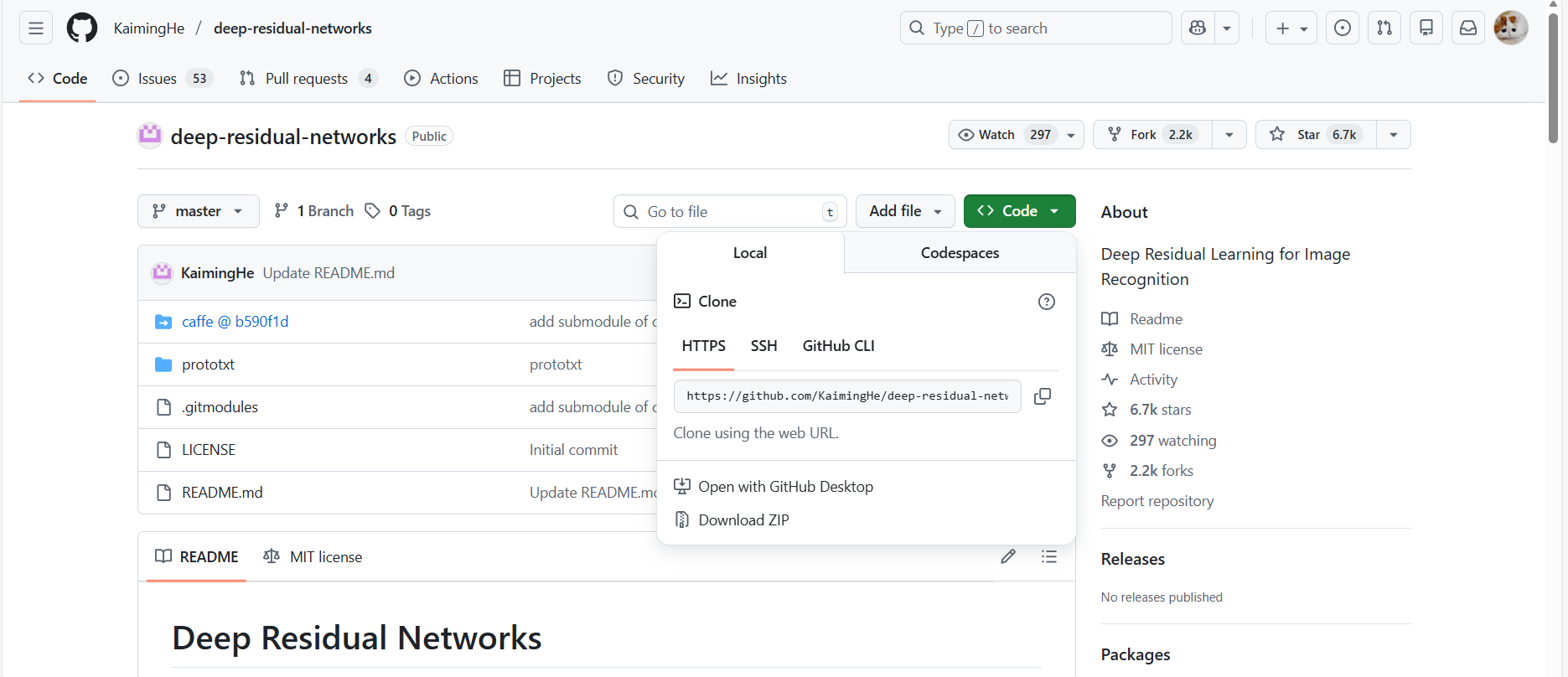
相关教程有很多,具体操作流程这里不再展开,以后如果有机会,我也希望能单独出一个这方面的教程。
需要额外强调的一点是:虽然 GitHub 上目前已经有了大量的中文项目,但终究还是以英文为主,如果希望找到一些经典的出处,还是要掌握一定的英文能力。
而且GitHub 对国内的连接时常不稳定,有时需要“魔法”才能稳定进入。
因此,如果你平时有兴趣浏览一些项目或者博客,但又受限于英文水平,GitHub中文社区也是一个不错的选择。不过在查找论文原始出处或权威实现时,仍建议以英文 GitHub 仓库和作者主页为准。
2. 应用迁移学习
实际上,我们在上一课的理论部分已经详细展开过迁移学习了,并且在代码实践部分演示了ResNet-18 在我们一直使用的猫狗二分类数据集上的良好效果。
这里我们再简单展开一下:
在实际任务中,从零开始训练一个模型,往往既慢又不稳定。
相比之下,使用已经训练好的模型参数作为初始化,是目前更主流、也更现实的选择。
在 CV 领域,许多模型已经在 ImageNet 等大规模数据集上完成了充分训练,这些模型学到的底层特征(边缘、纹理、形状)具有很强的通用性。
因此,即便你的任务和原始数据集并不完全一致,这些预训练权重依然能作为一个很好的起点。
在演示部分我们也偶看到了,PyTorch 和 TF 都内置了可以调用预训练模型的模块与相应方法。
CV 领域已经形成了一批相对成熟、活跃的数据集平台与社区,因此,我们这里补充几个可以寻找数据集的平台,与迁移学习强强联合达到更好的效果。(需要魔法)
(1)Kaggle Datasets
Kaggle 是目前最知名的机器学习竞赛与社区平台之一,其 Datasets 板块汇集了大量公开数据集,覆盖图像分类、目标检测、医学影像、遥感图像等多个方向。
(2)Hugging Face Datasets
虽然 Hugging Face 最早以 NLP 闻名,但近年来其 Datasets 库已经逐步覆盖视觉领域。
(3)学术机构与官方数据集网站
对于一些经典任务,数据集往往直接由学术机构或研究团队维护,例如:
- ImageNet
- CIFAR
- COCO
- Pascal VOC
3. 使用数据增强
同样,对于数据增强,我们之前已经进行过理论介绍和实践演示。
这里再简单补充一下:
数据增强并不是“造新数据”,而是通过对原始样本进行合理扰动,迫使模型学习更稳健、更具泛化性的特征。
常见的数据增强方式包括:
- 空间变换:随机裁剪、翻转、旋转;
- 颜色变换:亮度、对比度、饱和度扰动;
这些操作的共同点在于:
它们不会改变样本的语义标签,但会打破模型对某些“表面规律”的依赖。
例如:
- 不再依赖固定位置;
- 不再依赖固定光照;
- 不再依赖单一颜色分布。
在很多任务中,合理的数据增强带来的收益,甚至不亚于更换模型结构,而且相比设计新网络,它的实现成本往往更低。
在 PyTorch 中,数据增强通常作为 数据预处理流水线的一部分,通过 torchvision.transforms 在 训练阶段 作用于样本,我们也不止一次演示过,相信你也并不陌生了。
4. 竞赛策略
最后一点,更偏向方法论层面的提醒。
在学术竞赛或榜单任务中,目标往往只有一个:性能最大化。
因此,我们简单介绍两个之前没提到过的策略:多模型集成与多裁剪测试。
4.1 多模型集成(Ensemble)
多模型集成指的是: 在推理阶段同时使用多个已经训练完成的模型,对同一个输入样本进行预测,再对输出结果进行融合(如取平均、加权平均或投票)。
就像这样:
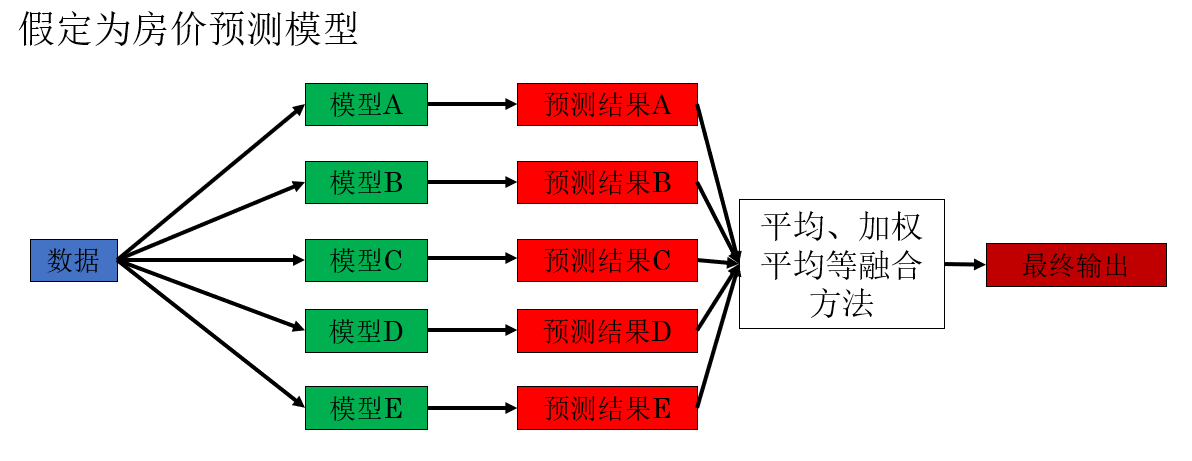
直观理解很简单: 不把决策权交给单一模型,而是让多个模型共同“表决”。
具体来说,不同模型即使结构相同,只要训练过程存在差异(初始化、数据顺序、正则化方式等),其犯错模式也往往不同,集成后,这些不一致的错误会被相互抵消,整体预测更加稳定。
从统计角度看,ensemble 的作用类似于降低模型预测的方差。
常见的集成方式有很多:
- 不同结构的模型集成;
- 同一结构、不同随机种子的模型集成;
- 不同训练轮次的模型集成。
4.2 多裁剪测试(Multi-crop)
多裁剪测试指的是: 在验证或测试阶段,对同一输入图像生成多个裁剪版本,分别送入模型预测,再对结果取平均。
以常见的 10-crop 为例:
- 对原图进行中心裁剪和四角裁剪;
- 再对每个裁剪做一次水平翻转;
- 共得到 10 个输入视角。
就像这样:

我们把一幅测试图像裁剪成十份,再对它们取平均。
理论上讲:单次裁剪可能恰好丢失关键信息,而多裁剪可以降低这种偶然性,不同裁剪在特征层面的响应不同,取平均后结果更稳定。
而且这种方式不需要重新训练模型,只在评估阶段增加相应逻辑即可获得收益。
4.3 竞赛与实际部署
上面提到的方法在竞赛环境下完全合理,这是因为在竞赛环境中:响应时间往往不敏感,资源成本也不是首要约束,我们只关心最终指标。
但在真实部署场景中,情况往往完全不同:
- 响应延迟、显存占用、电力消耗都是硬约束;
- 模型需要稳定、可维护、可扩展;
- 很多竞赛技巧在工程上并不划算,甚至不可用。
因此,一个非常重要的认知是: 竞赛解法 ≠ 工业解法。
5.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 查找论文作者的开源代码 | 直接使用或参考作者官方实现,获取完整模型结构、训练流程与关键工程细节,避免仅凭论文文字复现造成偏差 | 看菜谱不如进后厨,看别人怎么真正下锅 |
| 官方实现 vs 社区复现 | 官方代码最贴近论文实验设置;社区复现可能更工程化,但不一定严格等价 | 原厂零件 vs 第三方兼容件 |
| 预训练模型 | 底层卷积学到的边缘、纹理、形状具有跨任务泛化能力 | 已经练过基本功的运动员,换项目也更快上手 |
| 数据集平台 | Kaggle、Hugging Face、官方数据集网站集中提供标准化、可复用的数据资源 | 公共食材市场,不必自己从头种菜 |
| 数据增强 | 对样本做不改变语义的扰动,打破模型对表面规律的依赖,提高泛化能力 | 让学生在不同光线、角度下反复看同一道题 |
| 多模型集成(Ensemble) | 多个模型共同预测,融合结果以抵消单模型的偶然错误,降低方差 | 多个评委投票,而不是一个人拍板 |
| 多裁剪测试(Multi-crop) | 对同一图像从多个视角预测并取平均,降低单次裁剪信息缺失的风险 | 多看几眼同一张照片再下结论 |
| 竞赛策略 | 用计算资源换性能上限,推理成本不是首要约束 | 用钱和时间堆出最高分 |
| 工业部署 | 在延迟、显存、功耗等约束下做整体权衡,强调稳定与可维护 | 在有限预算下装修房子 |